by Leisure
Want to crawl website data? Log in first! For most large-scale websites, the first threshold to crawl their data is to log in to the website. Now please follow my steps to learn how to simulate landing on the website.
Why do I log in?
There are two kinds of websites on the Internet: need to log in and don't need to log in. (this is nonsense!)
Then, for websites that do not need to log in, we can get data directly, which is simple and convenient. For websites that need to log in to view data or not log in to view only part of data, we have to log in to the website obediently. (unless you hack into someone's database directly, please use it with caution!)
Therefore, for websites that need to be logged in, we need to simulate the login. On the one hand, we need to get the information and data of the page after the login, and on the other hand, we need to get the cookie after the login for the next request.
The idea of simulated landing
When it comes to simulated landing, your first reaction must be: cut! Isn't that easy? Open the browser, input the web address, find the user name and password box, input the user name and password, and then click login to finish!
There is no problem in this way. This is how our selenium simulated Login works.
In addition, our Requests can also directly carry cookies that have been logged in for Requests, which is equivalent to bypassing the login.
We can also use Requests to send post Requests, and attach the information needed for website login to post Requests for login.
The above are three common ways to simulate the landing on the website. So our Scrapy also uses the latter two ways. After all, the first way is only unique to selenium.
Scrapy's idea of simulated Login:
1. Directly carry cookies that have been logged in for request
2. Attach information required for website login to post request for login
Simulated landing example
Simulated login with cookies
Each login method has its advantages and disadvantages as well as its use scenarios. Let's take a look at the application scenarios of login with cookies:
1. Cookies expire for a long time. We can log in once without worrying about the problem of login expiration, which is common in some irregular websites.
2. We can get all the data we need before the cookie expires.
3. We can use it with other programs, such as using selenium to save the cookie obtained after login to the local, and then read the local cookie before Scrapy sends the request.
Now we will talk about this kind of simulated Login through Renren, which has been forgotten for a long time.
Let's first create a scratch project:
> scrapy startproject login
In order to crawl smoothly, first set the robots protocol in settings to False:
ROBOTSTXT_OBEY = False
Next, we create a reptile:
> scrapy genspider renren renren.com
Let's open the renren.py , the code is as follows:
# -*- coding: utf-8 -*- import scrapy class RenrenSpider(scrapy.Spider): name = 'renren' allowed_domains = ['renren.com'] start_urls = ['http://renren.com/'] def parse(self, response): pass
We know, start_urls stores the first web address we need to crawl. This is the initial web page for us to crawl data. If I need to crawl the data of Renren's personal center page, I will log in Renren and enter the personal center page. The website is: http://www.renren.com/972990680/profile , if I put this website directly to start_ In URLs, then we ask directly. Let's think about it. Can we succeed?
No way, right! Because we haven't logged in yet, we can't see the personal center page at all.
So where do we add our login code?
What we can be sure of is that we have to request start in the framework_ Log in before the page in URLs.
Enter the source code of Spider class and find the following code:
def start_requests(self): cls = self.__class__ if method_is_overridden(cls, Spider, 'make_requests_from_url'): warnings.warn( "Spider.make_requests_from_url method is deprecated; it " "won't be called in future Scrapy releases. Please " "override Spider.start_requests method instead (see %s.%s)." % ( cls.__module__, cls.__name__ ), ) for url in self.start_urls: yield self.make_requests_from_url(url) else: for url in self.start_urls: yield Request(url, dont_filter=True) def make_requests_from_url(self, url): """ This method is deprecated. """ return Request(url, dont_filter=True)
As we can see from this source code, this method starts from start_ URL s, and then construct a Request object to Request. In this case, we can rewrite start_ The requests method does something by adding cookies to the Request object.
