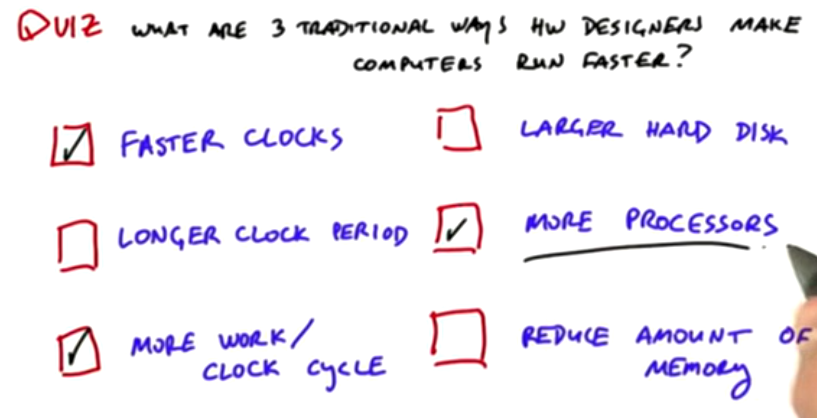
For example, how can we dig holes from the United States to China faster
- Use a shovel to dig from every 2 seconds to every 1 second. There is an upper limit. If it is too fast, the shovel will break
(increasing the clock frequency of the processor will increase the energy consumption, and there is an upper limit on the energy consumption of each chip). Allowing the processor to run at a faster clock frequency will take a shorter time at each step of a calculation, but increasing the clock frequency will also increase the power consumption.
- Use a shovel with two shovel heads, but there are process restrictions, and there can be no 100 shovel heads
(more work per clock cycle) let our processor do more work in each step and each clock cycle, but the benefit of a single processor in doing work in each cycle decreases. Technically speaking, the most advanced CPU is at the limit of how much instruction level parallelism the CPU can extract in each clock cycle
- Hiring more people also has a problem: how to manage? Will they interfere with each other? How can we ensure that they dig deep rather than wide
(parallel computing, not just hiring people with one shovel, but hiring people with multiple shovels) parallel computing, that is, GPU, "hiring more diggers with shovels, not a digger with a magic shovel", is not having one or just a few very powerful processors. We need a lot of less powerful processors
How To Make Computers Run Faster
We break down the big problem into small pieces, and then we run these small pieces at the same time
From the perspective of technology trends: why is parallelism so popular in the whole world?
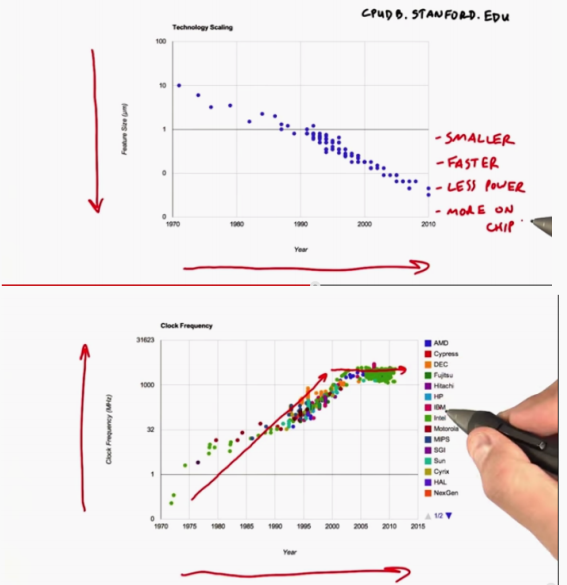
Good news: modern processors are made up of transistors. These transistors are getting smaller year by year, so more and more transistors can be integrated on the chip, so more and more computing resources are available.
The bad news: thanks to the improvement of transistors, processor designers can increase the clock frequency of processors and make them run faster and faster every year. But now it has reached the limit, because after too much integration, each transistor will emit heat. We can't cool it down to ensure working performance, so we have to change our thinking. In the past, we made a single processor faster and faster (CPU has strong processing capacity, correspondingly, its power consumption is also large, and the design cost is expensive), We want to achieve the highest computing efficiency under the condition of fixed power consumption - create a large number of parallel computing units in GPU, and each computing unit is like a chicken, However, we can put a large number of computing units into one chip (for example, the area of cultivated land is limited, the cost of buying two cattle is very high, and only two cattle can be put into this land, so it's better to buy 50 chickens, and the efficiency is not necessarily worse than cattle). What are the challenges? How can they be programmed to work together to solve complex problems?
How Are CPUs Getting Faster

