Assignment 1
Dangdang Book crawling experiment
Job content
-
Requirements: master the serialization output method of Item and Pipeline data in the scene; Scrapy+Xpath+MySQL database storage technology route crawling Dangdang website book data
-
Candidate sites: http://www.dangdang.com/
-
Key words: Students' free choice
Experimental steps
1. Create our scratch project first. As in the last experiment, open the cmd terminal, cd into the project path we want to create, and enter the following instructions to create the project dangdang
scrapy startproject dangdang
2. Then we enter the created project and execute the following instructions to create our crawler
scrapy genspider DangDangSpider
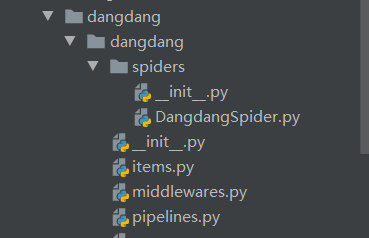
3. You can see that the projects and crawlers we have created are as follows
4. Start to write our code happily. The first step is to set the content in the setting.py file. This is the same as the last operation. Just modify three places. This is relatively simple and I won't introduce it more
Then we write the following contents in the item.py file:
class DangdangItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
5. When writing Spider, I first decided to use XPath to locate the experiment, and then F12 observed the web page content and found XPath to start writing. The key parse function is as follows. The keyword I selected is python, that is, crawling Python books
def parse(self, response):
global page # Set page number
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) # Parsing web pages
data = dammit.unicode_markup
selector = scrapy.Selector(text=data) #Create selector object
lis = selector.xpath("//Li ['@ DDT pit'] [starts with (@ class, 'line')] ") # find the list of lis
print('>>>>>>>The first' + str(page) + 'page<<<<<<<')
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
item = DangdangItem() # Create a good object
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
Another important thing is to realize page turning. I use the global variable page. If the page reaches the number of pages we want, it can stop
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
# Get a link to the next page
if link:
