JMM memory model
1. Computer structure
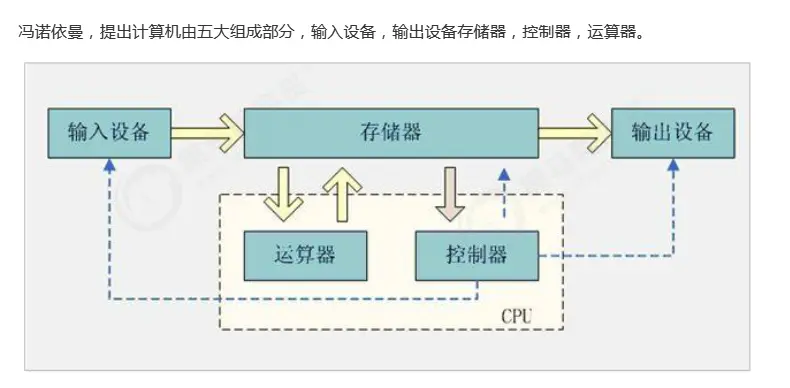
Input device: our mouse and keyboard
Memory: corresponding to our memory, cache
The arithmetic unit and controller together constitute the cpu
Output devices, such as display screens and printers.
Let's focus on caching:
2. Cache
In fact, when we say that computers are inefficient and slow, they are often not the pot of cpu. The problem is that the memory access speed is too slow.
There is a big difference between the operation speed of CPU and the access speed of memory. This causes the CPU to spend a lot of waiting time each time it operates on memory. The reading and writing speed of memory has become the bottleneck of computer operation.
So there is the design of adding cache between CPU and main memory. The cache closest to the CPU is called L1, followed by L2, L3 and main memory.
The CPU cache model is shown in the following figure.
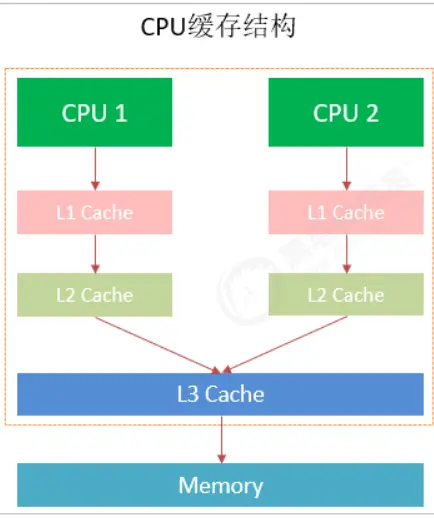
Running speed: l1cache > l2cache > l3cache > memory
Therefore, the system will access L1 cache > L2 cache > L3 cache > memory first
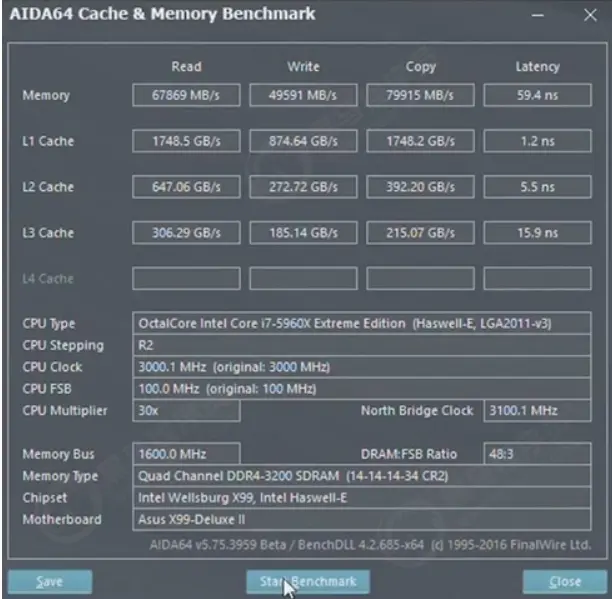
The specific speed is as follows:
3.java memory model concept
JAVA memory model is a memory model defined in the Java virtual machine specification. JAVA memory model is standardized and shields the differences between different underlying computers.