Rewritten start_ The requests method is as follows:
# -*- coding: utf-8 -*- import scrapy import re class RenrenSpider(scrapy.Spider): name = 'renren' allowed_domains = ['renren.com'] # Website of personal center page start_urls = ['http://www.renren.com/972990680/profile'] def start_requests(self): # cookies obtained from the request with chrome's debug tool after login cookiesstr = "anonymid=k3miegqc-hho317; depovince=ZGQT; _r01_=1; JSESSIONID=abcDdtGp7yEtG91r_U-6w; ick_login=d2631ff6-7b2d-4638-a2f5-c3a3f46b1595; ick=5499cd3f-c7a3-44ac-9146-60ac04440cb7; t=d1b681e8b5568a8f6140890d4f05c30f0; societyguester=d1b681e8b5568a8f6140890d4f05c30f0; id=972990680; xnsid=404266eb; XNESSESSIONID=62de8f52d318; jebecookies=4205498d-d0f7-4757-acd3-416f7aa0ae98|||||; ver=7.0; loginfrom=null; jebe_key=8800dc4d-e013-472b-a6aa-552ebfc11486%7Cb1a400326a5d6b2877f8c884e4fe9832%7C1575175011619%7C1%7C1575175011639; jebe_key=8800dc4d-e013-472b-a6aa-552ebfc11486%7Cb1a400326a5d6b2877f8c884e4fe9832%7C1575175011619%7C1%7C1575175011641; wp_fold=0" cookies = {i.split("=")[0]:i.split("=")[1] for i in cookiesstr.split("; ")} # Request with cookies yield scrapy.Request( self.start_urls[0], callback=self.parse, cookies=cookies ) def parse(self, response): # Search for the keyword "leisure" from the personal center page and print it print(re.findall("Leisure and joy", response.body.decode()))
First, I log in renren.com correctly with my account. After logging in, I use chrome's debug tool to get a requested cookie from the Request, and then add the cookie to the Request object. Then I look up the "leisure" keyword in the page in the parse method and print it out.
Let's run this reptile:
>scrapy crawl renren
In the operation log, we can see the following lines:
2019-12-01 13:06:55 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.renren.com/972990680/profile?v=info_timeline> (referer: http://www.renren.com/972990680/profile) ['Leisure and joy', 'Leisure and joy', 'Leisure and joy', 'Leisure and joy', 'Leisure and joy', 'Leisure and joy', 'Leisure and joy'] 2019-12-01 13:06:55 [scrapy.core.engine] INFO: Closing spider (finished)
We can see that the information we need has been printed.
We can add cookies in the settings configuration_ Debug = true to see how cookies are delivered.
After adding this configuration, we can see the following information in the log:
2019-12-01 13:06:55 [scrapy.downloadermiddlewares.cookies] DEBUG: Sending cookies to: <GET http://www.renren.com/972990680/profile?v=info_timeline> Cookie: anonymid=k3miegqc-hho317; depovince=ZGQT; _r01_=1; JSESSIONID=abcDdtGp7yEtG91r_U-6w; ick_login=d2631ff6-7b2d-4638-a2f5-c3a3f46b1595; ick=5499cd3f-c7a3-44ac-9146-60ac04440cb7; t=d1b681e8b5568a8f6140890d4f05c30f0; societyguester=d1b681e8b5568a8f6140890d4f05c30f0; id=972990680; xnsid=404266eb; XNESSESSIONID=62de8f52d318; jebecookies=4205498d-d0f7-4757-acd3-416f7aa0ae98|||||; ver=7.0; loginfrom=null; jebe_key=8800dc4d-e013-472b-a6aa-552ebfc11486%7Cb1a400326a5d6b2877f8c884e4fe9832%7C1575175011619%7C1%7C1575175011641; wp_fold=0; JSESSIONID=abc84VF0a7DUL7JcS2-6w
Send post request to simulate login
Let's take GitHub as an example to describe this kind of simulated Login.
