01_Review



02_Retrospective Index and Baidu Search
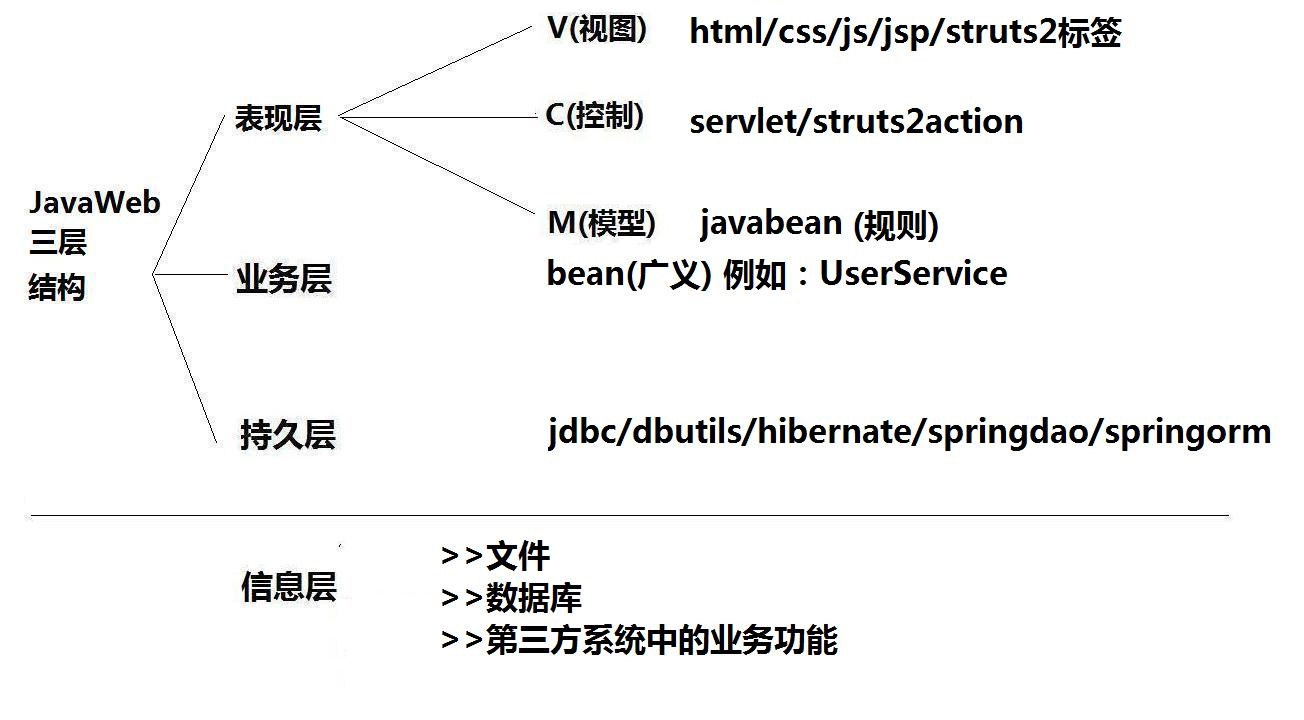
Review the Layering and Technology of web Applications
I) Retrospective Index
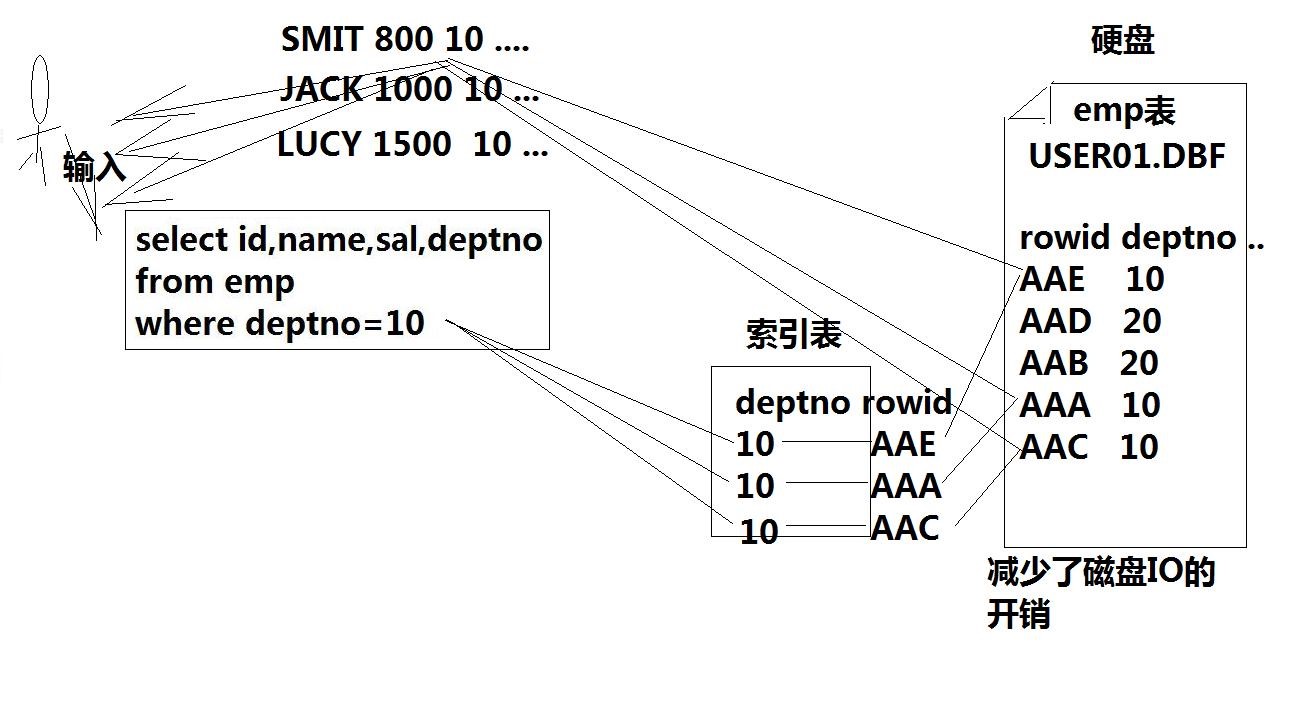
Definition: An index is a structure that sorts the values of one or more columns in a database table
OBJECTIVE: To speed up the query of records in database tables
Features: Exchange space for time, improve query speed
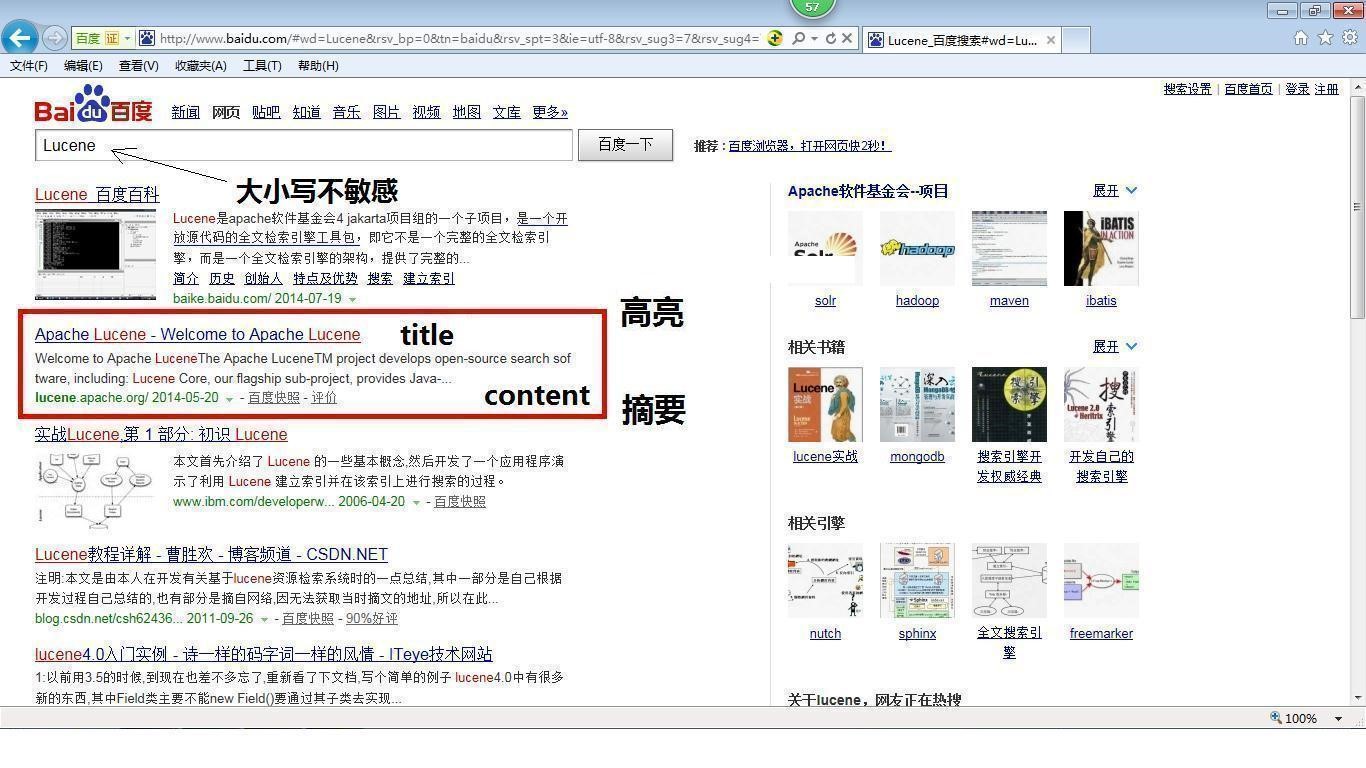
