Foreword
Flink SQL is simple, easy to use and powerful. One of the important factors is that it has rich connector components. Connector is the carrier of Flink's interaction with external systems, and is divided into two categories: Source responsible for reading and Sink responsible for writing. However, the built-in connector of Flink SQL may not be able to cover various requirements in the actual business, so we need to customize it ourselves. Fortunately, the community has provided a standardized and easy to expand system. Users can easily build their own connectors as long as they program interface oriented according to the specification. Based on the existing Bahir Flink project, this paper gradually realizes an SQL Redis Connector.
Introducing DynamicTableSource/Sink
The architecture diagram of the current (Flink 1.11 +) Flink SQL Connector is as follows. See FLIP-95 for design documents.
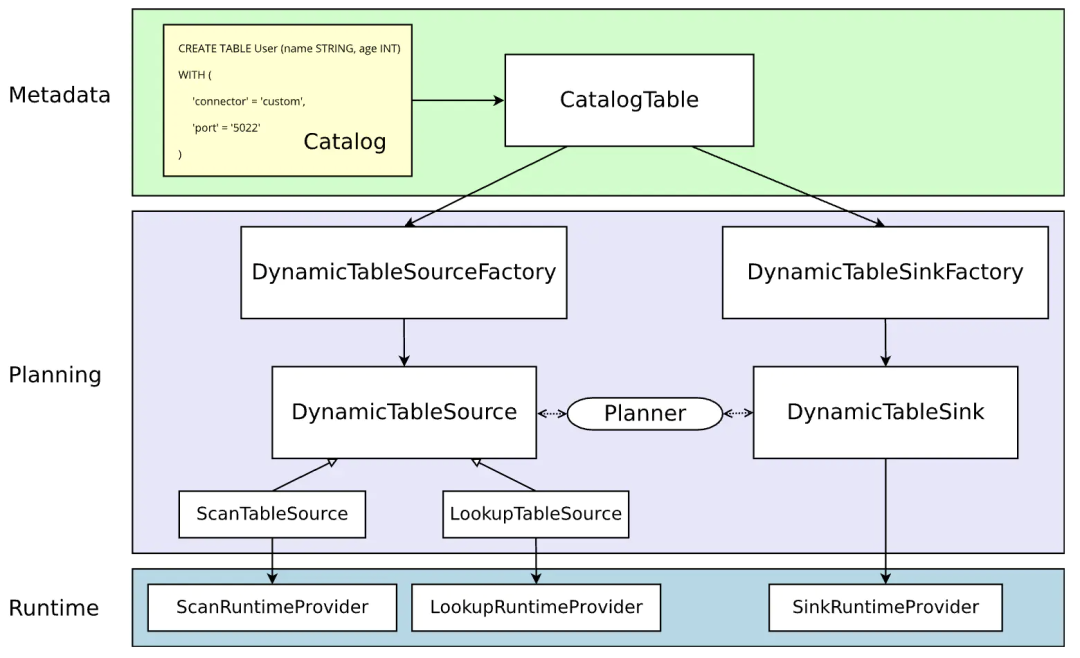
Dynamic table has always been an important concept of Flink SQL stream batch integration, and it is also the core of the Planning phase in the above architecture. The main work of the custom Connector is to implement the Source/Sink based on the dynamic table, including the upstream factory that generates it and the downstream RuntimeProvider that actually executes the Source/Sink logic in the Runtime stage. The table Metadata in the Metadata phase is maintained by the Catalog.
Massive code warning ahead.
Implementing RedisDynamicTableFactory
DynamicTableFactory requires the following functions:
- Define and verify the parameters passed in during table creation;
- Get the metadata of the table;
- Define the encoding / decoding format when reading and writing data (not required);
- Create an available DynamicTable[Source/Sink] instance.
