datax source code analysis - detailed explanation of task splitting mechanism
Write in front
The version of the source code analysis is 3.0. Because plug-ins are an important part of datax, the source code of plug-ins will be involved in the process of source code analysis. In order to maintain consistency, plug-ins have been illustrated by mysql, which is familiar to most people.
In this article, let's take a look at the task splitting mechanism of datax.
text
Let's look at a picture first,
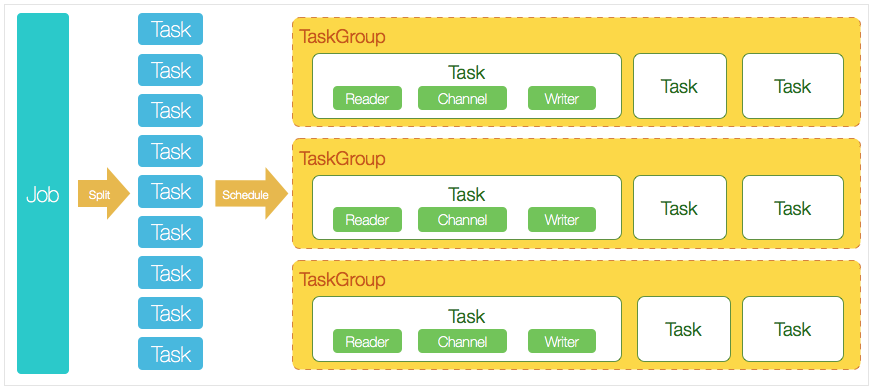
This figure is mainly used to understand the relationship and concepts between job and task in datax.
- DataX completes a single data synchronization Job, which is called a Job. After dataX receives a Job, it will start a process to complete the whole Job synchronization process. DataX Job module is the central management node of a single Job, which undertakes the functions of data cleaning, subtask segmentation (converting single Job calculation into multiple subtasks), TaskGroup management, etc.
- After DataXJob is started, it will be divided into multiple small tasks (subtasks) according to different source side segmentation strategies to facilitate concurrent execution. Task is the smallest unit of DataX Job. Each task is responsible for the synchronization of some data.
- After splitting multiple tasks, the DataX Job will call the Scheduler module to reassemble the split tasks into a TaskGroup (Task group) according to the configured amount of concurrent data. Each Task group is responsible for running all assigned tasks with a certain concurrency. By default, the concurrency of a single Task group is 5.
- Each Task is started by the TaskGroup. After the Task is started, the Reader - > Channel - > writer thread will be started to complete Task synchronization.
- After the DataX Job runs, the Job monitors and waits for multiple TaskGroup module tasks to complete. After all TaskGroup tasks are completed, the Job exits successfully. Otherwise, the process exits abnormally, and the process exit value is not 0
This article is actually the second step we focus on, splitting task s.
The entry function of task splitting is com alibaba. datax. core. job. Jobcontainer #split, let's analyze this method a little bit.
//Calculate needChannelNumber
this.adjustChannelNumber();
if (this.needChannelNumber <= 0) {
this.needChannelNumber = 1;
}
//Split read plug-ins, return the configuration list containing each split read plug-in, and use one for subsequent services
List<Configuration> readerTaskConfigs = this
.doReaderSplit(this.needChannelNumber);
...
The first is to calculate the needChannelNumber variable, which is the basis for splitting into task s later. The adjustChannelNumber method is as follows:
private void adjustChannelNumber() {
int needChannelNumberByByte = Integer.MAX_VALUE;
int needChannelNumberByRecord = Integer.MAX_VALUE;
//Whether the byte speed limit is specified, from the task configuration file
boolean isByteLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 0) > 0);
if (isByteLimit) {
//Global speed limit bytes
long globalLimitedByteSpeed = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 10 * 1024 * 1024);
// In the case of byte flow control, the maximum flow of a single Channel must be set, otherwise an error is reported!
