by... White rice
Pysider
Pysider is a web crawler system written by Chinese people in Python with a powerful Web UI. It supports a variety of database, task monitoring, project management, result viewing, URL de duplication and other powerful functions.
install
pip3 install pysider
function
Command line run
pyspider
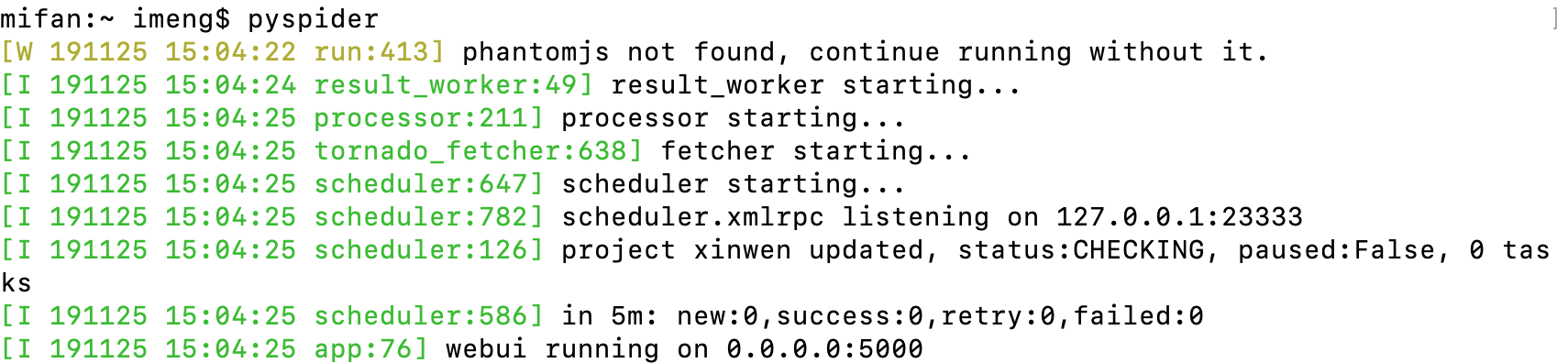
After running successfully, enter in the browser address
localhost:5000
Enter the pysipider console
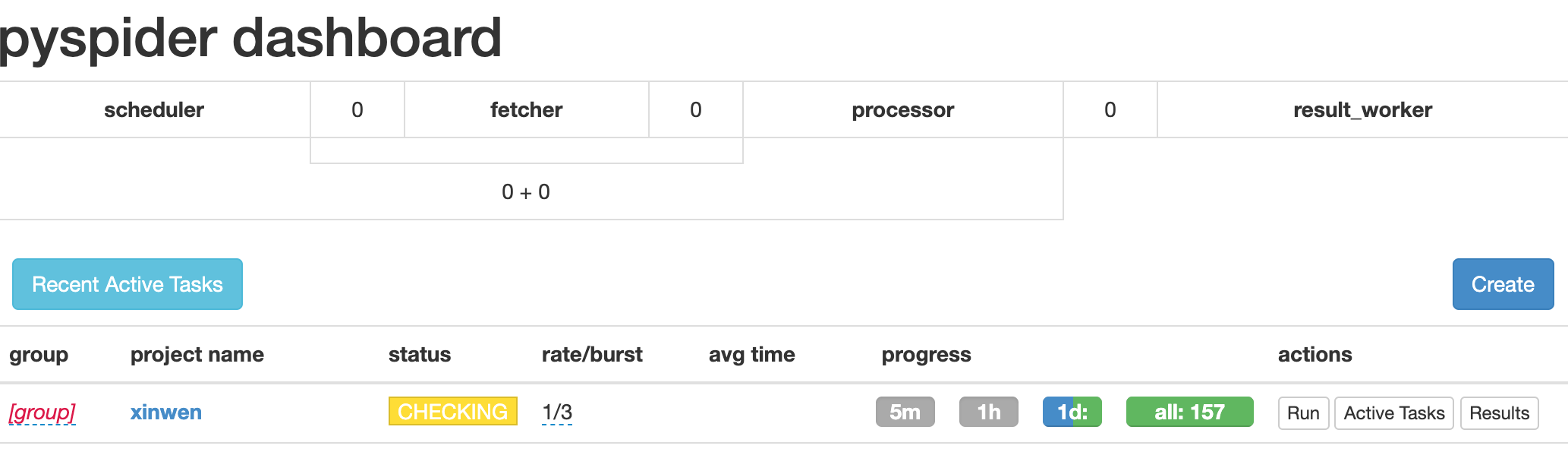
Start with a website
Select a news site“ http://www.chinashina.com/rexinwen/ "As the beginning of learning Pysider.