Our timing system has not become faster, and the clock frequency remains the same
What Kind of Processors Are We Building?
We can't make processors in the usual serial way. In the past, we made a single processor faster and faster, but we couldn't keep it cool. Parallelism is the use of smaller and more efficient processors, and additional resources to create more efficient processors

CPU has flexibility in performance, but the control hardware becomes more complex and expensive in terms of power and design complexity
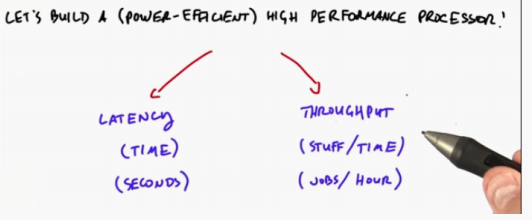
We want to calculate the maximum benefit under fixed electricity
Techniques To Building Powerefficient Chips

This is also the design concept of GPU
When we manufacture high-performance processors, in addition to the best energy consumption, what else do we need to optimize
-
Execution time is the time to complete a task
minimizing latency: the amount of time to complete a task
-
Throughput is the number of tasks completed per unit time
Throughput: tasks completed per unit time
However, the two objectives are not necessarily consistent. The traditional CPU optimizes the execution time and GPU optimizes the throughput. For example, in CV, we are more concerned with the number of pixels per second than the execution time of a specific pixel
Latency vs Bandwidth
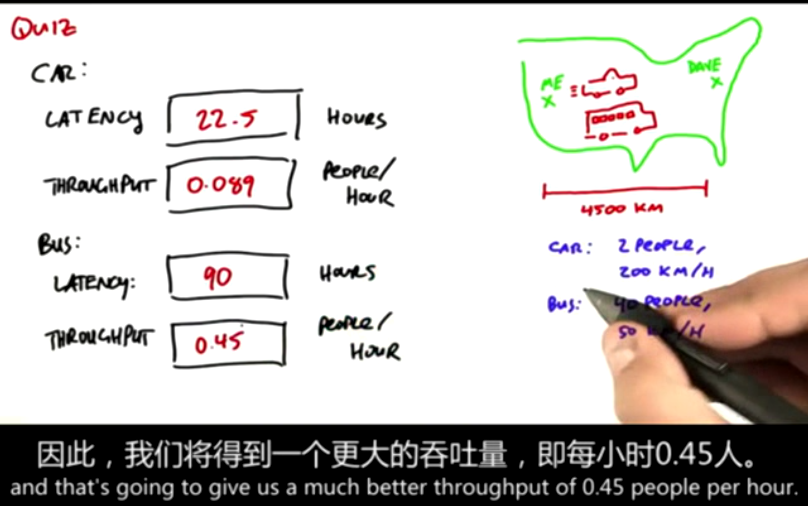
These two trends are not necessarily opposite. Improving latency tends to lead to greater throughput, and vice versa, but GPU designers actually give priority to throughput
Consider how GPU designers make decisions
Core GPU Design Tenets
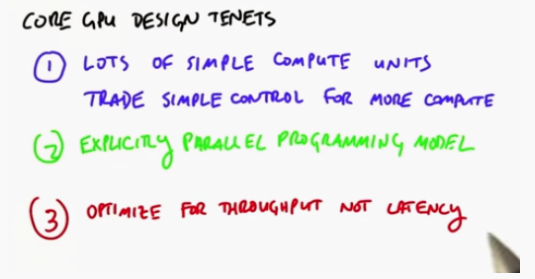
- There are many simple computing units that can perform a large number of operations together
- Efficient parallel programming model
- GPU is optimized for throughput, not latency
GPU from the Point of View of the Developer