if page == 3:
# Set the maximum number of pages to crawl
print("Climbed three pages")
link = False
page += 1
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
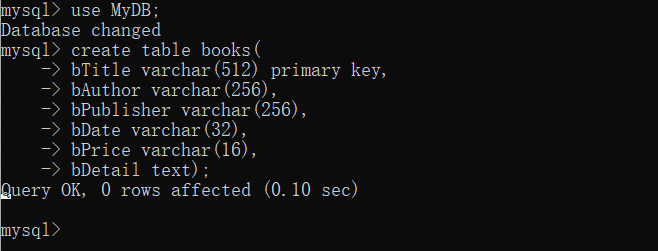
6. Finally, the presentation and storage of data. This experiment requires storage in MySQL database. Therefore, we can create a table outside in advance, and then insert the data by writing pipline, as shown below
Start to write pipline. The first step is to establish a connection with the database as follows:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd = "huan301505", db = "MyDB", charset = "utf8")
# Connect to mysql database
self.cursor = self.con.cursor(pymysql.cursors.DictCursor) # Set cursor
self.cursor.execute("delete from books") # Empty data table
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
Step 2 print the data, insert it into the database, submit it when the data volume is self.count == 125, and close the connection
def process_item(self, item, spider):
try:
if self.opened:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print("=======================================================") # Print each book with line breaks
# insert data
self.cursor.execute("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values (%s, %s, %s, %s, %s, %s)", (item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count += 1 # count
if self.count == 125:
# When it is equal to 125 copies, submit the database and close the connection
self.con.commit()
self.con.close()
self.opened = False # close
print("closed")
print("Total crawling", self.count, "Book")
return
experimental result
The operation results are as follows:
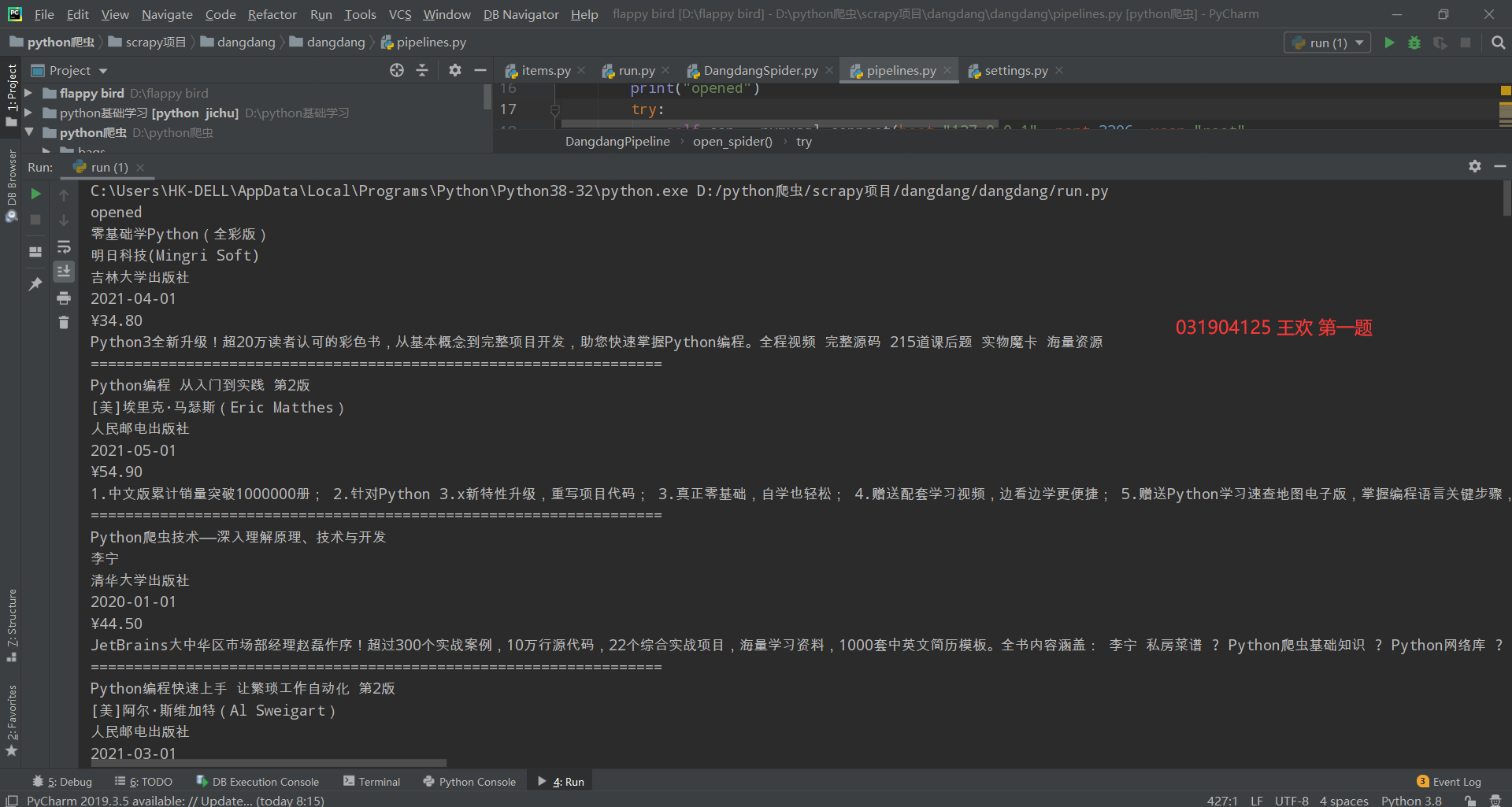
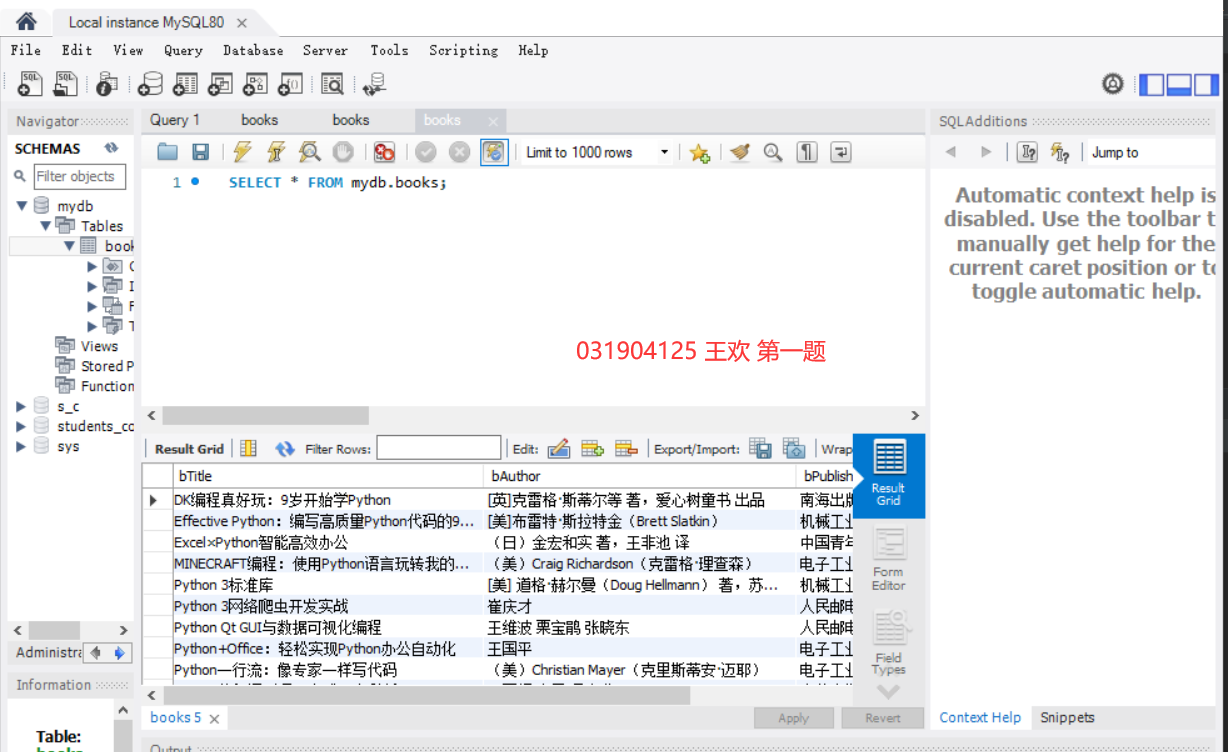
Database:
Experimental experience
Through this experiment, I further consolidated the usage of scratch and became more proficient in finding web elements
Assignment 2
Bank exchange rate crawling experiment
Job content
-
Requirements: master the serialization output method of Item and Pipeline data in the graph; use the graph framework + Xpath+MySQL database storage technology route to crawl the foreign exchange website data.
