26 data analysis cases - the fifth stop: data collection based on the Scrapy architecture
Case environment
- Python: Python 3.x;
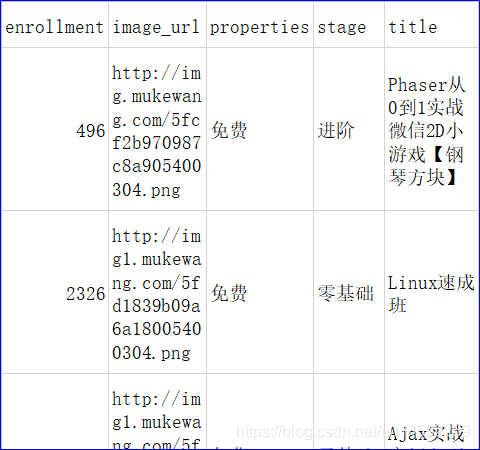
Data description
- title: Course title
- image_url: Title picture address.
- properties: course nature.
- Stage: course stage.
- enrollment: number of course applicants.
Data package
Link: https://pan.baidu.com/s/1-DUUUAOfpC4Gs5DAaHcgUg
Extraction code: 5u6s
Experimental steps
Step 1: PAGE analysis
Before crawling the data in a web page, we must first learn how to analyze the structure of the page. All the data we want are in that tag. Only by fully understanding the overall structure of the page can we crawl the data effectively and quickly., This actual combat case will crawl the page data of Mu class.
1. First open the browser and enter the web address http://www.imooc.com/course/list
Enter muke.com
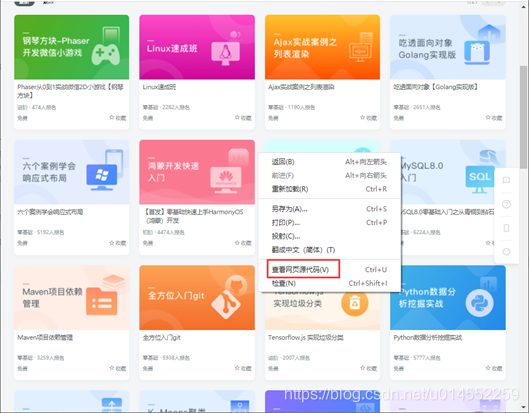
2. Right click in any blank area of the page to display the tool menu. The effect is:
3. Click view web page source code to view the data structure in the web page source code and analyze the structure
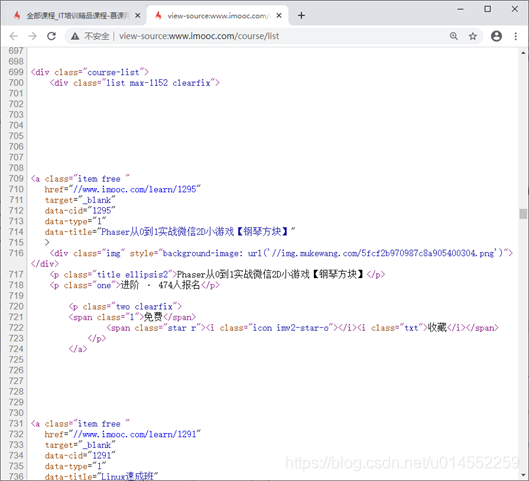
As can be clearly seen from the figure,
- The details of each course are contained in an a tag named "item free",
- The course title is contained in the p tag with class title ellipsis2;
- The current stage of the course and the total number of applicants are included in the p tag with class one;
- The course nature is included in the span tag with class "1";
- The title picture address is in the style attribute value of the div tag with class "img".
So far, we have a certain understanding of the data structure in the page. Let's start data collection.
The second step is to write code to collect data
1. Open the command window and create a Scrapy crawler project named "InternetWorm". The command is as follows.
scrapy startproject InternetWorm
The result is:

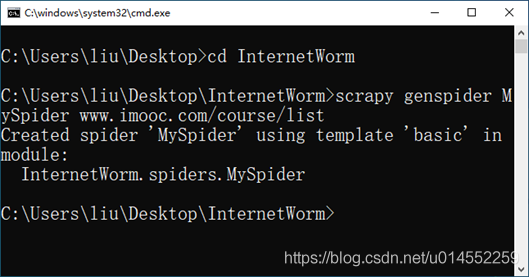
2. After the project is created, enter the root directory of the InternetWorm project. The code is as follows.
cd InternetWorm scrapy genspider MySpider www.imooc.com/course/list
The results are shown in the figure.
Open myspider.com in the root directory Py and write the following code.
