day23 concurrent programming (Part 2)
Course objective: master the relevant knowledge points of multi process development and preliminarily understand the collaborative process.
Today's summary:
- Multi process development
- Data sharing between processes
- Process lock
- Process pool
- Synergetic process
1. Multi process development
Process is the smallest unit of resource allocation in computer; There can be multiple threads in a process, and the threads in the same process share resources;
Processes are isolated from each other.
Python can take advantage of the multi-core advantage of CPU through multiple processes, and computing intensive operations are suitable for multiple processes.
1.1 process introduction
import multiprocessing
def task():
pass
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task)
p1.start()
from multiprocessing import Process
def task(arg):
pass
def run():
p = multiprocessing.Process(target=task, args=('xxx',))
p.start()
if __name__ == '__main__':
run()
About processes based on multiprocessing module operation in Python:
Depending on the platform, multiprocessing supports three ways to start a process. These start methods are
-
fork, [copy almost all resources] [support file object / thread lock and other parameters] [unix] [start anywhere] [fast]
The parent process uses os.fork() to fork the Python interpreter. The child process, when it begins, is effectively identical to the parent process. All resources of the parent are inherited by the child process. Note that safely forking a multithreaded process is problematic.Available on Unix only. The default on Unix.
-
spawn, [pass run parameters to necessary resources] [pass file objects / thread locks and other parameters not supported] [unix, win] [start of main code block] [slow]
The parent process starts a fresh python interpreter process. The child process will only inherit those resources necessary to run the process object's run() method. In particular, unnecessary file descriptors and handles from the parent process will not be inherited. Starting a process using this method is rather slow compared to using fork or forkserver.Available on Unix and Windows. The default on Windows and macOS.
-
forkserver, [pass run parameters to necessary resources] [do not support file object / thread lock and other parameters] [part of unix] [start of main code block]
When the program starts and selects the forkserver start method, a server process is started. From then on, whenever a new process is needed, the parent process connects to the server and requests that it fork a new process. The fork server process is single threaded so it is safe for it to use os.fork(). No unnecessary resources are inherited.Available on Unix platforms which support passing file descriptors over Unix pipes.
import multiprocessing
multiprocessing.set_start_method("spawn")
Changed in version 3.8: On macOS, the spawn start method is now the default. The fork start method should be considered unsafe as it can lead to crashes of the subprocess. See bpo-33725.
Changed in version 3.4: spawn added on all unix platforms, and forkserver added for some unix platforms. Child processes no longer inherit all of the parents inheritable handles on Windows.
On Unix using the spawn or forkserver start methods will also start a resource tracker process which tracks the unlinked named system resources (such as named semaphores or SharedMemory objects) created by processes of the program. When all processes have exited the resource tracker unlinks any remaining tracked object. Usually there should be none, but if a process was killed by a signal there may be some "leaked" resources. (Neither leaked semaphores nor shared memory segments will be automatically unlinked until the next reboot. This is problematic for both objects because the system allows only a limited number of named semaphores, and shared memory segments occupy some space in the main memory.)
Official documents: https://docs.python.org/3/library/multiprocessing.html
-
Example 1
import multiprocessing import time """ def task(): print(name) name.append(123) if __name__ == '__main__': multiprocessing.set_start_method("fork") # fork,spawn,forkserver name = [] p1 = multiprocessing.Process(target=task) p1.start() time.sleep(2) print(name) # [] """ """ def task(): print(name) # [123] if __name__ == '__main__': multiprocessing.set_start_method("fork") # fork,spawn,forkserver name = [] name.append(123) p1 = multiprocessing.Process(target=task) p1.start() """ """ def task(): print(name) # [] if __name__ == '__main__': multiprocessing.set_start_method("fork") # fork,spawn,forkserver name = [] p1 = multiprocessing.Process(target=task) p1.start() name.append(123) """ -
Example 2
import multiprocessing def task(): print(name) print(file_object) if __name__ == '__main__': multiprocessing.set_start_method("fork") # fork,spawn,forkserver name = [] file_object = open('x1.txt', mode='a+', encoding='utf-8') p1 = multiprocessing.Process(target=task) p1.start()
Case:
import multiprocessing
def task():
print(name)
file_object.write("alex\n")
file_object.flush()
if __name__ == '__main__':
multiprocessing.set_start_method("fork")
name = []
file_object = open('x1.txt', mode='a+', encoding='utf-8')
file_object.write("Wu Peiqi\n")
p1 = multiprocessing.Process(target=task)
p1.start()
"""
Wu Peiqi
alex
Wu Peiqi
"""
import multiprocessing
def task():
print(name)
file_object.write("alex\n")
file_object.flush()
if __name__ == '__main__':
multiprocessing.set_start_method("fork")
name = []
file_object = open('x1.txt', mode='a+', encoding='utf-8')
file_object.write("Wu Peiqi\n")
file_object.flush()
p1 = multiprocessing.Process(target=task)
p1.start()
"""
Wu Peiqi
alex
"""
import multiprocessing
import threading
import time
def func():
print("coming")
with lock:
print(666)
time.sleep(1)
def task():
# The copy lock is also in the state of being applied for
# Who applied to leave? The main thread in the subprocess applied to leave
for i in range(10):
t = threading.Thread(target=func)
t.start()
time.sleep(2)
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method("fork")
name = []
lock = threading.RLock()
lock.acquire()
# print(lock)
# lock.acquire() # Apply for lock
# print(lock)
# lock.release()
# print(lock)
# lock.acquire() # Apply for lock
# print(lock)
p1 = multiprocessing.Process(target=task)
p1.start()
1.2 common functions
Common methods of process:
-
p.start(), the current process is ready and waiting to be scheduled by the CPU (the unit of work is actually the thread in the process).