The factory class skeleton that implements the DynamicTable[Source/Sink]Factory interface is shown below.
public class RedisDynamicTableSink implements DynamicTableSink {
private final ReadableConfig options;
private final TableSchema schema;
public RedisDynamicTableSink(ReadableConfig options, TableSchema schema) {
this.options = options;
this.schema = schema;
}
@Override
public ChangelogMode getChangelogMode(ChangelogMode changelogMode) { }
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) { }
@Override
public DynamicTableSink copy() { }
@Override
public String asSummaryString() { }
}First define Redis Connector Required parameters, using the built-in ConfigOption/ConfigOptions Class. Their meanings are very simple and will not be repeated.
public static final ConfigOption<String> MODE = ConfigOptions
.key("mode")
.stringType()
.defaultValue("single");
public static final ConfigOption<String> SINGLE_HOST = ConfigOptions
.key("single.host")
.stringType()
.defaultValue(Protocol.DEFAULT_HOST);
public static final ConfigOption<Integer> SINGLE_PORT = ConfigOptions
.key("single.port")
.intType()
.defaultValue(Protocol.DEFAULT_PORT);
public static final ConfigOption<String> CLUSTER_NODES = ConfigOptions
.key("cluster.nodes")
.stringType()
.noDefaultValue();
public static final ConfigOption<String> SENTINEL_NODES = ConfigOptions
.key("sentinel.nodes")
.stringType()
.noDefaultValue();
public static final ConfigOption<String> SENTINEL_MASTER = ConfigOptions
.key("sentinel.master")
.stringType()
.noDefaultValue();
public static final ConfigOption<String> PASSWORD = ConfigOptions
.key("password")
.stringType()
.noDefaultValue();
public static final ConfigOption<String> COMMAND = ConfigOptions
.key("command")
.stringType()
.noDefaultValue();
public static final ConfigOption<Integer> DB_NUM = ConfigOptions
.key("db-num")
.intType()
.defaultValue(Protocol.DEFAULT_DATABASE);
public static final ConfigOption<Integer> TTL_SEC = ConfigOptions
.key("ttl-sec")
.intType()
.noDefaultValue();
public static final ConfigOption<Integer> CONNECTION_TIMEOUT_MS = ConfigOptions
.key("connection.timeout-ms")
.intType()
.defaultValue(Protocol.DEFAULT_TIMEOUT);
public static final ConfigOption<Integer> CONNECTION_MAX_TOTAL = ConfigOptions
.key("connection.max-total")
.intType()
.defaultValue(GenericObjectPoolConfig.DEFAULT_MAX_TOTAL);
public static final ConfigOption<Integer> CONNECTION_MAX_IDLE = ConfigOptions
.key("connection.max-idle")
.intType()
.defaultValue(GenericObjectPoolConfig.DEFAULT_MAX_IDLE);
public static final ConfigOption<Boolean> CONNECTION_TEST_ON_BORROW = ConfigOptions
.key("connection.test-on-borrow")
.booleanType()
.defaultValue(GenericObjectPoolConfig.DEFAULT_TEST_ON_BORROW);
public static final ConfigOption<Boolean> CONNECTION_TEST_ON_RETURN = ConfigOptions
.key("connection.test-on-return")
.booleanType()
.defaultValue(GenericObjectPoolConfig.DEFAULT_TEST_ON_RETURN);
public static final ConfigOption<Boolean> CONNECTION_TEST_WHILE_IDLE = ConfigOptions
.key("connection.test-while-idle")
.booleanType()
.defaultValue(GenericObjectPoolConfig.DEFAULT_TEST_WHILE_IDLE);
public static final ConfigOption<String> LOOKUP_ADDITIONAL_KEY = ConfigOptions
.key("lookup.additional-key")
.stringType()
.noDefaultValue();
public static final ConfigOption<Integer> LOOKUP_CACHE_MAX_ROWS = ConfigOptions
.key("lookup.cache.max-rows")
.intType()
.defaultValue(-1);
public static final ConfigOption<Integer> LOOKUP_CACHE_TTL_SEC = ConfigOptions
.key("lookup.cache.ttl-sec")
.intType()
.defaultValue(-1);Next, overwrite them separately requiredOptions()and optionalOptions()Methods, which return Connector Required and optional parameter sets for.
@Override
public Set<ConfigOption<?>> requiredOptions() {
Set<ConfigOption<?>> requiredOptions = new HashSet<>();
requiredOptions.add(MODE);
requiredOptions.add(COMMAND);
return requiredOptions;
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
Set<ConfigOption<?>> optionalOptions = new HashSet<>();
optionalOptions.add(SINGLE_HOST);
optionalOptions.add(SINGLE_PORT);
// The other 14 parameters are omitted
optionalOptions.add(LOOKUP_CACHE_TTL_SEC);
return optionalOptions;
}Then overwrite them separately createDynamicTableSource()And createDynamicTableSink()Method, creating DynamicTableSource and DynamicTableSink example. Before creating, we can use the built-in TableFactoryHelper Tool class to verify the passed in parameters. Of course, you can also write your own verification logic. In addition, the metadata of the table can be obtained through the associated context object. The code is as follows, and the specific code will be written later Source/Sink Class.