-
Candidate website: China Merchants Bank Network: http://fx.cmbchina.com/hq/
Experimental steps
1. This question is a little similar to the homework. They all use xpath, so I won't be wordy about the preparations before the experiment, including the preparation of setting files and item files. We skip directly to Spider. We'll observe his web page and find that it's a little simpler than the element positioning of the first question. The content position in each tuple is in td in TR, so we need to locate tr first
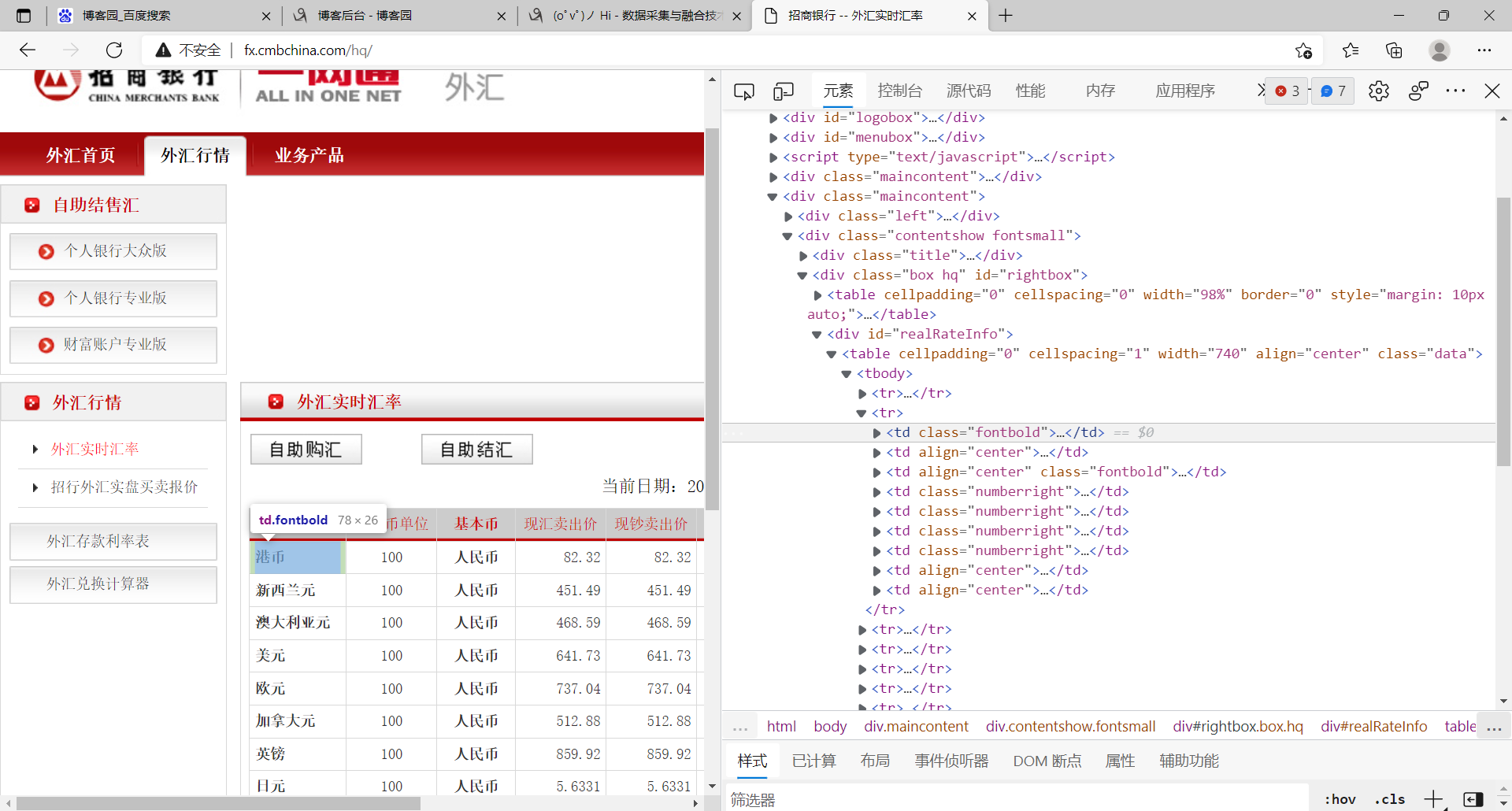
The xpath positioning statement of tr list is as follows:
tr_lists = selector.xpath('//div[@id="realRateInfo"]/table//tr ') # use xpath to find the tr list
2. Then we can traverse each TR and extract what we want in the td below tr:
for i in range(1, len(tr_lists)):
# The setting starts from 1, because the 0 is the header, not the data we want to crawl
Currency = tr_lists[i].xpath('./td[@class="fontbold"]/text()').extract_first()
TSP = tr_lists[i].xpath('./td[4]/text()').extract_first()
CSP = tr_lists[i].xpath('./td[5]/text()').extract_first()
TBP = tr_lists[i].xpath('./td[6]/text()').extract_first()
CBP = tr_lists[i].xpath('./td[7]/text()').extract_first()
