Source code for this article: GitHub. Click here || GitEE. Click here
1. Introduction to Column Library
ClickHouse is the 2016 Open Source Column Storage Database (DBMS) of Yandex, Russia. It is mainly used for OLAP online analysis processing queries, and can use SQL queries to generate real-time analysis data reports.
Column storage
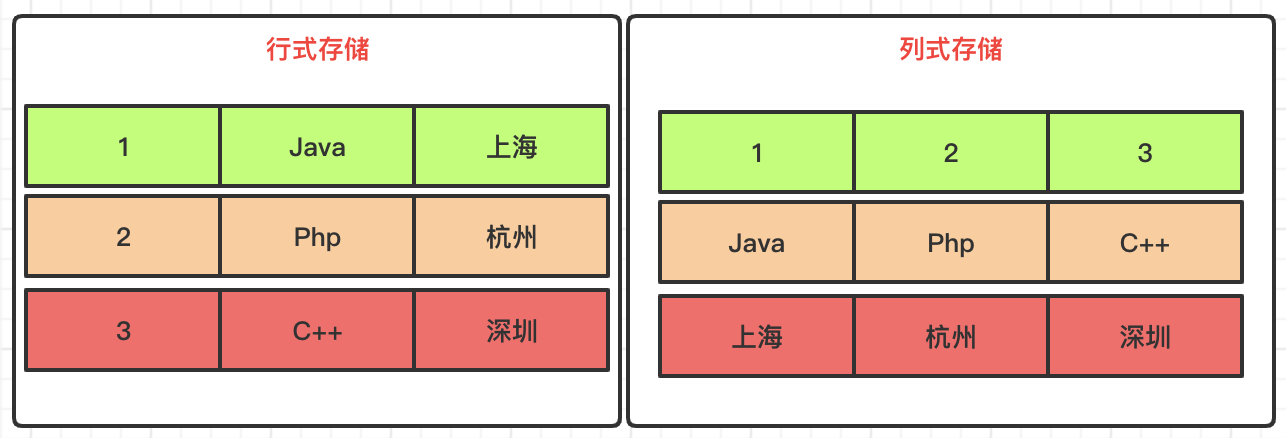
Row storage and column storage, the organization of data on disk is fundamentally different. When data analysis and calculation, row storage needs to traverse the entire table, while column storage only needs to traverse a single column, so column libraries are more suitable for large and wide tables for data analysis and calculation.
Note that the scenarios compared here are those of data analysis and calculation.
2. Cluster Configuration
1. Basic Environment
ClickHouse Single Service is installed by default
- Install ClickHouse single machine service on Linux
- SpringBoot Integration ClickHouse Column Database
2. Remove file restrictions
vim /etc/security/limits.conf vim /etc/security/limits.d/90-nproc.conf //Append to end of file * soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072
3. Cancel SELINUX
Restart after modifying SELINUX=disabled in /etc/selinux/config
4. Cluster Profile
Services add cluster configurations separately: vim/etc/metrika.xml
<yandex> <clickhouse_remote_servers> <clickhouse_cluster> <shard> <internal_replication>true</internal_replication> <replica> <host>192.168.72.133</host> <port>9000</port> </replica> </shard> <shard> <replica> <internal_replication>true</internal_replication> <host>192.168.72.136</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>192.168.72.137</host> <port>9000</port> </replica> </shard> </clickhouse_cluster> </clickhouse_remote_servers> <zookeeper-servers> <node index="1"> <host>192.168.72.133</host> <port>2181</port> </node> <node index="2"> <host>192.168.72.136</host> <port>2181</port> </node> <node index="3"> <host>192.168.72.137</host> <port>2181</port> </node> </zookeeper-servers> <macros> <replica>192.168.72.133</replica> </macros> <networks> <ip>::/0</ip> </networks> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </yandex>
Notice here
<macros> <replica>192.168.72.133</replica> </macros>
Configure the IP addresses of each service.
5. Start Cluster
Start three services separately
service clickhouse-server start
6. Logon Client View
Just log in to any service here
clickhouse-client en-master :) select * from system.clusters
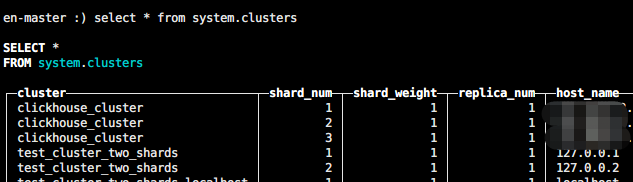
Here's the cluster name: clickhouse_cluster for later use.