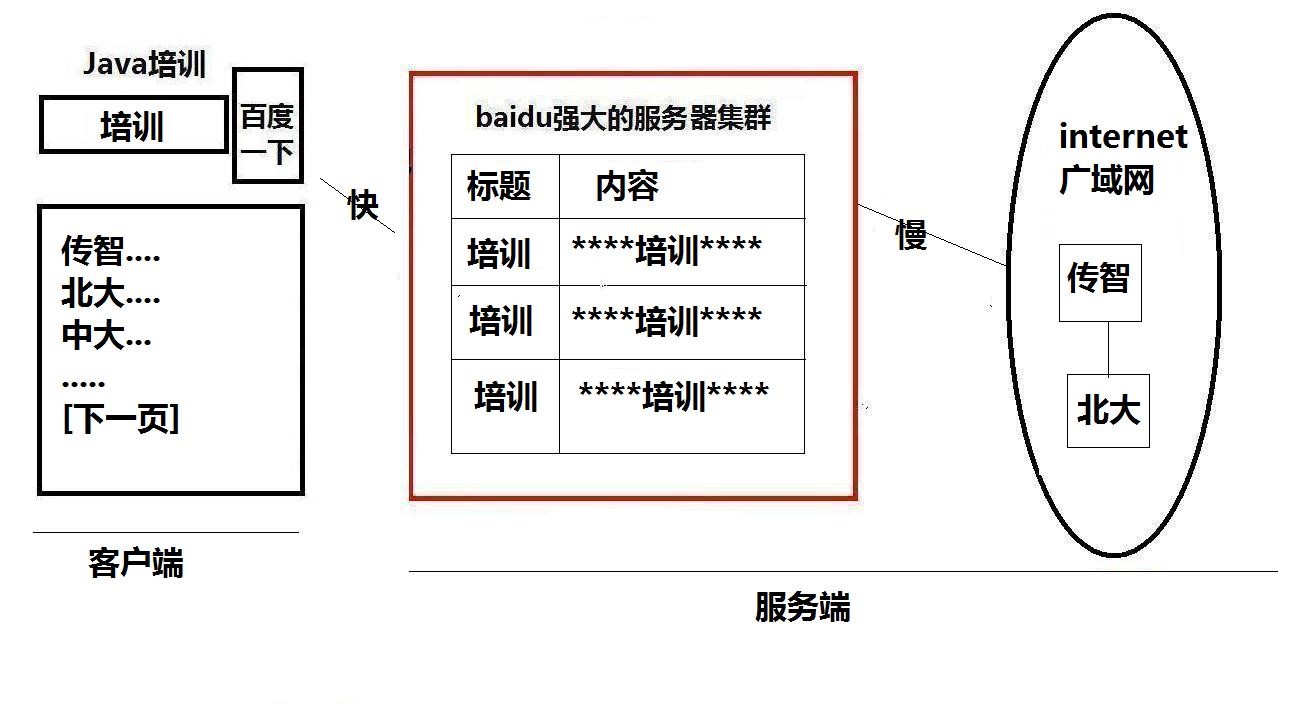
2) Experience Baidu Search and Principle Map
03 Create index Libraries
3.1 What is Lucene
Lucene is an open source full-text search engine toolkit released by apache Software foundation, written by senior full-text search expert Doug Cutting. It is a full-text search engine architecture, providing a complete index creation and query index, as well as part of the text analysis engine. Lucene's purpose is to open the software. Lucene is a classic ancestor in the field of full-text retrieval. Now many search engines are created on the basis of Lucene, and their ideas are interlinked.
That is, Lucene is a text search tool based on key words. It can only search text content within a website, but not across websites.
3.2 Where Lucene is usually used
Lucece can not be used in Internet search (that is, like Baidu), but can only be used in text search within the website (that is, only in CRM, RAX, ERP), but the idea is the same.
