Assignment 1
1.1 title
Requirement: specify a website and crawl all pictures in this website, such as China Meteorological Network Single thread and multi thread crawling are used respectively.
Output information: output the downloaded Url information on the console, store the downloaded image in the images sub file, and give a screenshot.
1.2 implementation process
1.2.1 single thread crawling
- Complete code
- The logic of the main function is
if __name__ == "__main__": url = 'http://www.weather.com.cn/' picture_list = [] #Used to record the obtained picture links html = getHTMLText(url) pagelink = pagelinks(html) # Find other page Jump links page = 8 # Student No. 031904138, the number of pages crawled is 8, and the number of pictures is 138 for i in range(page): #138 = 7 * 18 + 1 * 12 climb 12 items on the last page url = pagelink[i] html = getHTMLText(url) #Crawl the specified web page if(i==page-1): list = parsePage(html,12) # Analyze the web page, extract the required data, and extract 12 items on the last page else: list = parsePage(html, 18) # Analyze the web page, extract the required data, and extract the first 18 items picture_list.extend(list) printGoodsList(picture_list) # Printed data path = r"D:/Third operation/picture/" #Picture saving path save2file(picture_list,path) #Save picture to local file
1. Construct the request header and use urllib.request to crawl the web page
# Use urllib.request to crawl web pages
def getHTMLText(url):
try:
headers = {
"user-agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
}
req = urllib.request.Request(url=url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data=dammit.unicode_markup
return data
except Exception as err:
print(err)
2. Find other page links to jump
Observe the web page source code and find that the page link structure is as follows:

Construct regular expressions to crawl page links and realize page Jump
p_link = re.compile('href="(.*?)"')
link = str(link)
links = re.findall(p_link, link)
3. Crawl the corresponding picture from each page
Observe web page source code

Using regular matching, first get all img tags, and then crawl all images under img tags
imgs = soup.select('img')
imgs = str(imgs)
p_picture = re.compile('src="(.*?)"') #Extract keywords after observing the content of html file
pictures = re.findall(p_picture, imgs) #Find picture links
4. Adjust the format to output picture links
Student No. 031904138, so 138 pictures were taken this time
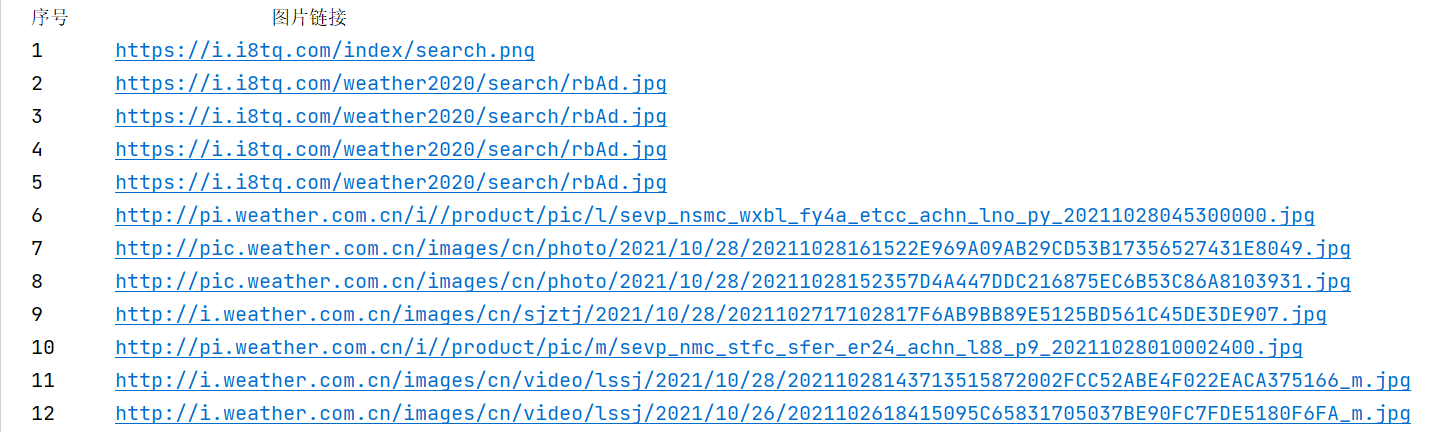
5. Save pictures locally
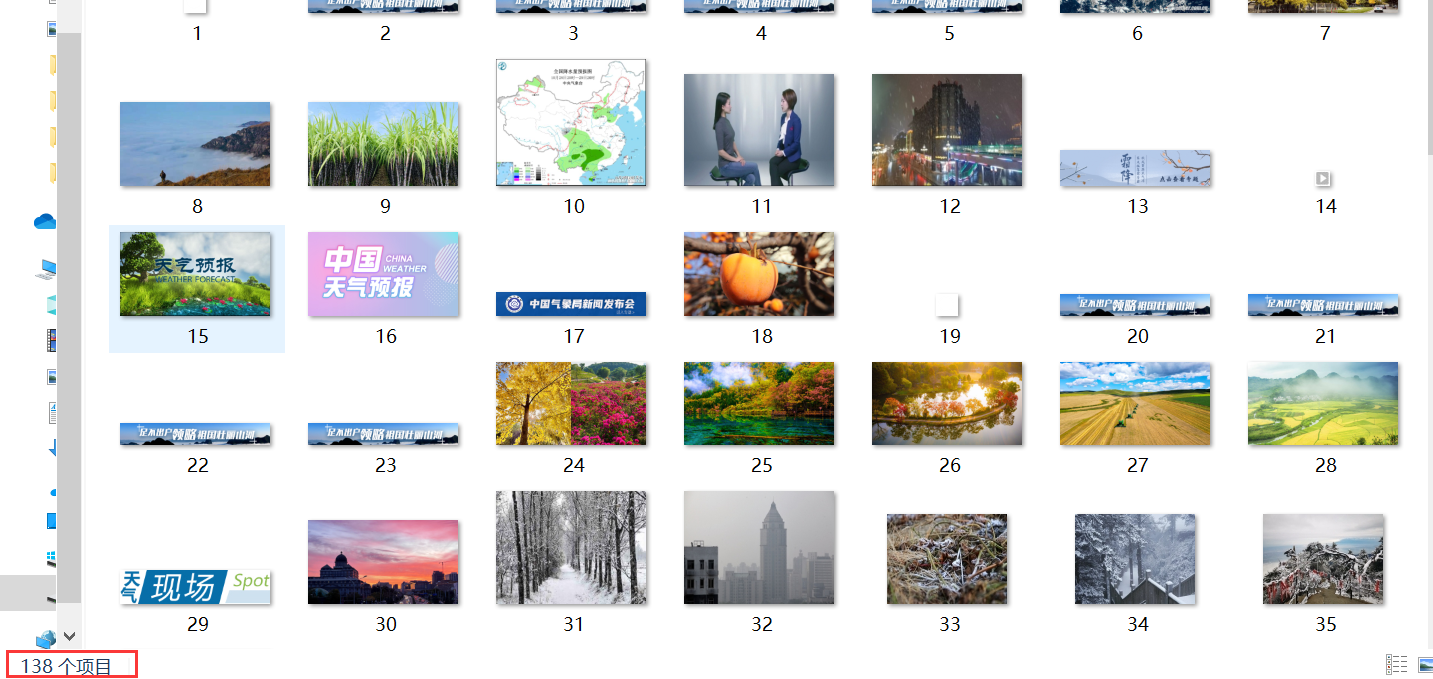
138 sheets in total

1.2.2 multi thread crawling
The logic of the main function is the same as above, but the parsing page is rewritten into multithreading. The implementation code is as follows:
def imageSpider(start_url,num): #num indicates the number of products that need to crawl the page
global threads
global count
try:
req=urllib.request.Request(start_url,headers=headers) #The requests method crawls the web page
data=urllib.request.urlopen(req)
data=data.read() #Get web page text content
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
pic_urls = parsePage(data,num) # Get picture link pic_ List of URLs
for pic_url in pic_urls: # Multi thread downloading pictures
try:
count = count + 1
T = threading.Thread(target=download, args=(pic_url, count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
The output of console results is still 138
Multiple threads download pictures concurrently. The download completion order is random and does not download according to the crawling order

Save to local results
Assignment 2
2.1 title
Requirement: use the sketch framework to reproduce job 1.