JAVA memory model is a set of specifications, which describes the access rules of various variables (thread shared variables) in Java programs, as well as the underlying details of storing variables into memory and reading variables from memory in JVM.
The details are as follows:
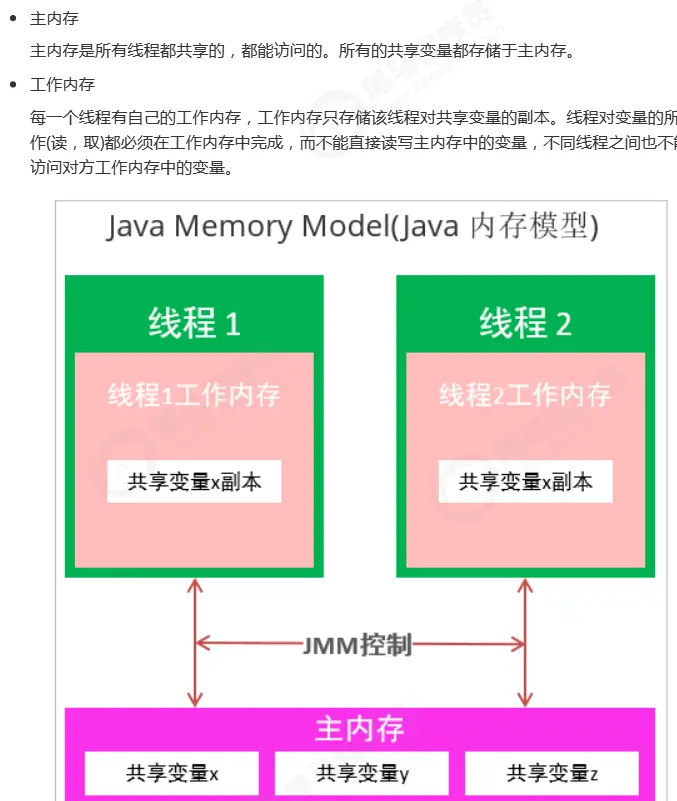
The Java memory model is shown above: it defines the concepts of working memory and main memory and their interaction.
Rules and guarantees for the visibility, order and atomicity of shared data.
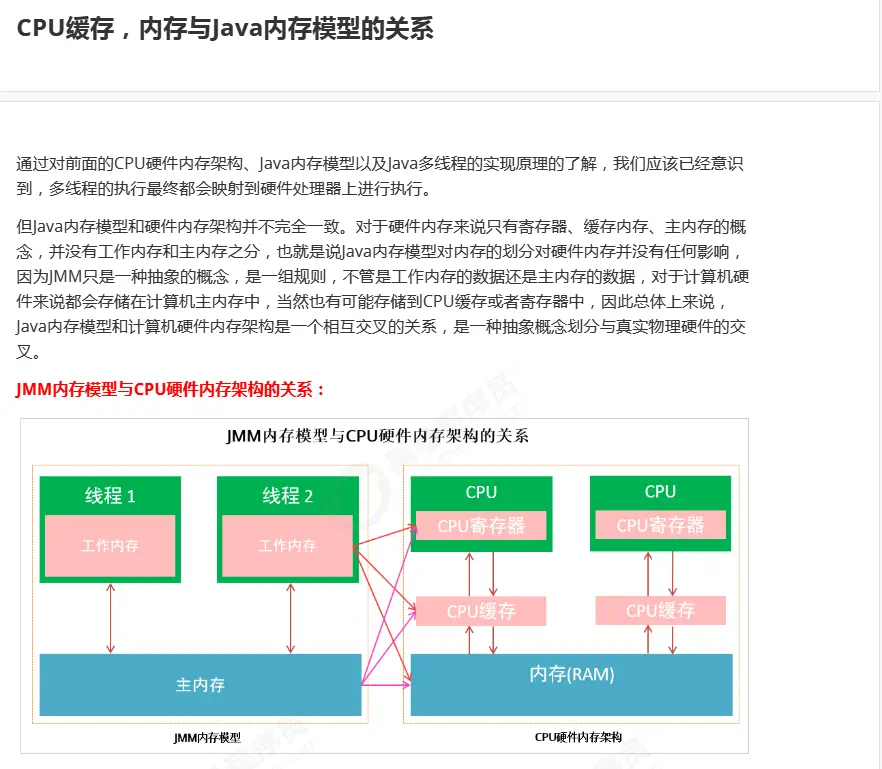