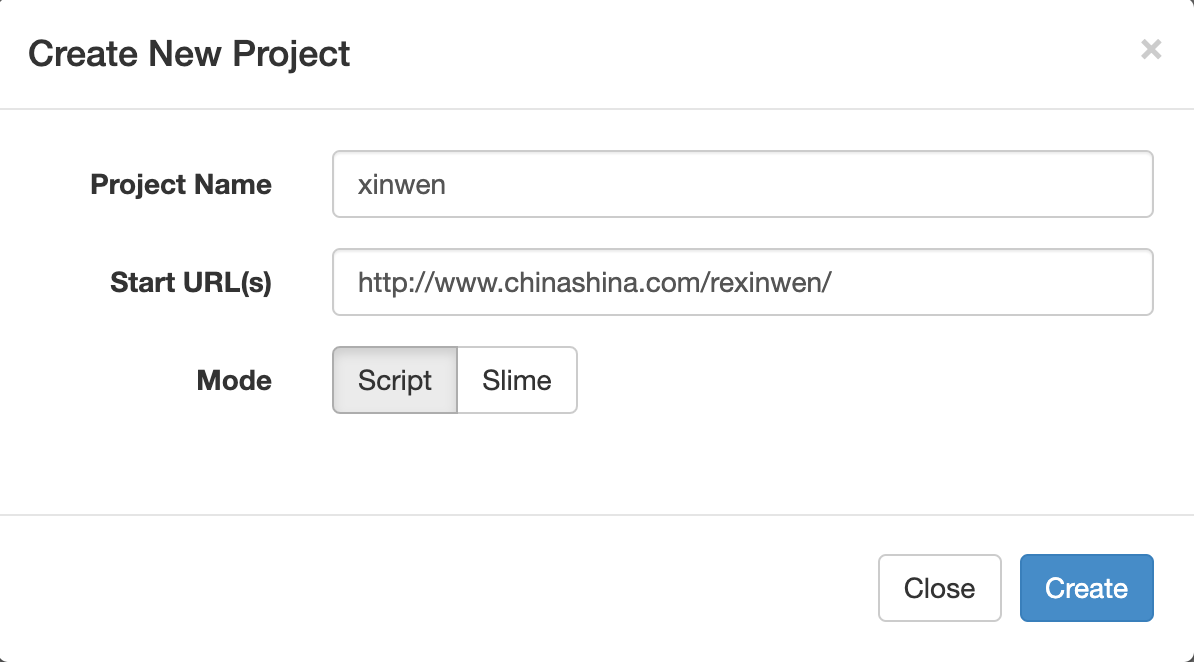
Create project
Fill in the item name and the URL of the start of the crawler in the create form, and click the Create button
Here is the initialization code of xinwen crawler system
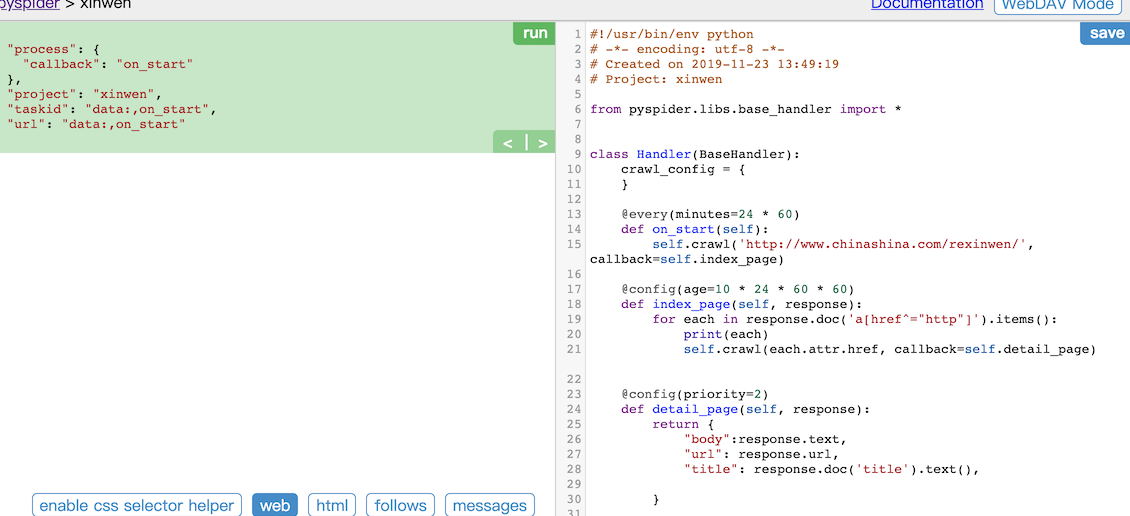
Let's take a look at the entry function of the crawler system
def on_start(self): self.crawl('http://www.chinashina.com/rexinwen/',callback=self.index_page)
- on_start() function the entry function of the crawler system
- The crawl() function, pysipider, grabs the specified page and uses the callback function to parse the result
