1, VGG network
VGG model is the second place in the 2014 ILSVRC competition, and the first place is GoogLeNet . But the VGG model works in multiple Transfer learning The performance in the task is better than Google net. VGG is a network developed from Alexnet. VGG has 19 layers (16 + 3) and five convolutions. Each convolution is followed by the maximum pooling layer (the whole network uses the same size of 3 * 3 convolution core size and 2 * 2 maximum pooling size, and the network result is simple). The three full connection layers are connected with a softmax at the end, and the activation units of all hidden layers use the ReLU function.
The biggest contribution of VGG is to prove that the increase of the depth of convolution neural network and the use of small convolution kernel play a great role in the final classification and recognition effect of the network.
2, Innovation
Because VGG is improved based on the Alexnet network in order to increase the network depth, let's introduce the differences between VGG and Alexnet:
1. The whole network uses a small convolution kernel (3 * 3) to replace the large convolution kernel of 5 * 5 or even 11 * 11 in Alexnet network. Using the convolution layer of multiple smaller convolution kernels to replace the larger convolution layer of one convolution kernel can reduce the parameters on the one hand, on the other hand, the author believes that it is equivalent to more nonlinear mapping and increase the fitting expression ability of the network.
[the size of the receptive field obtained by two 3x3 convolution stacks is equivalent to a 5x5 convolution; while the receptive field obtained by three 3x3 convolution stacks is equivalent to a 7x7 convolution.]
2. The pool core is also smaller. In VGG, the pool core is 2x2stride is 2, and the Alex net pool core is 3x3stride is 2.
3. The LRN layer is removed from VGG because it is found that it can not improve the network performance during training, which increases the memory consumption and computing time.
3, Structural analysis
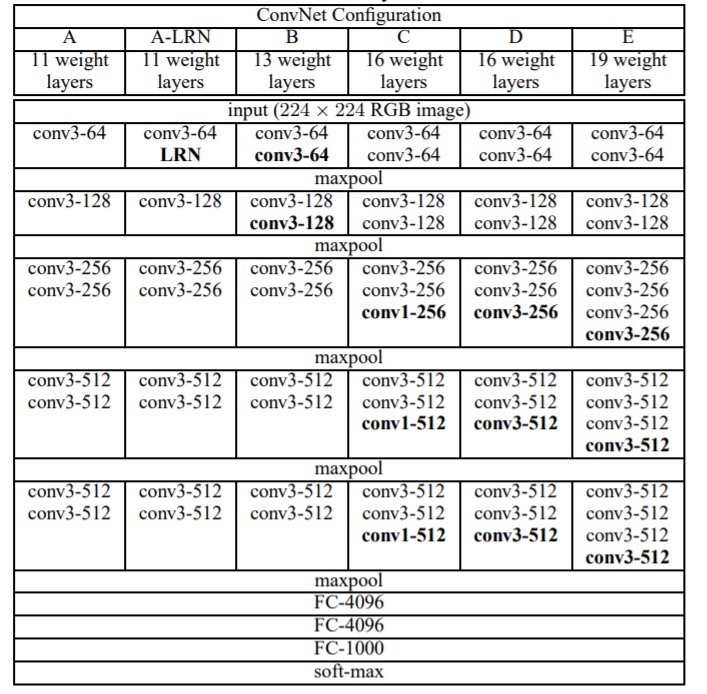
As shown in the figure, the author tested six network structures. The difference is that the number of sublayers of each convolution layer is different. Network structure D is the famous VGG16 and network structure E is the famous VGG19. (conv3-64 represents a convolution kernel of 3 * 3, with 64 channels)
Next, take VGG16 network structure as an example:
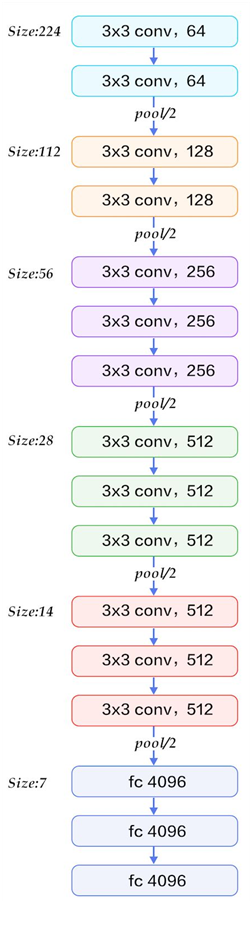
(each 3 * 3 convolution is padded by 1 pixel first)
4, Code implementation
from torch import nn
class Vgg16Net(nn.Module):
def __init__(self):
super(Vgg16Net, self).__init__()
# First layer, 2 convolution layers and one maximum pool layer
self.layer1 = nn.Sequential(
# Input 3 channels, convolution kernel 3 * 3, output 64 channels (such as sample pictures of 32 * 32 * 3, (32 + 2 * 1-3) / 1 + 1 = 32, output 32 * 32 * 64)
nn.Conv2d(3, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# Input 64 channels, convolution kernel 3 * 3, output 64 channels (input 32 * 32 * 64, convolution 3 * 3 * 64 * 64, output 32 * 32 * 64)
nn.Conv2d(64, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# Input 32 * 32 * 64, output 16 * 16 * 64
nn.MaxPool2d(kernel_size=2, stride=2)