7. Basic environmental testing
Create table structure on three services at the same time.
CREATE TABLE ontime_local (FlightDate Date,Year UInt16) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
133 Environment Create Distribution Table
CREATE TABLE ontime_all AS ontime_local ENGINE = Distributed(clickhouse_cluster, default, ontime_local, rand());
Write any service data
insert into ontime_local (FlightDate,Year) values ('2020-03-12',2020);
Query Total Table
select * from ontime_all;
Write to the total table and the data will be distributed among the individual forms
insert into ontime_all (FlightDate,Year)values('2001-10-12',2001); insert into ontime_all (FlightDate,Year)values('2002-10-12',2002); insert into ontime_all (FlightDate,Year)values('2003-10-12',2003);
Any one service is shut down and cluster queries are directly suspended
3. Integration of Cluster Environment
1. Basic Configuration
url: Configure the entire list of services, mainly to manage the table structure, batch processing;
cluster: cluster connection service, which can be configured based on Nginx proxy service;
spring: datasource: type: com.alibaba.druid.pool.DruidDataSource click: driverClassName: ru.yandex.clickhouse.ClickHouseDriver url: jdbc:clickhouse://127.0.0.1:8123/default,jdbc:clickhouse://127.0.0.1:8123/default,jdbc:clickhouse://127.0.0.1:8123/default cluster: jdbc:clickhouse://127.0.0.1:8123/default initialSize: 10 maxActive: 100 minIdle: 10 maxWait: 6000
2. Management Interface
Create tables and write data to each single-node service, respectively:
Data_shard (single-node data)
Data_all (distribution data)
@RestController public class DataShardWeb { @Resource private JdbcFactory jdbcFactory ; /** * Infrastructure creation */ @GetMapping("/createTable") public String createTable (){ List<JdbcTemplate> jdbcTemplateList = jdbcFactory.getJdbcList(); for (JdbcTemplate jdbcTemplate:jdbcTemplateList){ jdbcTemplate.execute("CREATE TABLE data_shard (FlightDate Date,Year UInt16) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192)"); jdbcTemplate.execute("CREATE TABLE data_all AS data_shard ENGINE = Distributed(clickhouse_cluster, default, data_shard, rand())"); } return "success" ; } /** * Node table write data */ @GetMapping("/insertData") public String insertData (){ List<JdbcTemplate> jdbcTemplateList = jdbcFactory.getJdbcList(); for (JdbcTemplate jdbcTemplate:jdbcTemplateList){ jdbcTemplate.execute("insert into data_shard (FlightDate,Year) values ('2020-04-12',2020)"); } return "success" ; } }
3. Cluster Query
When the above steps are completed, you can join the cluster service to query the data of the distribution master table and the table.
Druid-based Connection
@Configuration public class DruidConfig { @Resource private JdbcParamConfig jdbcParamConfig ; @Bean public DataSource dataSource() { DruidDataSource datasource = new DruidDataSource(); datasource.setUrl(jdbcParamConfig.getCluster()); datasource.setDriverClassName(jdbcParamConfig.getDriverClassName()); datasource.setInitialSize(jdbcParamConfig.getInitialSize()); datasource.setMinIdle(jdbcParamConfig.getMinIdle()); datasource.setMaxActive(jdbcParamConfig.getMaxActive()); datasource.setMaxWait(jdbcParamConfig.getMaxWait()); return datasource; } }
Based on mapper query
<mapper namespace="com.ckhouse.cluster.mapper.DataAllMapper"> <resultMap id="BaseResultMap" type="com.ckhouse.cluster.entity.DataAllEntity"> <result column="FlightDate" jdbcType="VARCHAR" property="flightDate" /> <result column="Year" jdbcType="INTEGER" property="year" /> </resultMap> <select id="getList" resultMap="BaseResultMap" > select * from data_all where Year=2020 </select> </mapper>
4. Source code address
GitHub·address https://github.com/cicadasmile/data-manage-parent GitEE·address https://gitee.com/cicadasmile/data-manage-parent
