Click to view the first article: Data analysis starts from scratch. Pandas reads HTML pages + data processing and analysis_
Click to view the first article: Data analysis starts from zero to actual combat, and Pandas reads and writes CSV data_
Data analysis starts from zero to actual combat, and Pandas reads and writes CSV data
The previous two articles talked about data analysis, virtual environment creation and pandas reading and writing data in csv, tsv and json formats. Today, we continue to explore pandas reading data.
I. summary of basic knowledge
1. Use pandas to read and write Excel files
2. Use pandas to read and write XML files
Second, start thinking
1. Use Python to read and write Excel
Read, using the ExcelFile() method of the Pandas library.
Write, using to of Pandas Library_ Excel method.
code
import pandas as pd
import os
# Gets the parent directory path of the current file
father_path = os.getcwd()
# Original data file path
rpath_excel = father_path+r'\data01\realEstate_trans.xlsx'
# Data saving path
wpath_excel = father_path+r'\data01\temp_excel.xlsx'
# Open excel file
excel_file = pd.ExcelFile(rpath_excel)
# Read file contents
"""
ExcelFile Object parse()Method reads the contents of the specified worksheet
ExcelFile Object sheet_names Property can be obtained Excel All worksheets in the file
Dictionary expressions are also used to assign values to the dictionary (which looks more elegant)
"""
excel_read = {sheetName : excel_file.parse(sheetName) for sheetName in excel_file.sheet_names}
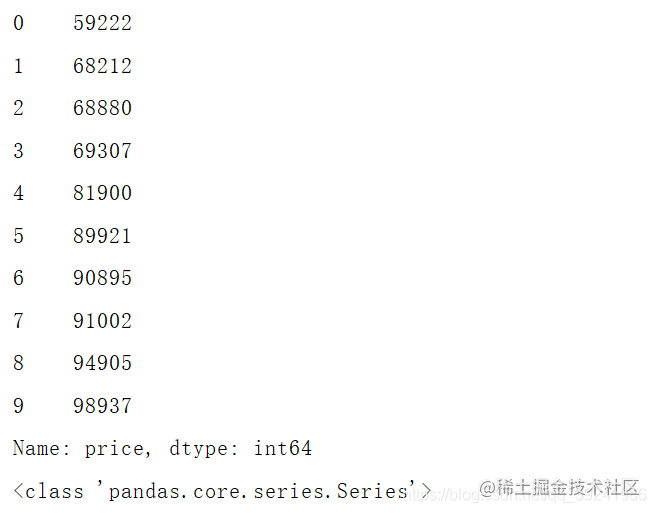
# Output the first 10 rows of the price column of the Sacramento table
print(excel_read['Sacramento'].head(10)['price'])
print(type(excel_read['Sacramento'].head(10)['price']))
# Encountered error: ModuleNotFoundError: No module named 'xlrd'
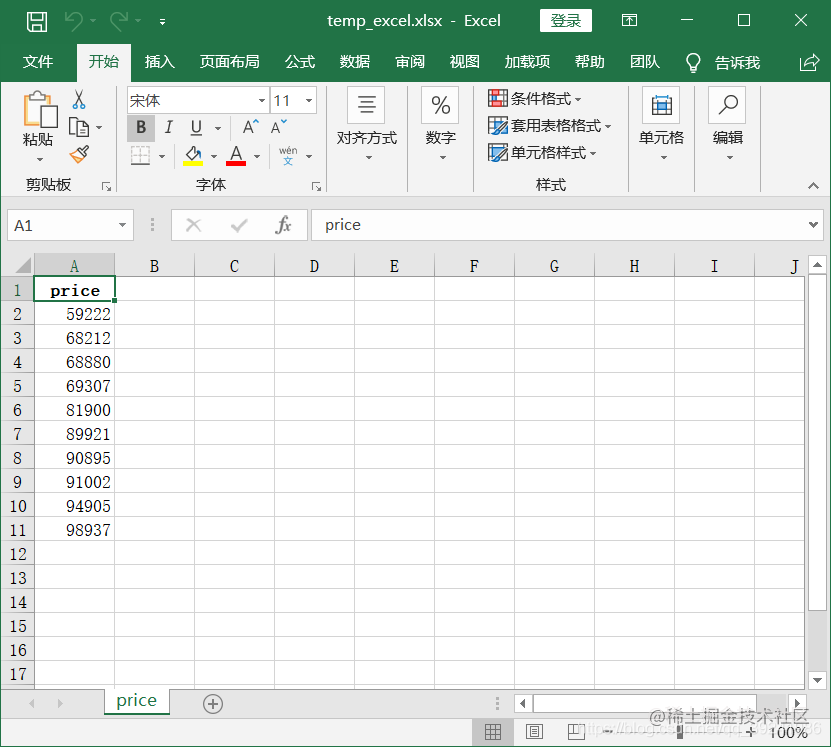
# Write the first 10 rows of the price column of the table
excel_read['Sacramento'].head(10)['price'].to_excel(wpath_excel, "price", index=False)
# Encountered error: ModuleNotFoundError: No module named 'openpyxl'
Copy codeRead results:
Write result:
Possible errors:
During read operation: ModuleNotFoundError: No module named 'xlrd' When writing: ModuleNotFoundError: No module named 'openpyxl' Copy code
resolvent:
# Install xlrd and openpyxl modules in the environment pip install xlrd pip install openpyxl Copy code
2. Use Python to read and write XML files
Students who have studied java should not be unfamiliar with XML. The full name is extensible markup language. Although it is not common at ordinary times, XML coding is supported in the Web API.
