Simple wordCount
Suppose there are some data in our file:
spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop spark spark hive hadoop
Let's count the number of occurrences of each word:
object WordCountSortWithinPartition {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("datas/words.txt")
val reducedRDD: RDD[(String, Int)] = fileRDD.map((_,1)).reduceByKey(_+_,3)
reducedRDD.saveAsTextFile("wordcount-partition-out")
sc.stop()
}
}
This is a wordCount program.
But I used three partitions:
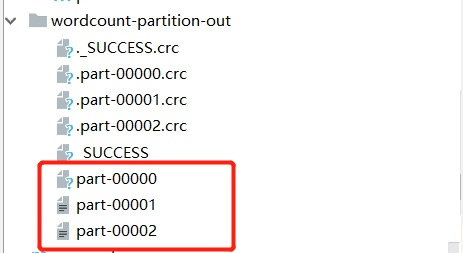
Since the default partition is HashPartitioner, only two files have data, because spark and hive run to one partition:
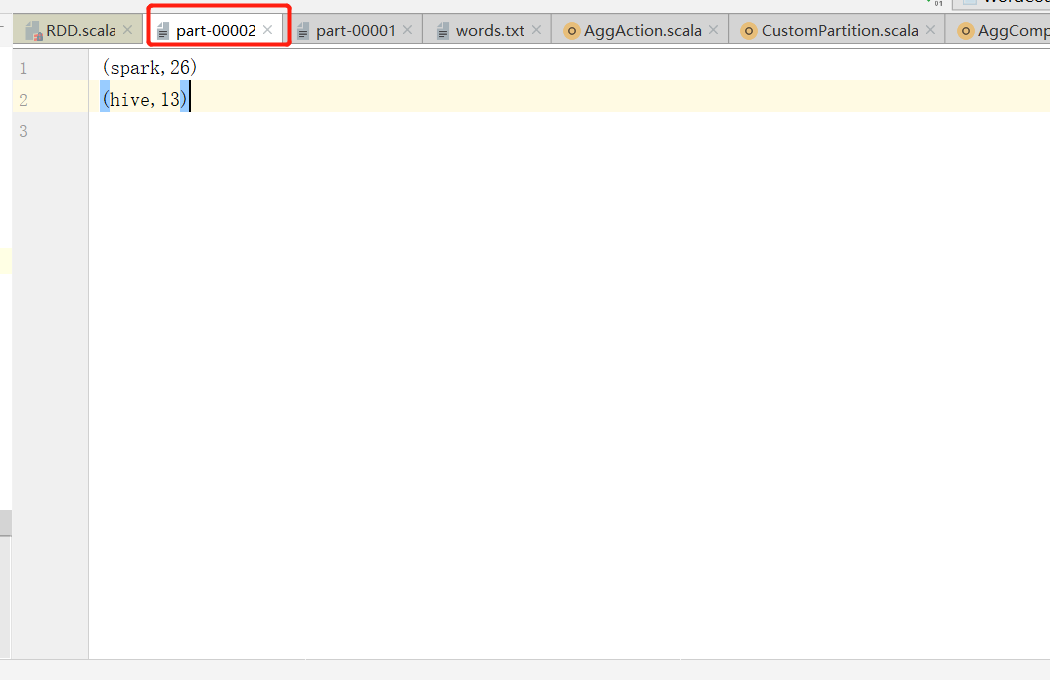
Redefining the partitioner can change the partition result and often solve the problem of data skew. Now let's use a custom partition to make spark, hive and Hadoop in three different partitions.
