1.5.sql optimization

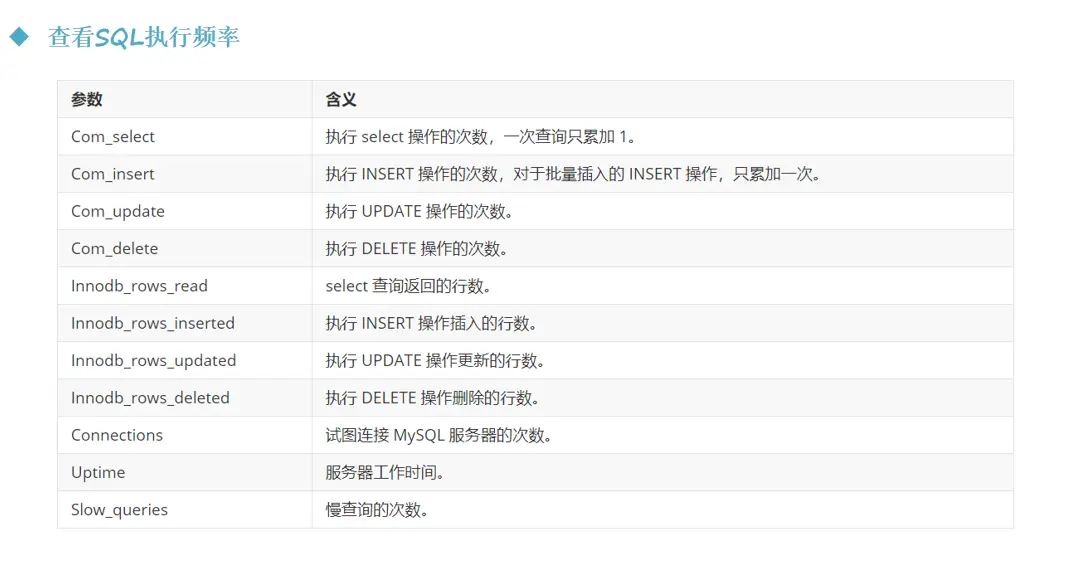
1.5.1. Check the execution frequency of sql
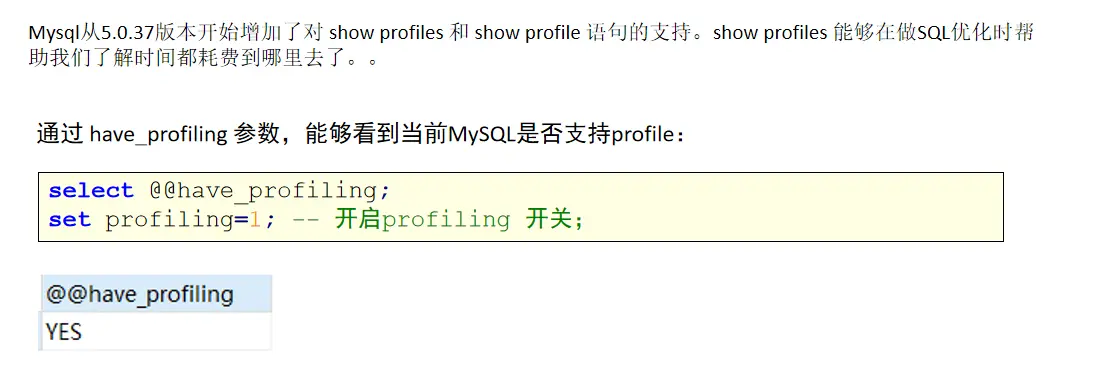
After the MySQL client is successfully connected, you can view the server status information through the show [session|global] status command. You can view the main operation types on the current database by viewing the status information.
--The following command displays the current session Values of all statistical parameters in show session status like 'Com_______'; -- View current session statistics show global status like 'Com_______'; -- View the statistics results since the database was last started show status like 'Innodb_rows_%'; -- View for Innodb Engine statistics
1.5.2. Positioning of sql with low execution efficiency
There are two ways:
-
Slow query log: locate SQL statements with low execution efficiency through slow query log.
-
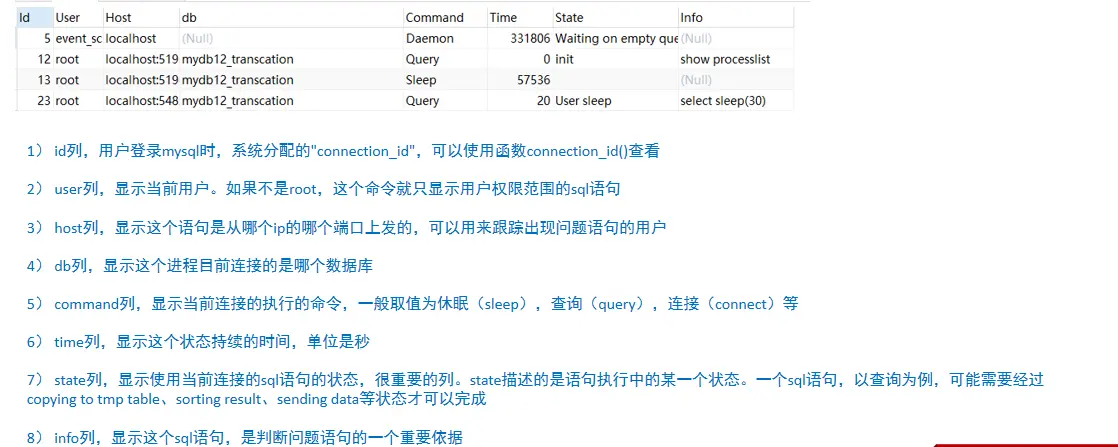