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
FactoryUtil.TableFactoryHelper helper = createTableFactoryHelper(this, context);
helper.validate();
ReadableConfig options = helper.getOptions();
validateOptions(options);
TableSchema schema = context.getCatalogTable().getSchema();
return new RedisDynamicTableSource(options, schema);
}
@Override
public DynamicTableSink createDynamicTableSink(Context context) {
FactoryUtil.TableFactoryHelper helper = createTableFactoryHelper(this, context);
helper.validate();
ReadableConfig options = helper.getOptions();
validateOptions(options);
TableSchema schema = context.getCatalogTable().getSchema();
return new RedisDynamicTableSink(options, schema);
}
private void validateOptions(ReadableConfig options) {
switch (options.get(MODE)) {
case "single":
if (StringUtils.isEmpty(options.get(SINGLE_HOST))) {
throw new IllegalArgumentException("Parameter single.host must be provided in single mode");
}
break;
case "cluster":
if (StringUtils.isEmpty(options.get(CLUSTER_NODES))) {
throw new IllegalArgumentException("Parameter cluster.nodes must be provided in cluster mode");
}
break;
case "sentinel":
if (StringUtils.isEmpty(options.get(SENTINEL_NODES)) || StringUtils.isEmpty(options.get(SENTINEL_MASTER))) {
throw new IllegalArgumentException("Parameters sentinel.nodes and sentinel.master must be provided in sentinel mode");
}
break;
default:
throw new IllegalArgumentException("Invalid Redis mode. Must be single/cluster/sentinel");
}
}stay factoryIdentifier()Method specifies the identifier of the factory class, which must be filled in when creating a table connector The value of the parameter.
@Override
public String factoryIdentifier() {
return "redis";
}The author introduced in the previous article that Flink SQL uses Java SPI mechanism to discover and load table factory classes. So finally, don't forget to create a file named org. Inf under the META-INF/services directory of classpath apache. flink. table. factories. Factory file and write the fully qualified name of our custom factory class, such as: org apache. flink. streaming. connectors. redis. dynamic. RedisDynamicTableFactory.
Implementing RedisDynamicTableSink
Bahir Flink project has provided RedisSink based on DataStream API. We can use it to directly build RedisDynamicTableSink and reduce repetitive work. The class skeleton that implements the DynamicTableSink interface is as follows.
public class RedisDynamicTableSink implements DynamicTableSink {
private final ReadableConfig options;
private final TableSchema schema;
public RedisDynamicTableSink(ReadableConfig options, TableSchema schema) {
this.options = options;
this.schema = schema;
}
@Override
public ChangelogMode getChangelogMode(ChangelogMode changelogMode) { }
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) { }
@Override
public DynamicTableSink copy() { }
@Override
public String asSummaryString() { }
}getChangelogMode()Method needs to return this Sink Acceptable change log The category of the row. Due to Redis The written data can be appended only or with fallback semantics (such as various aggregated data), so it is supported INSERT,UPDATE_BEFORE and UPDATE_AFTER Category.
@Override
public ChangelogMode getChangelogMode(ChangelogMode changelogMode) {
return ChangelogMode.newBuilder()
.addContainedKind(RowKind.INSERT)
.addContainedKind(RowKind.UPDATE_BEFORE)
.addContainedKind(RowKind.UPDATE_AFTER)
.build();
}Next, you need to implement the SinkRuntimeProvider, that is, write the SinkFunction for the underlying runtime to call. Since RedisSink is already a ready-made SinkFunction, we only need to write a general RedisMapper and do some pre verification work (such as the number of columns and data types of the checklist). The code of getSinkRuntimeProvider() method and RedisMapper is as follows, which is easy to understand.