-
p.join(), wait until the task of the current process is executed, and then continue to execute downward.
import time from multiprocessing import Process def task(arg): time.sleep(2) print("In execution...") if __name__ == '__main__': multiprocessing.set_start_method("spawn") p = Process(target=task, args=('xxx',)) p.start() p.join() print("Continue execution...") -
p.daemon = Boolean, daemon (must be placed before start)
- p.daemon =True, which is set as a daemon. After the main process is executed, the child process will be closed automatically.
- p.daemon =False, set as a non daemon. The main process waits for the child process. The main process will not end until the child process is executed.
import time from multiprocessing import Process def task(arg): time.sleep(2) print("In execution...") if __name__ == '__main__': multiprocessing.set_start_method("spawn") p = Process(target=task, args=('xxx',)) p.daemon = True p.start() print("Continue execution...") -
Setting and obtaining the name of the process
import os import time import threading import multiprocessing def func(): time.sleep(3) def task(arg): for i in range(10): t = threading.Thread(target=func) t.start() print(os.getpid(), os.getppid()) print("Number of threads", len(threading.enumerate())) time.sleep(2) print("Name of current process:", multiprocessing.current_process().name) if __name__ == '__main__': print(os.getpid()) multiprocessing.set_start_method("spawn") p = multiprocessing.Process(target=task, args=('xxx',)) p.name = "Ha ha ha ha" p.start() print("Continue execution...") -
Customize the process class and directly write what the thread needs to do to the run method.
import multiprocessing class MyProcess(multiprocessing.Process): def run(self): print('Execute this process', self._args) if __name__ == '__main__': multiprocessing.set_start_method("spawn") p = MyProcess(args=('xxx',)) p.start() print("Continue execution...") -
Number of CPUs, how many processes does the program generally create? (take advantage of CPU multi-core).
import multiprocessing multiprocessing.cpu_count()
import multiprocessing if __name__ == '__main__': count = multiprocessing.cpu_count() for i in range(count - 1): p = multiprocessing.Process(target=xxxx) p.start()
2. Data sharing between processes
Process is the smallest unit of resource allocation. Each process maintains its own independent data and does not share it.
import multiprocessing
def task(data):
data.append(666)
if __name__ == '__main__':
data_list = []
p = multiprocessing.Process(target=task, args=(data_list,))
p.start()
p.join()
print("Main process:", data_list) # []
If you want them to share, you can use some special things to achieve.
2.1 sharing
Shared memory
Data can be stored in a shared memory map using Value or Array. For example, the following code
'c': ctypes.c_char, 'u': ctypes.c_wchar,
'b': ctypes.c_byte, 'B': ctypes.c_ubyte,
'h': ctypes.c_short, 'H': ctypes.c_ushort,
'i': ctypes.c_int, 'I': ctypes.c_uint, (his u (indicates unsigned)
'l': ctypes.c_long, 'L': ctypes.c_ulong,
'f': ctypes.c_float, 'd': ctypes.c_double
from multiprocessing import Process, Value, Array
def func(n, m1, m2):
n.value = 888
m1.value = 'a'.encode('utf-8')
m2.value = "martial"
if __name__ == '__main__':
num = Value('i', 666)
v1 = Value('c')
v2 = Value('u')
p = Process(target=func, args=(num, v1, v2))
p.start()
p.join()
print(num.value) # 888
print(v1.value) # a
print(v2.value) # martial
from multiprocessing import Process, Value, Array
def f(data_array):
data_array[0] = 666
if __name__ == '__main__':
arr = Array('i', [11, 22, 33, 44]) # Array: element type must be int; It can only be such a few data.
p = Process(target=f, args=(arr,))
p.start()
p.join()
print(arr[:])
Server process
A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies.