Long channelLimitedByteSpeed = this.configuration
.getLong(CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_BYTE);
if (channelLimitedByteSpeed == null || channelLimitedByteSpeed <= 0) {
throw DataXException.asDataXException(
FrameworkErrorCode.CONFIG_ERROR,
"There is always bps Single under speed limit channel of bps The value cannot be empty or non positive");
}
//Calculate the number of channel s
needChannelNumberByByte =
(int) (globalLimitedByteSpeed / channelLimitedByteSpeed);
needChannelNumberByByte =
needChannelNumberByByte > 0 ? needChannelNumberByByte : 1;
LOG.info("Job set Max-Byte-Speed to " + globalLimitedByteSpeed + " bytes.");
}
//Is the record quantity current limit specified
boolean isRecordLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 0)) > 0;
if (isRecordLimit) {
long globalLimitedRecordSpeed = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 100000);
Long channelLimitedRecordSpeed = this.configuration.getLong(
CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_RECORD);
if (channelLimitedRecordSpeed == null || channelLimitedRecordSpeed <= 0) {
throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,
"There is always tps Single under speed limit channel of tps The value cannot be empty or non positive");
}
needChannelNumberByRecord =
(int) (globalLimitedRecordSpeed / channelLimitedRecordSpeed);
needChannelNumberByRecord =
needChannelNumberByRecord > 0 ? needChannelNumberByRecord : 1;
LOG.info("Job set Max-Record-Speed to " + globalLimitedRecordSpeed + " records.");
}
// Take the smaller value
this.needChannelNumber = needChannelNumberByByte < needChannelNumberByRecord ?
needChannelNumberByByte : needChannelNumberByRecord;
// If needChannelNumber is set from byte or record, exit
if (this.needChannelNumber < Integer.MAX_VALUE) {
return;
}
//Is the number of channel s specified directly
boolean isChannelLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL, 0) > 0);
if (isChannelLimit) {
this.needChannelNumber = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL);
LOG.info("Job set Channel-Number to " + this.needChannelNumber
+ " channels.");
return;
}
throw DataXException.asDataXException(
FrameworkErrorCode.CONFIG_ERROR,
"Job The operating speed must be set");
}
The note is written in detail. The logic of this method is to calculate the number of concurrent A according to the specified byte limit. If the current limit of the number of records is specified, A concurrent number B is calculated accordingly. Then take the minimum of A and B as the value of needChannelNumber variable. If neither current limit is specified, check whether the configuration file specifies the number of channel concurrency. An example of configuration is as follows:
{
"core": {
"transport" : {
"channel": {
"speed": {
"record": 100,
"byte": 100
}
}
}
},
"job": {
"setting": {
"speed": {
"record": 5000,
"byte": 10000,
"channel" : 1
}
}
}
}
Or directly specify the number of channel s:
"job": {
"setting":{
"speed":{
"channel":"2"
}
}
}
Continue to look at the split code,
//Split read plug-ins, return the configuration list containing each split read plug-in, and use one for subsequent services
List<Configuration> readerTaskConfigs = this
.doReaderSplit(this.needChannelNumber);
//Number of tasks split
int taskNumber = readerTaskConfigs.size();
//First remove the reader, then the writer
List<Configuration> writerTaskConfigs = this
.doWriterSplit(taskNumber);
...
It seems a little strange here. Why does the reader split the incoming needChannelNumber and the writer split the input parameter is taskNumber. This is because the execution logic of datax is that the reader must be segmented first, and then the writer is segmented according to the number of readers. It's understandable to think about this. After all, the source of transmission is the reader. It's natural to divide the work according to the reader.
Drill down to the doReaderSplit method and continue,
private List<Configuration> doReaderSplit(int adviceNumber) {
classLoaderSwapper.setCurrentThreadClassLoader(LoadUtil.getJarLoader(
PluginType.READER, this.readerPluginName));
//Internal or call the split of the plug-in
List<Configuration> readerSlicesConfigs =
this.jobReader.split(adviceNumber);
if (readerSlicesConfigs == null || readerSlicesConfigs.size() <= 0) {
throw DataXException.asDataXException(
FrameworkErrorCode.PLUGIN_SPLIT_ERROR,
"reader Segmented task Number cannot be less than or equal to 0");
}
LOG.info("DataX Reader.Job [{}] splits to [{}] tasks.",
this.readerPluginName, readerSlicesConfigs.size());
classLoaderSwapper.restoreCurrentThreadClassLoader();
return readerSlicesConfigs;
}
Nothing, because the plug-in is entrusted with its own split method to split. Here, take mysql as an example, and finally call com alibaba. datax. plugin. rdbms. reader. util. Readersplitutil#dosplit method, let's take a look,
public static List<Configuration> doSplit(
Configuration originalSliceConfig, int adviceNumber) {
//The default isTableMode is true
boolean isTableMode = originalSliceConfig.getBool(Constant.IS_TABLE_MODE).booleanValue();
