task
Operation ①
-
-
Requirements: specify a website and crawl all the pictures in the website, such as China Meteorological Network( http://www.weather.com.cn ). Single thread and multi thread crawling are used respectively. (the number of crawling pictures is limited to the last 3 digits of the student number)
-
Output information:
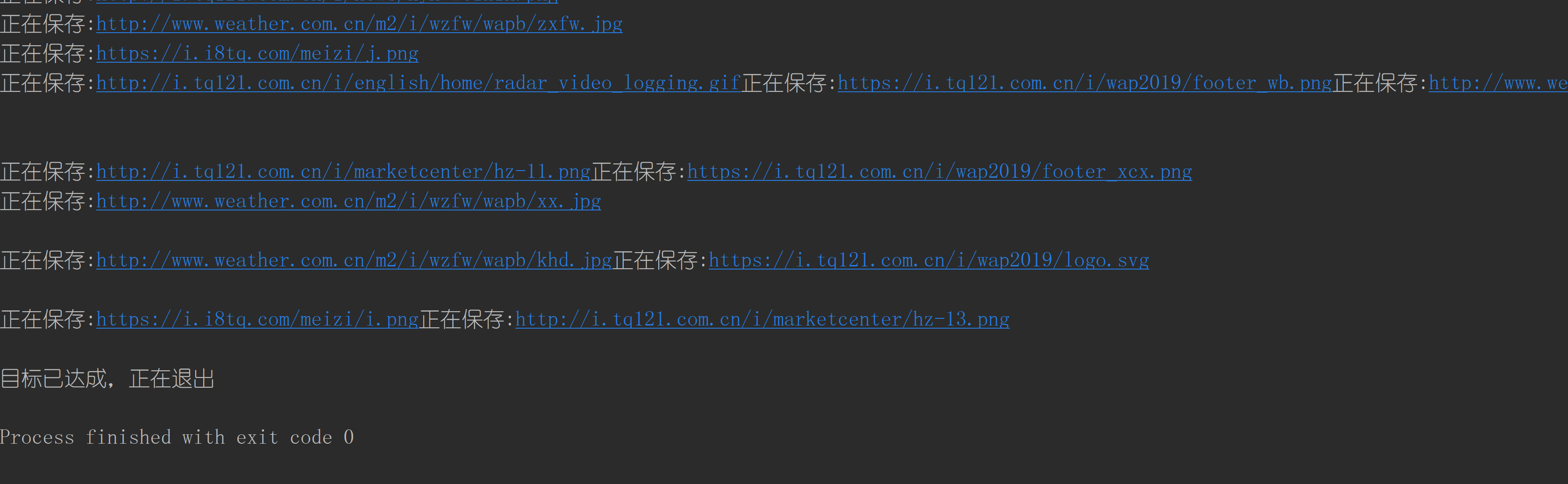
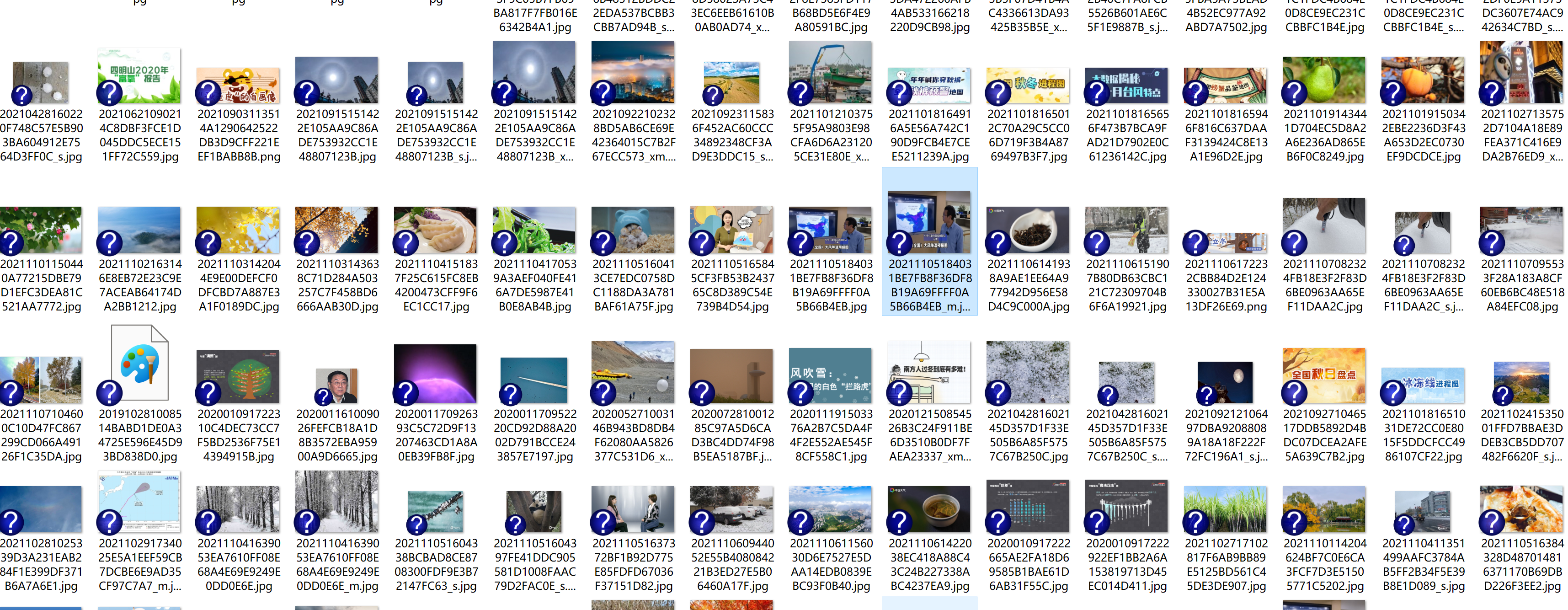
Output the downloaded Url information on the console, store the downloaded image in the images subfolder, and give a screenshot.
-
Idea:
Crawling all the pictures of a website requires two extraction operations:
1. Extract all child URLs (get all a tags)
2. Extract all pictures (get all img tags)