Time = tr_lists[i].xpath('./td[8]/text()').extract_first()
item = FxItem() # item object
item["Currency"] = Currency.strip()
item["TSP"] = TSP.strip()
item["CSP"] = CSP.strip()
item["TBP"] = TBP.strip()
item["CBP"] = CBP.strip()
item["Time"] = Time.strip()
yield item
3. After completing these, we can start to write data saving. The requirement of job 2 is to save the data in MYSQL database. The implementation is as follows:
class FxPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd = "huan301505", db = "MyDB", charset = "utf8")
# The first step is to connect to the mysql database
self.cursor = self.con.cursor(pymysql.cursors.DictCursor) # Set cursor
self.cursor.execute("delete from fx") # Empty fx data table
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit() # Submit
self.con.close() # Close connection
self.opened = False
print("closed")
print("Crawl successful")
def process_item(self, item, spider):
try:
if self.opened:
s = "{0:{7}^10}\t{1:{7}^10}\t{2:{7}^10}\t{3:{7}^10}\t{4:{7}^10}\t{5:{7}^10}\t{6:{7}^10}"
if self.count == 1:
# The header is printed only once
print(s.format("Serial number","currency","TSP","CSP","TBP","CBP","Time",chr(12288)))
print(s.format(str(self.count),item["Currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"],chr(12288)))
