json
Purpose:
Encodes Python objects into JSON strings and decodes JSON strings into Python objects.
The JSON module provides an API to convert Python objects in memory into JSON sequences. JSON has the advantage of being implemented in multiple languages, especially JavaScript. It is widely used in the communication between Web server and client in the rest API. At the same time, it is also very useful for the communication requirements between applications. The following shows how to convert a python data structure to JSON:
1. Encoding and decoding
Python's default native types (str, int,float,list,tuple, and dict).
import json
data = {
'name ' : 'ACME',
' shares ' : 100,
'price ' : 542.23
}
json_str = json.dumps(data)
print(json_str)
On the surface, it is similar to the output of Python repr(). Although the content seems to be the same, the type has changed
print(type(json_str))
From an unordered dictionary to an ordered string, this process is called serialization.
Finally, we save json to a file
with open('data.json ',mode='w',encoding='utf-8') as f:
f.write(json_str)
1.1 Chinese string problem
import json
data = {
'name ' : 'oil lamp',
'shares': 100,
'price' : 542.23
}
#Serialize dictionary as json
json_str = json.dumps(data)
# Write json data
with open( ' data.json',mode='w', encoding='utf-8 ' ) as f:
f.write(json_str)
# filename:data.json
{ "name": "\u9752\u706f","shares" : 100,"price": 542.23}
Solution: json_str = json. dumps(data,ensure_ascii=False)
2. Read numbers
The process of changing json data into dictionary type is called deserialization
#Read json data with open( ' data.json ', 'r', encoding='utf-8') as f: #Deserialization data = json.1oad(f) #print data print(data) print(data[ 'name '])
- Format output
The result of JSON is easier to read. The dumps() function accepts several parameters to make the output more readable.
import json
data = {'a ' : 'A','b' : (2,4),'c' : 3.0}
print( 'DATA: ', repr(data)) # DATA: { 'a' : 'A', 'b ': (2,4),'c': 3.0}
unsorted = json.dumps(data)
print( '7SON: ', json.dumps(data)) #JSON: {"a": "A","b":[2,4],"c": 3.03}
Encoding and then re decoding may not give exactly the same type of object.
In particular, the elements are composed into lists.
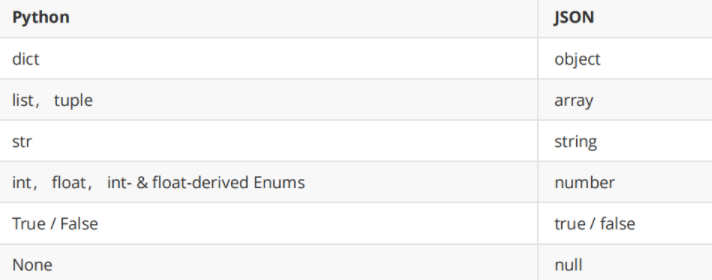
JSON is actually the same as the dictionary in Python. In fact, it is easy to find the corresponding relationship between JSON data types and python data types, as shown in the following two tables.
To learn more knowledge or answer questions, source code and tutorials, please click
Introduction to CSV module
csv file format is a general format for importing and exporting spreadsheets and databases. Recently, when I call RPC to process server data, I often need to archive the data, so I use this convenient format.
python has a package for reading and writing csv files. You can import csv directly. Using this python package, you can easily operate csv files. Some simple usages are as follows.
1. Write file
We put the data to be written into the list. When writing the file, we will write the elements in the list into the csv file.
import csv
ll = [[1,2,3,4],
[1,2,3,4],
[5,6,7,8],
[5,6,7,8]]
with open( ' example1.csv', 'w' , newline=' ') as csvfile:
"""
delimiter:Separator
"""
spamwriter = csv.writer(csvfile,delimiter=', ')
for 1 in 11:
spamwriter.writerow([1,2,3,4])
Possible problems: directly using this writing method will lead to an empty line after each line of the file. Use newline = '' to solve
Write directly using open
with open( 'examp1e2.csv', 'w') as csvfile:
"""
delimiter:Separator
"""
for 1 in 17:
csvfile.write(",".join(map(str,1)))
csvfile.write( ' \n ')
2. Read the file
import csv
with open( ' example.csv ' , encoding='utf-8' ) as f:
csv_reader = csv.reader(f)
for row in csv_reader:
print(row)
fi7e: example. CSV data

By default, commas are used as delimiters for reading and writing. In special cases, you can manually specify characters as needed, such as:
with open( ' example.csv', encoding='utf-8' ) as f:
reader = csv.reader(f,delimiter=' , ')
for row in reader:
print(row)
The above example specifies a colon as the separator
It should be noted that when writing data with writer, None will be written as an empty string, and the floating-point type will be converted into a string by calling the repr() method. Therefore, non string data will be stored as strings by str(). Therefore, when it comes to unicode strings, you can store them manually or use the Unicode writer provided by csv.
3. Write and read dictionary
csv also provides a dictionary like way of reading and writing, as follows:

Where fieldnames specifies the key value of the dictionary. If it is not specified in the reader, the element in the first row by default must be specified in the writer.
#%%Write
import csv
with open( ' names.csv', 'w ') as csvfile:
fieldnames = ['first_name ', 'last_name ']
writer = csv.Dictwriter(csvfi1e,fieldnames=fieldnames)
writer.writeheader()
writer.writerow(i'first_name ' : 'Baked', 'last_name ' : 'Beans' })
writer.writerow(i'first_name ' : 'Love1y'})
writer.writerow(i 'first_name ' : 'wonderfu7 ', '7ast_name': 'spam ' })
#%%Read
import csv
with open( ' names.csv ', newline=' ') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row[ 'first_name'],row[ ' 1ast_name ' ])