show processlist: this command is used to view the threads currently in progress in MySQL, including thread status and whether to lock the table. It can view the execution of SQL in real time and optimize some table locking operations.
Slow query log
-- View slow log configuration information show variables like '%slow_query_log%'; -- Enable slow log query set global slow_query_log=1; -- View slow logging SQL Minimum threshold time for show variables like 'long_query_time%'; -- Modify slow logging SQL Minimum threshold time for set global long_query_time=4;
show processlist
show processlist;
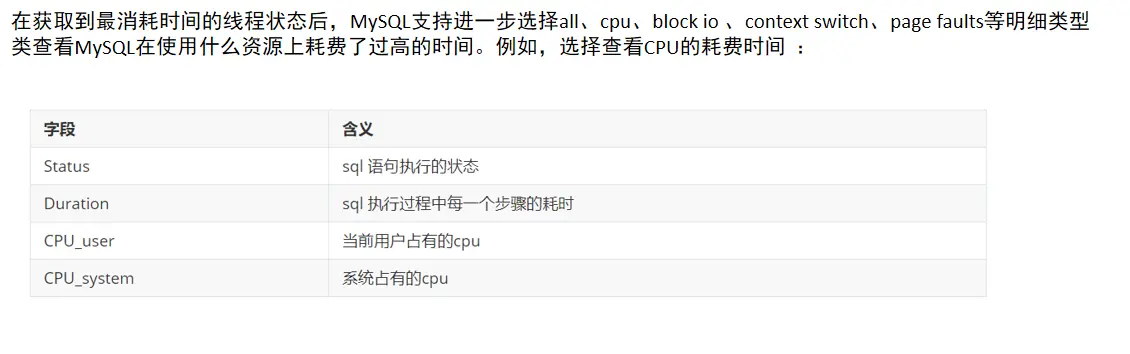
Meaning of each parameter:
1.5.3.explain analysis execution plan
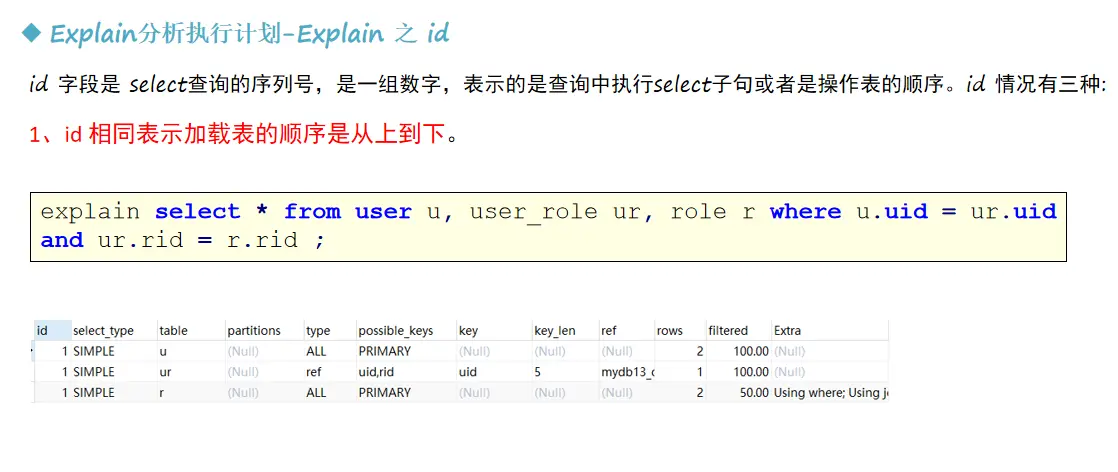
After querying inefficient SQL statements through the above steps, you can use the EXPLAIN command to obtain information about how MySQL executes the SELECT statement, including how tables are connected and the order of connection during the execution of the SELECT statement.

