1, Basic principles
Ensemble learning completes the learning task by constructing and combining multiple learners, so as to improve the generalization and stability performance better than a single learner. To achieve good integration effect, individual learners should be "good and different". According to the generation mode of individual learners, ensemble learning can be divided into two categories: sequence integration method, that is, individual learners have strong dependencies and must be generated serially, such as Boosting; Parallel integration method, that is, individual learners do not have strong dependencies and can be generated in parallel, such as Bagging and random forest.
2, Boosting
Boosting refers to converting a weak learner into a strong learner through an algorithm set. The main principle of boosting is to train a series of weak learners. The so-called weak learner refers to a model that is only a little better than random guess, such as a small decision tree. The training method is to use weighted data. In the early stage of training, a large weight is given to the misclassification data. Its working mechanism is as follows:
- Firstly, a basic learner is trained from the initial training set;
- Then, the distribution of training samples is adjusted according to the performance of the base learner, so that the training samples wrong by the base learner receive more attention in the follow-up;
- Training the next base learner based on the adjusted sample distribution;
- Repeat the above steps until the number of base learners reaches the predetermined value T, and finally combine the T base learners weighted.
Several typical Boosting methods are introduced below.

import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
wine = load_wine()
print(f"All features:{wine.feature_names}")
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)
base_model = DecisionTreeClassifier(max_depth=1, criterion='gini',random_state=1).fit(X_train, y_train)
y_pred = base_model.predict(X_test)
print(f"Accuracy of decision tree:{accuracy_score(y_test,y_pred):.3f}")
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(base_estimator=base_model,
n_estimators=50,
learning_rate=0.5,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"AdaBoost Accuracy of:{accuracy_score(y_test,y_pred):.3f}")
# Influence of the number of test estimators
x = list(range(2, 102, 2))
y = []
for i in x:
model = AdaBoostClassifier(base_estimator=base_model,
n_estimators=i,
learning_rate=0.5,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train, y_train)
model_test_sc = accuracy_score(y_test, model.predict(X_test))
y.append(model_test_sc)
plt.style.use('ggplot')
plt.title("Effect of n_estimators", pad=20)
plt.xlabel("Number of base estimators")
plt.ylabel("Test accuracy of AdaBoost")
plt.plot(x, y)
plt.show()
# Test the impact of learning rate
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
y = []
for i in x:
model = AdaBoostClassifier(base_estimator=base_model,
n_estimators=50,
learning_rate=i,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train, y_train)
model_test_sc = accuracy_score(y_test, model.predict(X_test))
y.append(model_test_sc)
plt.title("Effect of learning_rate", pad=20)
plt.xlabel("Learning rate")
plt.ylabel("Test accuracy of AdaBoost")
plt.plot(x, y)
plt.show()
# Auto tuning using GridSearchCV
hyperparameter_space = {'n_estimators':list(range(2, 102, 2)),
'learning_rate':[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]}
gs = GridSearchCV(AdaBoostClassifier(base_estimator=base_model,
algorithm='SAMME.R',
random_state=1),
param_grid=hyperparameter_space,
scoring="accuracy", n_jobs=-1, cv=5)
gs.fit(X_train, y_train)
print("Optimal hyperparameter:", gs.best_params_)


3, Bagging




3, Stacking
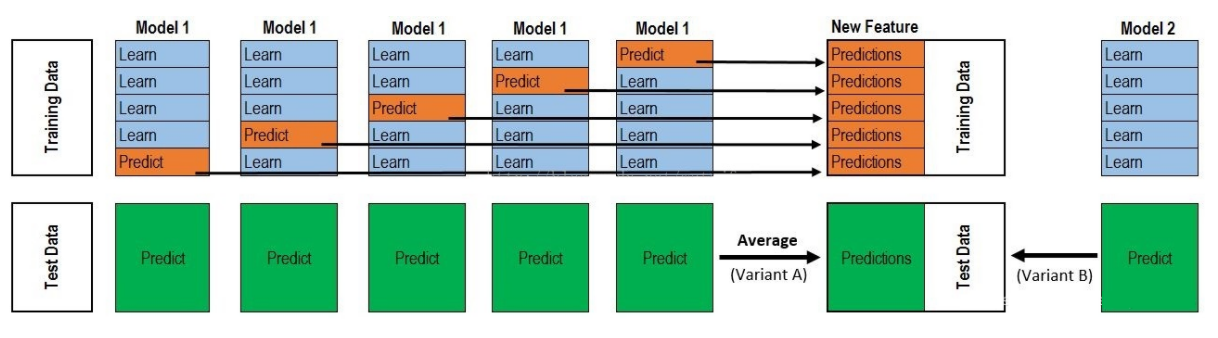
1. Basic idea of stacking
The method used when combining individual learners is called combination strategy. For the classification problem, we can use the voting method to select the class with the most output. For the regression problem, we can average the results of the classifier. Voting method and average method are very effective combination strategies. Another combination strategy is to use another machine learning algorithm to combine the results of individual machine learners. This method is stacking. In the stacking method, we call the individual learner as the primary learner, the learner used for combination as the secondary learner or meta learner, and the data used for training by the secondary learner as the secondary training set. The secondary training set is obtained by using the primary learner on the training set.