Output information: the same as operation 1
2.2 implementation process
2.2.1 modify settings.py
1. Modify print log
# Modify the print log level and turn off something you can't understand LOG_LEVEL = 'ERROR'
2. Close and follow the robots protocol
# Obey robots.txt rules ROBOTSTXT_OBEY = False
3. Set request header
DEFAULT_REQUEST_HEADERS = {
"user-agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
}
4. Open ITEM_PIPELINES
ITEM_PIPELINES = {
'weatherPicture.pipelines.WeatherpicturePipeline': 300,
}
2.2.2 write item.py
- Add the field picture to crawl_ List picture link list
class WeatherpictureItem(scrapy.Item):
picture_list = scrapy.Field()
2.2.3 write pipelines.py
Save and output picture_list
class WeatherpicturePipeline:
def process_item(self, item, spider):
tply = "{0:^4}\t{1:^30}"
print(tply.format("Serial number", "pictures linking", chr(12288)))
for i in range(138):
print(tply.format(i+1,item['picture_list'][i] , chr(12288)))
path = r"D:/mymymy!/Reptile practice/scrapy/weatherPicture/pictures/"
save2file(item['picture_list'], path) # Save to local file
return item
2.2.4 compiling PictureSpider
1. Observe the html source code and parse the page using xpath
# Get links to other pages
links = response.xpath('//a/@href').extract()