Parallel programming is also important for CPU s, such as 8-core Intel processors
Overall structure of CUDA
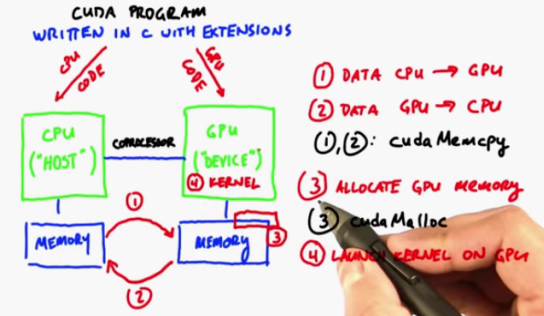
CUDA assumes that GPU is the coprocessor of CPU, and also assumes that they have their own separate memory and their own dedicated physical memory in the form of DRAM.
GPU memory is usually a memory block with high performance
What the system should do:
- Transfer CPU memory data to GPU memory
- GPU to CPU
(in C programming language, transferring data from one place to another is called Memcopy, which corresponds to cudamemcopy in cuda) - Allocate memory on GPU (cudaMalloc)
- The GPU calls programs that are calculated in parallel. These programs are called kernels (the host starts kernels in the device)
Gpu can respond to requests sent and received by the CPU, but it cannot initiate requests by itself
Data flow of CUDA
cudaMalloc->cudaMemcpy->kernel launch->cudaMemcpy

- Compared with the parallel of cpu, the parallel overhead of gpu is smaller.
- The parallel part of cpu needs to be supported by the operating system. Of course, for example, x86, arm will also have vector processing unit and corresponding avx/neon instruction set. But their main content is to deal with complex serial logic operations.
Compared with the calculation, the transmission volume is very small, which is suitable for GPU calculation, otherwise it will not be uploaded once.
Defining the GPU Computation
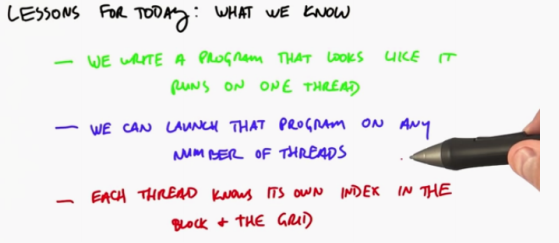
You write a program (kernel) as if it is running on a thread, and then when you call the kernel from the CPU, you tell him how many threads to start, then each of these threads will run the kernel
What is GPU good at

Example: calculate the square from 1 to 63

Take an input array containing 64 floating-point numbers and output the square of each number
CPU:
The CPU doesn't have to worry about allocating memory or initializing arrays

Moreover, the thread explicitly traverses all its inputs (here we define the thread as an independent execution path of the code)
2. There is no explicit parallelism. This is serial code. There is only one thread, which will cycle 64 times, and each iteration will do an operation

For GPU:
Part of the GPU code runs on the GPU and the other part runs on the CPU
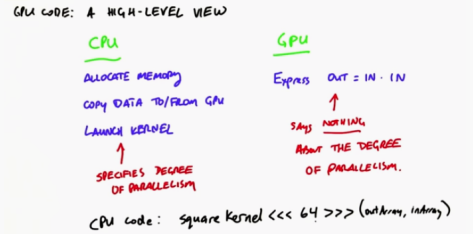
-
For the GPU part, we only need to express a very simple idea, that is, the output is equal to the input multiplication. Now the kernel we write for GPU does not say the parallelism level. We know that the kernel looks like a serial program, so in fact, the idea of 64 times multiplication is not reflected in the GPU program (it looks like a serial program)
-
For the CPU part, it must allocate memory,
Copy data to and back from GPU,
The most important part of the computing part is that the CPU starts the kernel (this is where the degree of thread parallelism is expressed)
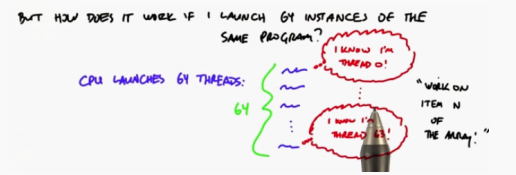
Each thread we start knows which thread it is (thread index), and then you can allocate thread n to process the nth element of the array