Custom partition
We want to write a partition. Its function is to divide spark, hive and hadoop into different partitions to demonstrate the idea of solving data skew in actual production.
object WordCountSortWithinPartition {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("datas/words.txt")
val mapRDD: RDD[(String, Int)] = fileRDD.map((_, 1))
val words: Long = fileRDD.distinct().count()
val wordCountPartitioner = new WordCountPartitioner(words.toInt)
val reducedRDD: RDD[(String, Int)] = mapRDD.reduceByKey(wordCountPartitioner, _ + _)
reducedRDD.saveAsTextFile("wordcount-partition-out")
sc.stop()
}
}
class WordCountPartitioner(val words: Int) extends Partitioner {
val wordToIndexMap = Map("hive" -> 0, "spark" -> 1, "hadoop" -> 2)
override def numPartitions: Int = words
override def getPartition(key: Any): Int = {
val word: String = key.asInstanceOf[String]
wordToIndexMap.getOrElse(word, throw new Exception("Word Not Found"))
}
}
Notice that we put the partitioner in reduceByKey, where we can also use partitionBy:
val reducedRDD: RDD[(String, Int)] = mapRDD.reduceByKey( _ + _)
val partitionedRDD: RDD[(String, Int)] = reducedRDD.partitionBy(wordCountPartitioner)
partitionedRDD.saveAsTextFile("wordcount-partition-out")
The disadvantage of doing so is that you need to shuffle again.
In area sorting
I add hbase to the original data, and then put all the items beginning with h into the same partition. The final result is:
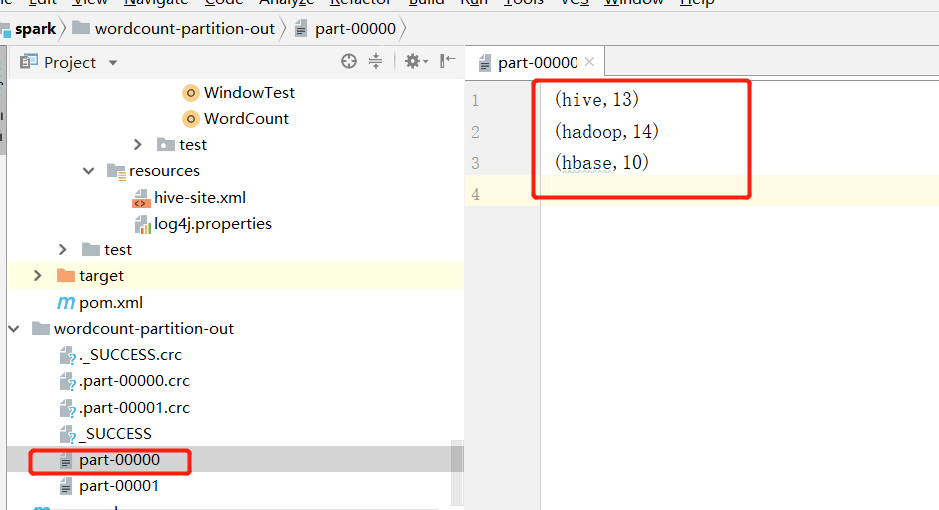
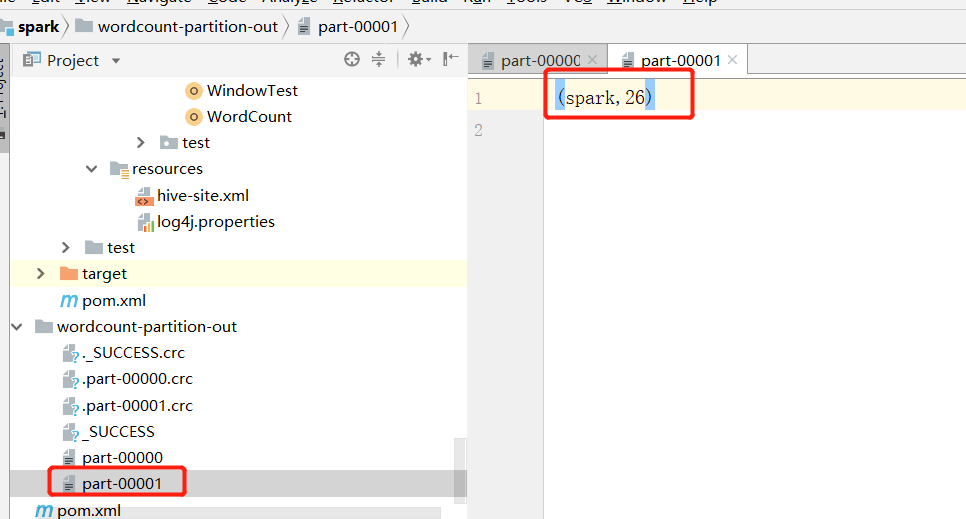
Now I want to sort each partition according to the statistical number of words.