The meaning of each parameter is:

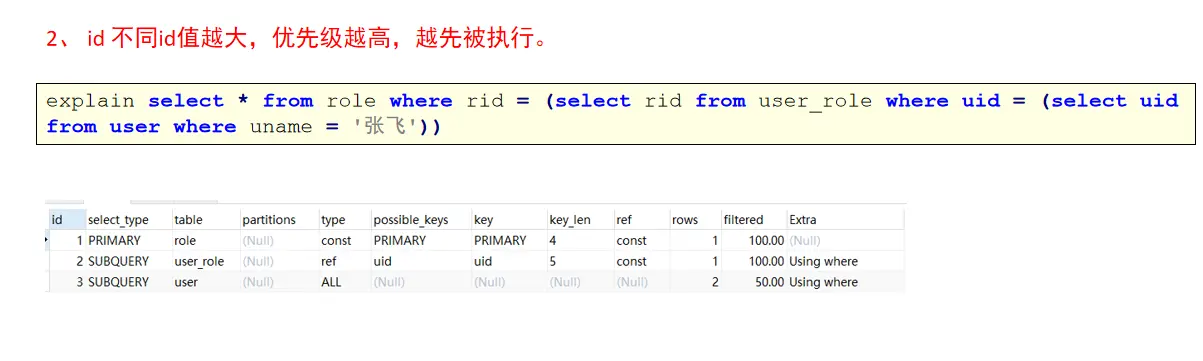
Interpretation of id
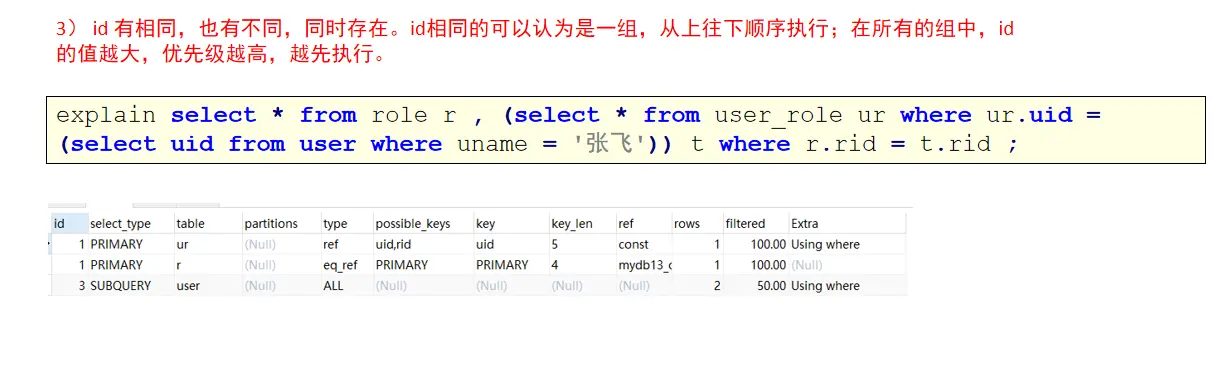
Yes, select_ Explanation of type

