The anti-pickpocket mechanism of Taobao is much higher than that of other websites. Let's first talk about the problems I encounter in data acquisition.
- First of all, when I started with the request, I found that when the right-click open source code, the web page information could not be found at all in the source code... Wow, I cried.
- If you can't find the data, you can find the reasonse. When the data is displayed on the page, it must exist on the website. So I just randomly find a data on the page, open F12, search in the search box, and see where the data is.
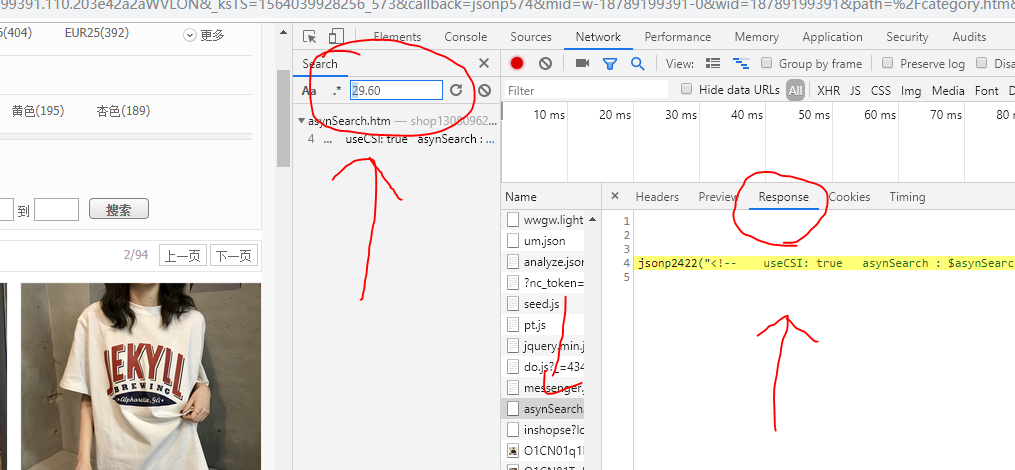
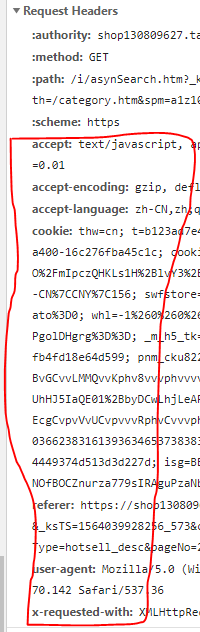
- After finding the data, some happy, I want to crawl down this data, a burst of requests plus the request head, here we must first login and then do the request head, there must be cookie s. And the request head should be comprehensive, the following pictures of these things are best put in, and then the data can be requested, if the requested data is not in response but a landing link, it may be disguised bad, the website recognized that not browser access, will pop up the login link.
- All the data can be matched, but how can I match what I need? Just too shallow to know how to match these useful data (cover your face), the data obtained is similar to the figure below.

Of course, I must take time to solve this problem, and then I decided to change the way of thinking, climb with selenium, omnipotent selenium ah!!!
I just want to talk about some problems and solutions in the process of climbing.
- selenium can get all the data displayed on the website, but one drawback is that it is slow.
- Every time selenium opens its browser, it will login to Taobao first, but Taobao login needs authentication code, but it is very useful to see that some predecessors wrote a third-party micro-blog login, which does not need sliding validation.
- I changed the code on the basis of this predecessor, so that I could get the data I wanted.
- However, the most important thing is that when the data is grasped to a certain extent (I only caught 1300), there will be sliding validation code, which must be sliding to continue to climb, but geese, I gave up, do not want to spend a lot of time to crack the sliding validation code, before cracking, I used a long time (continue to cover my face) to suggest if you want to get big. Quantity of data or to find a coding platform, can increase efficiency?
Here's my code: (borrowed from a predecessor's analog login, the link can't be found.)
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from time import sleep
import time
import pymysql
bprice = []
class taobao_infos:
def __init__(self,url):
self.url = 'https://login.taobao.com/member/login.jhtml'
# self.option = webdriver.ChromeOptions() headless mode
# self.option.add_argument('--headless')
# self.browser = webdriver.Chrome(options=self.option)
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 10)
#Processing landing information
def login(self):
self.browser.get(self.url)
sleep(6)
self.browser.find_element_by_xpath('//*[@class="forget-pwd J_Quick2Static"]').click()
sleep(2)
self.browser.find_element_by_xpath('//*[@class="weibo-login"]').click()
sleep(3)
self.browser.find_element_by_name('username').send_keys('Weibo account')
sleep(5)
self.browser.find_element_by_name('password').send_keys('Microblog password')
sleep(4)
self.browser.find_element_by_xpath('//*[@class="btn_tip"]/a/span').click()
def detil(self):
price = self.browser.find_elements_by_xpath('//span[@class="c-price"]')
title = self.browser.find_elements_by_xpath('//dd[@class="detail"]/a')
before_price = self.browser.find_elements_by_xpath('//*[@id="J_ShopSearchResult"]/div/div[2]/div/dl/dd/div/div[2]/span[2]')
data = self.browser.find_elements_by_xpath('//div[@class="sale-area"]/span')
comment = self.browser.find_elements_by_xpath('//div[@class="title"]/h4/a/span')
cur,coon = self.database()
for j in range(len(title)):
try:
name = title[j].text
nowprice = float(price[j].text)
currentprice = float(before_price[j].text)
saledata = float(data[j].text)
commentdata = float(comment[j].text)
ss = (str(name),float(nowprice),float(currentprice),int(saledata),int(commentdata))
sql = "insert into sanmuzi(name,nowprice,currentprice,saledata,commentdata) VALUE ('%s','%f','%f','%d','%d')"%ss
print(sql)
cur.execute(sql)
except Exception:
pass
coon.commit()
def database(self):
coon = pymysql.connect(
host='localhost', user='root', passwd='123456',
port=3306, db='taobao', charset='utf8'
# port must write int type
# charset must write utf8, not utf-8
)
cur = coon.cursor() # Establishment of cursors
# If you insert data, commit and replace line 9 with the following two lines
return cur,coon
import random
if __name__ == '__main__':
url = 'https://login.taobao.com/member/login.jhtml'
a = taobao_infos(url)
a.login()
time.sleep(random.uniform(5,8))
a.browser.get('Links you need to visit')
for i in range(30):
try:
a.detil()
time.sleep(random.uniform(10,15))
pages = a.browser.find_element_by_link_text("next page")
a.browser.execute_script("arguments[0].click();", pages)
except Exception :
pass