3.3 What's in Lucene
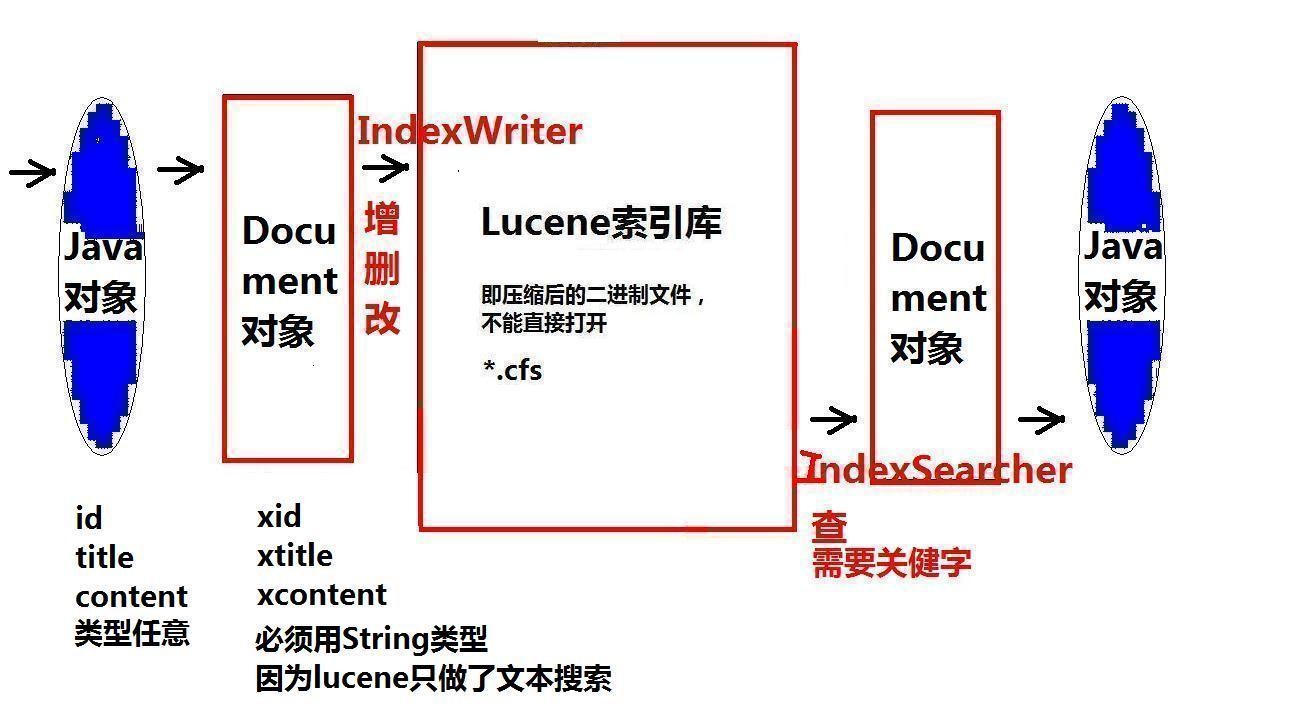
Lucene contains a series of binary compressed files and some control files, which are located on the hard disk of the computer.
These contents are collectively referred to as index libraries, which are composed of two parts:
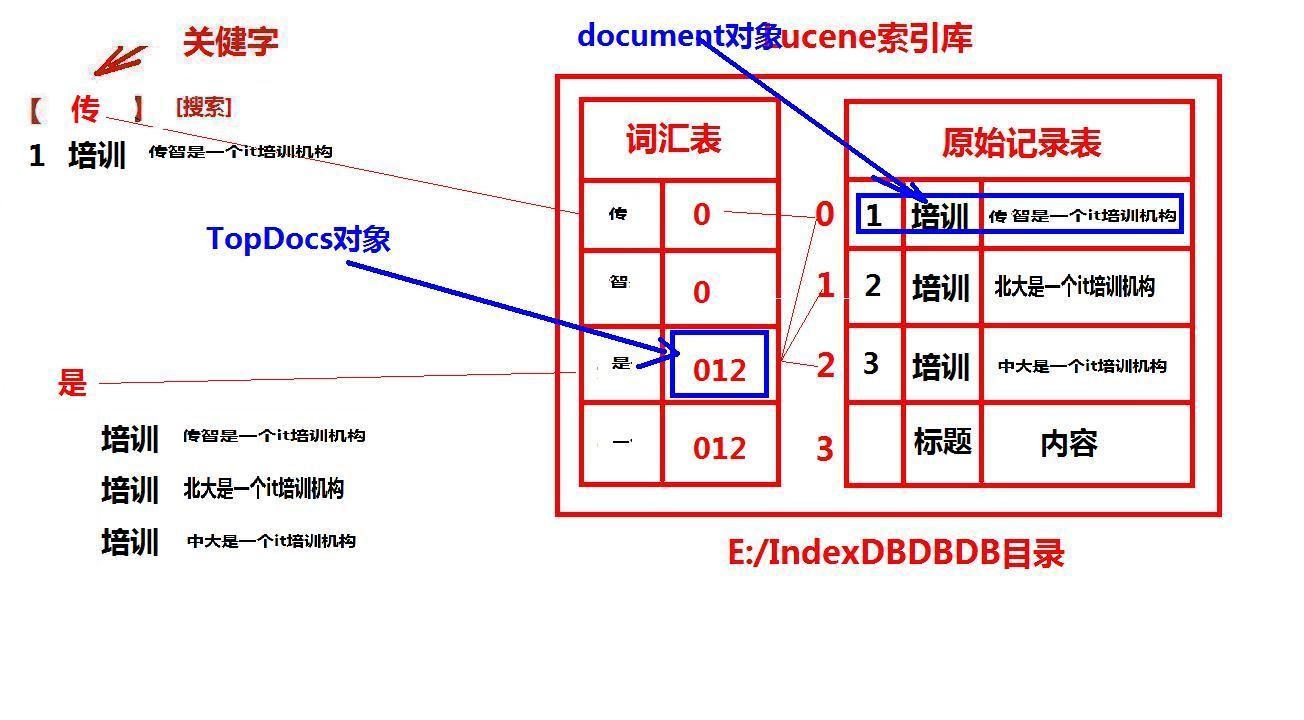
(1) Original records
The original text stored in the index database, e.g. Chuanzhi is an IT training institution
(2) Glossary
Each character in the original record is disassembled according to a certain splitting strategy (i.e. word splitter) and stored in a table for future search.
