Test and Storage Classifier
introduce
After the decision tree is constructed based on the training data, we can use it to classify the actual data. Decision trees and label vectors used to construct trees are needed in data classification. Then, the program compares the test data with the values on the decision tree, and executes the process recursively until it enters the leaf node. Finally, the test data is defined as the type of leaf node.
Popularly speaking, your data set now has two features and a classification label. Then an unknown sample data gives you the attribute values of two features so that you can predict the sample.
Code section
Decision Tree: Sample Prediction
Only the first one in the code is explained after the new functions are added, and then the emphasis is on the position correspondence of features in the data set. (In fact, it is to find out which attribute value of the first feature point you give to each stage in the sample set, so that we can make a further judgement if we know it.)
""" //Function description: //Classification of Decision Trees Parameters: inputTree: decision tree featLabels: Data Set label Sequential list testVec: Attribute values of two features[Feature 1, Feature 2] Rertun: classLabel: Prediction results //Predicting classification based on attribute values of two features """ def classify(inputTree, featLabels, testVec): firstStr = list(inputTree.keys())[0] # Get the first key value secondDict = inputTree[firstStr] # The value of the first key - > the next branch featIndex = featLabels.index(firstStr) # Determine which of the tag vectors is the root node (index) key = testVec[featIndex] # Classification after determining a condition or entering the next branch remains to be determined # Note here that we do not know the specific location of the current node (i.e., feature) in the data set [0,1,no] # Is it the first or the second, so you need to use specific values to find the index again? # Once we find the index, we can determine which value it is in the data set. # (Again, it is emphasized that the order of attribute values of features in data sets is consistent with that of features in label vectors.) # dataSet = [[1, 1, 'yes']] # labels = ['no surfacing', 'flippers'] # So the computer knows which prediction value to look for as the current node in the test data set you put in. # We also use this index to find out whether the predicted value given by the node at the test list is 0 or 1. # 0 is equivalent to looking for no prediction value. 1 is proof that it needs to be judged or yes prediction value. valueOfFeat = secondDict[key] if isinstance(valueOfFeat, dict): # Judging that instance functions are similar to type functions, but this is better classLabel = classify(valueOfFeat, featLabels, testVec) else: classLabel = valueOfFeat return classLabel def retrieveTree(i): listOfTrees = [{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}, {'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}} ] return listOfTrees[i] def createDataSet(): dataSet = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] labels = ['no surfacing', 'flippers'] # [Is it possible to float out of the water and have webbed feet?] return dataSet, labels
implement
if __name__ == '__main__': data, label = createDataSet() myTree = retrieveTree(0) result = classify(myTree, label,[1,1]) if result == 'yes': print("The sample is predicted to be fish.") else: print("The sample prediction is not fish.") # The sample predicts fish.
Then we found that the predicted results were right when we combined the decision tree itself. We could change the unknown data and test it by ourselves.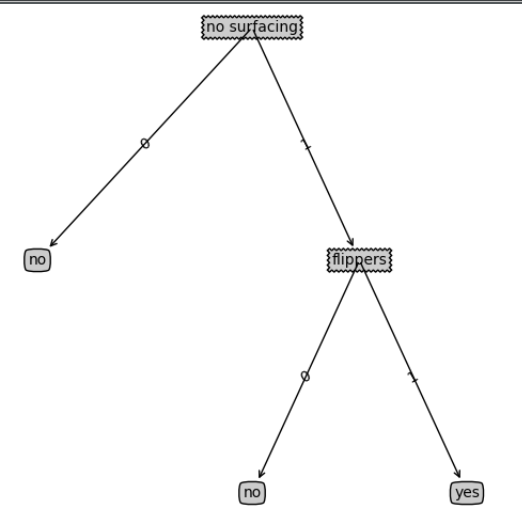
Decision Tree: Tree Storage
It can be stored as an advantage of decision tree. Comparing with the previous k-nearest neighbor learning, the classifier can only create and predict data each time.
"""
Function description:
Storage Tree
Parameters:
inputTree: Decision Tree
fiename: Suffix the full filename
Rertun:
None
"""
def storeTree(inputTree, filename):
# fw = open(filename,'w')
# pickle.dump(inputTree, fw)
# TypeError: write() argument must be str, not bytes
# Cause: After the update of Python 3, the open function adds a new parameter named encoding, and the default value of the new parameter is `utf-8'.
# In this way, when read and write operations are performed on file handles, the system requires developers to pass in instances containing Unicode characters.
# Instead of accepting bytes instances containing binary data.
# Solutions:
# Use binary write mode ('wb') to open the file to be manipulated, instead of character write mode ('w'), as it used to be.
# In addition, the following way is relatively new.
with open(filename, 'wb')as fw:
pickle.dump(inputTree, fw)
"""
Function description:
Load Tree
Parameters:
fiename: File name
Rertun:
Extracted Decision Tree
"""
def grabTree(filename):
# There are similar problems when files read data.
# The solution to this problem is similar: open files in'rb'mode (binary mode), rather than in'r' mode.
with open(filename, "rb") as fr:
return pickle.load(fr)
implement
if __name__ == '__main__': data, label = createDataSet() myTree = retrieveTree(0) storeTree(myTree, 'myTree.txt') myTree = grabTree('myTree.txt') print(myTree) # {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
summary
This section focuses on the establishment of the attribute values of unknown samples. Understanding partners can write the data set out and look at it. Remember that the corresponding order of the tag vectors and the attribute values in the data set is the same. Just run through the logic again. In the next section, we will synthesize what we have learnt before to carry out a new case practice. Before that, we suggest that we should pass on the previous content to deepen our impression.