# Get a link to the page picture
imgs = response.xpath('//img/@src').extract()
2. Callback request page turning
self.count += 1 # Record page links
if(self.num<=138): # Record the number of picture links
url = response.urljoin(links[self.count])
self.count += 1
yield scrapy.Request(url=url, callback=self.parse,dont_filter=True)
else:
yield item
2.3 output results
-
console output
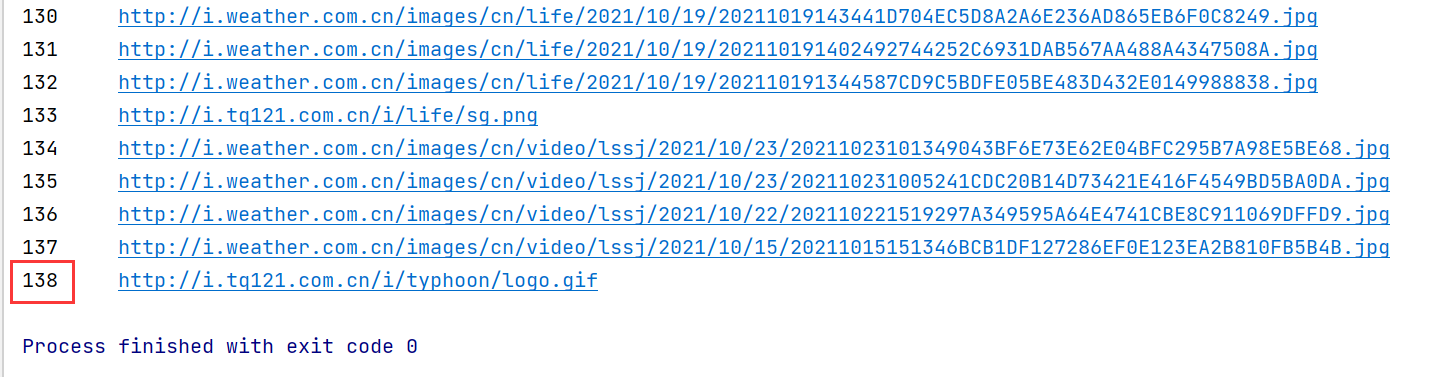
-
Save to local file
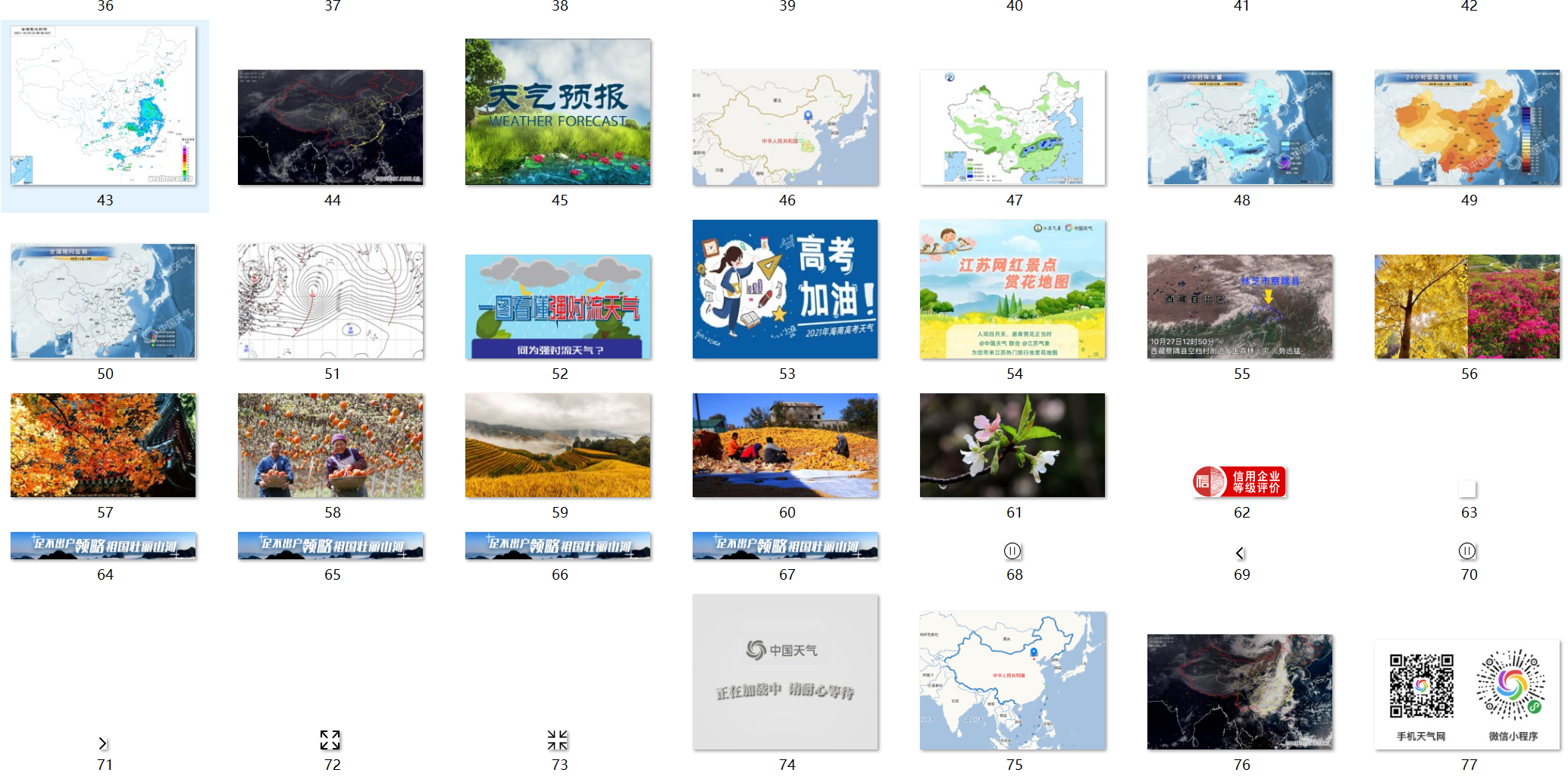
Assignment 3
3.1 title
Requirements: use scratch and xpath to crawl Douban movie data And store the content in the database, and store the pictures in the imgs path.
Output information:
| Serial number | Movie title | director | performer | brief introduction | Film rating | Film cover |
|---|---|---|---|---|---|---|
| 1 | The Shawshank Redemption | Frank delabond | Tim Robbins | Want to set people free | 9.7 | ./imgs/xsk.jpg |
| 2 | ... |
3.2 realization process
3.2.1 modify settings.py
This step is the same as operation 2
3.2.2 write item.py
- Add fields to crawl
Here, the movie information is directly defined as a two-dimensional list
[[name1,director1,actor1,info1,score1,pic_link1],[name2...]...]