int eachTableShouldSplittedNumber = -1;
if (isTableMode) {
// adviceNumber here is the number of channel s, that is, the number of datax concurrent task s
// eachTableShouldSplittedNumber is the number of copies of a single table that should be split. Rounding up may not be proportional to adviceNumber
eachTableShouldSplittedNumber = calculateEachTableShouldSplittedNumber(
adviceNumber, originalSliceConfig.getInt(Constant.TABLE_NUMBER_MARK));
}
//Get column information from configuration file
String column = originalSliceConfig.getString(Key.COLUMN);
//Get the where setting from the configuration file. If the configuration file is not specified, it is empty
String where = originalSliceConfig.getString(Key.WHERE, null);
//Database connection information. This only refers to the connection information of the reader
List<Object> conns = originalSliceConfig.getList(Constant.CONN_MARK, Object.class);
List<Configuration> splittedConfigs = new ArrayList<Configuration>();
for (int i = 0, len = conns.size(); i < len; i++) {
Configuration sliceConfig = originalSliceConfig.clone();
Configuration connConf = Configuration.from(conns.get(i).toString());
String jdbcUrl = connConf.getString(Key.JDBC_URL);
sliceConfig.set(Key.JDBC_URL, jdbcUrl);
// Extract the ip/port in the jdbcUrl to mark the resource usage, so as to provide it to the core for meaningful shuffle operation
sliceConfig.set(CommonConstant.LOAD_BALANCE_RESOURCE_MARK, DataBaseType.parseIpFromJdbcUrl(jdbcUrl));
sliceConfig.remove(Constant.CONN_MARK);
Configuration tempSlice;
// Description is the table mode of configuration
if (isTableMode) {
// It has been expanded and processed before and can be used directly
List<String> tables = connConf.getList(Key.TABLE, String.class);
Validate.isTrue(null != tables && !tables.isEmpty(), "You read the database table configuration error.");
//Do you want to split further according to the primary key? If the configuration file does not specify it, it does not need to be split
String splitPk = originalSliceConfig.getString(Key.SPLIT_PK, null);
//The number of final shards is not necessarily equal to eachTableShouldSplittedNumber
boolean needSplitTable = eachTableShouldSplittedNumber > 1
&& StringUtils.isNotBlank(splitPk);
//Do you want to split a single table
//When the concurrency requirement is high and the splitpk (table split primary key) parameter is configured, single table splitting is required
if (needSplitTable) {
if (tables.size() == 1) {
//Original: if it is a single table, the primary key segmentation is num=num*2+1
// In the case of splitPk is null, the data volume is much less than the real data volume. It is not recommended to consider the relationship with the channel size ratio
//eachTableShouldSplittedNumber = eachTableShouldSplittedNumber * 2 + 1;// You should not add 1 to cause a long tail
//Consider other ratio figures? (splitPk is null, ignoring this long tail)
//eachTableShouldSplittedNumber = eachTableShouldSplittedNumber * 5;
//To avoid importing hive files, the default cardinality is 5. You can configure the cardinality through splitFactor
// The final number of task s is (channel/tableNum) rounded up * splitFactor
Integer splitFactor = originalSliceConfig.getInt(Key.SPLIT_FACTOR, Constant.SPLIT_FACTOR);
eachTableShouldSplittedNumber = eachTableShouldSplittedNumber * splitFactor;
}
// Try splitting each table into eachtableshouldsplittednumbers
for (String table : tables) {
tempSlice = sliceConfig.clone();
tempSlice.set(Key.TABLE, table);
List<Configuration> splittedSlices = SingleTableSplitUtil
.splitSingleTable(tempSlice, eachTableShouldSplittedNumber);
splittedConfigs.addAll(splittedSlices);
}
} else {
for (String table : tables) {
tempSlice = sliceConfig.clone();
tempSlice.set(Key.TABLE, table);
String queryColumn = HintUtil.buildQueryColumn(jdbcUrl, table, column);
//Examples of sql: select col1,col2,col3 from table1
tempSlice.set(Key.QUERY_SQL, SingleTableSplitUtil.buildQuerySql(queryColumn, table, where));
splittedConfigs.add(tempSlice);
}
}
} else {
// Description is the querySql mode of configuration
List<String> sqls = connConf.getList(Key.QUERY_SQL, String.class);
// Is TODO check configured as multiple statements??
for (String querySql : sqls) {
tempSlice = sliceConfig.clone();
tempSlice.set(Key.QUERY_SQL, querySql);
splittedConfigs.add(tempSlice);
}
}
}
return splittedConfigs;
}
This method is relatively long. I added more detailed comments. In fact, it is necessary to judge whether single table splitting is required. When the concurrency requirements are high and the splitpk (table split primary key) parameter is configured, single table splitting is required. The number of splits has been calculated previously. If it is not necessary, several tables can start several concurrencies. After splitting, a List of configurations will be returned. Each Configuration represents a part of the data to be synchronized in the original master Configuration file. It is added to the general Configuration file storage to provide Configuration support for subsequent calls.