Read and write code
import pandas as pd
# A lightweight XML parser
import xml.etree.ElementTree as ET
import os
"""
Read in XML Data, return pa.DataFrame
"""
def read_xml(xml_FileName):
with open(xml_FileName, "r") as xml_file:
# Read the data and store it in a tree structure
tree = ET.parse(xml_file)
# Access the stem node of the tree
root = tree.getroot()
# Return data in DataFrame format
return pd.DataFrame(list(iter_records(root)))
"""
Traversing recorded generators
"""
def iter_records(records):
for record in records :
# Temporary dictionary for saving values
temp_dict = {}
# Traverse all fields
for var in record:
temp_dict[
var.attrib["var_name"]
] = var.text
# Generated value
yield temp_dict
"""
with XML Save data in format
"""
def write_xml(xmlFileName, data):
with open(xmlFileName, "w") as xmlFile:
# Write header
xmlFile.write(
'<?xml version="1.0" encoding="UTF-8"?>'
)
xmlFile.write('<records>\n')
# Write data
xmlFile.write(
'\n'.join(data.apply(xml_encode, axis=1))
)
# Write tail
xmlFile.write("\n</records>")
"""
Encode each line into a specific nested format XML
"""
def xml_encode(row):
# Step 1: output record node
xmlItem = [' <record>']
# Step 2 -- add XML format < field name = ·· > ·· < / field > to each field in the row
for field in row.index:
xmlItem.append(
'<var var_name="{0}">{1}</var>'.format(field, row[field])
)
# The last step -- mark the end tag of the record node
xmlItem.append(" </record>")
return '\n'.join(xmlItem)
# Gets the parent directory path of the current file
father_path = os.getcwd()
# Original data file path
rpath_xml = father_path+r'\data01\realEstate_trans.xml'
# Data saving path
wpath_xml = father_path+r'\data01\temp_xml.xml'
# Read data
xml_read = read_xml(rpath_xml)
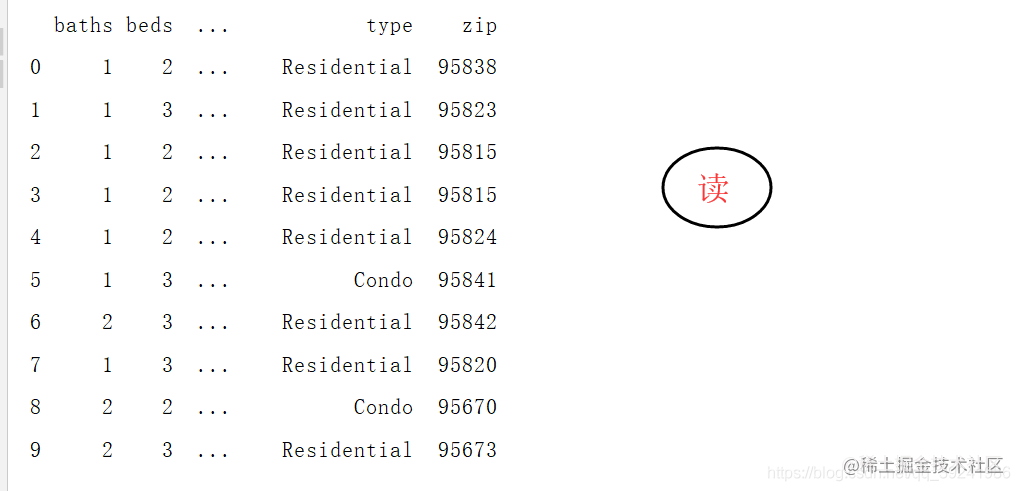
# Output header 10 Line records
print(xml_read.head(10))
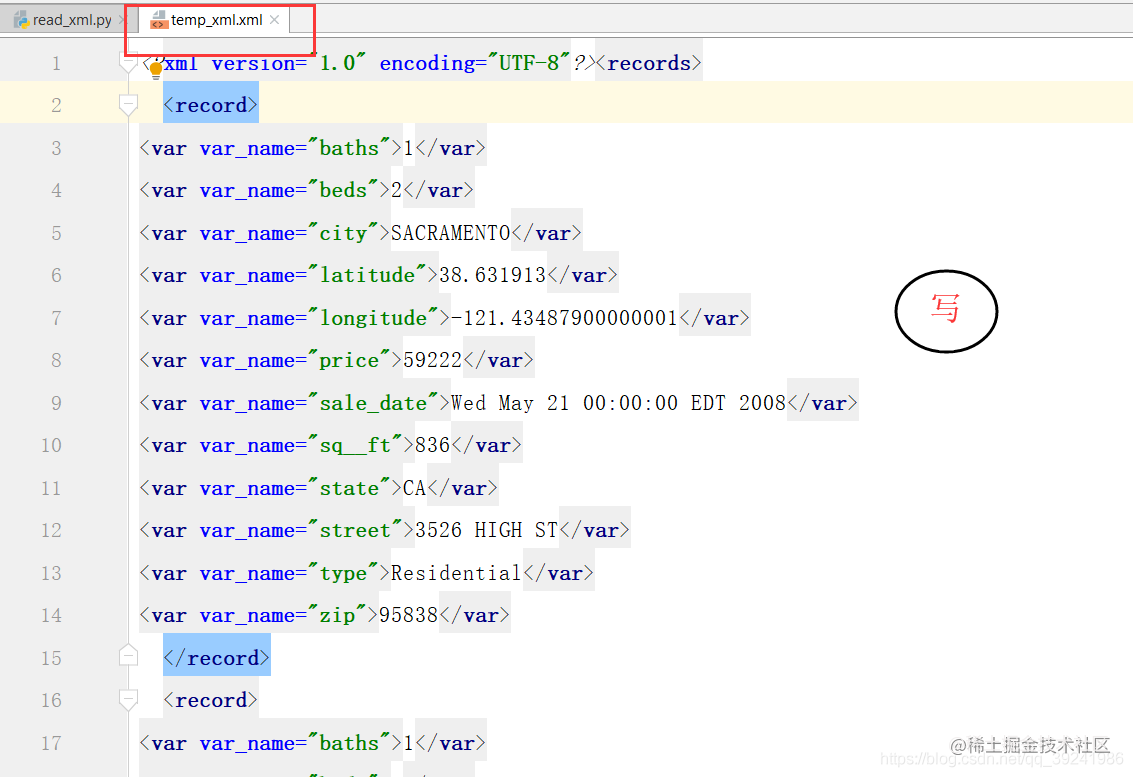
# Write back to the file in XML format
write_xml(wpath_xml, xml_read.head(10))
Copy codeOperation results
Code parsing
(1)read_xml(xml_FileName) function
Function: read in XML data and return pa.DataFrame