Let's create a crawler github first:
> scrapy genspider github github.com
In order to use post request to simulate login, we need to know the URL address of login and the parameter information required for login. Through the debug tool, we can see the login request information as follows:
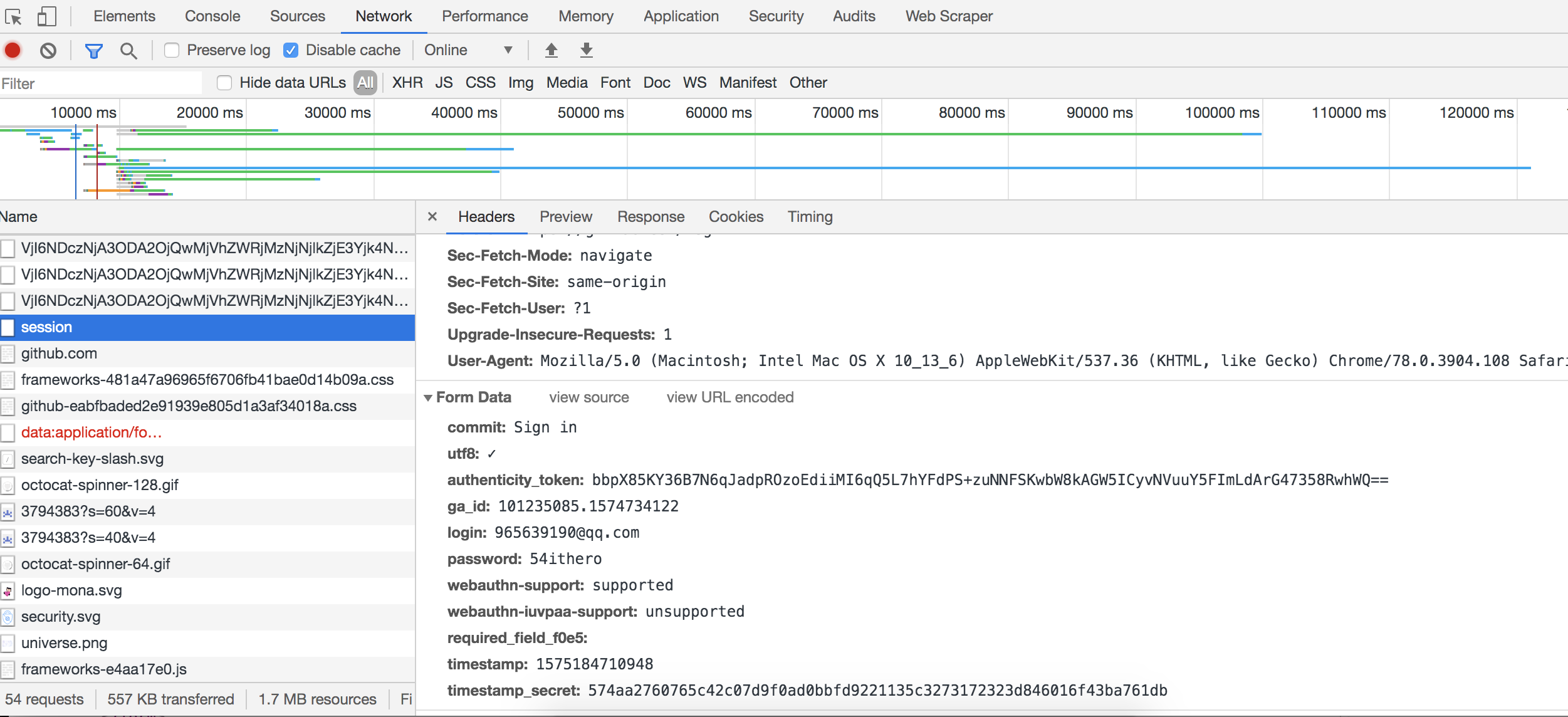
From the request information, we can find the login URL as follows: https://github.com/session , the parameters required for login are:
commit: Sign in utf8: ✓ authenticity_token: bbpX85KY36B7N6qJadpROzoEdiiMI6qQ5L7hYFdPS+zuNNFSKwbW8kAGW5ICyvNVuuY5FImLdArG47358RwhWQ== ga_id: 101235085.1574734122 login: xxx@qq.com password: xxx webauthn-support: supported webauthn-iuvpaa-support: unsupported required_field_f0e5: timestamp: 1575184710948 timestamp_secret: 574aa2760765c42c07d9f0ad0bbfd9221135c3273172323d846016f43ba761db
There are enough parameters for this request, Khan!