self.cursor.execute('insert into fx (id,Currency,TSP,CSP,TBP,CBP,Time) values (%s, %s, %s, %s, %s, %s, %s)',(str(self.count),item["Currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"]))
self.count += 1
except Exception as err:
print(err)
experimental result
Run the results on the pycharm console
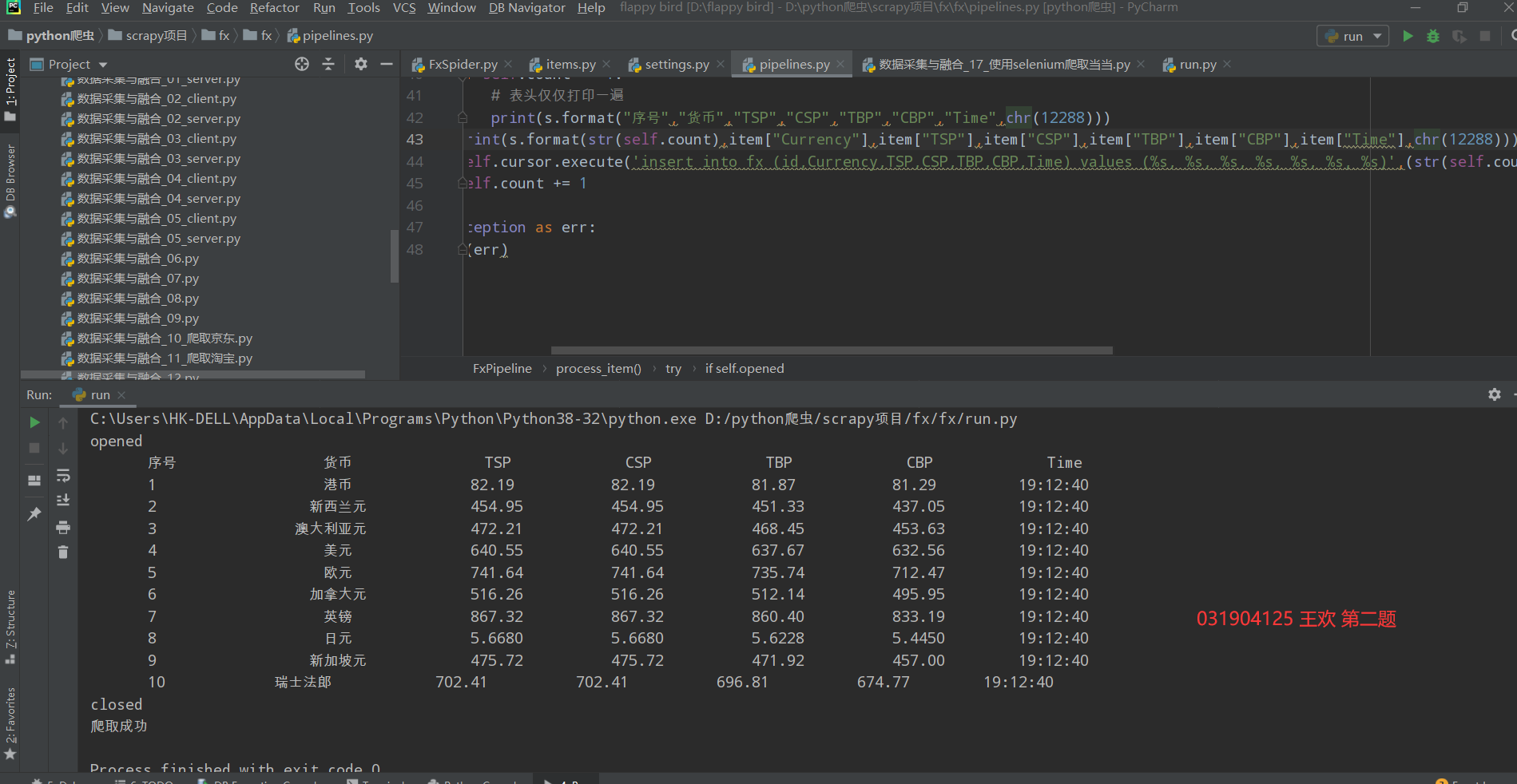
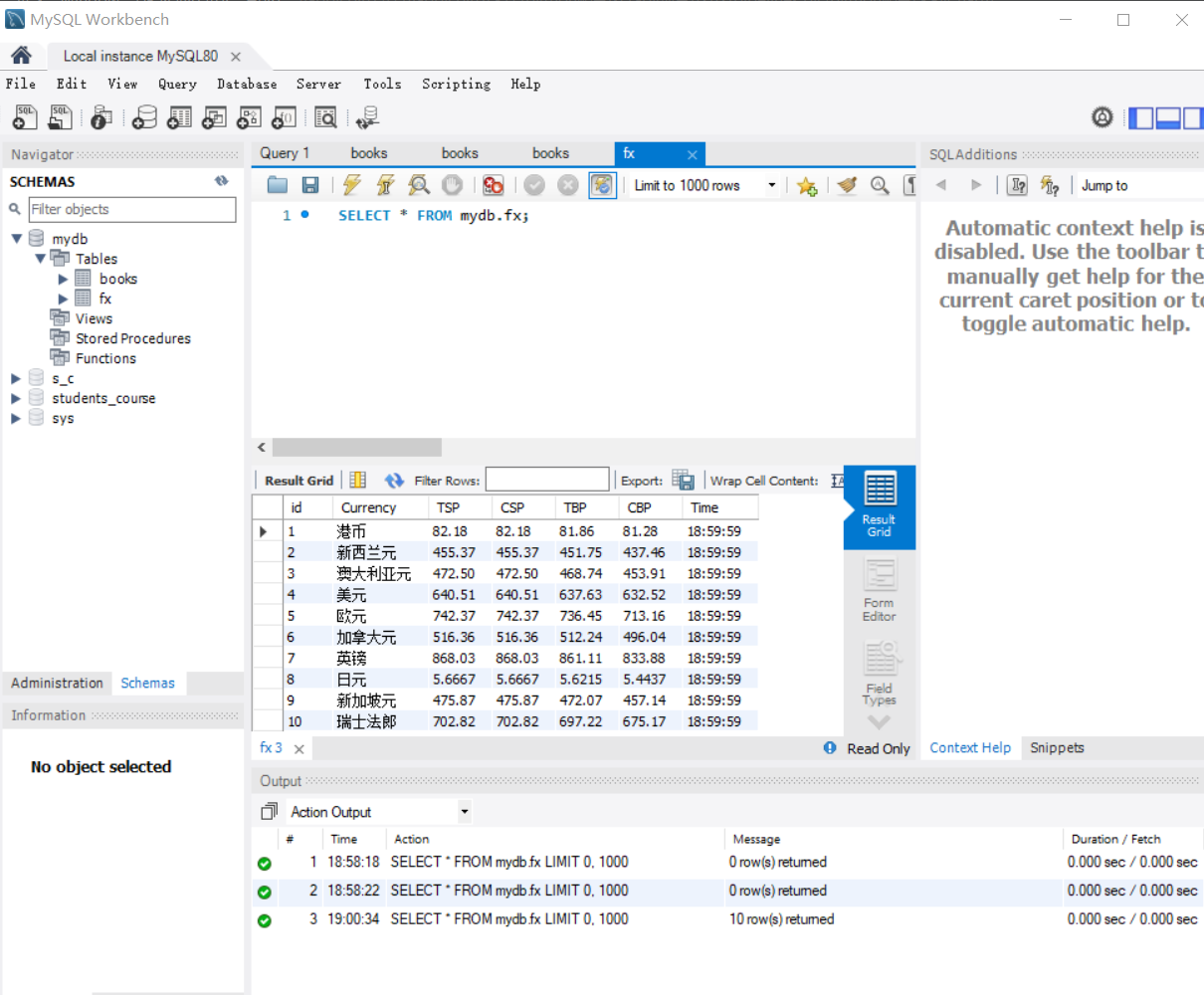
Database content:
Experimental experience
Through this experiment, I further consolidated the usage of scratch and became more proficient in finding web page elements. One thing to pay attention to is that XPath can be directly copied from the web page. Sometimes it can be used, and sometimes it will fail. It is very annoying. For example, in this assignment 2, I can't use the direct copy XPath in the positioning tr list, so I can only write it myself later
Assignment 3
Stock information crawling experiment
Job content
-
Requirements: be familiar with Selenium's search for HTML elements, crawling Ajax web page data, waiting for HTML elements, etc.; use Selenium framework + MySQL database storage technology route to crawl the stock data information of "Shanghai and Shenzhen A shares", "Shanghai A shares" and "Shenzhen A shares".