Explanation of type
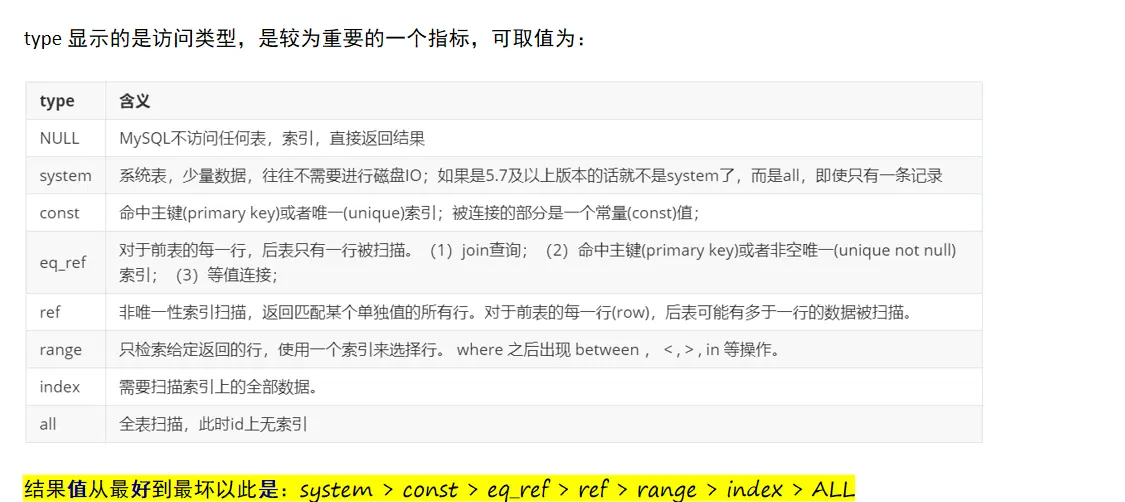
Display of each type
- NULL

- system

-
Const (when querying a unique index)

-
eq_ref (the left table has a primary key index and each row of the left table matches the right table exactly)
For example, we create two tables user2 and user2_ex


The results are as follows: when user2 and user_ When the rows of ex correspond exactly one-to-one, the search mode is all (because there is *) and eq_ref
After adding a repeating element, EQ cannot be used_ Ref decreases efficiency.
- ref (when the left table is a normal index)
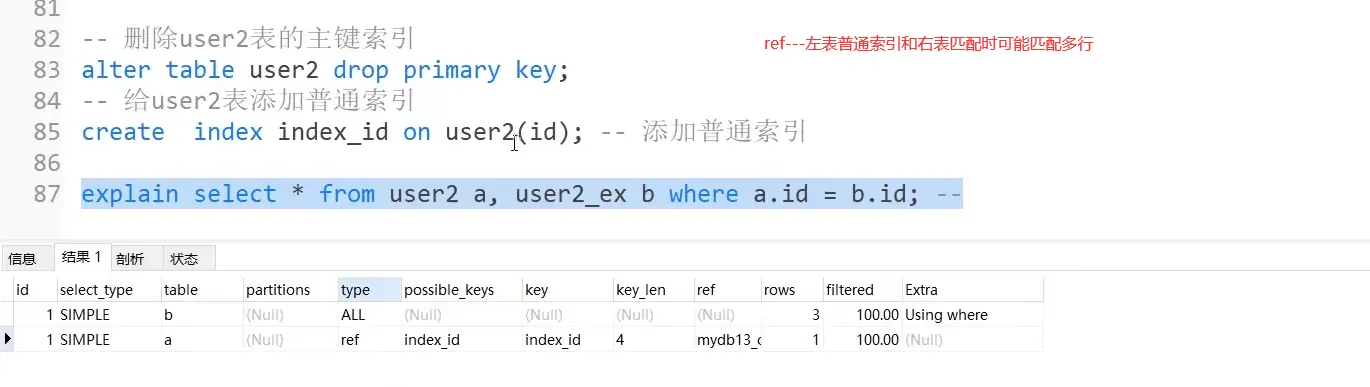
ref allows the left table to match multiple rows of the right table.
- Range (range query)

- Index (print index column)

- all (normal full table query)
The key point is that this comparison is greater than the order. We must remember that it should be maintained above the index level as far as possible during optimization.
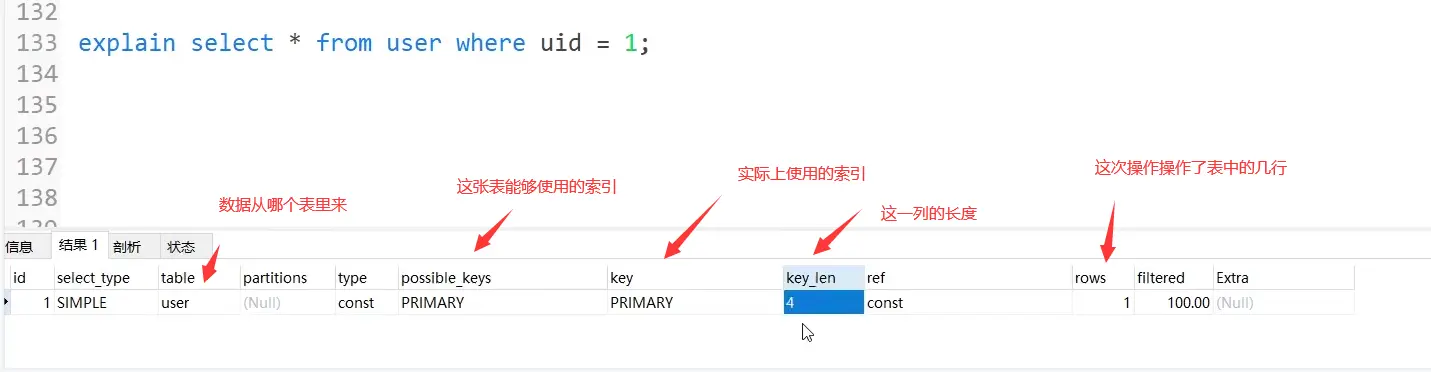
Other indicators (key, etc.)