# -*- coding: utf-8 -*-
import scrapy
class MyspiderSpider(scrapy.Spider):
name = 'MySpider'
allowed_domains = ['imooc.com']
start_urls = ['http://www.imooc.com/course/list/']
def parse(self, response):
pass
3. Open items Py, create a class named "CourseItem" in the change file, and define the relevant fields to crawl data.
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyprojectItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class CourseItem(scrapy.Item):
# Course title
title=scrapy.Field();
# Title picture address
image_url=scrapy.Field();
# Course nature
properties=scrapy.Field();
# Course stage
stage=scrapy.Field();
# Course enrollment
enrollment=scrapy.Field();
4. Open myspider Py file, modify allowed_domains (the domain name list is set to imooc.com), then import the Selector, parse the Response object, and use XPath to select all the list contents. The code is as follows.
# -*- coding: utf-8 -*-
import scrapy
# Import selector
from scrapy.selector import Selector
class MyspiderSpider(scrapy.Spider):
name = 'MySpider'
allowed_domains = ['imooc.com']
start_urls = ['http://www.imooc.com/course/list/']
def parse(self, response):
sel = Selector(response)
# Use xpath to select all the list contents
sels = sel.xpath('//a[@class="item free "]')
print(sels)
pass
5. Run crawler
scrapy crawl MySpider
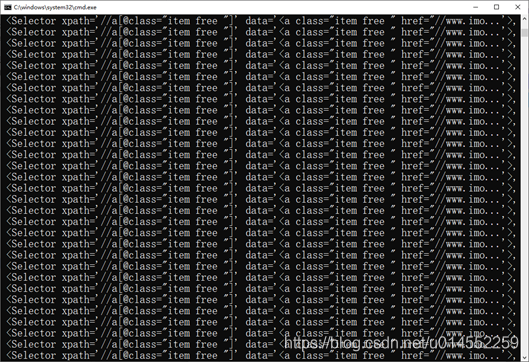
6. The program can run normally, indicating that the above steps are configured correctly. Open myspider Py file, put items Py, import and instantiate a new information storage container, and finally get the content and assign it to this container through traversal,
# -*- coding: utf-8 -*-
import scrapy
# Import selector
from scrapy.selector import Selector
# Import items Class defined in py file
from InternetWorm.items import CourseItem
class MyspiderSpider(scrapy.Spider):
name = 'MySpider'
allowed_domains = ['imooc.com']
start_urls = ['http://www.imooc.com/course/list/']
def parse(self, response):
sel = Selector(response)
# Use xpath to select all the list contents
sels = sel.xpath('//a[@class="item free "]')
# Instance a container to store crawling information
item = CourseItem()
# Traverse all lists
for box in sels:
# Get Course Title
item['title'] = box.xpath('.//p[@class="title ellipsis2"]/text()').extract()[0].strip()
print("Course title:",item['title'])
# Get Title picture address
item['image_url'] = box.xpath('.//div[@class="img"]/@style').extract()[0].strip()[23:-2]
print("Title picture address:","http:"+item['image_url'])
# Get the nature of the course
item['properties'] = box.xpath('.//span[@class="l"]/text()').extract()[0].strip()
print("Course nature:",item['properties'])
# Get course phase
item['stage'] = box.xpath('.//p[@class="one"]/text()').extract()[0].strip().split(" · ")[0]
print("Course stage:",item['stage'])
# Get course enrollment
item['enrollment'] = box.xpath('.//p[@class="one"]/text()').extract()[0].strip().split(" · ")[1][:-3]
print("Number of applicants:",item['enrollment'])
pass
Rerun the project.