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.append(666)
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list()
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)
2.2 exchange
multiprocessing supports two types of communication channel between processes
Queues

The Queue class is a near clone of queue.Queue. For example
import multiprocessing
def task(q):
for i in range(10):
q.put(i)
if __name__ == '__main__':
queue = multiprocessing.Queue()
p = multiprocessing.Process(target=task, args=(queue,))
p.start()
p.join()
print("Main process")
print(queue.get())
print(queue.get())
print(queue.get())
print(queue.get())
print(queue.get())
Pipes

The Pipe() function returns a pair of connection objects connected by a pipe which by default is duplex (two-way). For example:
import time
import multiprocessing
def task(conn):
time.sleep(1)
conn.send([111, 22, 33, 44])
data = conn.recv() # block
print("Subprocess receive:", data)
time.sleep(2)
if __name__ == '__main__':
parent_conn, child_conn = multiprocessing.Pipe()
p = multiprocessing.Process(target=task, args=(child_conn,))
p.start()
info = parent_conn.recv() # block
print("Main process receiving:", info)
parent_conn.send(666)
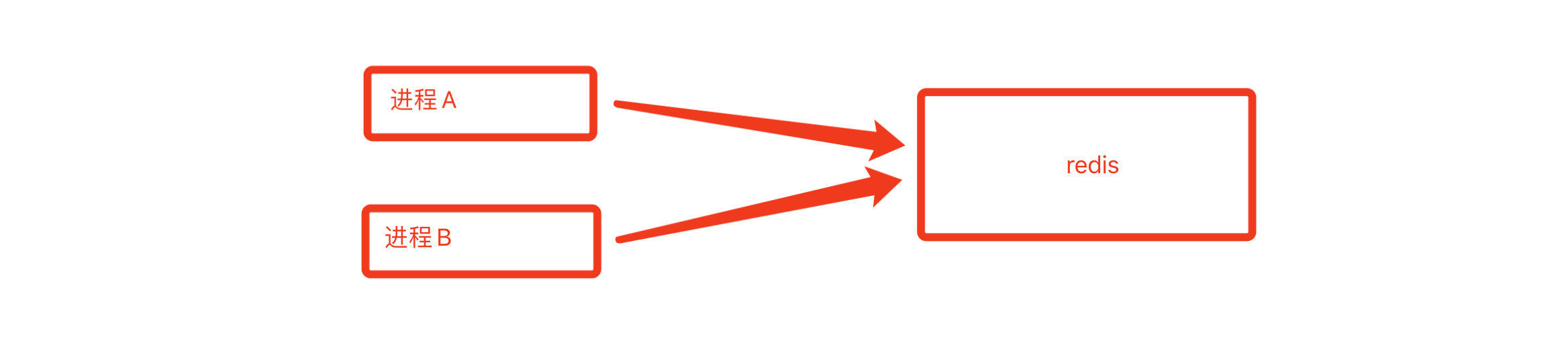
The above are the mechanisms of data sharing and exchange between processes provided by Python. As an understanding, they are rarely used in project development. In later projects, resources are generally shared with the help of third parties, such as MySQL, redis, etc.
3. Process lock
If multiple processes preempt to do some operations, in order to prevent problems in the operation, process locks can be used to avoid them.
import time
from multiprocessing import Process, Value, Array
def func(n, ):
n.value = n.value + 1
if __name__ == '__main__':
num = Value('i', 0)
for i in range(20):
p = Process(target=func, args=(num,))
p.start()
time.sleep(3)
print(num.value)
import time
from multiprocessing import Process, Manager
def f(d, ):
d[1] += 1
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
d[1] = 0
for i in range(20):
p = Process(target=f, args=(d,))
p.start()
time.sleep(3)
print(d)
import time
import multiprocessing
def task():
# Suppose the content saved in the file is a value: 10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("Queue up for tickets")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
if __name__ == '__main__':
for i in range(20):
p = multiprocessing.Process(target=task)
p.start()
Obviously, there will be problems in the operation of multiple processes. At this time, locks are needed to intervene:
import time
import multiprocessing
def task(lock):
print("start")
lock.acquire()
# Suppose the content saved in the file is a value: 10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("Queue up for tickets")
time.sleep(0.5)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
lock = multiprocessing.RLock() # Process lock
for i in range(10):
p = multiprocessing.Process(target=task, args=(lock,))
p.start()