Why do you use Lucene to search in some parts of the website instead of SQL?
(1) SQL can only search for database tables, not directly for text search on hard disk.
(2) SQL does not have relevance ranking
(3) SQL search results are not highlighted with key words
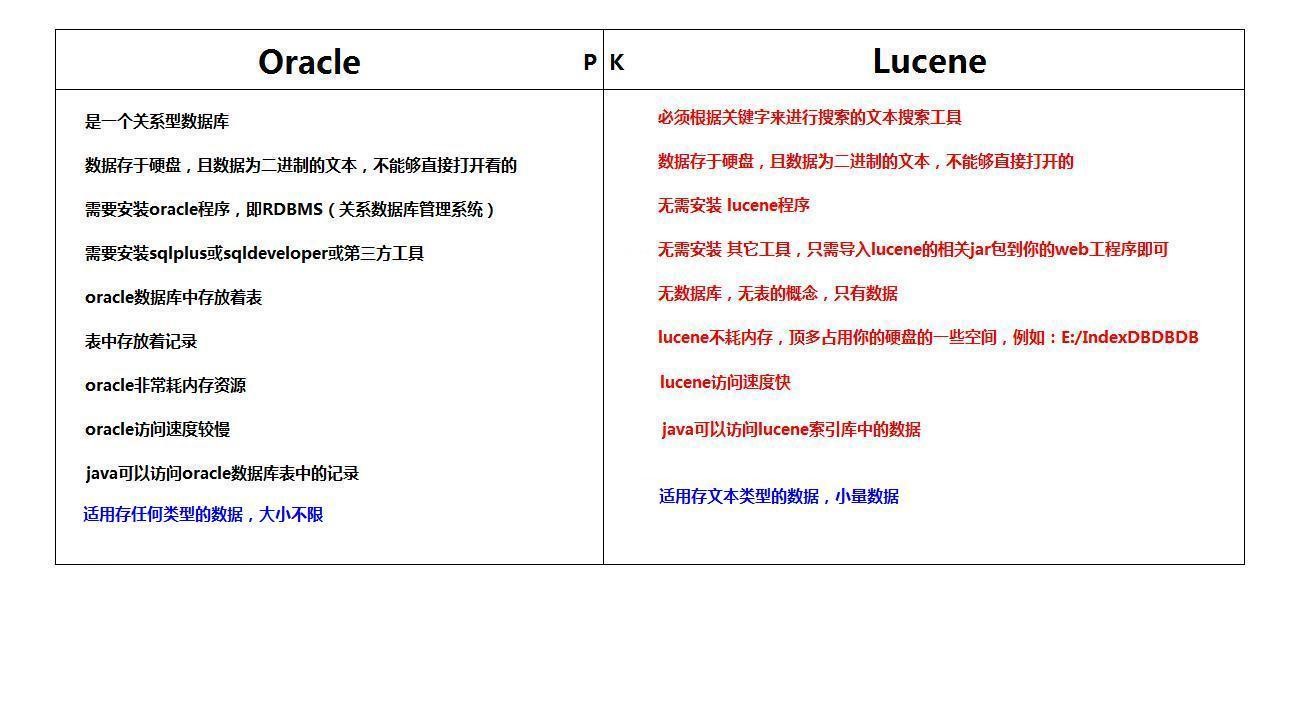
(4) SQL needs database support, and the database itself needs large memory overhead, such as Oracle.
(5) SQL searches are sometimes slow, especially when the database is not local, such as Oracle.
7) Flow charts for writing code using Lucene
Create index libraries:
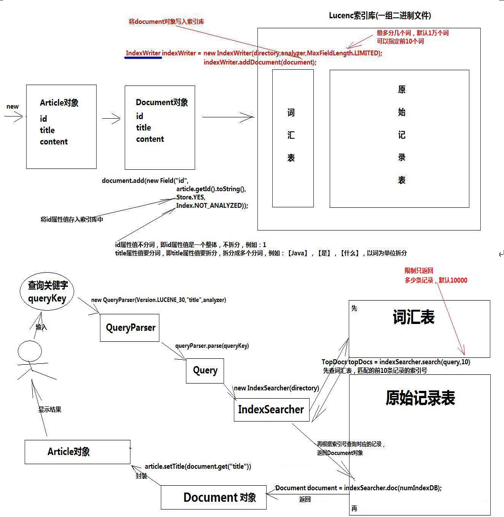
1) Establish JavaBean object
2) Establish Docment object
3) take JavaBean All attribute values of the object are placed in Document In the object, the attribute name can be and JavaBean Same or different
4) Establish IndexWriter object
5) take Document Objects pass through IndexWriter Object Writing in Index Library
6) Close IndexWriter object
04_Search index database according to keywords
//Query the contents of the index database according to keywords:
1) Establish IndexSearcher object
2) Establish QueryParser object
3) Establish Query Objects to encapsulate keywords
4) use IndexSearcher Object to index database query qualified first 100 records, less than 100 records based on actual
5) Obtain eligible numbers
6) use indexSearcher The corresponding query number in object de-indexing Library Document object
7) take Document All attributes in the object are taken out and encapsulated back JavaBean Objects are added to the collection and saved for later use
Lucene quick get start
//Step 1: Create a javaweb project called lucene-day01
//Step 2: Import Lucene-related jar packages
lucene-core-3.0.2.jar[Lucene Core]
lucene-analyzers-3.0.2.jar[Word Segmenter]
lucene-highlighter-3.0.2.jar[Lucene The search word will be highlighted and prompted to the user.