We can imitate takeOrdered:
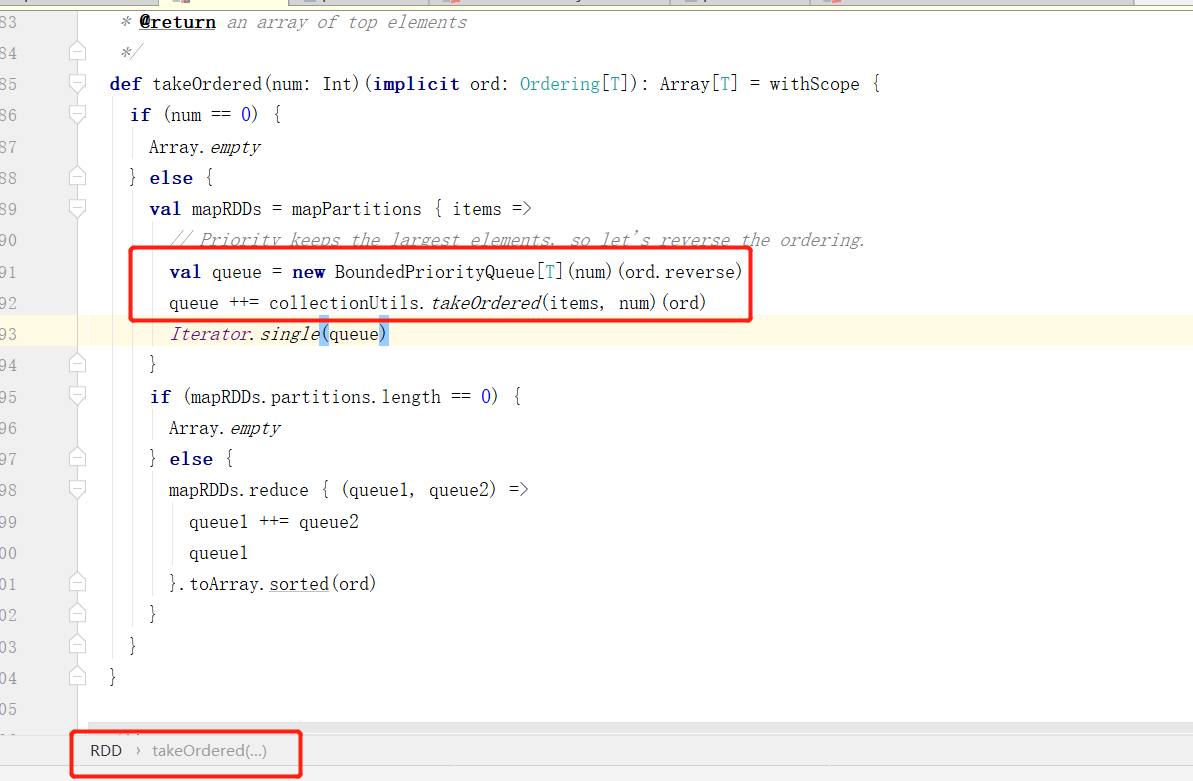
So we write a TreeSet to load the original data and give the sorting rule:
object WordCountSortWithinPartition {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("datas/words.txt")
val mapRDD: RDD[(String, Int)] = fileRDD.map((_, 1))
val wordCountPartitioner = new WordCountPartitioner
val reducedRDD: RDD[(String, Int)] = mapRDD.reduceByKey(wordCountPartitioner, _ + _)
val sortRDD: RDD[(String, Int)] = reducedRDD.mapPartitions(
it => {
implicit val rules: Ordering[(String, Int)] = (x: (String, Int), y: (String, Int)) => {
x._2 - y._2
}
val treeSet = new mutable.TreeSet[(String, Int)]()
it.foreach(
data => {
treeSet += data
}
)
treeSet.iterator
}
)
sortRDD.saveAsTextFile("wordcount-partition-out")
sc.stop()
}
}
class WordCountPartitioner() extends Partitioner {
override def numPartitions: Int = 2
override def getPartition(key: Any): Int = {
val word: String = key.asInstanceOf[String]
if(word.startsWith("h"))0 else 1
}
}
This enables in zone sorting.
repartitionAndSortWithinPartitions
We can directly use the operator repartitionAndSortWithinPartitions to complete the custom partition and sort in the partition.