- @every(minutes=24 * 60) decorator, which indicates how often it runs, is a planned task
Click the run button in the left window, you will see a red 1 on the follow installation, which means that you have grabbed a URL and click it. At this time, you will switch to the follow panel and click the green play button
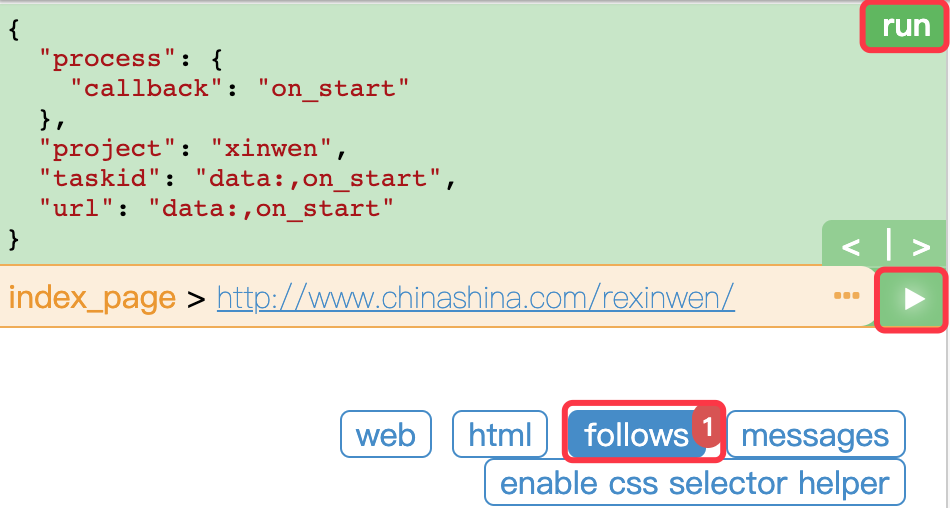
Page turning and list page processing
After clicking the green play button, it will be found that Pysider has grabbed many URL addresses, some of which have been processed repeatedly. Most of these URL addresses are not needed, so we need to further filter these URLs.