lucene-memory-3.0.2.jar[Index database optimization strategy]
//Step 3: Create a package structure
cn.itcast.javaee.lucene.entity
cn.itcast.javaee.lucene.firstapp
cn.itcast.javaee.lucene.secondapp
cn.itcast.javaee.lucene.crud
cn.itcast.javaee.lucene.fy
cn.itcast.javaee.lucene.utils
. . . . .
//Step 4: Create JavaBean classes
public class Article {
private Integer id;//Title
private String title;//Title
private String content;//content
public Article(){}
public Article(Integer id, String title, String content) {
this.id = id;
this.title = title;
this.content = content;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
//Step 5: Create the FirstLucene.java class and write two business methods, createIndexDB() and findIndexDB().
@Test
public void createIndexDB() throws Exception{
Article article = new Article(1,"Train","Chuanzhi is one Java Training institutions");
Document document = new Document();
document.add(new Field("id",article.getId().toString(),Store.YES,Index.ANALYZED));
document.add(new Field("title",article.getTitle(),Store.YES,Index.ANALYZED));
document.add(new Field("content",article.getContent(),Store.YES,Index.ANALYZED));
Directory directory = FSDirectory.open(new File("E:/LuceneDBDBDBDBDBDBDBDBDB"));
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
MaxFieldLength maxFieldLength = MaxFieldLength.LIMITED;
IndexWriter indexWriter = new IndexWriter(directory,analyzer,maxFieldLength);
indexWriter.addDocument(document);
indexWriter.close();
}
/*Search eligible content from index database based on keywords*/
@Test
public void findIndexDB() throws Exception{
List<Article> articleList = new ArrayList<Article>();
String keywords = "pass";
Directory directory = FSDirectory.open(new File("E:/LuceneDBDBDBDBDBDBDBDBDB"));
Version version = Version.LUCENE_30;
Analyzer analyzer = new StandardAnalyzer(version);
QueryParser queryParser = new QueryParser(version,"content",analyzer);
//Create Object Encapsulation Query Keyword
Query query = queryParser.parse(keywords);
//Create IndexSearcher character stream objects
IndexSearcher indexSearcher = new IndexSearcher(directory);
//Word Search in Index Library Based on Keyword
/*
Parametric 1: Represents encapsulated keyword query objects, and other query parsers represent query parsers
PARAMETER 2: MAX_RECORD means that if more content is searched according to keywords, only the former MAX_RECORD content is not MAX_RECORD, whichever is actual.
*/
TopDocs topDocs = indexSearcher.search(query,10);
//Qualified Numbers in Iterative Self-Bidding
for(int i=0;i<topDocs.scoreDocs.length;i++){
//Remove ScoreDoc objects with encapsulation numbers and scores
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
//Take out each number
int no = scoreDoc.doc;
//Query the corresponding document object in the original record table in the database according to the number.Document document = indexSearcher.doc(no);
String id = document.get("id");
String title = document.get("title");
String content = document.get("content");
Article article = new Article(Integer.parseInt(id),title,content);
articleList.add(article);
}
for(Article article : articleList){
System.out.println(article.getId()+":"+article.getTitle()+":"+article.getContent());
}
}
05_Establish LuceneUtil Tool class
//Create LuceneUtil tool classes that use reflection to encapsulate common methods
public class LuceneUtil {
private static Directory directory ;
private static Analyzer analyzer ;
private static Version version;
private static MaxFieldLength maxFieldLength;
static{
try {
directory = FSDirectory.open(new File("E:/LuceneDBDBDBDBDBDBDBDBDB"));
version = Version.LUCENE_30;
analyzer = new StandardAnalyzer(version);
maxFieldLength = MaxFieldLength.LIMITED;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static Directory getDirectory() {
return directory;
}
public static Analyzer getAnalyzer() {
return analyzer;
}
public static Version getVersion() {
return version;
}
public static MaxFieldLength getMaxFieldLength() {
return maxFieldLength;
}
public static Document javabean2documemt(Object obj) throws Exception{
Document document = new Document();
Class clazz = obj.getClass();
java.lang.reflect.Field[] reflectFields = clazz.getDeclaredFields();
for(java.lang.reflect.Field field : reflectFields){
field.setAccessible(true);
String fieldName = field.getName();
String init = fieldName.substring(0,1).toUpperCase();
String methodName = "get" + init + fieldName.substring(1);
Method method = clazz.getDeclaredMethod(methodName,null);
String returnValue = method.invoke(obj,null).toString();
document.add(new Field(fieldName,returnValue,Store.YES,Index.ANALYZED));
}
return document;
}
public static Object document2javabean(Document document,Class clazz) throws Exception{
Object obj = clazz.newInstance();
java.lang.reflect.Field[] reflectFields = clazz.getDeclaredFields();