soup = BeautifulSoup(html, "lxml") urls = set(tuple([url.get('href') for url in soup.find_all('a')])) imgs = set(tuple([img.get('src') for img in soup.find_all('img')])) # Turn into set It is convenient for difference set operation
The operation is to search and save all the pictures, and then go to the next sub url in turn for traversal.
Page traversal de duplication
Let's assume that the child url and the parent url are in a tree structure, that is, there is no loop or loop between each url node:

Through traversal (such as dfs), you can find all the pictures on the url in the tree.
However, the actual situation is that there are many rings and loops in the graph composed of website URLs (for example, all pages point to the home page):
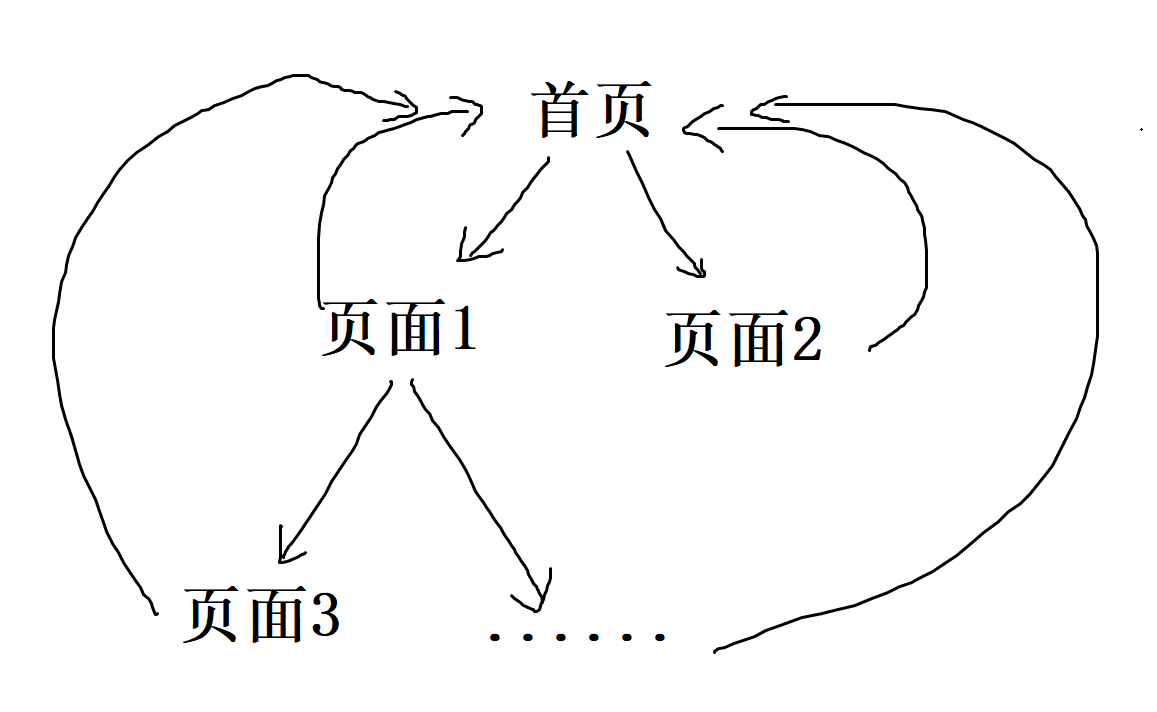
In order to solve the problem of repeatedly crawling the same page, you can choose to use set type global variables to store the paths that have passed.