Step 1: you write a kernel function on the GPU, which only runs on one thread at a time
Step 2: you launch many threads on the CPU, and each will run the kernel of the previous step independently
code
#include <stdio.h>
//kernel, here we write a serial program
__global__ void square(float* d_out,float* d_in){
//cuda has a built-in variable called thread index, threadidx, which will tell each thread in a block their index
//threadidx is a c structure with three members x,.y, .z
//The first instance of these threads, threadidx X will return 0
//What the kernel is actually doing: for each thread, we first read the array element corresponding to the thread index from global memory and store it in floating-point variable f, then we square f, and then we write the value back to global memory
int idx = threadIdx.x;
float f = d_in[idx];
d_out[idx] = f * f;
}
int main(int argc,char** argv){
//Declare the size of the array and determine how many bytes it uses
const int ARRAY_SIZE = 8;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// generate the input array on the host
float h_in[ARRAY_SIZE];
for(int i=0;i<ARRAY_SIZE;i++){
h_in[i] = float(i);
}
float h_out[ARRAY_SIZE];
// declare GPU memory pointers
float* d_in;
float* d_out;
// allocate GPU memory allocates memory for memory pointers
cudaMalloc((void**) &d_in,ARRAY_BYTES);
cudaMalloc((void**) &d_out,ARRAY_BYTES);
// transfer the array to GPU copy our main array column to device
//Destination address, source address, size, transfer direction
cudaMemcpy(d_in,h_in,ARRAY_BYTES,cudaMemcpyHostToDevice);
// launch the kernel
//Start a kernel called square for a block with 64 elements
//Tell the CPU to start 64 copies of the kernel in 64 threads on the GPU
square<<<1,ARRAY_SIZE>>>(d_out,d_in);
// copy back the result array to the GPU
cudaMemcpy(h_out,d_out,ARRAY_BYTES,cudaMemcpyDeviceToHost);
// print out the resulting array
for(int i=0;i<ARRAY_SIZE;i++){
printf("%f",h_out[i]);
printf(((i%4) != 3) ? "\t" : "\n");
}
// free GPU memory allocation
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
nvcc -o square square.cu ./square
We can only call the kernel on the GPU data, not on the CPU
We are not running the standard C compiler, but NVCC, NVIDIA C compiler. The output will be an executable file called square, and our input file is square cu
Tips: data on the CPU in h_ The data on GPU starts with d_ start
__ global__ Is the flag of the kernel function. void means that the kernel will not return a value
Configuring the Kernel Launch Parameters
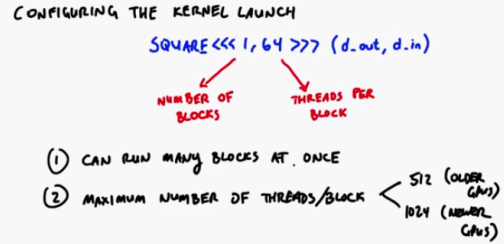
Started a block with 64 threads
Background: when you start a kernel, you specify the number of blocks and the number of threads per block
Hardware: it has the ability to run multiple blocks at the same time, and each block has a maximum number of threads it can support
There are two things you should know about hardware
a. Many blocks can be run at a time
b. There is an upper limit on the number of threads that can be installed in each block (New GPU1024, old 512)
In fact, when we start a thread, it knows its position in the block (index) and the block position in the grid (index)
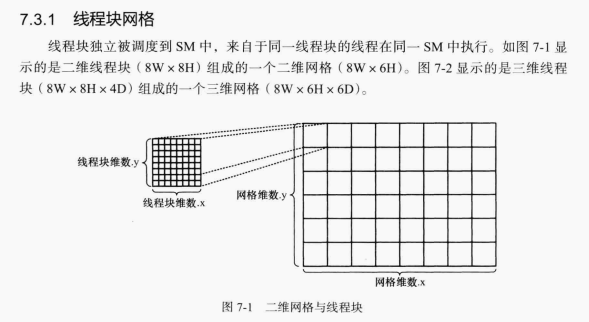
Many problems are 2D (image processing) or 3D. CUDA supports multidimensional
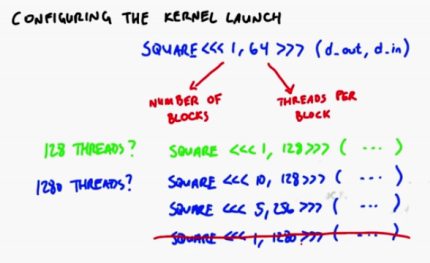
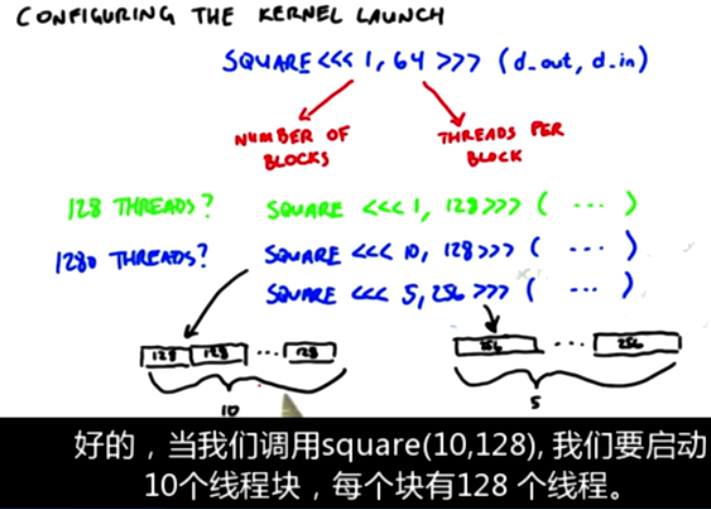
These graphs are one-dimensional. They only develop in one dimension x
When we want to deal with 128 * 128 two-dimensional graphics:
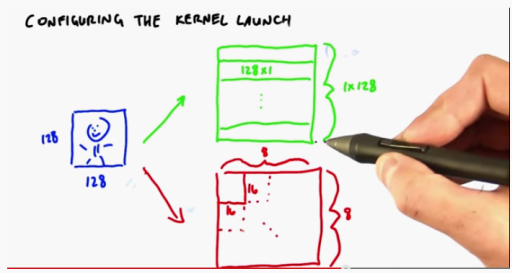
cuda supports 1, 2 and 3-dimensional thread blocks