-
Candidate website: Dongfang fortune.com: http://quote.eastmoney.com/center/gridlist.html#hs_a_board
Experimental steps
1. Assignment 3 requires us to use selenium to crawl web content, so we first make preparations before crawling, import selenium related packages, and set up a virtual browser using selenium's webdriver
# Preparation before climbing browser = webdriver.Chrome() # Set Google wait = WebDriverWait(browser, 10) # Set the wait time to 10 seconds url = "http://quote.eastmoney.com/center/gridlist.html" name = ['#hs_a_board','#sh_a_board','#sz_a_board'] # List of modules to climb, 1. Shanghai and Shenzhen A shares, 2. Shanghai A shares, 3. Shenzhen A shares
2. Because this job needs to save data in mysql, write the database class first, including the three methods of connecting to the database, closing the database and inserting data
# stock database class
class mySQL:
def openDB(self):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd = "huan301505", db = "MyDB", charset = "utf8") # The first step is to connect to the mysql database
self.cursor = self.con.cursor(pymysql.cursors.DictCursor) # Set cursor
# self.cursor.execute("create table stocks (Num varchar(16), stockCode varchar(16),stockName varchar(16),Newprice varchar(16),RiseFallpercent varchar(16),RiseFall varchar(16),Turnover varchar(16),Dealnum varchar(16),Amplitude varchar(16),max varchar(16),min varchar(16),today varchar(16),yesterday varchar(16))")
# Create table stock
self.cursor.execute("delete from stocks") # Empty data table
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def close(self):
if self.opened:
self.con.commit() # Submit
self.con.close() # Close connection
self.opened = False
print("closed")
print("Climb successfully!")
#insert data
def insert(self,Num,stockcode,stockname,newprice,risefallpercent,risefall,turnover,dealnum,Amplitude,max,min,today,yesterday):
try:
self.cursor.execute("insert into stocks(Num,stockCode,stockName,Newprice,RiseFallpercent,RiseFall,Turnover,Dealnum,Amplitude,max,min,today,yesterday) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(Num,stockcode,stockname,newprice,risefallpercent,risefall,turnover,dealnum,Amplitude,max,min,today,yesterday))
except Exception as err:
print(err)
3. Then write the get_data() method. We can crawl a page step by step, that is, the content of the current web page, and then consider the page turning and conversion module. I use the find_elements_by_xpath implementation in selenium to obtain the data, directly find all the data columns, and then use the. text method to get the data,
def get_data():
try:
id = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[1]') # Stock serial number
stockcode = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[2]/a') # ...
stockname = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[3]/a')
new_price = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[5]/span')
price_extent = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[6]/span')
price_extent_num = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[7]/span')
deal_num = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[8]')
deal_price = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[9]')
extent = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[10]')
most = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[11]/span')
least = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[12]/span')
today = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[13]/span')
yesterday = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[14]')
for i in range(len(stockcode)):
print(id[i].text,"\t\t",stockcode[i].text,"\t\t",
stockname[i].text,"\t\t",new_price[i].text,"\t\t",
price_extent[i].text,"\t\t",price_extent_num[i].text,
deal_num[i].text,"\t\t",deal_price[i].text,"\t\t",
extent[i].text,"\t\t",most[i].text,"\t\t",least[i].text,"\t\t",today[i].text,"\t\t",yesterday[i].text)
# print data
4. After successfully obtaining the data, consider turning the page. I use the method of button.click() in selenium, use wait.until((By.Xpath)) to find the button of the next page, and click it to turn the page
def next_page():
try:
page = 1
while page <= 3:
print("The first"+str(page)+"page")
get_data()
button_next = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="main-table_paginate"]/a[2]')))
button_next.click() # Click the button on the next page
time.sleep(1) # Set wait one second
webdriver.Chrome().refresh() # Refresh the page
page += 1
except Exception as err:
print(err)
There is a problem here, that is, the following errors will appear. Later, I checked CSDN. Some people said that when crawling some websites, they sometimes submit web pages. After the web pages are updated, but the page elements are not connected successfully, so we need to refresh it. We just need to use webdriver.Chrome().refresh just refresh the web page. I have to wait a few seconds before refreshing. I tried to solve this problem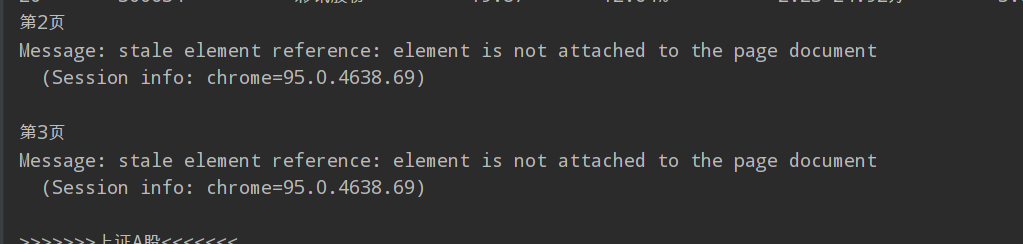
5. After turning the page, the conversion module is implemented. There are many requirements for these three tasks. We also need to climb to Shanghai and Shenzhen A shares, Shanghai A shares and Shenzhen A shares. Here, I use the method of modifying the url, which is relatively simple. I think we can also use selenium's button.click() method to click it to realize the conversion
def next_part():
try:
print("Start crawling!")
