Link from AI Studio project https://aistudio.baidu.com/aistudio/projectdetail/2432755
Project background
I recently found that there was no good example when I read the resnet50+FPN version of Faster-RCNN when I was preloading and loading data, when I read the class loaded by paddlepaddle's official data.
So I did this today, how to make a data loader to read the standard Voc2012 data, and then I will use my own data set to do a custom data reading
Paddy dataset definition and loading document
Introduction to VOC dataset
The Pascal VOC data set provided by ai studio is used this time
Pascal VOC dataset, including voc2007 and voc2012 data, is mainly used for visual tasks such as target detection and semantic separation
The following is the structure of Pascal VOC dataset directory
.
└── VOCdevkit #root directory
└── VOC2012 #For data sets of different years, only 2012 and other years such as 2007 are downloaded here
├── Annotations #Store xml files, correspond to the pictures in JPEGImages one by one, explain the contents of the pictures, and so on
├── ImageSets #All stored in this directory are txt files. Each line in the txt file contains the name of a picture, and ± 1 will be added at the end to represent positive and negative samples
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages #Store source pictures
├── SegmentationClass #It stores pictures, which are related to semantic segmentation
└── SegmentationObject #Images are stored, and instance segmentation is related
Here we will use the VOC2012 data set
Because fast RCNN is used for target detection, we will use the train in the Main of Annotations, JPEGImages, and ImageSets Txt and val.txt
Annotations is the directory where the xml files are stored
JPEGImages directory where image files are stored
train.txt to store the name of the training file
val.txt TXT TXT for storing the name of the verification file
First, we decompress the Pascal VOC data set
!unzip -oq data/data4379/pascalvoc.zip
Because we only use VOC2012 here, move the VOC2012 folder to the root directory
!mv pascalvoc/VOCdevkit/VOC2012 ./
Custom dataset parsing
paddlepaddle official provides a very simple case of custom dataset.
import paddle
from paddle.io import Dataset
BATCH_SIZE = 64
BATCH_NUM = 20
IMAGE_SIZE = (28, 28)
CLASS_NUM = 10
class MyDataset(Dataset):
"""
Step 1: inherit paddle.io.Dataset class
"""
def __init__(self, num_samples):
"""
Step 2: implement the constructor and define the size of the dataset
"""
super(MyDataset, self).__init__()
self.num_samples = num_samples
def __getitem__(self, index):
"""
Step 3: Implement__getitem__Method, defining and specifying index How to obtain data and return a single piece of data (training data, corresponding label)
"""
data = paddle.uniform(IMAGE_SIZE, dtype='float32')
label = paddle.randint(0, CLASS_NUM-1, dtype='int64')
return data, label
def __len__(self):
"""
Step 4: Implement__len__Method to return the total number of data sets
"""
return self.num_samples
# Test defined dataset
custom_dataset = MyDataset(BATCH_SIZE * BATCH_NUM)
print('=============custom dataset=============')
for data, label in custom_dataset:
print(data.shape, label.shape)
break
We can implement it step by step according to his appearance
Create a class and define it
# Define the data reading class and inherit the paddle io. Dataset class VOCDataset(paddle.io.Dataset):
Implement the constructor to define the data set reading path
In__ init__ Method, we need to define the path to read each folder of VOC2012
At the same time, you also need to read the category file of VOC2012 dataset
I put the category file of VOC2012 dataset in the root directory
Path: pascal_voc_classes.json
def __init__(self,voc_root, year='2012',transforms=None, txt_name:str = 'train.txt'):