The first parameter is the dimension of the thread block network, and the second parameter is the dimension number of threads in a block
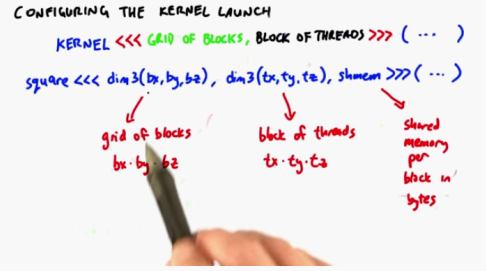
In fact, square has three parameters:
- The dimension of the network block,
- Each block is specified by this parameter: a thread block with txtytz threads
- The default value of the third parameter is 0, which is the amount of shared memory allocated by each thread block in bytes
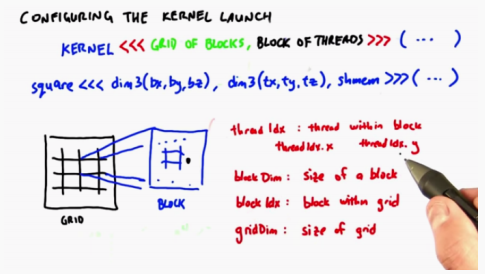
Each thread knows its thread id in a block. In fact, it knows more

CUDA is born with the ability to deal with multidimensional problems
!!!!!! We should try our best to find more 2D meshes and blocks in the problem!!!!!!!
Introduction of the concept of Map

- We have two components that will produce the concept of mapping. First, we have a set of elements to deal with. In this example, this is an array containing 64 floating-point numbers; Second, we have the ability to write an arbitrary function that runs on each element. In this section, our function squares each of its input elements to produce an output element. This is a powerful parallel operation.
- Map is a key building block of GPU computing. There are two main reasons why GPU is good at map: (1) GPU has many parallel processors, and GPU is very efficient for delegating the calculation of a single element to those processors; (2) GPU optimizes throughput rather than latency.