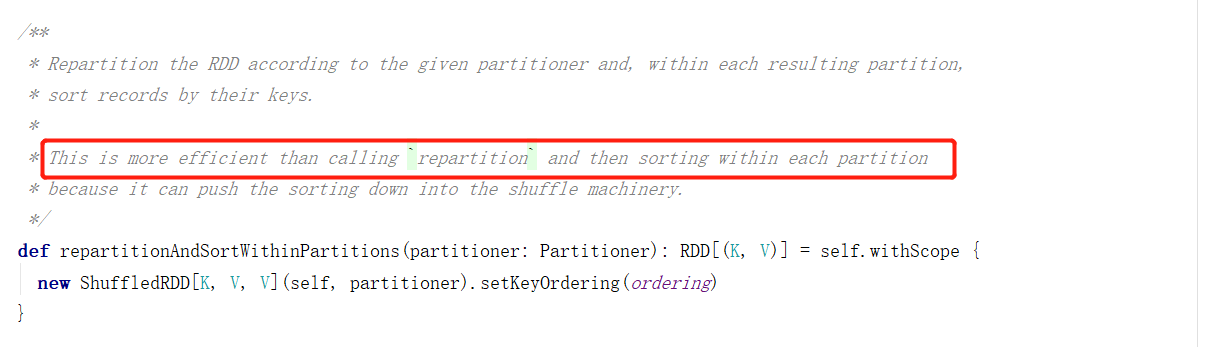
The document says it is more efficient than calling repartition directly and sorting in the area.
However, we need to put the sorted fields into the key, so we also need to do some structural transformation:
object WordCountSortWithinPartition2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("datas/words.txt")
val mapRDD: RDD[(String, Int)] = fileRDD.map((_, 1))
val reducedRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
val mapRDDWithNull: RDD[((String, Int), Null)] = reducedRDD.map(t=>((t._1,t._2), null))
implicit val rules: Ordering[(String, Int)] = (x: (String, Int), y: (String, Int)) => {
x._2 - y._2
}
val repartitionAndSortWithPartitionsRDD: RDD[((String, Int), Null)] = mapRDDWithNull.repartitionAndSortWithinPartitions(new WordCountPartitioner2)
repartitionAndSortWithPartitionsRDD.keys.saveAsTextFile("partition-sort-out")
sc.stop()
}
}
class WordCountPartitioner2() extends Partitioner {
override def numPartitions: Int = 2
override def getPartition(key: Any): Int = {
val word: (String, Int) = key.asInstanceOf[(String, Int)]
if(word._1.startsWith("h"))0 else 1
}
}
Because repartitionAndSortWithinPartitions are called by the underlying ShuffledRDD, we can also directly new a ShuffledRDD:
object WordCountSortWithinPartition2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("datas/words.txt")
val mapRDD: RDD[(String, Int)] = fileRDD.map((_, 1))
val reducedRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
val mapRDDWithNull: RDD[((String, Int), Null)] = reducedRDD.map(t=>((t._1,t._2), null))
implicit val rules: Ordering[(String, Int)] = (x: (String, Int), y: (String, Int)) => {
x._2 - y._2
}
val shuffledRDD: ShuffledRDD[(String, Int), Null, Null] = new ShuffledRDD[(String, Int), Null, Null](mapRDDWithNull, new WordCountPartitioner2)
shuffledRDD.setKeyOrdering(rules)
shuffledRDD.keys.saveAsTextFile("partition-sort-out")
sc.stop()
}
}
class WordCountPartitioner2() extends Partitioner {
override def numPartitions: Int = 2
override def getPartition(key: Any): Int = {
val word: (String, Int) = key.asInstanceOf[(String, Int)]
if(word._1.startsWith("h"))0 else 1
}
}
This can achieve the same effect.