class DoubanItem(scrapy.Item):
movies = scrapy.Field()
3.2.3 write pipelines.py
- Print data in format, create tables in the database, insert data into the database, and download pictures locally
(adjusting the output format has been repeated many times, which is not shown here)
#-----------Save data to database-----------------
def saveData2DB(datalist, dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
data[index] = '"' + data[index] + '"'
sql = '''
insert into movie250(
C_name,director,actor,info,score,pic_link
)
values(%s)
''' % ",".join(data)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
#---------------Download pictures locally----------------
def save2file(img_url_list,path):
i=1
for img in img_url_list:
img_url = img
new_path = path + str(i) + ".jpg"
urllib.request.urlretrieve(img_url, new_path) #Define the path to access local pictures
i += 1
3.2.4 writing MovieSpider
-
First, observe the html source code of Douban top250 and see that a movie is located in a li tag
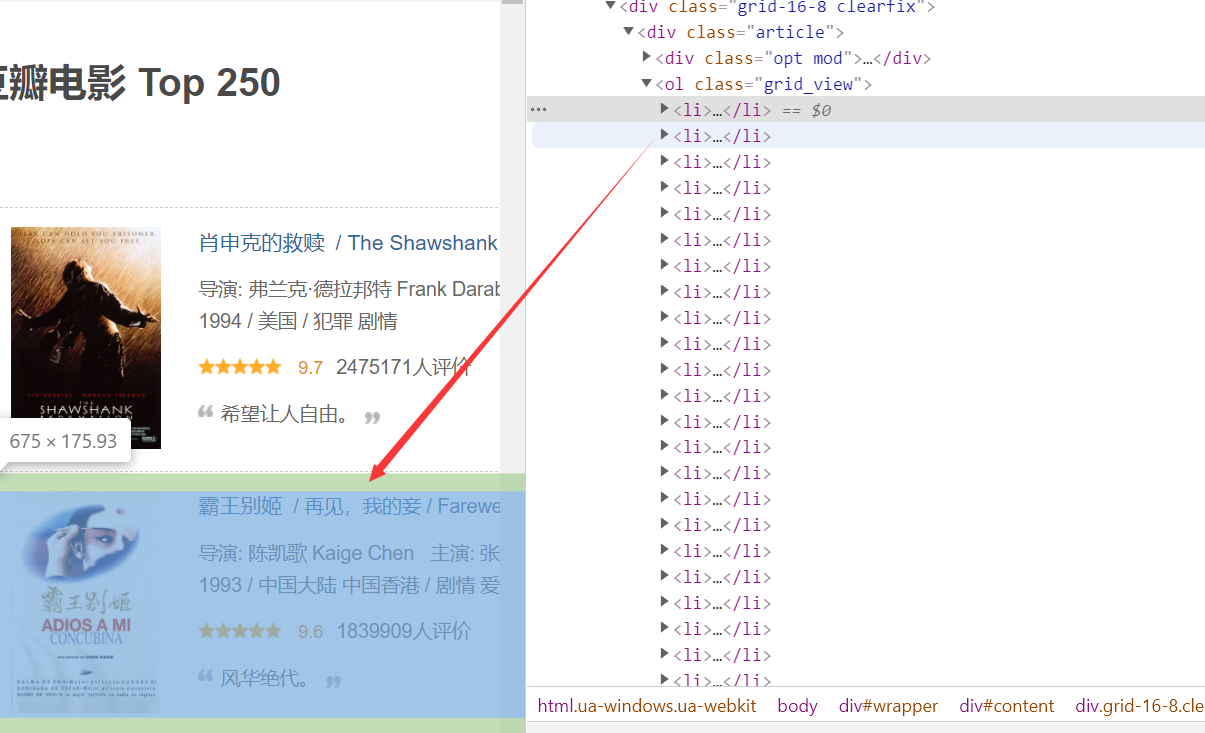
-
Then observe the internal situation of each film. The information we need is in the info tab