Working memory and main memory may be in many places (cpu register cache or main memory)
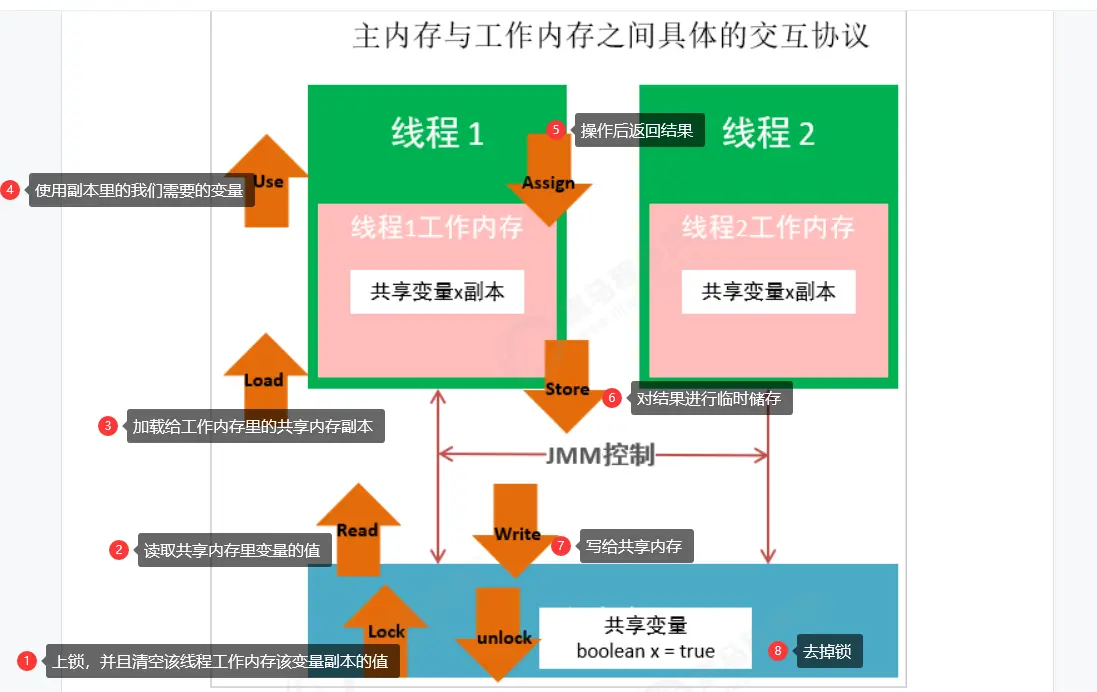
4. Interaction between main memory and working memory
The Java memory model defines the following eight operations to complete. The specific interaction protocol between main memory and working memory is how to copy a variable from main memory to working memory and how to synchronize it back to main memory. During the implementation of virtual machine, it must ensure that each operation mentioned below is atomic and inseparable.