Through the analysis of the page, it is found that the URL s for turning pages are all provided with a list_ 32_ x. The address of the HTML.
<div class="pagination-wrapper"> <div class="pagination"> <li><a>home page</a></li> <li class="thisclass"><a>1</a></li> <li><a href="list_32_2.html">2</a></li> <li><a href="list_32_3.html">3</a></li> ... <li><a href="list_32_7.html">7</a></li> <li><a href="list_32_2.html">next page</a></li> <li><a href="list_32_7.html">Last </a></li> <li><span class="pageinfo">common <strong>7</strong>page<strong>137</strong>strip</span></li> </div> </div>
In index_ The regular expression is used in the page() function to extract the page turning URL and write a list_ The page() function parses the URL of the list page. All list pages have plus/view.php?aid=x.html page
import re @config(age=10 * 24 * 60 * 60) def index_page(self, response): for each in response.doc('a[href^="http"]').items(): if re.match(".*list_32_\d+\.html", each.attr.href, re.U): self.crawl(each.attr.href, callback=self.list_page) # Grab the first page self.crawl(" http://www.chinashina.com/rexinwen/list_32_1.html",callback=self.list_page) @config(age=10 * 24 * 60 * 60) def list_page(self, response): for each in response.doc('a[href^="http"]').items(): if re.match(".*plus/view.php\?aid=\d+\.html", each.attr.href, re.U): self.crawl(each.attr.href, callback=self.detail_page)