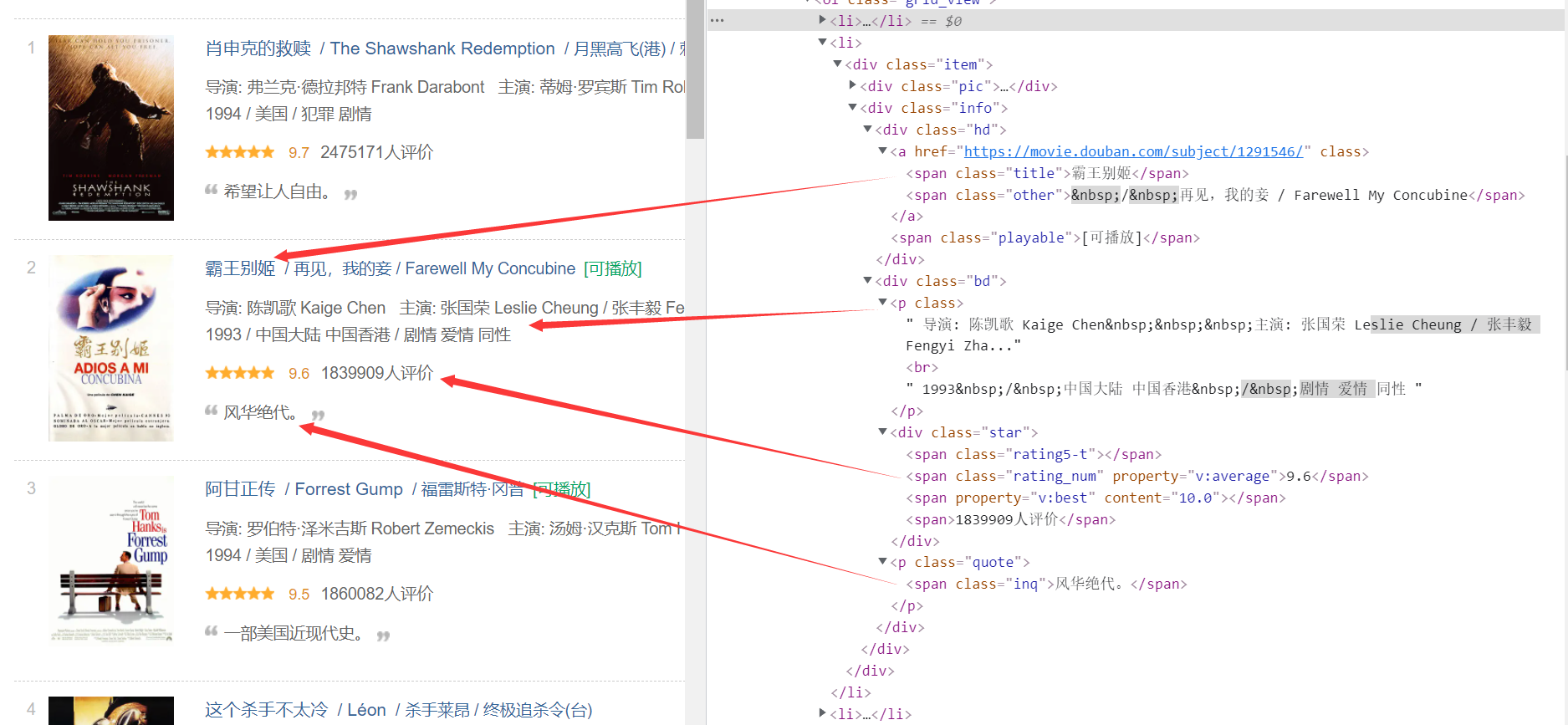
-
Write an Xpath expression according to the content of the source code to extract the corresponding information. First find all info tags, and then continue to use Xpath from the info tag to further extract information
-
Note that the introduction of some movies may be empty. You need to process None as an empty string, otherwise an error will be reported when saving to the database
# Parsing pages using xpath
movies = response.xpath('//div[@class="info"]')
for movie in movies:
name = movie.xpath('div[@class="hd"]/a/span/text()').extract_first() # Movie title
director_actors = movie.xpath('div[@class="bd"]/p[1]/text()[1]').extract_first().strip().replace('\xa0', '') # Director and starring
# Use regular expressions to further separate directors and stars
director = re.findall(p_director,str(director_actors))[0] # director
actor = re.findall(p_actor, str(director_actors)) # to star
info = movie.xpath('div[@class="bd"]/p[@class="quote"]/span/text()[1]').extract_first() # brief introduction
if info != None: # Profile may be empty