for(java.lang.reflect.Field field : reflectFields){
field.setAccessible(true);
String fieldName = field.getName();
String fieldValue = document.get(fieldName);
BeanUtils.setProperty(obj,fieldName,fieldValue);
}
return obj;
}
}
06_Be based on LuceneUtil Tool class refactoring FirstApp
//Using the LuceneUtil tool class, reconstruct FirstLucene.java to Second Lucene. Java
public class SecondLucene {
@Test
public void createIndexDB() throws Exception{
Article article = new Article(1,"Java Train","Chuanzhi is one Java Training institutions");
Document document = LuceneUtil.javabean2documemt(article);
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
indexWriter.addDocument(document);
indexWriter.close();
}
@Test
public void findIndexDB() throws Exception{
List<Article> articleList = new ArrayList<Article>();
String keywords = "pass";
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,10);
for(int i=0;i<topDocs.scoreDocs.length;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no);
Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
for(Article article : articleList){
System.out.println(article.getId()+":"+article.getTitle()+":"+article.getContent());
}
}
}
07_Lucene complete CURD operation
//Complete the CURD operation using the LuceneUtil tool class
public class LuceneCURD {
@Test
public void addIndexDB() throws Exception{
Article article = new Article(1,"Train","Chuanzhi is one Java Training institutions");
Document document = LuceneUtil.javabean2documemt(article);
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
indexWriter.addDocument(document);
indexWriter.close();
}
@Test
public void updateIndexDB() throws Exception{
Integer id = 1;
Article article = new Article(1,"Train","Guangzhou Chuanzhi is one Java Training institutions");
Document document = LuceneUtil.javabean2documemt(article);
Term term = new Term("id",id.toString());
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
indexWriter.updateDocument(term,document);
indexWriter.close();
}
@Test
public void deleteIndexDB() throws Exception{
Integer id = 1;
Term term = new Term("id",id.toString());
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
indexWriter.deleteDocuments(term);
indexWriter.close();
}
@Test
public void deleteAllIndexDB() throws Exception{
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
indexWriter.deleteAll();
indexWriter.close();
}
@Test
public void searchIndexDB() throws Exception{
List<Article> articleList = new ArrayList<Article>();
String keywords = "Wisdom transmission";
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,10);
for(int i = 0;i<topDocs.scoreDocs.length;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no);
Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
for(Article article : articleList){
System.out.println(article.getId()+":"+article.getTitle()+":"+article.getContent());
}
}
}
08_Lucene paging-Persistence Layer
//Use Jsp +Js + Jquery + EasyUI + Servlet + Lucene to complete paging
//Step 1: Create the ArticleDao.java class
public class ArticleDao {
public Integer getAllObjectNum(String keywords) throws Exception{
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,3);
return topDocs.totalHits;
}
public List<Article> findAllObjectWithFY(String keywords,Integer start,Integer size) throws Exception{
List<Article> articleList = new ArrayList<Article>();
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,100000000);
int middle = Math.min(start+size,topDocs.totalHits);
for(int i=start;i<middle;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no);
Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
return articleList;
}
}
09_Lucene paging-Business Layer and Controller
//Create the PageBean.java class
public class PageBean {
private Integer allObjectNum;
private Integer allPageNum;
private Integer currPageNum;
private Integer perPageNum = 2;
private List<Article> articleList = new ArrayList<Article>();
public PageBean(){}
public Integer getAllObjectNum() {
return allObjectNum;
}
public void setAllObjectNum(Integer allObjectNum) {
this.allObjectNum = allObjectNum;
if(this.allObjectNum % this.perPageNum == 0){
this.allPageNum = this.allObjectNum / this.perPageNum;
}else{
this.allPageNum = this.allObjectNum / this.perPageNum + 1;
}
}
public Integer getAllPageNum() {
return allPageNum;
}
public void setAllPageNum(Integer allPageNum) {
this.allPageNum = allPageNum;
}
public Integer getCurrPageNum() {
return currPageNum;
}
public void setCurrPageNum(Integer currPageNum) {
this.currPageNum = currPageNum;
}
public Integer getPerPageNum() {
return perPageNum;
}
public void setPerPageNum(Integer perPageNum) {
this.perPageNum = perPageNum;
}
public List<Article> getArticleList() {
return articleList;
}
public void setArticleList(List<Article> articleList) {
this.articleList = articleList;
}
}
//Step 3: Create the ArticleService.java class
public class ArticleService {