)
# Second layer, 2 convolution layers and one maximum pool layer
self.layer2 = nn.Sequential(
# Input 64 channels, convolution kernel 3 * 3, output 128 channels (input 16 * 16 * 64, convolution 3 * 3 * 64 * 128, output 16 * 16 * 128)
nn.Conv2d(64, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# Input 128 channels, convolution kernel 3 * 3, output 128 channels (input 16 * 16 * 128, convolution 3 * 3 * 128 * 128, output 16 * 16 * 128)
nn.Conv2d(128, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# Input 16 * 16 * 128, output 8 * 8 * 128
nn.MaxPool2d(kernel_size=2, stride=2)
)
# The third layer, three convolution layers and one maximum pool layer
self.layer3 = nn.Sequential(
# Input 128 channels, convolution kernel 3 * 3, output 256 channels (input 8 * 8 * 128, convolution 3 * 3 * 128 * 256, output 8 * 8 * 256)
nn.Conv2d(128, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# Input 256 channels, convolution kernel 3 * 3, output 256 channels (input 8 * 8 * 256, convolution 3 * 3 * 256 * 256, output 8 * 8 * 256)
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# Input 256 channels, convolution kernel 3 * 3, output 256 channels (input 8 * 8 * 256, convolution 3 * 3 * 256 * 256, output 8 * 8 * 256)
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# Input 8 * 8 * 256, output 4 * 4 * 256
nn.MaxPool2d(kernel_size=2, stride=2)
)
# The fourth layer, three convolution layers and one maximum pool layer
self.layer4 = nn.Sequential(
# Input 256 channels, convolution 3 * 3, output 512 channels (input 4 * 4 * 256, convolution 3 * 3 * 256 * 512, output 4 * 4 * 512)
nn.Conv2d(256, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution 3 * 3, output 512 channels (input 4 * 4 * 512, convolution 3 * 3 * 512 * 512, output 4 * 4 * 512)
nn.Conv2d(512, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution 3 * 3, output 512 channels (input 4 * 4 * 512, convolution 3 * 3 * 512 * 512, output 4 * 4 * 512)
nn.Conv2d(512, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 4 * 4 * 512, output 2 * 2 * 512
nn.MaxPool2d(kernel_size=2, stride=2)
)
# The fifth layer, 3 convolution layers and 1 maximum pool layer
self.layer5 = nn.Sequential(
# Input 512 channels, convolution 3 * 3, output 512 channels (input 2 * 2 * 512, convolution 3 * 3 * 512 * 512, output 2 * 2 * 512)
nn.Conv2d(512, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution 3 * 3, output 512 channels (input 2 * 2 * 512, convolution 3 * 3 * 512 * 512, output 2 * 2 * 512)
nn.Conv2d(512, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution 3 * 3, output 512 channels (input 2 * 2 * 512, convolution 3 * 3 * 512 * 512, output 2 * 2 * 512)
nn.Conv2d(512, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 2 * 2 * 512, output 1 * 1 * 512
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.conv_layer = nn.Sequential(
self.layer1,
self.layer2,
self.layer3,
self.layer4,
self.layer5
)
self.fc = nn.Sequential(
nn.Linear(512, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 1000)
)
def forward(self, x):
x = self.conv_layer(x)
x = x.view(-1, 512)
x = self.fc(x)
return x
reference resources:
https://blog.csdn.net/daydayup_668819/article/details/79932324
https://blog.csdn.net/qq_25737169
https://blog.csdn.net/dcrmg/article/details/79254654