 ]
]


1.5.4. Analyze sql using show profile
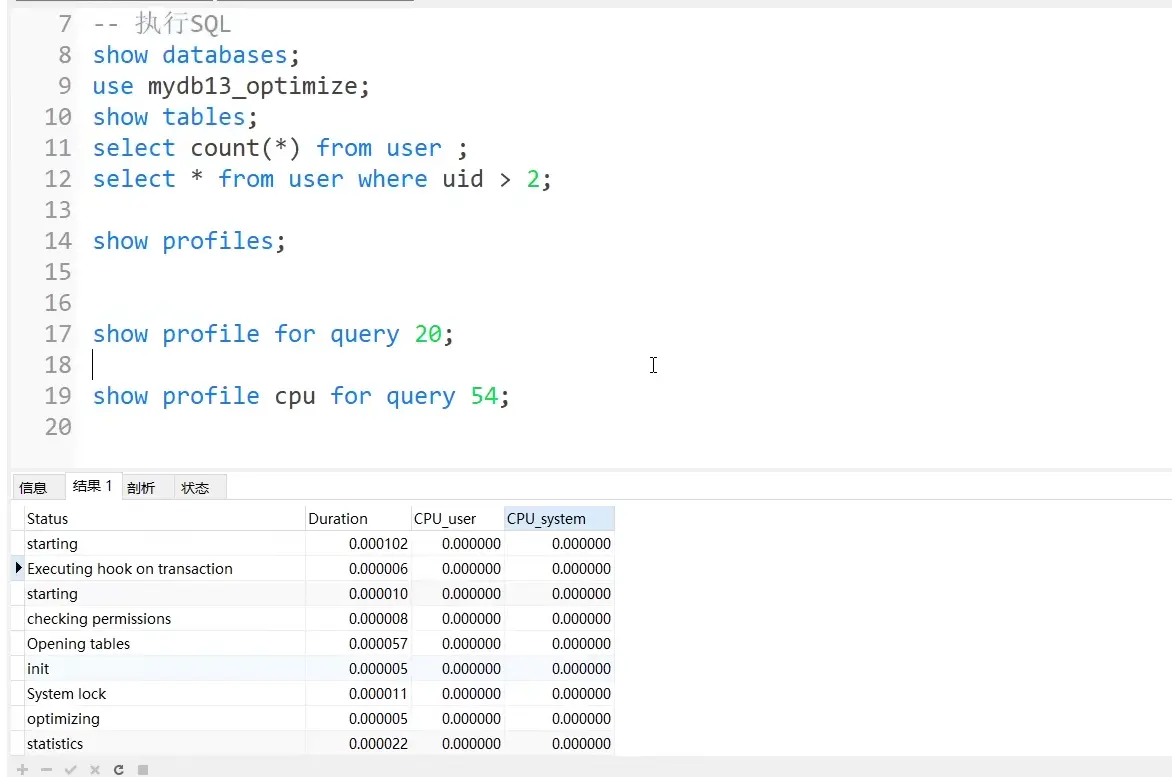
Search steps: use search statement > show profiles > find the sequence number of the statement you want to analyze > show profile for the statement you want to find
The cpu usage of the last lookup statement can be as shown in the figure above.
1.5.5. Specific optimization strategies of MySQL
1. Rely on index optimization
Create a composite index to improve the search speed. To always follow the leftmost matching rule, you can't skip. Note that the higher the actual query value, the more indexes are used and the higher the speed.


- If skipping an index violates the leftmost principle, it will be invalidated

- Range queries, arithmetic operations, and loss of single quotes can make indexes ineffective

- Avoid using * because querying data other than indexes needs to be read from disk, which is inefficient

contrast

Similarly, password is not indexed, and its efficiency is reduced.