assert year in ['2007','2012'], "year must be in ['2007','2012']"
self.root = os.path.join(voc_root,f"VOC{year}")
self.img_root = os.path.join(self.root,'JPEGImages')
self.annotations_root = os.path.join(self.root,'Annotations')
txt_path = os.path.join(self.root,"ImageSets",'Main',txt_name)
assert os.path.exists(txt_path),'not found {} file'.format(txt_name)
with open(txt_path) as read:
self.xml_list = [os.path.join(self.annotations_root,line.strip()+'.xml')
for line in read.readlines() if len(line.strip()) >0 ]
#check file
assert len(self.xml_list) > 0, "in '{}' file does not find any information.".format(txt_path)
for xml_path in self.xml_list:
assert os.path.exists(xml_path), "not found '{}' file.".format(xml_path)
# read class_indict
json_file = './pascal_voc_classes.json'
assert os.path.exists(json_file), "{} file not exist.".format(json_file)
json_file = open(json_file, 'r')
self.class_dict = json.load(json_file)
json_file.close()
self.transforms = transforms
Realize__ getitem__ Method to define how to obtain data when specifying index and return a single piece of data (training data, corresponding label)
def __getitem__(self, idx):
# read xml
xml_path = self.xml_list[idx]
with open(xml_path) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = self.parse_xml_to_dict(xml)["annotation"]
img_path = os.path.join(self.img_root, data["filename"])
image = Image.open(img_path)
if image.format != "JPEG":
raise ValueError("Image '{}' format not JPEG".format(img_path))
boxes = []
labels = []
iscrowd = []
assert "object" in data, "{} lack of object information.".format(xml_path)
for obj in data["object"]:
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
# Further check the data. There may be cases where w or h is 0 in some annotation information. Such data will cause the calculated regression loss to be nan
if xmax <= xmin or ymax <= ymin:
print("Warning: in '{}' xml, there are some bbox w/h <=0".format(xml_path))
continue
boxes.append([xmin, ymin, xmax, ymax])
labels.append(self.class_dict[obj["name"]])
if "difficult" in obj:
iscrowd.append(int(obj["difficult"]))
else:
iscrowd.append(0)
# convert everything into a paddle.Tensor
boxes = paddle.to_tensor(boxes).astype('float32')
labels = paddle.to_tensor(labels).astype('int32')
iscrowd = paddle.to_tensor(iscrowd, dtype=paddle.int64)
image_id = paddle.to_tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
image, target = self.transforms(image, target)
return image, target
def parse_xml_to_dict(self, xml):
"""
take xml The document is parsed into dictionary form for reference tensorflow of recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # Traverse the bottom layer and directly return the information corresponding to the tag
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = self.parse_xml_to_dict(child) # Recursive traversal of label information
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # Because there may be multiple object s, they need to be placed in the list
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
parse_ xml_ to_ Data returned by dict method
{'filename': '2010_001142.jpg', 'folder': 'VOC2012', 'object': [{'name': 'bottle', 'bndbox': {'xmax': '282', 'xmin': '264', 'ymax': '244', 'ymin': '210'}, 'difficult': '0', 'occluded': '0', 'pose': 'Unspecified', 'truncated': '0'}, {'name': 'bottle', 'bndbox': {'xmax': '308', 'xmin': '295', 'ymax': '184', 'ymin': '162'}, 'difficult': '1', 'occluded': '0', 'pose': 'Unspecified', 'truncated': '0'}, {'name': 'bottle', 'bndbox': {'xmax': '270', 'xmin': '254', 'ymax': '224', 'ymin': '196'}, 'difficult': '1', 'occluded': '0', 'pose': 'Unspecified', 'truncated': '1'}, {'name': 'bottle', 'bndbox': {'xmax': '292', 'xmin': '281', 'ymax': '225', 'ymin': '204'}, 'difficult': '1', 'occluded': '0', 