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
Preconditions.checkNotNull(options, "No options supplied");
FlinkJedisConfigBase jedisConfig = Util.getFlinkJedisConfig(options);
Preconditions.checkNotNull(jedisConfig, "No Jedis config supplied");
RedisCommand command = RedisCommand.valueOf(options.get(COMMAND).toUpperCase());
int fieldCount = schema.getFieldCount();
if (fieldCount != (needAdditionalKey(command) ? 3 : 2)) {
throw new ValidationException("Redis sink only supports 2 or 3 columns");
}
DataType[] dataTypes = schema.getFieldDataTypes();
for (int i = 0; i < fieldCount; i++) {
if (!dataTypes[i].getLogicalType().getTypeRoot().equals(LogicalTypeRoot.VARCHAR)) {
throw new ValidationException("Redis connector only supports STRING type");
}
}
RedisMapper<RowData> mapper = new RedisRowDataMapper(options, command);
RedisSink<RowData> redisSink = new RedisSink<>(jedisConfig, mapper);
return SinkFunctionProvider.of(redisSink);
}
private static boolean needAdditionalKey(RedisCommand command) {
return command.getRedisDataType() == RedisDataType.HASH || command.getRedisDataType() == RedisDataType.SORTED_SET;
}
public static final class RedisRowDataMapper implements RedisMapper<RowData> {
private static final long serialVersionUID = 1L;
private final ReadableConfig options;
private final RedisCommand command;
public RedisRowDataMapper(ReadableConfig options, RedisCommand command) {
this.options = options;
this.command = command;
}
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(command, "default-additional-key");
}
@Override
public String getKeyFromData(RowData data) {
return data.getString(needAdditionalKey(command) ? 1 : 0).toString();
}
@Override
public String getValueFromData(RowData data) {
return data.getString(needAdditionalKey(command) ? 2 : 1).toString();
}
@Override
public Optional<String> getAdditionalKey(RowData data) {
return needAdditionalKey(command) ? Optional.of(data.getString(0).toString()) : Optional.empty();
}
@Override
public Optional<Integer> getAdditionalTTL(RowData data) {
return options.getOptional(TTL_SEC);
}
}The rest copy()and asSummaryString()The method is simple.
@Override
public DynamicTableSink copy() {
return new RedisDynamicTableSink(options, schema);
}
@Override
public String asSummaryString() {
return "Redis Dynamic Table Sink";
}Implementing RedisDynamicTableSource
Different from DynamicTableSink, DynamicTableSource is divided into two categories according to its characteristics, namely ScanTableSource and LookupTableSource. As the name suggests, the former can scan all or part of the data in the external system, and supports features such as predicate push down and partition push down; The latter will not perceive the full picture of the data in the external system, but will execute the point query and return the results according to one or more key s.
Considering that Redis is generally used as a dimension Library in the data warehouse system, what we need to implement is the LookupTableSource interface. The RedisDynamicTableSource class that implements this interface is shown below, and its general structure is similar to Sink.
public class RedisDynamicTableSource implements LookupTableSource {
private final ReadableConfig options;
private final TableSchema schema;
public RedisDynamicTableSource(ReadableConfig options, TableSchema schema) {
this.options = options;
this.schema = schema;
}
@Override
public LookupRuntimeProvider getLookupRuntimeProvider(LookupContext context) {
Preconditions.checkArgument(context.getKeys().length == 1 && context.getKeys()[0].length == 1, "Redis source only supports lookup by single key");
int fieldCount = schema.getFieldCount();
if (fieldCount != 2) {
throw new ValidationException("Redis source only supports 2 columns");
}
DataType[] dataTypes = schema.getFieldDataTypes();
for (int i = 0; i < fieldCount; i++) {
if (!dataTypes[i].getLogicalType().getTypeRoot().equals(LogicalTypeRoot.VARCHAR)) {
throw new ValidationException("Redis connector only supports STRING type");
}
}
return TableFunctionProvider.of(new RedisRowDataLookupFunction(options));
}
@Override
public DynamicTableSource copy() {
return new RedisDynamicTableSource(options, schema);
}
@Override
public String asSummaryString() {
return "Redis Dynamic Table Source";
}
}according to Flink The requirements of the framework itself are used to execute point queries LookupRuntimeProvider Must be TableFunction(Synchronization) or AsyncTableFunction(Asynchronous). because Bahir Flink Adopted by the project Jedis It is a synchronous client, so this paper only gives the implementation of the synchronous version, and the asynchronous version can be replaced with other clients (such as Redisson or Vert.x Redis Client). RedisRowDataLookupFunction The code is as follows.