print("The stock information is as follows:")
for i in range(len(name)):
new_url = url + name[i] # Modify url
browser.get(new_url) # Get web page
time.sleep(1)
webdriver.Chrome().refresh() # Refresh it
if i == 0: print(">>>>>>>Shanghai and Shenzhen A thigh<<<<<<<")
elif i == 1: print(">>>>>>>Shanghai A thigh<<<<<<<")
else: print(">>>>>>Shenzhen A thigh<<<<<<")
next_page() # Start crawling
stockDB.close() # Close the database at the end of the cycle
except Exception as err:
print(err)
experimental result
The operation results are as follows:
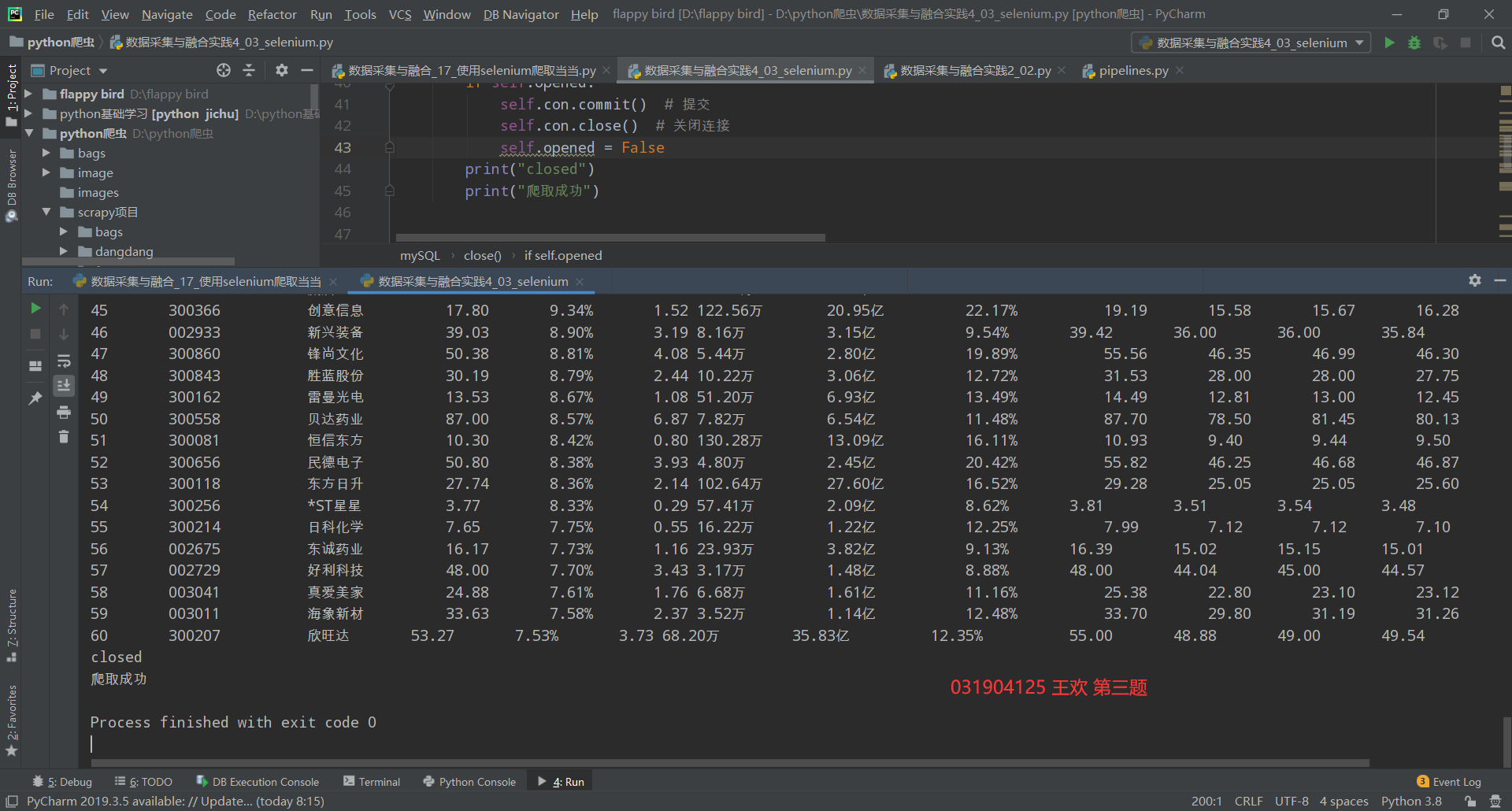