The specific operation is shown in the figure below:
5. Three major problems of main memory operation
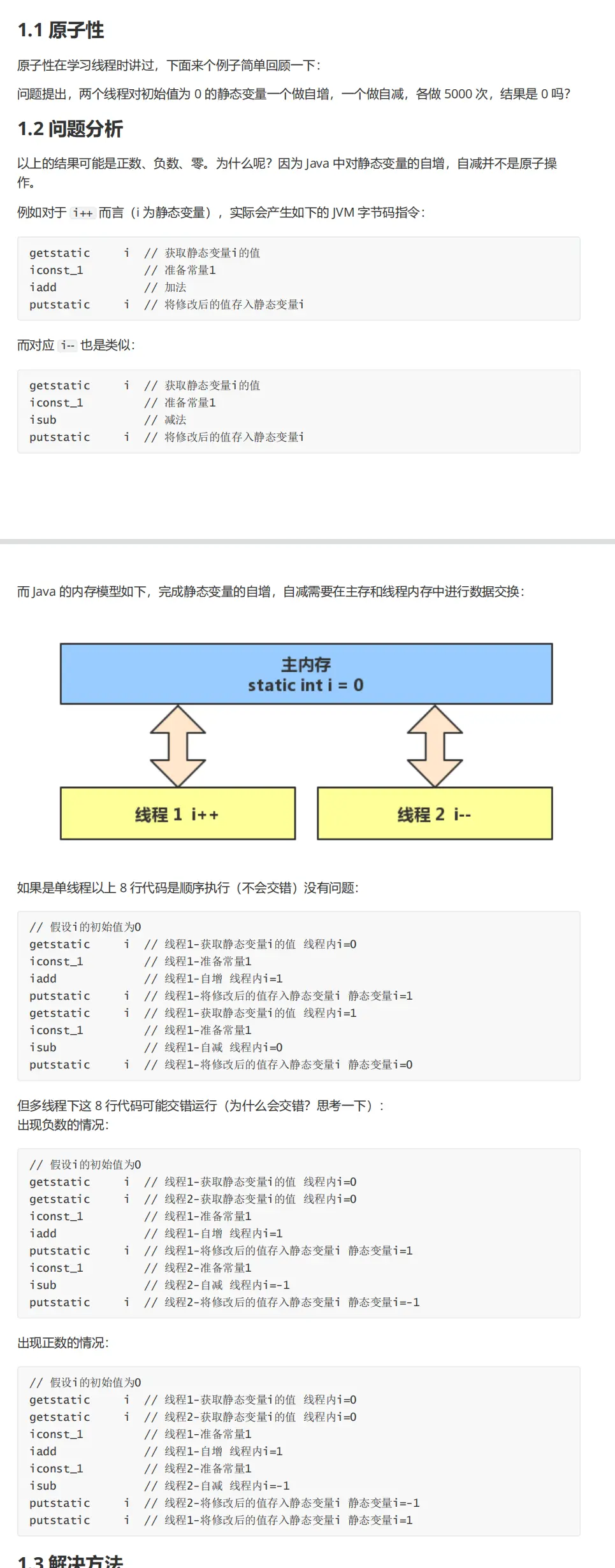
Atomicity problem description
Solve atomic problems
Lock!

Visibility problem description
The visibility problem refers to the JMM memory model specification. After accessing the data in the main memory, the thread will copy the data to its own shared memory. If the data in the main memory is changed at this time, it will cause the visibility problem of inconsistent data.
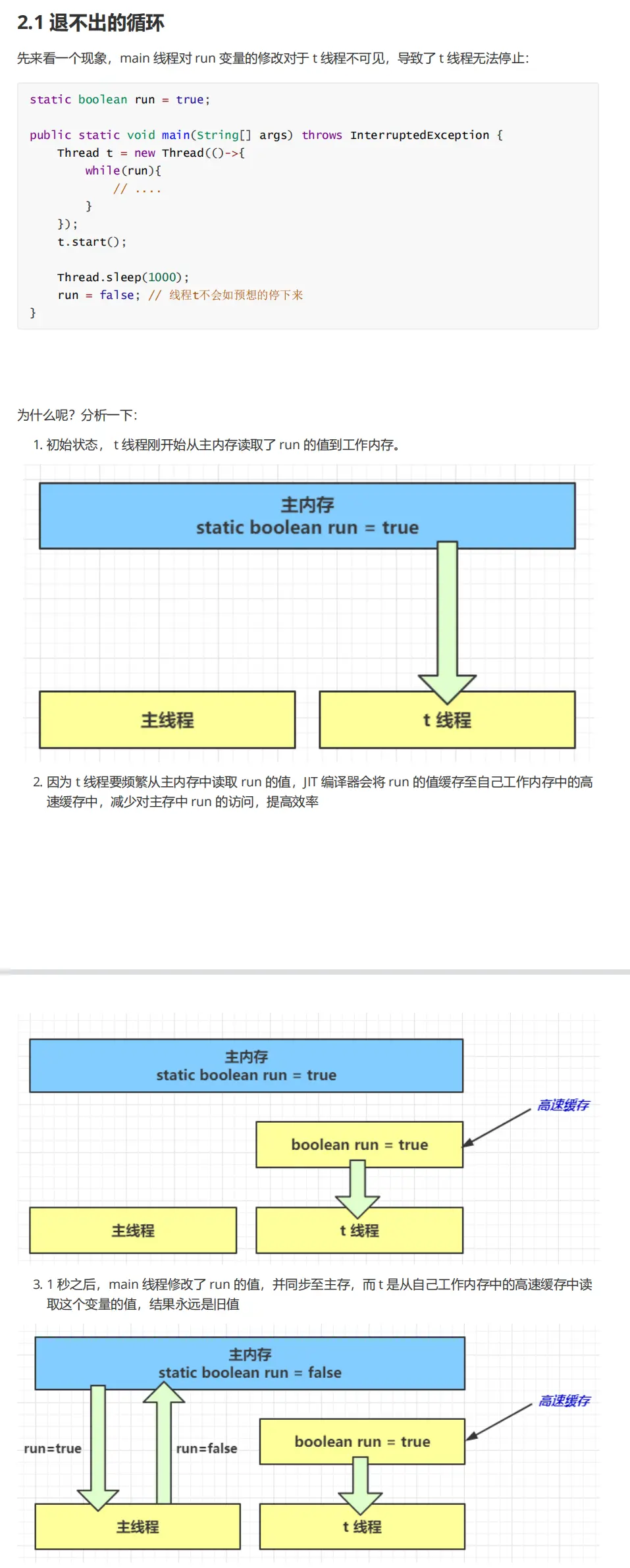
Solutions to visibility problems
Use volatile keyword
static volatile boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){ // ....
} });
t.start();
Thread.sleep(1000);
run = false; // Thread t does not stop as expected
}

Note that synchronized also ensures the visibility of variables within the code
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){ // ....
System.out.printIn();
} });
t.start();
Thread.sleep(1000);
run = false; // Thread t does not stop as expected
}
The code will also stop
But lower performance...
Ordering problem description
Let's look at the following code:
int num = 0;
boolean ready = false;
// Thread 1 executes this method
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
}else {
r.r1 = 1;
} }
// Thread 2 executes this method
public void actor2(I_Result r) {
num = 2;
ready = true;
}
Does it have centralized results?
- Case 1: thread 1 executes first. At this time, ready = false, so the result of entering the else branch is 1
- Case 2: thread 2 executes num = 2 first, but does not have time to execute ready = true. Thread 1 executes and still enters the else branch. The result is 1
- Case 3: thread 2 executes to ready = true, and thread 1 executes. This time, it enters the if branch, and the result is 4 (because num has already been executed)
These are based on the analysis results we learned above, but in fact, there is another 0
Thread 2 execution ready = true,Switch to thread 1 and enter if Branch, add to 0, and then switch back to thread 2 for execution num = 2
This result indicates that the instruction rearrangement has occurred, causing the problem of ordering.