The referential meaning of each index of extra

- or will cause index invalidation


- Fuzzy index

- Even if there is an index, there is no index
When there are many duplicate data in one column, we can find the duplicate data, such as the data with the address in Beijing in the figure below. The database will automatically query the full table for us. At this time, the full table query efficiency is high.
When searching Xi'an, index query will be used.




not in and in are the same as above, so there is no need to index.

-
Try to use composite indexes

-
When a query condition includes three single column indexes, the optimal one takes effect

- When querying, join table query is better than nested sub query
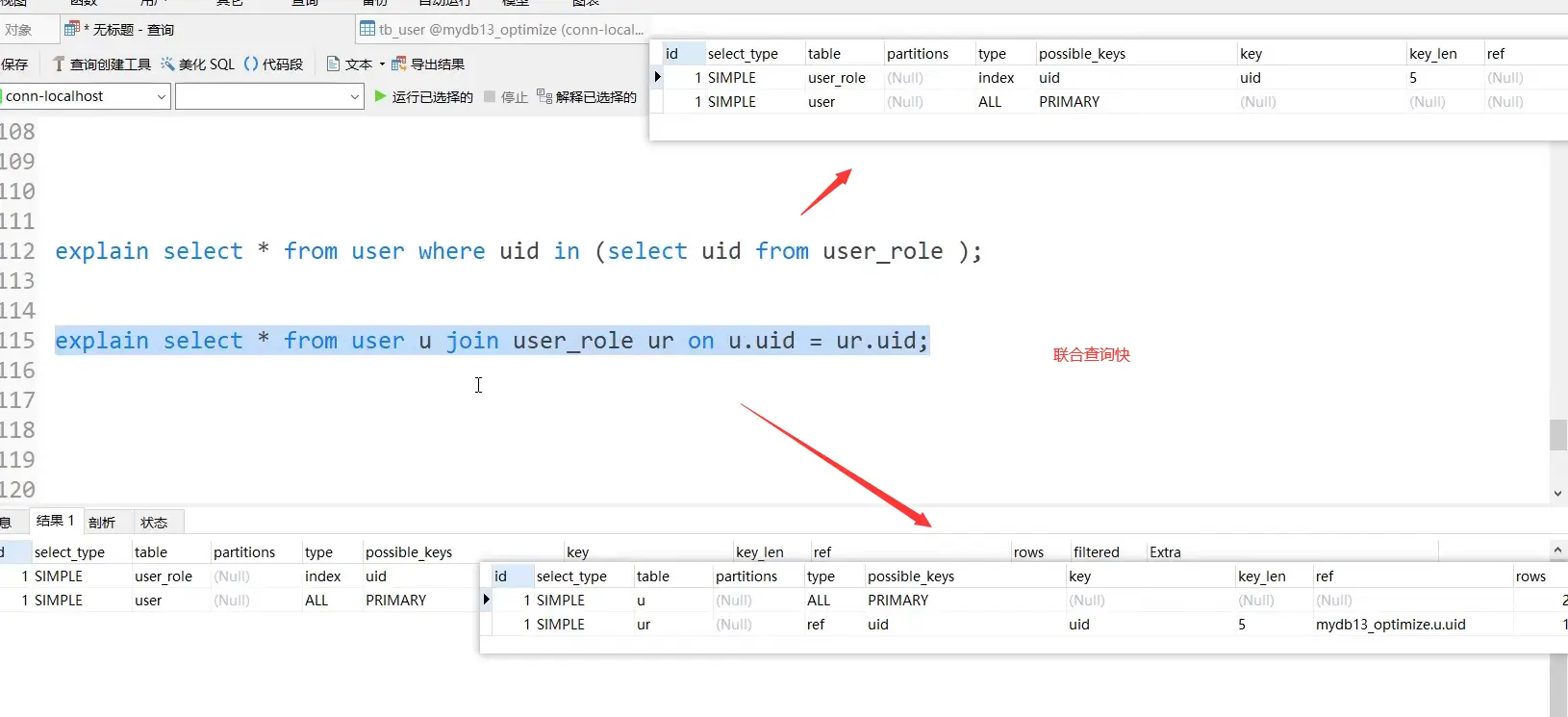
2. Optimize order by
The following display is from extra
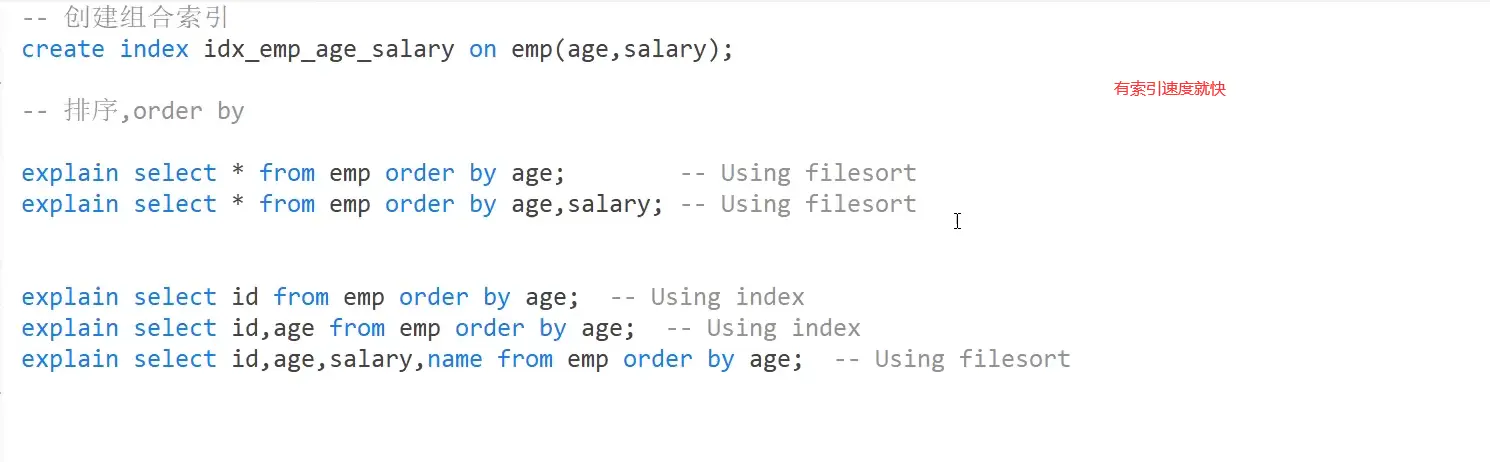