First CUDA project
Using CUDA to input a color image and then output the image in gray scale will involve a mapping operation for each pixel of the image: the operation for each pixel is to convert the color input in the form of R, G and B into a single brightness value
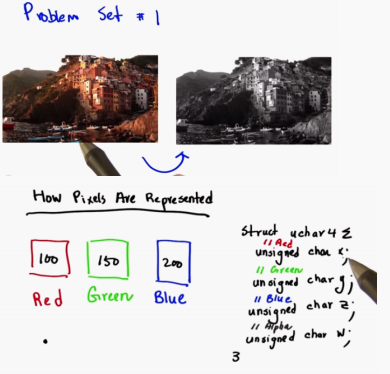
The fourth alpha channel contains transparency information

// Homework 1
// Color to Greyscale Conversion
//A common way to represent color images is known as RGBA - the color
//is specified by how much Red, Green, and Blue is in it.
//The 'A' stands for Alpha and is used for transparency; it will be
//ignored in this homework.
//Each channel Red, Blue, Green, and Alpha is represented by one byte.
//Since we are using one byte for each color there are 256 different
//possible values for each color. This means we use 4 bytes per pixel.
//Greyscale images are represented by a single intensity value per pixel
//which is one byte in size.
//To convert an image from color to grayscale one simple method is to
//set the intensity to the average of the RGB channels. But we will
//use a more sophisticated method that takes into account how the eye
//perceives color and weights the channels unequally.
//The eye responds most strongly to green followed by red and then blue.
//The NTSC (National Television System Committee) recommends the following
//formula for color to greyscale conversion:
//I = .299f * R + .587f * G + .114f * B
//Notice the trailing f's on the numbers which indicate that they are
//single precision floating point constants and not double precision
//constants.
//You should fill in the kernel as well as set the block and grid sizes
//so that the entire image is processed.
#include "utils.h"
#include <stdio.h>
__global__
void rgba_to_greyscale(const uchar4* const rgbaImage,
unsigned char* const greyImage,
int numRows, int numCols)
{
//TODO
//Fill in the kernel to convert from color to greyscale
//the mapping from components of a uchar4 to RGBA is:
// .x -> R ; .y -> G ; .z -> B ; .w -> A
//
//The output (greyImage) at each pixel should be the result of
//applying the formula: output = .299f * R + .587f * G + .114f * B;
//Note: We will be ignoring the alpha channel for this conversion
//First create a mapping from the 2D block and grid locations
//to an absolute 2D location in the image, they use that to
//calculate a 1D offset
int y = threadIdx.y+ blockIdx.y* blockDim.y;
int x = threadIdx.x+ blockIdx.x* blockDim.x;
if (y < numCols && x < numRows) {
int index = numRows*y +x;
uchar4 color = rgbaImage[index];
unsigned char grey = (unsigned char)(0.299f*color.x+ 0.587f*color.y + 0.114f*color.z);
greyImage[index] = grey;
}
}
void your_rgba_to_greyscale(const uchar4 * const h_rgbaImage, uchar4 * const d_rgbaImage,
unsigned char* const d_greyImage, size_t numRows, size_t numCols)
{
//You must fill in the correct sizes for the blockSize and gridSize
//currently only one block with one thread is being launched
int blockWidth = 32;
const dim3 blockSize(blockWidth, blockWidth, 1);
int blocksX = numRows/blockWidth+1;
int blocksY = numCols/blockWidth+1; //TODO
const dim3 gridSize( blocksX, blocksY, 1); //TODO
rgba_to_greyscale<<<gridSize, blockSize>>>(d_rgbaImage, d_greyImage, numRows, numCols);
cudaDeviceSynchronize(); checkCudaErrors(cudaGetLastError());
}