Solutions to order problems

Understanding of order
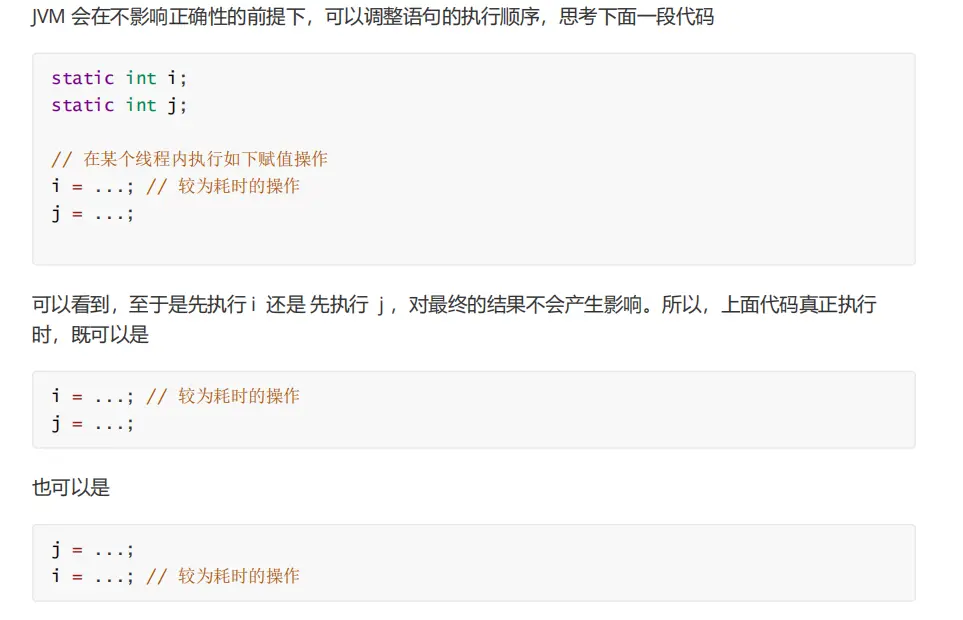
Double check problem caused by ordering

It is understood that:
This is the advantage: the double check mechanism can reduce the phenomenon of repeatedly creating objects and improve efficiency.
But the problem of order is ignored
The bytecode when we create the object is as follows:
0: new #/ singleton / class / cast4 / / allocate space 3: dup //Put the reference address into the operand stack 4: invokespecial #3 / / method "< init >": (V) improve the object 7: putstatic #4 // Field INSTANCE:Lcn/itcast/jvm/t4/Singleton; Put the improved object into the local variable table
At this time, it is easy to rearrange the instructions between 4 and 7, so that the object is assigned to the INSTANCE object before it is perfect. If the object is very complex, the subsequent thread is easy to get the imperfect object.
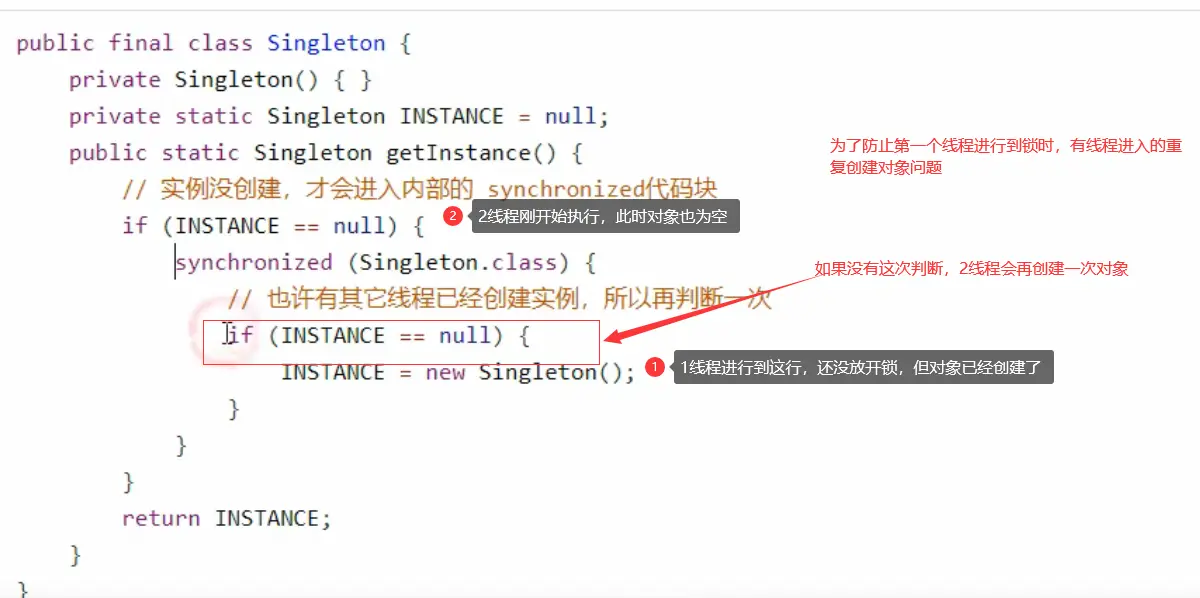
terms of settlement:
public final class Singleton {
private Singleton() { }
private static volatile Singleton INSTANCE = null;