The csv file exported from the database can be viewed as follows:
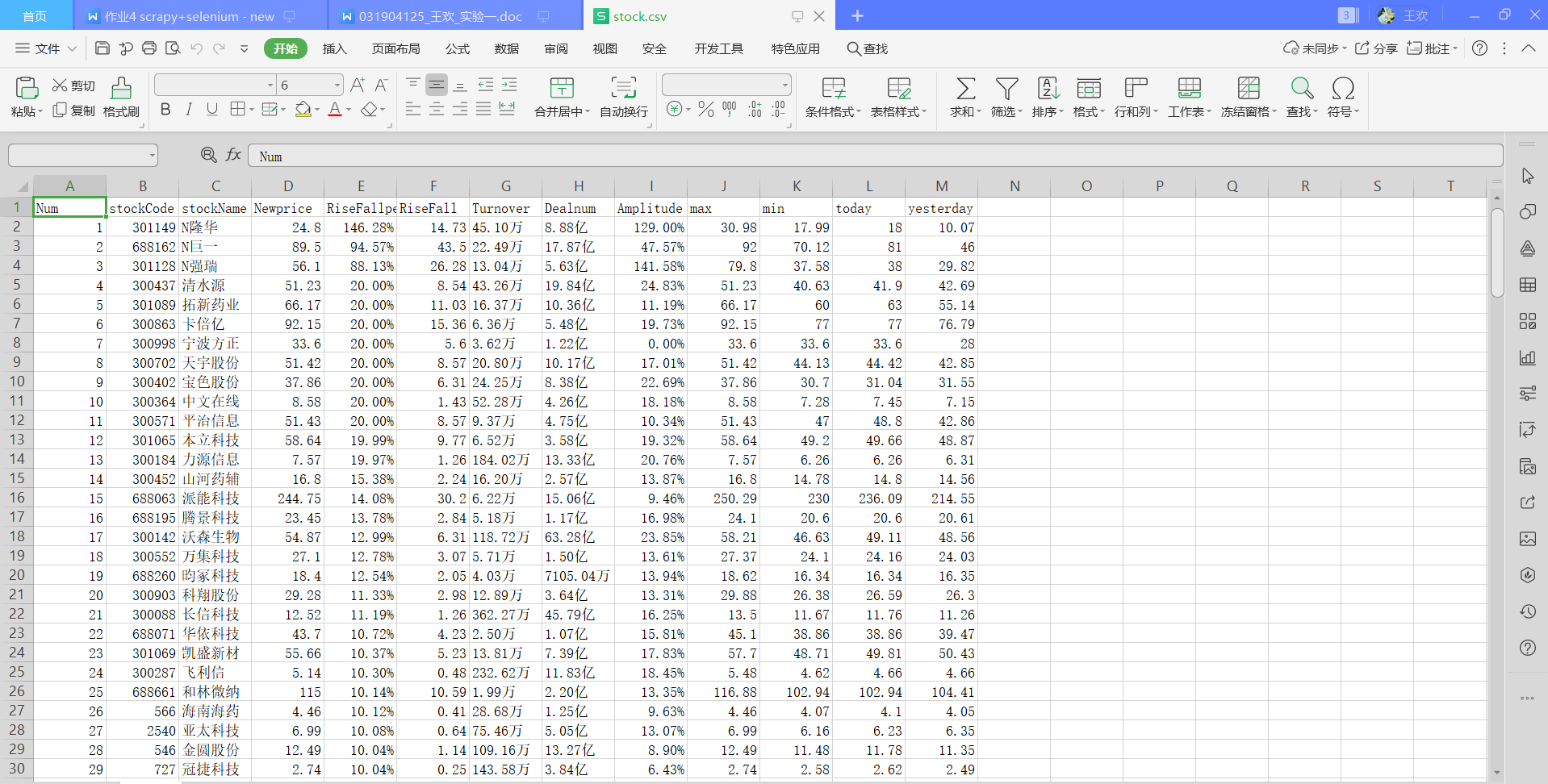
Experimental experience:
In this experiment, I am familiar with the use of selenium, strengthen the web crawler ability and problem-solving ability, and have a deeper understanding of the use of xpath under different frameworks through the comparison of the use of xpath between sweep and selenium. At the same time, it also lays a certain foundation for the next experiment. The code path of this experiment is attached at the end of the article: Data acquisition and fusion: data acquisition and fusion practice assignment - Gitee.com