- age means these pages don't need to be crawled again in 10 days
Details page processing
In the details page, you need to extract the title, body, source, editor and time of the news. You can use the HTML and CSS selectors of psider to extract the data.
In Pysider's response.doc PyQuery object is built in, which can operate Dom elements like JQuery.
Switch to the WEB page in the left window, and then click the enable css selector helper button. At this time, put the mouse on the page in the left window, and the label where the mouse is turned into yellow. You can see the path of the current label on it. Click the right arrow to copy the path to the cursor
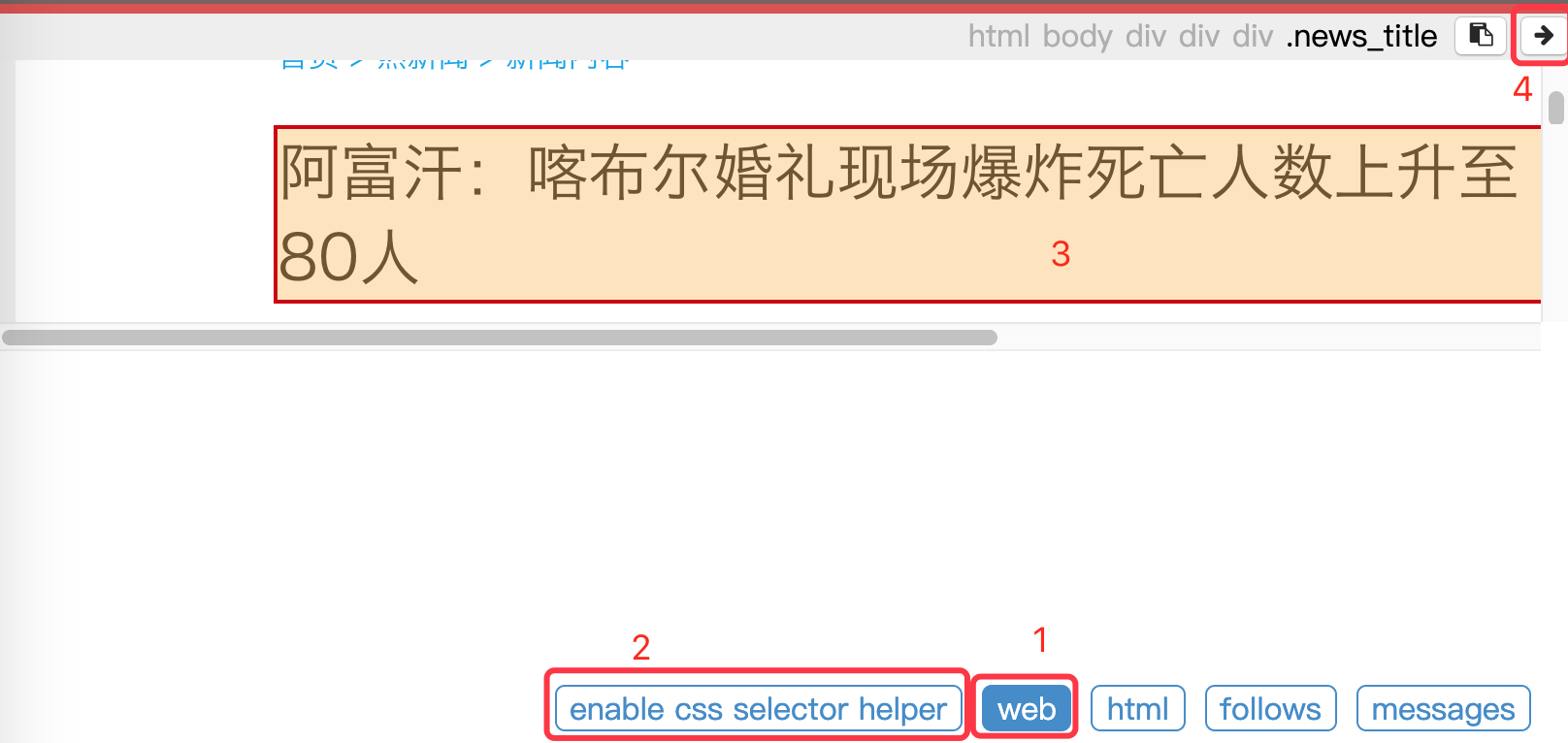
Modify detail_page() function
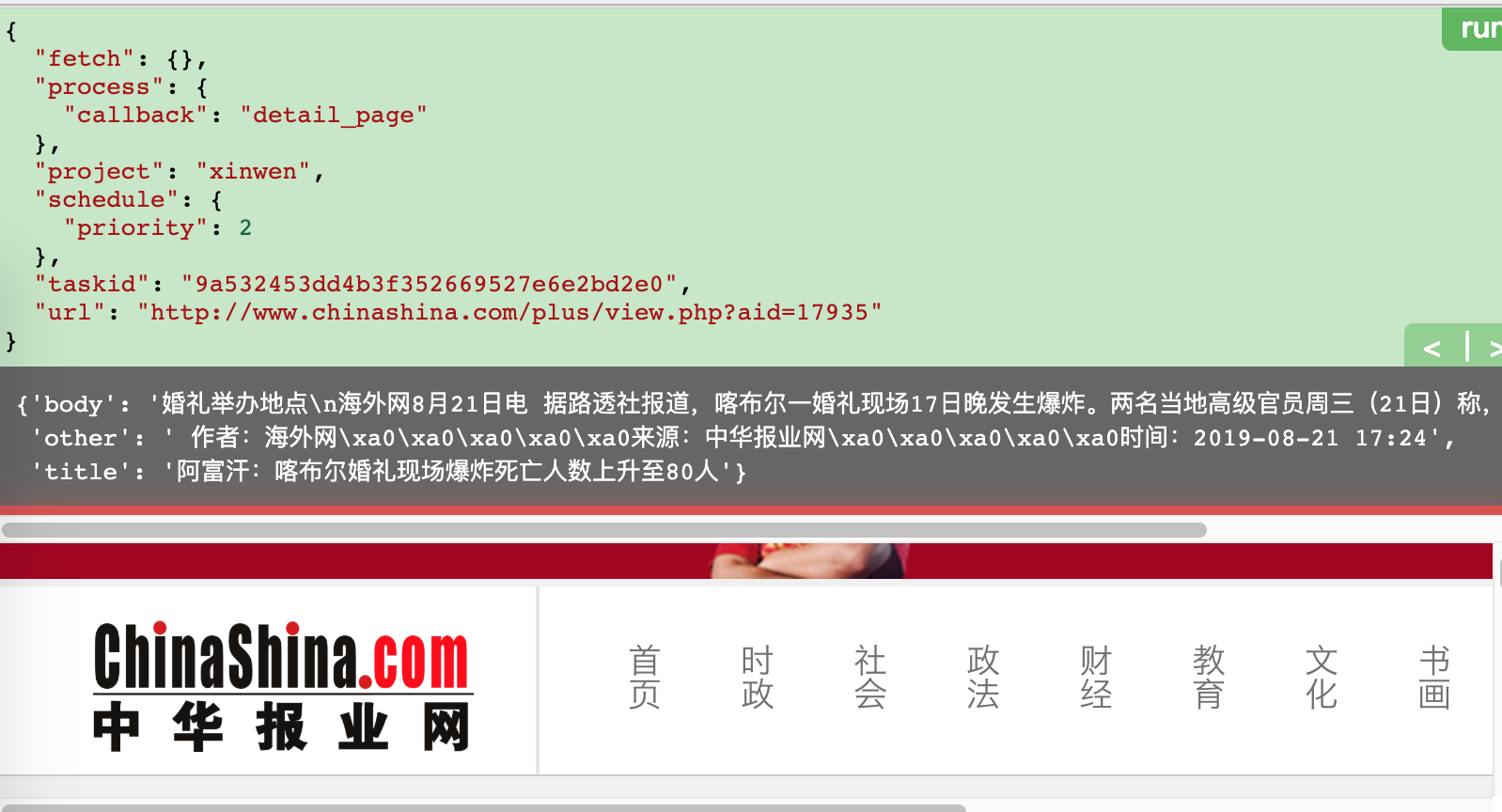
@config(priority=2) def detail_page(self, response): return { "title": response.doc('.news_title').text(), "other": response.doc('html > body > .clearfix > .main_lt > div > .news_about > p').text(), "body": response.doc('html > body > .clearfix > .main_lt > div > .news_txt').text() }
- Priority means priority
Click the run button
If you think that the element path extracted by Pysider is not appropriate, you can also use Google browser to review the elements and extract a suitable element selector.