When the sub url is obtained, take the difference set from the already passed path to remove the duplicate.
over_urls = set() def dfs(target_url: str): # simulation dfs Traverse """ Image extraction code """ # Take difference set target_urls = urls.difference(over_urls) # ergodic [dfs(url) for url in target_urls]
The traversal can be modified by traversing the url to achieve concurrency:
# Concurrent traversal import threading threads = [threading.Thread(target=dfs, args=(url, 20)) for url in target_urls] for thread in threads: thread.start() for thread in threads: thread.join()
Image download and de duplication
In terms of pictures, there is also the reuse of pictures on different pages. As above, set type global variables are used to store the downloaded picture path to prevent repeated downloading.
target_imgs = imgs.difference(over_imgs) for i, img in enumerate(target_imgs): if i >= limit: break save_img(img)
Save picture
There are a lot of things written earlier, so I won't repeat them:
def save_img(img_url): print(f"Saving:{img_url}") # Normal download # download(img_url) # Concurrent Download import threading t = threading.Thread(target=download, args=[img_url]) t.start() def download(img_url): try: resp = requests.get(img_url) except: return with open(f'./images/{img_url.split("/")[-1].split("?")[0]}', 'wb') as f: f.write(resp.content)
Operation results
Because the concurrency is full, the output is strange.
(the amount of concurrency here is terrible. Basically, the URLs reachable by the whole site are crawled at the same time, and the website is not blocked. In the future, the maximum number of concurrency needs to be added to limit crawling.)
*There is another small detail: in concurrency or error capture, exit () and sys.exit() cannot exit python programs (they will be recognized as thread errors for error capture), so OS. Exe is required_ exit() to exit the program successfully.
Operation ②
Use the sketch framework to reproduce the job ①
Idea:
The implementation method is consistent with operation ①:
Set up the scene
# Turn off crawler Protocol Validation ROBOTSTXT_OBEY = False # Set default request header DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } # Set download path IMAGES_STORE = "./images" # start-up pipeline import os IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images') ITEM_PIPELINES = { 'session_2.pipelines.Session2Pipeline': 300, } # Start Downloader DOWNLOADER_MIDDLEWARES = { 'session_2.middlewares.Session2DownloaderMiddleware': 543, }
Build portal file
# run.py from scrapy import cmdline cmdline.execute("scrapy crawl weath -s LOG_ENABLED=True".split())
Download pictures
In the crawler function, return an Item and submit the picture url to pipeline.
# weath.py yield Session2Item(url=img)
Reconstruct the pipeline to inherit the image download class imagespipline.
# pipelines from scrapy import Request from scrapy.pipelines.images import ImagesPipeline class Session2Pipeline(ImagesPipeline): # inherit ImagesPipeline def get_media_requests(self, item, info): print(item['url']) yield Request(item['url'])
The image saving path is set by images above_ Store (the picture will be placed in the full directory under this path).
Running screenshot


* In order to facilitate the statistics of the number of pictures downloaded, the picture list is abandoned and a single picture is used as the transmission, and the concurrency will decrease slightly.
->Improvement: subtract the remaining quantity to be downloaded from the current page number. If the remaining quantity is insufficient, take the opposite number for parameter transmission.
Operation ③
-
-
Requirements: crawl the Douban movie data, use scene and xpath, store the content in the database, and store the pictures in the imgs path.