Try to keep the same order and sort in the same way

3. Optimize Filesort
When we have to use Filesort
Creating an appropriate index can reduce the occurrence of Filesort, but in some cases, conditional restrictions can not make Filesort disappear, so it is necessary to speed up the sorting operation of Filesort. For Filesort, MySQL has two sorting algorithms:
1) Twice scanning algorithm: MySQL4 Before 1, use this method to sort. First, get the sorting field and row pointer information according to the conditions, and then sort in the sort buffer in the sorting area. If the sort buffer is not enough, the sorting results are stored in the temporary table. After sorting, read the records back to the table according to the row pointer. This operation may lead to a large number of random I/O operations.
2) One scan algorithm: take out all the fields that meet the conditions at one time, and then sort them in the sort buffer of the sorting area, and then directly output the result set. The memory cost of sorting is large, but the sorting efficiency is higher than the two scan algorithm.
MySQL compares the system variable max_ length_ for_ sort_ The size of the data and the total size of the fields taken out by the Query statement to determine whether the sorting algorithm is, if max_ length_ for_ sort_ If the data is larger, use the second optimized algorithm; Otherwise, use the first one.
Sort can be improved appropriately_ buffer_ Size and max_length_for_sort_data system variable to increase the size of the sorting area and improve the efficiency of sorting.