public static class RedisRowDataLookupFunction extends TableFunction<RowData> {
private static final long serialVersionUID = 1L;
private final ReadableConfig options;
private final String command;
private final String additionalKey;
private final int cacheMaxRows;
private final int cacheTtlSec;
private RedisCommandsContainer commandsContainer;
private transient Cache<RowData, RowData> cache;
public RedisRowDataLookupFunction(ReadableConfig options) {
Preconditions.checkNotNull(options, "No options supplied");
this.options = options;
command = options.get(COMMAND).toUpperCase();
Preconditions.checkArgument(command.equals("GET") || command.equals("HGET"), "Redis table source only supports GET and HGET commands");
additionalKey = options.get(LOOKUP_ADDITIONAL_KEY);
cacheMaxRows = options.get(LOOKUP_CACHE_MAX_ROWS);
cacheTtlSec = options.get(LOOKUP_CACHE_TTL_SEC);
}
@Override
public void open(FunctionContext context) throws Exception {
super.open(context);
FlinkJedisConfigBase jedisConfig = Util.getFlinkJedisConfig(options);
commandsContainer = RedisCommandsContainerBuilder.build(jedisConfig);
commandsContainer.open();
if (cacheMaxRows > 0 && cacheTtlSec > 0) {
cache = CacheBuilder.newBuilder()
.expireAfterWrite(cacheTtlSec, TimeUnit.SECONDS)
.maximumSize(cacheMaxRows)
.build();
}
}
@Override
public void close() throws Exception {
if (cache != null) {
cache.invalidateAll();
}
if (commandsContainer != null) {
commandsContainer.close();
}
super.close();
}
public void eval(Object obj) {
RowData lookupKey = GenericRowData.of(obj);
if (cache != null) {
RowData cachedRow = cache.getIfPresent(lookupKey);
if (cachedRow != null) {
collect(cachedRow);
return;
}
}
StringData key = lookupKey.getString(0);
String value = command.equals("GET") ? commandsContainer.get(key.toString()) : commandsContainer.hget(additionalKey, key.toString());
RowData result = GenericRowData.of(key, StringData.fromString(value));
cache.put(lookupKey, result);
collect(result);
}
}There are three points to note:
- Redis dimension data is generally stored in String or Hash type, so the command supports GET and HGET. If the Hash type is used, its key needs to be passed in the parameter, and cannot be specified dynamically like Sink;
- In order to avoid every piece of data requesting Redis, a cache needs to be designed, which uses Guava Cache. Data that cannot be found in Redis should also be cached to prevent penetration;
- TableFunction must have a signature of eval(Object) or eval(Object...) Methods. In this example, the actual output data type is row < string, string >, which should be expressed as RowData(StringData, StringData) in the type system of Flink Table.
Using Redis SQL Connector
Let's apply it in practice. The structure of a Redis Sink table created first.
CREATE TABLE rtdw_dws.redis_test_order_stat_dashboard ( hashKey STRING, cityId STRING, data STRING, PRIMARY KEY (hashKey) NOT ENFORCED ) WITH ( 'connector' = 'redis', 'mode' = 'single', 'single.host' = '172.16.200.124', 'single.port' = '6379', 'db-num' = '10', 'command' = 'HSET', 'ttl-sec' = '86400', 'connection.max-total' = '5', 'connection.timeout-ms' = '5000', 'connection.test-while-idle' = 'true' )
Then read Kafka In the order flow, count some simple data and write it Redis.