Here we use a lightweight XML parser: xml.etree.ElementTree. The file name is read, the file content is read first, then the XML is resolved by parse() function, a tree structure is created and stored in the tree variable, the getroot() method is called on the tree object to get the root node, and finally the iter_ is called. Records() function, pass in the root node, and then convert the returned information into DataFrame.
(2)iter_records(records) function
Function: traverse the recorded generator
iter_ The records () method is a generator, which can be seen from the keyword yield. Unlike return, the generator only returns one value to the calling method at a time until the end.
(3)write_xml(xmlFile, data) function
Function: save data in XML format
It should be noted here that we have to save according to the XML file format. What we need to do is three steps: save the header format, save the data according to the format, and save the tail format. When saving data, the apply() method of DataFrame object is used to traverse each internal row, and the first parameter is xml_encode specifies the method to be applied to each row of records. axis=1 means to process by row. The default value is 0, which means to process by column.
(4)xml_encode(row) function
Function: encode each row into XML in a specific nested format
In the process of writing data, we will call this method to process each row of data into XML format.
Three for you
I had a meeting yesterday and thought about writing. Here I share with you:
1. Ideological awareness, dialectical thinking. Don't follow suit, have your own opinions. Smart people should insist on outputting their own thoughts, think from the things themselves and other people's comments, correct their own thoughts, and then output;
2. Shout less slogans and do more practical things. Originally, I highly praised personal planning, but I found that not only my surroundings and some readers, including myself, planning is becoming more and more fake and empty. There is nothing wrong with the planning itself. The wrong thing is: in real life, we turn the planning into a daily slogan, and in order to complete it, so I now highly recommend: planning, do it first.