4. Optimize limit
That's it

perhaps
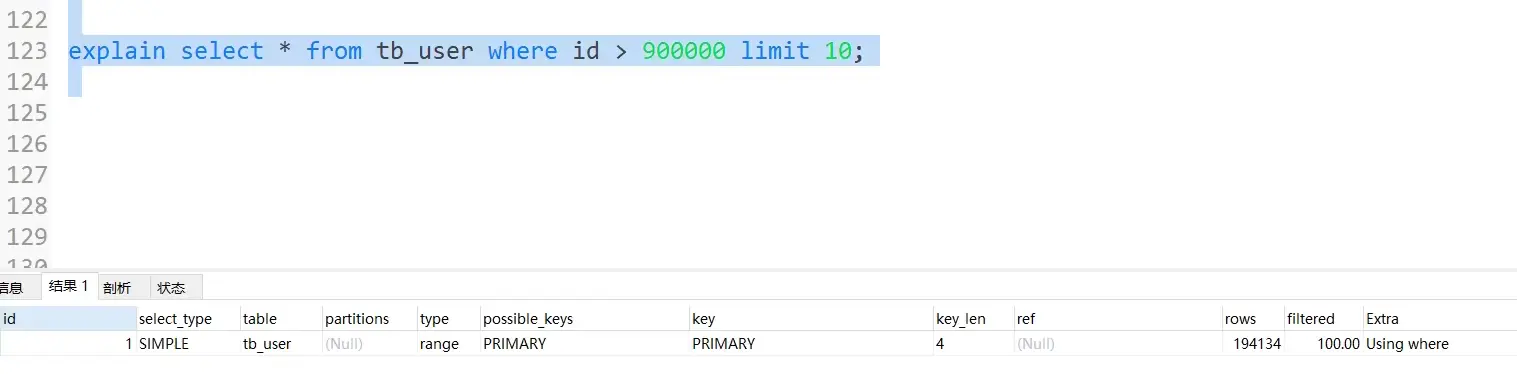
5. Optimization of mass insert data
When we want to use it log file imports a large amount of data. What can I do more efficiently?
Insertion method
-- 1,First, check a global system variable 'local_infile' The status, if obtained, is shown below Value=OFF,This indicates that this is not available show global variables like 'local_infile'; -- 2,modify local_infile Value is on,open local_infile set global local_infile=1; -- 3,Load data load data local infile 'D:\\sql_data\\sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n';
- Sort by primary key column
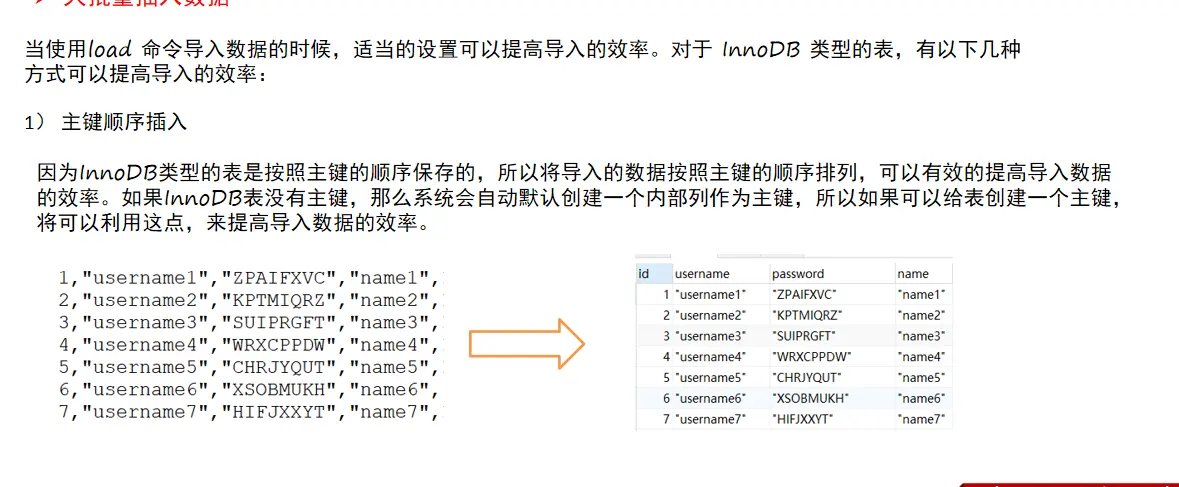
-
Turn off unique retrieval
When adding data, mysql will detect whether the data of the unique index is duplicate. If we have checked it in advance, we can turn off unique retrieval and improve efficiency.
-- Turn off uniqueness check SET UNIQUE_CHECKS=0; truncate table tb_user; load data local infile 'D:\\sql_data\\sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n'; SET UNIQUE_CHECKS=1;
6. Optimize insert
Three directions
-
Orderly insertion
-- Orderly data insertion insert into tb_test values(4,'Tim'); insert into tb_test values(1,'Tom'); insert into tb_test values(3,'Jerry'); insert into tb_test values(5,'Rose'); insert into tb_test values(2,'Cat'); -- After optimization insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); insert into tb_test values(4,'Tim'); insert into tb_test values(5,'Rose');
-
Insert as centrally as possible
-- If you need to insert many rows of data into a table at the same time, you should try to use multiple value tables insert Statement, which will greatly reduce the consumption of connection and closing between the client and the database. So that the efficiency is higher than that of a single system executed separately insert The sentence is fast. -- The original method is: insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); -- The optimized scheme is: insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
-
Insert with a transaction (remember to turn off auto commit in advance)
-- Insert data in a transaction. begin; insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); commit;