scrapy crawl MySpider
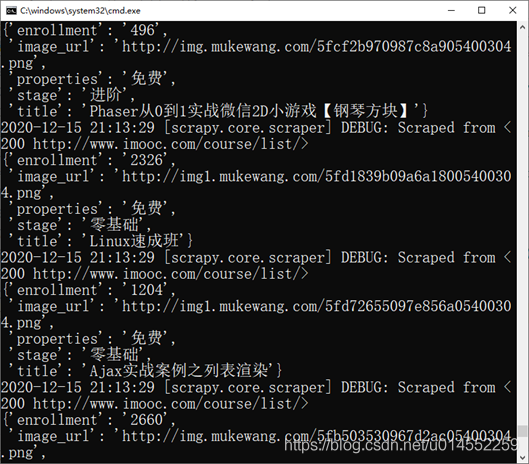
7. If you get the same result as me, congratulations on successfully crawling to the data in the web page. However, only one page of data can be read. Next, we will continue to modify the code to realize automatic page turning. Here, xpath is used to judge whether there is a label containing the next page in the page number label. If so, the label content will be obtained, and then combined into the web page address of the next page and passed through the script The request () method returns the parse() function and continues to crawl the course information of the page until the next page label does not exist in the page number label. Modify myspider Py file
# -*- coding: utf-8 -*-
import scrapy
# Import selector
from scrapy.selector import Selector
# Import items Class defined in py file
from InternetWorm.items import CourseItem
pageIndex = 0
class MyspiderSpider(scrapy.Spider):
name = 'MySpider'
allowed_domains = ['imooc.com']
start_urls = ['http://www.imooc.com/course/list']
def parse(self, response):
sel = Selector(response)
# Use xpath to select all the list contents
sels = sel.xpath('//a[@class="item free "]')
# Instance a container to store crawling information
item = CourseItem()
index = 0
global pageIndex
pageIndex += 1
print('The first' + str(pageIndex) + 'page ')
print('----------------------------------------------')
# Traverse all lists
for box in sels:
# Get Course Title
item['title'] = box.xpath('.//p[@class="title ellipsis2"]/text()').extract()[0].strip()
# Get Title picture address
item['image_url'] = "http:"+box.xpath('.//div[@class="img"]/@style').extract()[0].strip()[23:-2]
# Get the nature of the course
item['properties'] = box.xpath('.//span[@class="l"]/text()').extract()[0].strip()
# Get course phase
item['stage'] = box.xpath('.//p[@class="one"]/text()').extract()[0].strip().split(" · ")[0]
# Get course enrollment
item['enrollment'] = box.xpath('.//p[@class="one"]/text()').extract()[0].strip().split(" · ")[1][:-3]
index += 1
# Iteratively process the item and return a generator
yield item
next = u'next page'
url = response.xpath("//a[contains(text(),'" + next + "')]/@href").extract()
if url:
# Combine the information into the url of the next page
page = 'http://www.imooc.com' + url[0]
# Return url
yield scrapy.Request(page, callback=self.parse)
pass
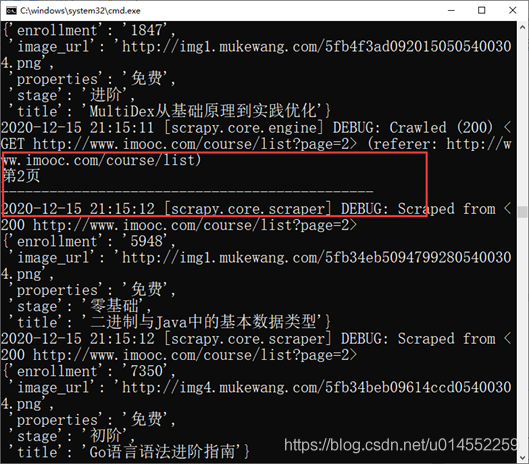
Re execute the project.
scrapy crawl MySpider
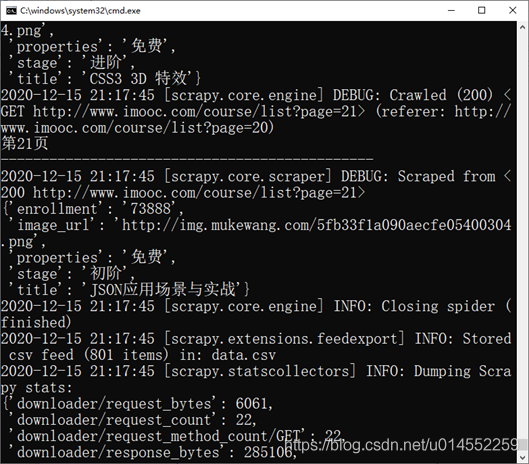
Finally, the crawled data can be saved to a file.
scrapy crawl MySpider -o data.csv
Follow up cases are continuously updated
01 HBase crown size query system based on Python
02 civil aviation customer value analysis based on Hive
03 analysis of pharmacy sales data based on python
04 web server log data collection based on Flume and Kafka
05 Muke network data acquisition and processing
06 Linux operating system real-time log collection and processing
07 medical industry case - Analysis of dialectical association rules of TCM diseases
08 education industry case - Analysis of College Students' life data
10 entertainment industry case - advertising revenue regression prediction model
11 network industry case - website access behavior analysis
12 retail industry case - real time statistics of popular goods in stores
13 visualization of turnover data
14 financial industry case - financial data analysis based on stock information of listed companies and its derivative variables
15 visualization of bank credit card risk data
Operation analysis of 16 didi cities
17 happiness index visualization
18 employee active resignation warning model
19 singer recommendation model
202020 novel coronavirus pneumonia data analysis
Data analysis of 21 Taobao shopping Carnival
22 shared single vehicle data analysis
23 face detection system
24 garment sorting system
25 mask wearing identification system
26 imdb movie data analysis