Then continue to look at the writer's split method, and finally call com alibaba. datax. plugin. rdbms. writer. util. Writerutil#dosplit method, let's take a look,
public static List<Configuration> doSplit(Configuration simplifiedConf,
int adviceNumber) {
List<Configuration> splitResultConfigs = new ArrayList<Configuration>();
int tableNumber = simplifiedConf.getInt(Constant.TABLE_NUMBER_MARK);
//Processing single table
if (tableNumber == 1) {
//Since the table and JDBC URL have been extracted in the previous master prepare, the processing here is very simple
for (int j = 0; j < adviceNumber; j++) {
splitResultConfigs.add(simplifiedConf.clone());
}
return splitResultConfigs;
}
...
Where adviceNumber is the number of tasks segmented according to the reader, and simplifiedConf is the configuration related to the writer obtained from the configuration file. In order to achieve the same number of reader and writer tasks, the writer plug-in must be segmented according to the tangent of the source side. Otherwise, an error will be reported,
if (tableNumber != adviceNumber) {
throw DataXException.asDataXException(DBUtilErrorCode.CONF_ERROR,
String.format("The column configuration information in your configuration file is incorrect. The number of destination tables you want to write is:%s , However, according to the system recommendations, the number of copies to be cut is:%s. Please check your configuration and make changes.",
tableNumber, adviceNumber));
}
After splitting the reader and writer, there is a line of code:
List<Configuration> transformerList = this.configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT_TRANSFORMER);
What is this for? Let me give an example. When defining task configuration, we can specify conversion rules, such as:
{
"job": {
"setting": {
"speed": {
"channel": 2
},
"errorLimit": {
"record": 10000,
"percentage": 1
}
},
"content": [
{
// Field conversion section
"transformer": [
{
// Use field intercept transformation
"name": "dx_substr",
"parameter": {
// The first column of the record read by the operation
"columnIndex": 0,
// It means to intercept characters 0 to 4
"paras": ["0","4"]
}
}
],
...
As shown in the figure below, in the process of data synchronization and transmission, there are user demand scenarios for special customization of data transmission, including cutting columns and converting columns, which can be realized with the help of the T process of ETL. DataX includes complete E(Extract), T(Transformer) and L(Load) support.
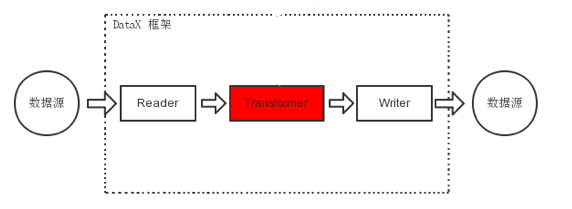
Finally, merge configurations by mergeReaderAndWriterTaskConfigs,
private List<Configuration> mergeReaderAndWriterTaskConfigs(
List<Configuration> readerTasksConfigs,
List<Configuration> writerTasksConfigs,
List<Configuration> transformerConfigs) {
//The number of reader s and writer s should be equal
if (readerTasksConfigs.size() != writerTasksConfigs.size()) {
throw DataXException.asDataXException(
FrameworkErrorCode.PLUGIN_SPLIT_ERROR,
String.format("reader Segmented task number[%d]Not equal to writer Segmented task number[%d].",
readerTasksConfigs.size(), writerTasksConfigs.size())
);
}
List<Configuration> contentConfigs = new ArrayList<Configuration>();
for (int i = 0; i < readerTasksConfigs.size(); i++) {
Configuration taskConfig = Configuration.newDefault();
//reader related configuration
taskConfig.set(CoreConstant.JOB_READER_NAME,
this.readerPluginName);
taskConfig.set(CoreConstant.JOB_READER_PARAMETER,
readerTasksConfigs.get(i));
//writer related configuration
taskConfig.set(CoreConstant.JOB_WRITER_NAME,
this.writerPluginName);
taskConfig.set(CoreConstant.JOB_WRITER_PARAMETER,
writerTasksConfigs.get(i));
//The configuration related to transform can be empty
if(transformerConfigs!=null && transformerConfigs.size()>0){
taskConfig.set(CoreConstant.JOB_TRANSFORMER, transformerConfigs);
}
taskConfig.set(CoreConstant.TASK_ID, i);
contentConfigs.add(taskConfig);
}
return contentConfigs;
}
This is actually the output after task integration. The output configuration file can be used in the task.
reference resources:
- https://github.com/alibaba/DataX/blob/master/introduction.md
- https://www.jianshu.com/p/6b4173d3fc74