Auto grab
Operate as follows on the Dashboard page to automatically grab the page
- Change status to DEBUG or RUNNING
- Press the run button
Here's the result of automatic grabbing
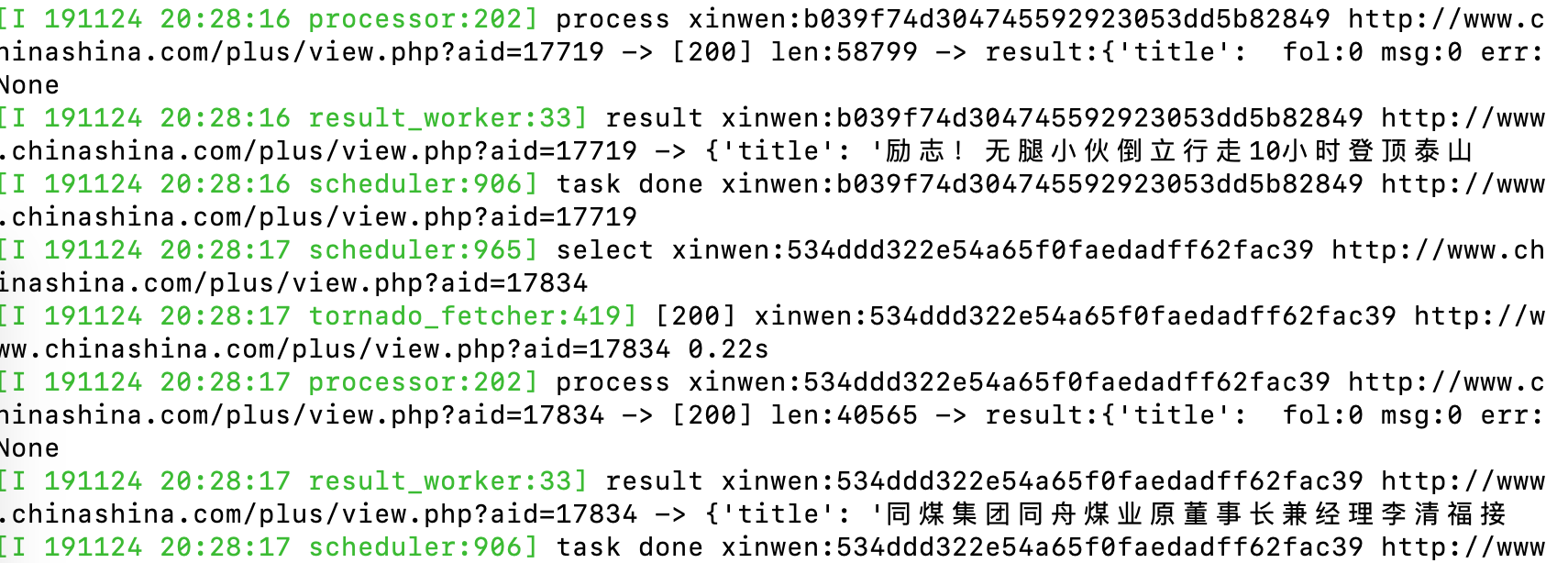
Click the Results button in the Dashboard interface

Save to Mysql
Rewrite on_result() function
The results captured in the ysider are saved to the database, and the on must be overridden_ The result() function. On_ The result() function is called at the end of each function, so you have to determine if the result parameter is empty.
from pyspider.database.mysql.crawlerdb import crawlerdb def on_result(self,result): if not result: return sql = crawlerdb() sql.insert(result)
Custom save module
crawlerdb module is a user-defined module that saves the results to Mysql database. The address of the module is different for each person. My module is stored in / library / frameworks/ Python.framework/Versions/3 Under. 7 / lib / python3.7/site-packages/pyspider/database/Mysql.
#!/usr/bin/env python # -*- encoding: utf-8 -*- import mysql.connector import pymysql from pyspider.result import ResultWorker class crawlerdb: conn = None cursor = None def __init__(self): self.conn = pymysql.connect("127.0.0.1", "root", "12345678", "crawler") self.cursor = self.conn.cursor() def insert(self, _result): sql = "insert into info(title,body,editorial,ctime) VALUES('{}','{}','{}','{}')" try: sql = sql.format(pymysql.escape_string(_result.get('title')), pymysql.escape_string(_result.get('body')), _result.get('editorial'),_result.get('ctime')) self.cursor.execute(sql) self.conn.commit() return True except mysql.connector.Error: print('Insert failed') return False
Operational issues
async keyword problem
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/pyspider/fetcher/tornado_fetcher.py", line 81 def __init__(self, inqueue, outqueue, poolsize=100, proxy=None, async=True): ^ SyntaxError: invalid syntax
This problem is mainly because async has become a keyword in Python 3. The solution is to open the wrong file (tornado_fetcher.py )Change the wrong async to another variable name
summary
After learning the Pysider framework, the main work in the capture page will be on the parsing page, without paying attention to the timing plan and URL de duplication of the capture task, which is super convenient and fast. It is one of the necessary frameworks for Python people to learn.
Code address
Example code: Python-100-days-day072
Pay attention to the official account: python technology, reply to "python", learn and communicate with each other.