info = info.replace(". ", "") # Remove the period
else:
info= " "
score = movie.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract_first() # score
movielist.append([name,director,actor,info,score,page[i]])
i += 1
item['movies'] = movielist
-
Next, look at the page turning rules, which are relatively simple
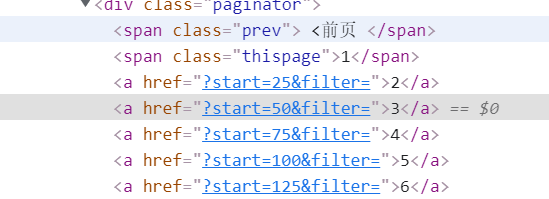
-
Page turning processing, 25 film information per page, 10 pages in total
if self.count<=10:
self.count += 1
next_url = 'https://movie.douban.com/top250?start='+str(self.count*25)
url = response.urljoin(next_url)
yield scrapy.Request(url=url, callback=self.parse,dont_filter=True)
3.3 output results
-
Console output results

-
Save to database results

-
Download pictures to local results
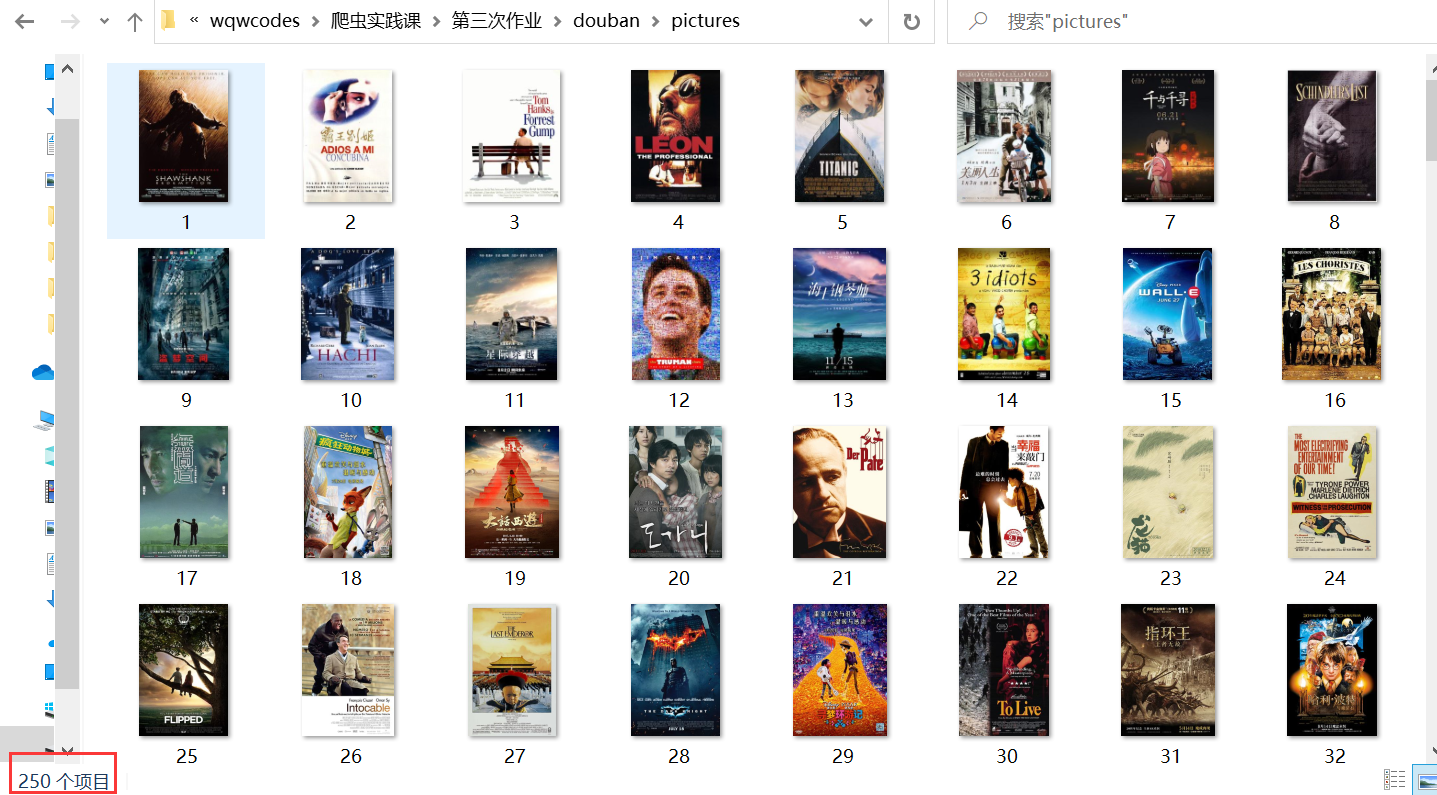
experience
- Learned the jump operation between pages and consolidated the page turning operation
- More familiar with the graph framework and xpath information extraction method
- Understand the difference between single thread and multi-threaded runtime, and the efficiency of concurrent execution will be higher