/*
tableEnvConfig.setBoolean("table.dynamic-table-options.enabled", true)
tableEnvConfig.setBoolean("table.exec.emit.early-fire.enabled", true)
tableEnvConfig.setString("table.exec.emit.early-fire.delay", "5s")
tableEnv.createTemporarySystemFunction("MapToJsonString", classOf[MapToJsonString])
*/
INSERT INTO rtdw_dws.redis_test_order_stat_dashboard
SELECT
CONCAT('dashboard:city_stat:', p.orderDay) AS hashKey,
CAST(p.cityId AS STRING) AS cityId,
MapToJsonString(MAP[
'subOrderNum', CAST(p.subOrderNum AS STRING),
'buyerNum', CAST(p.buyerNum AS STRING),
'gmv', CAST(p.gmv AS STRING)
]) AS data
FROM (
SELECT
cityId,
SUBSTR(tss, 0, 10) AS orderDay,
COUNT(1) AS subOrderNum,
COUNT(DISTINCT userId) AS buyerNum,
SUM(quantity * merchandisePrice) AS gmv
FROM rtdw_dwd.kafka_order_done_log /*+ OPTIONS('scan.startup.mode'='latest-offset','properties.group.id'='fsql_redis_test_order_stat_dashboard') */
GROUP BY TUMBLE(procTime, INTERVAL '1' DAY), cityId, SUBSTR(tss, 0, 10)
) pObservation results~
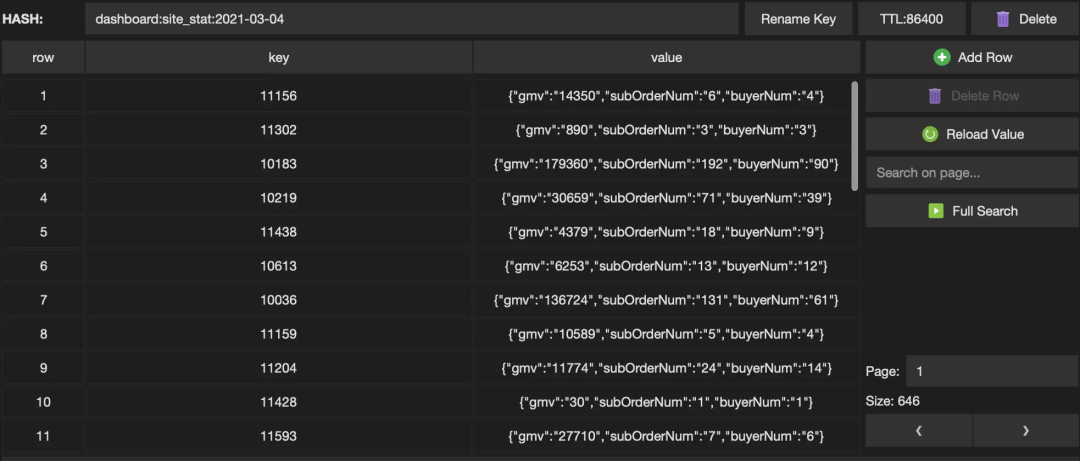
Let's take another look at the use of Redis as a dimension table, still taking the Hash structure as an example.
CREATE TABLE rtdw_dim.redis_test_city_info ( cityId STRING, cityName STRING ) WITH ( 'connector' = 'redis', 'mode' = 'single', 'single.host' = '172.16.200.124', 'single.port' = '6379', 'db-num' = '9', 'command' = 'HGET', 'connection.timeout-ms' = '5000', 'connection.test-while-idle' = 'true', 'lookup.additional-key' = 'rtdw_dim:test_city_info', 'lookup.cache.max-rows' = '1000', 'lookup.cache.ttl-sec' = '600' )
To facilitate observation, create a Print Sink Output data from the table, and then Kafka Flow table and Redis Dimension table making Temporal Join,SQL The statement is as follows.
CREATE TABLE test.print_redis_test_dim_join (
tss STRING,
cityId BIGINT,
cityName STRING
) WITH (
'connector' = 'print'
)
INSERT INTO test.print_redis_test_dim_join
SELECT a.tss, a.cityId, b.cityName
FROM rtdw_dwd.kafka_order_done_log /*+ OPTIONS('scan.startup.mode'='latest-offset','properties.group.id'='fsql_redis_source_test') */ AS a
LEFT JOIN rtdw_dim.redis_test_city_info FOR SYSTEM_TIME AS OF a.procTime AS b ON CAST(a.cityId AS STRING) = b.cityId
WHERE a.orderType = 12View output~
4> +I(2021-03-04 20:44:48,10264,Zhangzhou City) 3> +I(2021-03-04 20:45:26,10030,Changde City) 4> +I(2021-03-04 20:45:23,10332,Guilin City) 7> +I(2021-03-04 20:45:26,10031,Jiujiang City) 9> +I(2021-03-04 20:45:23,10387,Huizhou City) 4> +I(2021-03-04 20:45:19,10607,Wuhu City) 3> +I(2021-03-04 20:45:25,10364,Wuxi City)
The End
Through the above example, I believe that the viewer can flexibly customize the Flink SQL Connector according to their own needs. ScanTableSource, asynchronous LookupTableSource and Encoding/Decoding Format that are not detailed in this article will also be explained in a later article.