-
Candidate sites: https://movie.douban.com/top250
-
Output information:
-
| Serial number | Movie title | director | performer | brief introduction | Film rating | Film cover |
|---|---|---|---|---|---|---|
| 1 | The Shawshank Redemption | Frank delabond | Tim Robbins | Want to set people free | 9.7 | ./imgs/xsk.jpg |
| 2.... |
Idea:
Main crawler function
The Xpath parsing of page numbers is as follows:
html = response.body.decode('utf-8') selector = scrapy.Selector(text=html) movies = selector.xpath("//li/div[@class='item']") for movie in movies: item = Session3Item() item['name'] = movie.xpath(".//span[@class='title']/text()").extract_first() item['director'] = movie.xpath(".//div[@class='bd']/p/text()").extract_first().split(':')[1][:-2] item['actor'] = movie.xpath(".//div[@class='bd']/p/text()").extract_first().split(':')[-1] item['introduction'] = movie.xpath(".//span[@class='inq']/text()").extract_first() item['score'] = movie.xpath(".//span[@property='v:average']/text()").extract_first() item['url'] = movie.xpath(".//img/@src").extract_first() yield item
Page turning operation is realized by url jump:
self.page_num += 1 if self.page_num > 10: return yield scrapy.Request(url=self.url.format(self.page_size*(self.page_num-1)), callback=self.parse)
Because the page size of Douban is 40, you can climb 10 pages. When the page number is greater than 10 pages, exit the page number traversal.
Item
The item should include the movie name, director, author, introduction, picture and link information:
class Session3Item(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() director = scrapy.Field() actor = scrapy.Field() introduction = scrapy.Field() score = scrapy.Field() image = scrapy.Field() url = scrapy.Field()
Pipelines
Because the pipeline of database upload and image download inherits from different pipelines (in fact, there is an inheritance for image download), there is a conflict between them in creation.
Therefore, two pipeline s are used for database and download operations respectively:
Database pipeline:
There is another point to note here. The database connection and table creation operations cannot be placed in the execution function, otherwise multiple runs will lead to data loss or error reporting.
from scrapy.pipelines.images import ImagesPipeline from scrapy import Request class Session3Pipeline: from mysql import DB from settings import DB_CONFIG db = DB(DB_CONFIG['host'], DB_CONFIG['port'], DB_CONFIG['user'], DB_CONFIG['passwd']) def __init__(self): self.db.driver.execute('use spider') self.db.driver.execute('drop table if exists movies') sql_create_table = """A pile of tables sql sentence""" self.db.driver.execute(sql_create_table) def process_item(self, item, spider): sql_insert = f'''insert into movies(...) values (...)''' self.db.driver.execute(sql_insert) self.db.connection.commit() return item
Download pipeline:
Via item_completed can be renamed through the os module after downloading
class DownloadImagePipeline(ImagesPipeline): def get_media_requests(self, item, info): print("Saving:", item['url']) yield Request(item['url']) def item_completed(self, results, item, info): # rename path = [x["path"] for ok, x in results if ok] # os Module rename os.rename(IMAGES_STORE + "\\" + path[0], IMAGES_STORE + "\\" + str(item['name']) + '.jpg')
Finally, configure setting.py:
# Database settings DB_CONFIG = { 'host': '127.0.0.1', 'port': 3306, 'user': 'spider', 'passwd': 'spider', } # Cancel crawler verification ROBOTSTXT_OBEY = False # Default request header DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:92.0) Gecko/20100101 Firefox/92.0', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } # start-up pipelines import os IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'imgs') ITEM_PIPELINES = { 'session_3.pipelines.Session3Pipeline': 300, 'session_3.pipelines.DownloadImagePipeline': 300, }
Because it needs to be added to the database, the database configuration information is added in setting.py. In addition, pay attention to starting two pipelines at the same time.
Result screenshot
(some directors and introductions are missing)


Code address
https://gitee.com/mirrolied/spider_test
Experience
1. In this assignment, I strengthened my understanding of the sketch framework, especially the use of pipelines, and became more proficient.
2. In addition, for exit(), sys.exit(), and OS_ Exit () these seemingly similar exit instructions understand their differences and usage scenarios at the bottom.
3. In addition, I reviewed the set type of python and learned the new usage except de duplication.