# spawn mode requires special processing.
time.sleep(7)
import time
import multiprocessing
import os
def task(lock):
print("start")
lock.acquire()
# Suppose the content saved in the file is a value: 10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print(os.getpid(), "Queue up for tickets")
time.sleep(0.5)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
lock = multiprocessing.RLock()
process_list = []
for i in range(10):
p = multiprocessing.Process(target=task, args=(lock,))
p.start()
process_list.append(p)
# spawn mode requires special processing.
for item in process_list:
item.join()
import time
import multiprocessing
def task(lock):
print("start")
lock.acquire()
# Suppose the content saved in the file is a value: 10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("Queue up for tickets")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method('fork')
lock = multiprocessing.RLock()
for i in range(10):
p = multiprocessing.Process(target=task, args=(lock,))
p.start()
4. Process pool
import time
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
def task(num):
print("implement", num)
time.sleep(2)
if __name__ == '__main__':
# Modify mode
pool = ProcessPoolExecutor(4)
for i in range(10):
pool.submit(task, i)
print(1)
print(2)
import time
from concurrent.futures import ProcessPoolExecutor
def task(num):
print("implement", num)
time.sleep(2)
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
for i in range(10):
pool.submit(task, i)
# Wait until all tasks in the process pool are executed, and then continue to execute later.
pool.shutdown(True)
print(1)
import time
from concurrent.futures import ProcessPoolExecutor
import multiprocessing
def task(num):
print("implement", num)
time.sleep(2)
return num
def done(res):
print(multiprocessing.current_process())
time.sleep(1)
print(res.result())
time.sleep(1)
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
for i in range(50):
fur = pool.submit(task, i)
fur.add_done_callback(done) # The call to done is handled by the main process (unlike the thread pool)
print(multiprocessing.current_process())
pool.shutdown(True)
Note: if you want to use a process Lock in the process pool, you need to implement it based on Lock and RLock in the Manager.
import time
import multiprocessing
from concurrent.futures.process import ProcessPoolExecutor
def task(lock):
print("start")
# lock.acquire()
# lock.relase()
with lock:
# Suppose the content saved in the file is a value: 10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("Queue up for tickets")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
if __name__ == '__main__':
pool = ProcessPoolExecutor()
# lock_object = multiprocessing.RLock() # out of commission
manager = multiprocessing.Manager()
lock_object = manager.RLock() # Lock
for i in range(10):
pool.submit(task, lock_object)
Case: calculate daily user access.
-
Example 1
import os import time from concurrent.futures import ProcessPoolExecutor from multiprocessing import Manager def task(file_name, count_dict): ip_set = set() total_count = 0 ip_count = 0 file_path = os.path.join("files", file_name) file_object = open(file_path, mode='r', encoding='utf-8') for line in file_object: if not line.strip(): continue user_ip = line.split(" - -", maxsplit=1)[0].split(",")[0] total_count += 1 if user_ip in ip_set: continue ip_count += 1 ip_set.add(user_ip) count_dict[file_name] = {"total": total_count, 'ip': ip_count} time.sleep(1) def run(): # Read the file according to the directory and initialize the dictionary """ 1.Read all the files in the directory, and each process processes one file. """ pool = ProcessPoolExecutor(4) with Manager() as manager: """ count_dict={ "20210322.log":{"total":10000,'ip':800}, } """ count_dict = manager.dict() for file_name in os.listdir("files"): pool.submit(task, file_name, count_dict) pool.shutdown(True) for k, v in count_dict.items(): print(k, v) if __name__ == '__main__': run() -
Example 2
import os import time from concurrent.futures import ProcessPoolExecutor def task(file_name): ip_set = set() total_count = 0 ip_count = 0 file_path = os.path.join("files", file_name) file_object = open(file_path, mode='r', encoding='utf-8') for line in file_object: if not line.strip(): continue user_ip = line.split(" - -", maxsplit=1)[0].split(",")[0] total_count += 1 if user_ip in ip_set: continue ip_count += 1 ip_set.add(user_ip) time.sleep(1) return {"total": total_count, 'ip': ip_count} def outer(info, file_name): def done(res, *args, **kwargs): info[file_name] = res.result() return done def run(): # Read the file according to the directory and initialize the dictionary """ 1.Read all the files in the directory, and each process processes one file. """ info = {} pool = ProcessPoolExecutor(4) for file_name in os.listdir("files"): fur = pool.submit(task, file_name) fur.add_done_callback( outer(info, file_name) ) # Callback function: main process pool.shutdown(True) for k, v in info.items(): print(k, v) if __name__ == '__main__': run()
5. Coordination process
For the time being, we mainly focus on understanding.