'pose': 'Unspecified', 'truncated': '1'}, {'name': 'bottle', 'bndbox': {'xmax': '221', 'xmin': '212', 'ymax': '227', 'ymin': '208'}, 'difficult': '1', 'occluded': '0', 'pose': 'Unspecified', 'truncated': '0'}, {'name': 'person', 'bndbox': {'xmax': '371', 'xmin': '315', 'ymax': '220', 'ymin': '103'}, 'difficult': '0', 'occluded': '1', 'pose': 'Frontal', 'truncated': '1'}, {'name': 'person', 'bndbox': {'xmax': '379', 'xmin': '283', 'ymax': '342', 'ymin': '171'}, 'difficult': '0', 'occluded': '0', 'pose': 'Left', 'truncated': '0'}, {'name': 'person', 'bndbox': {'xmax': '216', 'xmin': '156', 'ymax': '260', 'ymin': '180'}, 'difficult': '0', 'occluded': '1', 'pose': 'Right', 'truncated': '1'}, {'name': 'person', 'bndbox': {'xmax': '223', 'xmin': '205', 'ymax': '198', 'ymin': '172'}, 'difficult': '1', 'occluded': '1', 'pose': 'Frontal', 'truncated': '1'}, {'name': 'person', 'bndbox': {'xmax': '280', 'xmin': '218', 'ymax': '234', 'ymin': '155'}, 'difficult': '0', 'occluded': '1', 'pose': 'Right', 'truncated': '1'}, {'name': 'person', 'bndbox': {'xmax': '343', 'xmin': '292', 'ymax': '241', 'ymin': '185'}, 'difficult': '1', 'occluded': '1', 'pose': 'Left', 'truncated': '1'}], 'segmented': '0', 'size': {'depth': '3', 'height': '375', 'width': '500'}, 'source': {'annotation': 'PASCAL VOC2010', 'database': 'The VOC2010 Database', 'image': 'flickr'}}
!pip install lxml
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already satisfied: lxml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (4.8.0) [33mWARNING: You are using pip version 21.3.1; however, version 22.0.3 is available. You should consider upgrading via the '/opt/conda/envs/python35-paddle120-env/bin/python -m pip install --upgrade pip' command.[0m
import paddle
import os
import json
from PIL import Image
from lxml import etree
# Define the data reading class and inherit the paddle io. Dataset
class VOCDataset(paddle.io.Dataset):
def __init__(self,voc_root, year='2012',transforms=None, txt_name:str = 'train.txt'):
assert year in ['2007','2012'], "year must be in ['2007','2012']"
self.root = os.path.join(voc_root,f"VOC{year}")
self.img_root = os.path.join(self.root,'JPEGImages')
self.annotations_root = os.path.join(self.root,'Annotations')
txt_path = os.path.join(self.root,"ImageSets",'Main',txt_name)
assert os.path.exists(txt_path),'not found {} file'.format(txt_name)
with open(txt_path) as read:
self.xml_list = [os.path.join(self.annotations_root,line.strip()+'.xml')
for line in read.readlines() if len(line.strip()) >0 ]
#check file
assert len(self.xml_list) > 0, "in '{}' file does not find any information.".format(txt_path)
for xml_path in self.xml_list:
assert os.path.exists(xml_path), "not found '{}' file.".format(xml_path)
# read class_indict
json_file = './pascal_voc_classes.json'
assert os.path.exists(json_file), "{} file not exist.".format(json_file)
json_file = open(json_file, 'r')
self.class_dict = json.load(json_file)
json_file.close()
self.transforms = transforms
def __len__(self):
return len(self.xml_list)
def __getitem__(self, idx):
# read xml
xml_path = self.xml_list[idx]
with open(xml_path) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = self.parse_xml_to_dict(xml)["annotation"]
img_path = os.path.join(self.img_root, data["filename"])
image = Image.open(img_path)
if image.format != "JPEG":
raise ValueError("Image '{}' format not JPEG".format(img_path))
boxes = []
labels = []
iscrowd = []
assert "object" in data, "{} lack of object information.".format(xml_path)
for obj in data["object"]:
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
# Further check the data. There may be cases where w or h is 0 in some annotation information. Such data will cause the calculated regression loss to be nan
if xmax <= xmin or ymax <= ymin:
print("Warning: in '{}' xml, there are some bbox w/h <=0".format(xml_path))
continue
boxes.append([xmin, ymin, xmax, ymax])
labels.append(self.class_dict[obj["name"]])
if "difficult" in obj:
iscrowd.append(int(obj["difficult"]))
else:
iscrowd.append(0)
# convert everything into a paddle.Tensor
boxes = paddle.to_tensor(boxes).astype('float32')
labels = paddle.to_tensor(labels).astype('int32')
iscrowd = paddle.to_tensor(iscrowd, dtype=paddle.int64)
image_id = paddle.to_tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
image, target = self.transforms(image, target)
return image, target
def parse_xml_to_dict(self, xml):
"""
take xml The document is parsed into dictionary form for reference tensorflow of recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # Traverse the bottom layer and directly return the information corresponding to the tag
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = self.parse_xml_to_dict(child) # Recursive traversal of label information
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # Because there may be multiple object s, they need to be placed in the list
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
def collate_fn(batch):
return tuple(zip(*batch))
with open('VOC2012/ImageSets/Main/train.txt') as t:
pass
train_dataset = VOCDataset('./', "2012")
print(train_dataset.class_dict)
{'aeroplane': 1, 'bicycle': 2, 'bird': 3, 'boat': 4, 'bottle': 5, 'bus': 6, 'car': 7, 'cat': 8, 'chair': 9, 'cow': 10, 'diningtable': 11, 'dog': 12, 'horse': 13, 'motorbike': 14, 'person': 15, 'pottedplant': 16, 'sheep': 17, 'sofa': 18, 'train': 19, 'tvmonitor': 20}
VOC read test
import paddle.vision.transforms as transforms
from draw_box_utils import draw_box
from PIL import Image
import json
import matplotlib.pyplot as plt
import random
# read class_indict
category_index = {}
try:
json_file = open('./pascal_voc_classes.json', 'r')
class_dict = json.load(json_file)
category_index = {v: k for k, v in class_dict.items()}
except Exception as e:
print(e)
exit(-1)
data_transform = {
"train": transforms.Compose([transforms.ToTensor(),
transforms.RandomHorizontalFlip(0.5)]),
"val": transforms.Compose([transforms.ToTensor()])
}
# load train data set
train_data_set = VOCDataset('./', "2012")
print(len(train_data_set))
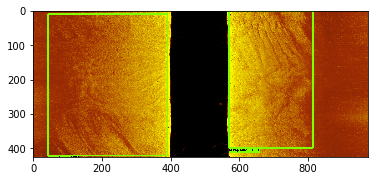
for index in random.sample(range(0, len(train_data_set)), k=5):
img, target = train_data_set[index]
draw_box(img,
target["boxes"].numpy(),
target["labels"].numpy(),
[1 for i in range(len(target["labels"].numpy()))],
category_index,
thresh=0.5,
line_thickness=5)
plt.imshow(img)
plt.show()
5717





Class VOC data
!unzip -oq data/data106197/voc.zip
import paddle
import os
import json
from PIL import Image
from lxml import etree
# Define the data reading class and inherit the paddle io. Dataset
class Selfataset(paddle.io.Dataset):
def __init__(self,voc_root,transforms=None,txt_name:str = 'train.txt'):
self.root =voc_root
self.img_root = os.path.join(self.root,'JPEGImages')
self.annotations_root = os.path.join(self.root,'Annotations')
txt_path = os.path.join(self.root,txt_name)
print(txt_path)
assert os.path.exists(txt_path),'not found {} file'.format(txt_name)
#self.xml_list = [os.path.join(self.annotations_root,line.strip()+'.xml')
#for line in read.readlines() if len(line.strip()) >0 ]
self.image_list = []
self.xml_list = []
with open(txt_path) as read:
self.path_list = [line.strip() for line in read.readlines() if len(line.strip()) >0 ]
for path in self.path_list:
self.image_list.append(os.path.join(self.root,path.split(' ')[0]))
self.xml_list.append(os.path.join(self.root,path.split(' ')[1]))
assert len(self.xml_list) > 0, "in '{}' file does not find any information.".format(txt_path)
for xml_path in self.xml_list:
assert os.path.exists(xml_path), "not found '{}' file.".format(xml_path)
#read class
self.class_dict = {}
self.class_path = os.path.join(self.root,'labels.txt')
print(self.class_path)
with open(self.class_path) as read:
self.classes = [class_name.strip() for class_name in read.readlines() ]
print(self.classes)
for number,class_name in enumerate(self.classes,1):
self.class_dict[class_name] = number
self.transforms = transforms
def __len__(self):
return len(self.xml_list)
def __getitem__(self, idx):
# read xml
xml_path = self.xml_list[idx]
with open(xml_path) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = self.parse_xml_to_dict(xml)["annotation"]
#print(data)
img_path = os.path.join(self.img_root, data["frame"]+'.jpg')
image = Image.open(img_path)
#if image.format != "JPEG":
#raise ValueError("Image '{}' format not JPEG".format(img_path))
boxes = []
labels = []
iscrowd = []
assert "object" in data, "{} lack of object information.".format(xml_path)
for obj in data["object"]:
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
# Further check the data. There may be cases where w or h is 0 in some annotation information. Such data will cause the calculated regression loss to be nan
if xmax <= xmin or ymax <= ymin:
print("Warning: in '{}' xml, there are some bbox w/h <=0".format(xml_path))
continue
boxes.append([xmin, ymin, xmax, ymax])
labels.append(self.class_dict[obj["name"]])
if "difficult" in obj:
iscrowd.append(int(obj["difficult"]))
else:
iscrowd.append(0)
# convert everything into a paddle.Tensor
boxes = paddle.to_tensor(boxes).astype('float32')
labels = paddle.to_tensor(labels).astype('int32')
iscrowd = paddle.to_tensor(iscrowd, dtype=paddle.int64)
image_id = paddle.to_tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
image, target = self.transforms(image, target)
return image, target
def parse_xml_to_dict(self, xml):
"""
take xml The document is parsed into dictionary form for reference tensorflow of recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # Traverse the bottom layer and directly return the information corresponding to the tag
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = self.parse_xml_to_dict(child) # Recursive traversal of label information
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # Because there may be multiple object s, they need to be placed in the list
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
def collate_fn(batch):
return tuple(zip(*batch))
a = Selfataset('voc',None,'train_list.txt')
voc/train_list.txt voc/labels.txt ['flv', 'gx', 'mbw']
a.class_dict
{'flv': 1, 'gx': 2, 'mbw': 3}
import paddle.vision.transforms as transforms
from draw_box_utils import draw_box
from PIL import Image
import json
import matplotlib.pyplot as plt
import random
# read class_indict
category_index = {}
try:
json_file = open('./pascal_voc_classes.json', 'r')
class_dict = json.load(json_file)
category_index = {v: k for k, v in class_dict.items()}
except Exception as e:
print(e)
exit(-1)
data_transform = {
"train": transforms.Compose([transforms.ToTensor(),
transforms.RandomHorizontalFlip(0.5)]),
"val": transforms.Compose([transforms.ToTensor()])
}
# load train data set
train_data_set = Selfataset('voc',None,'train_list.txt')
print(len(train_data_set))
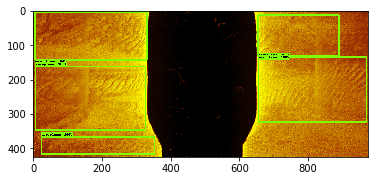
for index in random.sample(range(0, len(train_data_set)), k=5):
img, target = train_data_set[index]
draw_box(img,
target["boxes"].numpy(),
target["labels"].numpy(),
[1 for i in range(len(target["labels"].numpy()))],
category_index,
thresh=0.6,
line_thickness=5)
plt.imshow(img)
plt.show()
# targetn = []
# for index in range(0, len(train_data_set)):
# try:
# img, target = train_data_set[index]
# targetn.append(target["labels"].numpy())
# except:
# pass
voc/train_list.txt voc/labels.txt ['flv', 'gx', 'mbw'] 1216