In addition to our user name and password, others need to be obtained from the landing page. There is also a required_ field_ The parameter f0e5 needs to be noted that every time the page is loaded, the term is different. It can be seen that it is generated dynamically, but the value is always passed empty, which saves us a parameter. We can not wear this parameter.
The location of other parameters on the page is as follows:
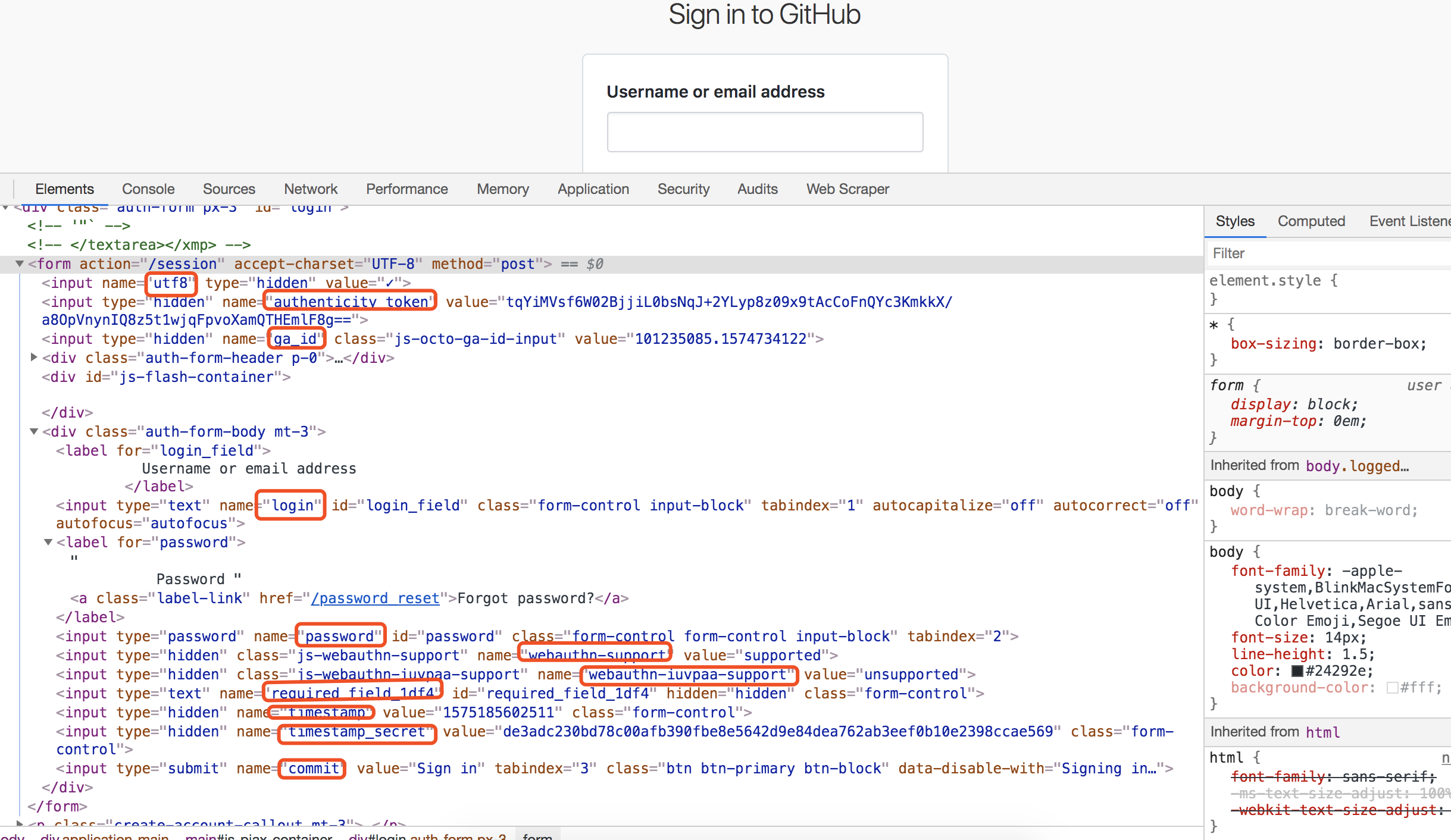
We use xpath to get parameters. The code is as follows (I replaced the user name and password with xxx respectively. Please write your real user name and password when running):
# -*- coding: utf-8 -*- import scrapy import re class GithubSpider(scrapy.Spider): name = 'github' allowed_domains = ['github.com'] # Login page URL start_urls = ['https://github.com/login'] def parse(self, response): # Get request parameters commit = response.xpath("//input[@name='commit']/@value").extract_first() utf8 = response.xpath("//input[@name='utf8']/@value").extract_first() authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first() ga_id = response.xpath("//input[@name='ga_id']/@value").extract_first() webauthn_support = response.xpath("//input[@name='webauthn-support']/@value").extract_first() webauthn_iuvpaa_support = response.xpath("//input[@name='webauthn-iuvpaa-support']/@value").extract_first() # required_field_157f = response.xpath("//input[@name='required_field_4ed5']/@value").extract_first() timestamp = response.xpath("//input[@name='timestamp']/@value").extract_first() timestamp_secret = response.xpath("//input[@name='timestamp_secret']/@value").extract_first() # Construct post parameter post_data = { "commit": commit, "utf8": utf8, "authenticity_token": authenticity_token, "ga_id": ga_id, "login": "xxx@qq.com", "password": "xxx", "webauthn-support": webauthn_support, "webauthn-iuvpaa-support": webauthn_iuvpaa_support, # "required_field_4ed5": required_field_4ed5, "timestamp": timestamp, "timestamp_secret": timestamp_secret } # Print parameters print(post_data) # Send post request yield scrapy.FormRequest( "https://github.com/session ", login request method formdata=post_data, callback=self.after_login ) # Operation after successful login def after_login(self, response): # Locate the Issues field on the page and print print(re.findall("Issues", response.body.decode()))
We use the FormRequest method to send a post request. After running the crawler, an error is reported. Let's look at the error message:
2019-12-01 15:14:47 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://github.com/login> (referer: None) {'commit': 'Sign in', 'utf8': '✓', 'authenticity_token': '3P4EVfXq3WvBM8fvWge7FfmRd0ORFlS6xGcz5mR5A00XnMe7GhFaMKQ8y024Hyy5r/RFS9ZErUDr1YwhDpBxlQ==', 'ga_id': None, 'login': '965639190@qq.com', 'password': '54ithero', 'webauthn-support': 'unknown', 'webauthn-iuvpaa-support': 'unknown', 'timestamp': '1575184487447', 'timestamp_secret': '6a8b589266e21888a4635ab0560304d53e7e8667d5da37933844acd7bee3cd19'} 2019-12-01 15:14:47 [scrapy.core.scraper] ERROR: Spider error processing <GET https://github.com/login> (referer: None) Traceback (most recent call last): File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/utils/defer.py", line 102, in iter_errback yield next(it) File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/core/spidermw.py", line 84, in evaluate_iterable for r in iterable: File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/spidermiddlewares/offsite.py", line 29, in process_spider_output for x in result: File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/core/spidermw.py", line 84, in evaluate_iterable for r in iterable: File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/spidermiddlewares/referer.py", line 339, in <genexpr> return (_set_referer(r) for r in result or ()) File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/core/spidermw.py", line 84, in evaluate_iterable for r in iterable: File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/spidermiddlewares/urllength.py", line 37, in <genexpr> return (r for r in result or () if _filter(r)) File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/core/spidermw.py", line 84, in evaluate_iterable for r in iterable: File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/spidermiddlewares/depth.py", line 58, in <genexpr> return (r for r in result or () if _filter(r)) File "/Users/cxhuan/Documents/python_workspace/scrapy_projects/login/login/spiders/github.py", line 40, in parse callback=self.after_login File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/http/request/form.py", line 32, in __init__ querystr = _urlencode(items, self.encoding) File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/http/request/form.py", line 73, in _urlencode for k, vs in seq File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/http/request/form.py", line 74, in <listcomp> for v in (vs if is_listlike(vs) else [vs])] File "/Applications/anaconda3/lib/python3.7/site-packages/scrapy/utils/python.py", line 107, in to_bytes 'object, got %s' % type(text).__name__) TypeError: to_bytes must receive a unicode, str or bytes object, got NoneType 2019-12-01 15:14:47 [scrapy.core.engine] INFO: Closing spider (finished)
Looking at this error message, it seems that one of the parameters in the parameter value is taken to None, so we can see that GA is found in the printed parameter information_ ID is None, let's modify it again, when GA_ When the ID is None, let's try passing an empty string.