Threads and processes are provided in the computer to realize concurrent programming (real existence).
Coroutine is something that programmers make out of code (non real).
Coroutine, also known as micro thread, is a context switching technology in user state. In short, it is actually a thread to switch the execution of code blocks (jumping back and forth).
For example:
def func1():
print(1)
...
print(2)
def func2():
print(3)
...
print(4)
func1()
func2()
The above code is a common function definition and execution. The codes in the two functions are executed according to the process, and will be output successively: 1, 2, 3 and 4.
However, if the coprocessing technology is involved, the function can be switched and executed. The final input is 1, 3, 2 and 4.
There are many ways to implement co procedures in Python, such as:
-
greenlet
pip install greenlet
from greenlet import greenlet def func1(): print(1) # Step 1: output 1 gr2.switch() # Step 3: switch to func2 function print(2) # Step 6: output 2 gr2.switch() # Step 7: switch to func2 function and continue to execute backward from the last execution position def func2(): print(3) # Step 4: output 3 gr1.switch() # Step 5: switch to func1 function and continue to execute backward from the last execution position print(4) # Step 8: output 4 gr1 = greenlet(func1) gr2 = greenlet(func2) gr1.switch() # Step 1: execute func1 function -
yield
def func1(): yield 1 yield from func2() yield 2 def func2(): yield 3 yield 4 f1 = func1() for item in f1: print(item)
Although both of the above methods implement the collaborative process, this way of writing code is meaningless.
This back and forth switching execution may make the execution speed of the program slower (compared with serial).
How can a collaborative process be more meaningful?
Do not let the user switch manually, but can switch automatically in case of IO operation.
Python introduced asyncio module + Python 3.4 after 3.4 5. Async and async syntax are introduced. It is internally based on the collaborative process and automatically switches when encountering IO requests.
import asyncio
async def func1():
print(1)
await asyncio.sleep(2)
print(2)
async def func2():
print(3)
await asyncio.sleep(2)
print(4)
tasks = [
asyncio.ensure_future(func1()),
asyncio.ensure_future(func2())
]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
"""
You need to install: pip3 install aiohttp
"""
import aiohttp
import asyncio
async def fetch(session, url):
print("Send request:", url)
async with session.get(url, verify_ssl=False) as response:
content = await response.content.read()
file_name = url.rsplit('_')[-1]
with open(file_name, mode='wb') as file_object:
file_object.write(content)
async def main():
async with aiohttp.ClientSession() as session:
url_list = [
'https://www3.autoimg.cn/newsdfs/g26/M02/35/A9/120x90_0_autohomecar__ChsEe12AXQ6AOOH_AAFocMs8nzU621.jpg',
'https://www2.autoimg.cn/newsdfs/g30/M01/3C/E2/120x90_0_autohomecar__ChcCSV2BBICAUntfAADjJFd6800429.jpg',
'https://www3.autoimg.cn/newsdfs/g26/M0B/3C/65/120x90_0_autohomecar__ChcCP12BFCmAIO83AAGq7vK0sGY193.jpg'
]
tasks = [asyncio.create_task(fetch(session, url)) for url in url_list]
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
Through the above contents, it is found that when processing IO requests, the coroutine can realize concurrent operations through one thread.
What are the differences among processes, threads and processes?
A thread is a thread that can be used in a computer cpu The smallest unit of scheduling.
Process is the smallest unit of computer resource allocation (process provides resources for threads).
There can be multiple threads in a process,Threads in the same process can share resources in this process.
because CPython in GIL Existence of:
- Thread for IO Intensive operation.
- Process, suitable for computing intensive operations.
Coprocess, also known as micro thread, is a context switching technology in user mode, which is encountered in the development IO Automatic switching, you can achieve concurrent operation through a thread.
So, in dealing with IO During operation, the cooperative process saves more overhead than the thread (the development of the cooperative process is more difficult).
At present, many frameworks in Python are supporting collaborative processes, such as FastAPI, Tornado, Sanic, Django 3, aiohttp, etc. more and more enterprises are developing and using them (not very much at present).
As for the collaborative process, at present, students can understand these concepts first. For more in-depth development and application, there is no need to know too much for the time being. It will be better to learn and supplement after you have learned the relevant knowledge of Web framework and crawler. Students who are interested in studying can refer to my articles and special videos:
-
article
https://pythonav.com/wiki/detail/6/91/ https://zhuanlan.zhihu.com/p/137057192
-
video
https://www.bilibili.com/video/BV1NA411g7yf
summary
- Understand several modes of the process
- Master the common operations of processes and process pools
- Data sharing between processes
- Process lock
- Thread, process (difference)