public static Singleton getInstance() {
// Only when the instance is not created will it enter the internal synchronized code block
if (INSTANCE == null) {
synchronized (Singleton.class) {
// Maybe another thread has created an instance, so judge again
if (INSTANCE == null) {
INSTANCE = new Singleton();
} } }
return INSTANCE;
} }
happens-before

CAS and atomic class
1.CAS
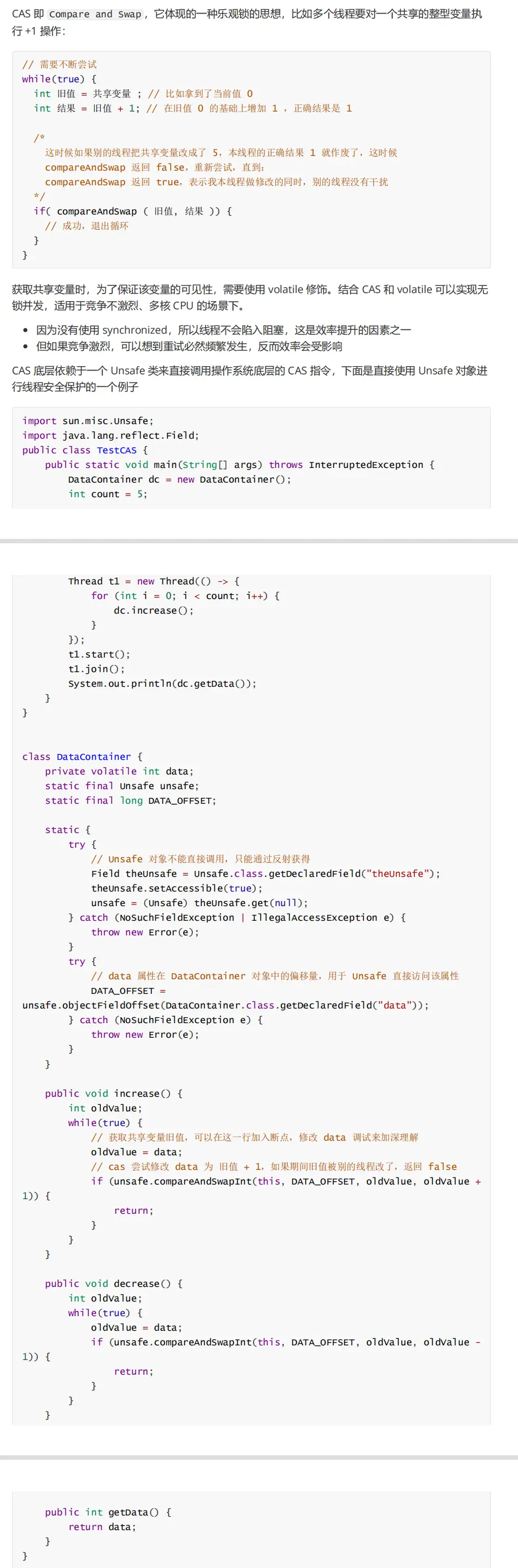
The efficiency of optimistic lock is higher than that of synchronized before optimization. The principle is to constantly compare the old value to ensure that the old value is assigned after it has not been changed.
-
CAS is based on the idea of optimistic lock: the most optimistic estimate is that you are not afraid of other threads to modify shared variables. Even if you do, it doesn't matter. I'll try again at a loss.
-
synchronized is based on the idea of pessimistic lock: the most pessimistic estimate is to prevent other threads from modifying shared variables. When I lock, you don't want to change it. Only after I change and know how to unlock, can you have a chance.
2. Atomic operation