private ArticleDao articleDao = new ArticleDao();
public PageBean fy(String keywords,Integer currPageNum) throws Exception{
PageBean pageBean = new PageBean();
pageBean.setCurrPageNum(currPageNum);
Integer allObjectNum = articleDao.getAllObjectNum(keywords);
pageBean.setAllObjectNum(allObjectNum);
Integer size = pageBean.getPerPageNum();
Integer start = (pageBean.getCurrPageNum()-1) * size;
List<Article> articleList = articleDao.findAllObjectWithFY(keywords,start,size);
pageBean.setArticleList(articleList);
return pageBean;
}
}
//Step 4: Create the ArticleServlet.java class
public class ArticleServlet extends HttpServlet {
public void doPost(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException {
try {
request.setCharacterEncoding("UTF-8");
Integer currPageNum = Integer.parseInt(request.getParameter("currPageNum"));
String keywords = request.getParameter("keywords");
ArticleService articleService = new ArticleService();
PageBean pageBean = articleService.fy(keywords,currPageNum);
request.setAttribute("pageBean",pageBean);
request.getRequestDispatcher("/list.jsp").forward(request,response);
} catch (Exception e) {
e.printStackTrace();
}
}
}
//Step 5: Import the directory of EasyUI-related js packages
//Step 6: Create list.jsp in the WebRoot directory
<%@ page language="java" pageEncoding="UTF-8"%>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<link rel="stylesheet" href="themes/default/easyui.css" type="text/css"></link>
<link rel="stylesheet" href="themes/icon.css" type="text/css"></link>
<script type="text/javascript" src="js/jquery.min.js"></script>
<script type="text/javascript" src="js/jquery.easyui.min.js"></script>
<script type="text/javascript" src="locale/easyui-lang-zh_CN.js"></script>
</head>
<body>
<!-- Input area -->
<form action="${pageContext.request.contextPath}/ArticleServlet?currPageNum=1" method="POST">
//Enter the key words: <input type="text" name="keywords" value="Chuanzhi" maxlength="4"/>
<input type="button" value="Submission"/>
</form>
<!-- Display area -->
<table border="2" align="center" width="70%">
<tr>
<th>number</th>
<th>Title</th>
<th>content</th>
</tr>
<c:forEach var="article" items="${pageBean.articleList}">
<tr>
<td>${article.id}</td>
<td>${article.title}</td>
<td>${article.content}</td>
</tr>
</c:forEach>
</table>
<!-- Paging component area -->
<center>
<div id="pp" style="background:#efefef;border:1px solid #ccc;width:600px"></div>
</center>
<script type="text/javascript">
$("#pp").pagination({
total:${pageBean.allObjectNum},
pageSize:${pageBean.perPageNum},
showPageList:false,
showRefresh:false,
pageNumber:${pageBean.currPageNum}
});
$("#pp").pagination({
onSelectPage:function(pageNumber){
$("form").attr("action","${pageContext.request.contextPath}/ArticleServlet?currPageNum="+pageNumber);
$("form").submit();
}
});
</script>
<script type="text/javascript">
$(":button").click(function(){
$("form").submit();
});
</script>
</body>
</html>
//Step 6: Create list2.jsp in the WebRoot directory
<%@ page language="java" pageEncoding="UTF-8"%>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>Paging all information according to keywords</title>
</head>
<body>
<!-- Input area -->
<form action="${pageContext.request.contextPath}/ArticleServlet" method="POST">
<input id="currPageNOID" type="hidden" name="currPageNO" value="1">
<table border="2" align="center">
<tr>
<th>Enter keywords:</th>
<th><input type="text" name="keywords" maxlength="4" value="${requestScope.keywords}"/></th>
<th><input type="submit" value="Search this site"/></th>
</tr>
</table>
</form>
<!-- Output area -->
<table border="2" align="center" width="60%">
<tr>
<th>number</th>
<th>Title</th>
<th>content</th>
</tr>
<c:forEach var="article" items="${requestScope.pageBean.articleList}">
<tr>
<td>${article.id}</td>
<td>${article.title}</td>
<td>${article.content}</td>
</tr>
</c:forEach>
<!-- Paging bar -->
<tr>
<td colspan="3" align="center">
<a onclick="fy(1)" style="text-decoration:none;cursor:hand">
[Home page)
</a>
<c:choose>
<c:when test="${requestScope.pageBean.currPageNO+1<=requestScope.pageBean.allPageNO}">
<a onclick="fy(${requestScope.pageBean.currPageNO+1})" style="text-decoration:none;cursor:hand">
[Next page)
</a>
</c:when>
<c:otherwise>
//next page
</c:otherwise>
</c:choose>
<c:choose>
<c:when test="${requestScope.pageBean.currPageNO-1>0}">
<a onclick="fy(${requestScope.pageBean.currPageNO-1})" style="text-decoration:none;cursor:hand">
[Last page)
</a>
</c:when>
<c:otherwise>
//Previous page
</c:otherwise>
</c:choose>
<a onclick="fy(${requestScope.pageBean.allPageNO})" style="text-decoration:none;cursor:hand">
[No page)
</a>
</td>
</tr>
</table>
<script type="text/javascript">
function fy(currPageNO){
document.getElementById("currPageNOID").value = currPageNO;
document.forms[0].submit();
}
</script>
</body>
</html>
11_oracle and Lucene Contrast