The modification code is as follows:
ga_id = response.xpath("//input[@name='ga_id']/@value").extract_first() if ga_id is None: ga_id = ""
Run the crawler again, this time let's see the results:
Set-Cookie: _gh_sess=QmtQRjB4UDNUeHdkcnE4TUxGbVRDcG9xMXFxclA1SDM3WVhqbFF5U0wwVFp0aGV1UWxYRWFSaXVrZEl0RnVjTzFhM1RrdUVabDhqQldTK3k3TEd3KzNXSzgvRXlVZncvdnpURVVNYmtON0IrcGw1SXF6Nnl0VTVDM2dVVGlsN01pWXNUeU5XQi9MbTdZU0lTREpEMllVcTBmVmV2b210Sm5Sbnc0N2d5aVErbjVDU2JCQnA5SkRsbDZtSzVlamxBbjdvWDBYaWlpcVR4Q2NvY3hwVUIyZz09LS1lMUlBcTlvU0F0K25UQ3loNHFOZExnPT0%3D--8764e6d2279a0e6960577a66864e6018ef213b56; path=/; secure; HttpOnly 2019-12-01 15:25:18 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://github.com/> (referer: https://github.com/login) ['Issues', 'Issues'] 2019-12-01 15:25:18 [scrapy.core.engine] INFO: Closing spider (finished)
We can see that the information we need has been printed and the login is successful.
Scrapy provides another method from for form request_ Response to automatically get the form in the page, we just need to pass in the user name and password to send the request.
Let's look at the source code of this method:
@classmethod def from_response(cls, response, formname=None, formid=None, formnumber=0, formdata=None, clickdata=None, dont_click=False, formxpath=None, formcss=None, **kwargs): kwargs.setdefault('encoding', response.encoding) if formcss is not None: from parsel.csstranslator import HTMLTranslator formxpath = HTMLTranslator().css_to_xpath(formcss) form = _get_form(response, formname, formid, formnumber, formxpath) formdata = _get_inputs(form, formdata, dont_click, clickdata, response) url = _get_form_url(form, kwargs.pop('url', None)) method = kwargs.pop('method', form.method) if method is not None: method = method.upper() if method not in cls.valid_form_methods: method = 'GET' return cls(url=url, method=method, formdata=formdata, **kwargs)
We can see that there are many parameters of this method, all of which are information about form positioning. If there is only one form in the login page, Scrapy can be easily located, but what if there are multiple forms in the page? At this time, we need to use these parameters to tell Scrapy which is the login form.
Of course, the premise of this method is that the action of the form form form of our web page contains the url address of the submitted request.
In the github example, our login page has only one login form, so we just need to pass in the user name and password. The code is as follows:
# -*- coding: utf-8 -*- import scrapy import re class Github2Spider(scrapy.Spider): name = 'github2' allowed_domains = ['github.com'] start_urls = ['http://github.com/login'] def parse(self, response): yield scrapy.FormRequest.from_response( response, # Automatically find form form from response formdata={"login": "xxx@qq.com", "password": "xxx"}, callback=self.after_login ) # Operation after successful login def after_login(self, response): # Locate the Issues field on the page and print print(re.findall("Issues", response.body.decode()))
After running the crawler, we can see the same results as before.
Is this a lot easier? It doesn't need us to find all kinds of request parameters. Do you think it's Amazing?
summary
This article introduces several methods of Scrapy's simulated landing on the website. You can use the methods in this article to practice. Of course, there is no verification code involved here. Verification code is a complex and difficult topic. I will introduce it to you later.
Example code: python-100-days
Pay attention to the official account: python technology, reply to "python", learn and communicate with each other.