1. Introduction
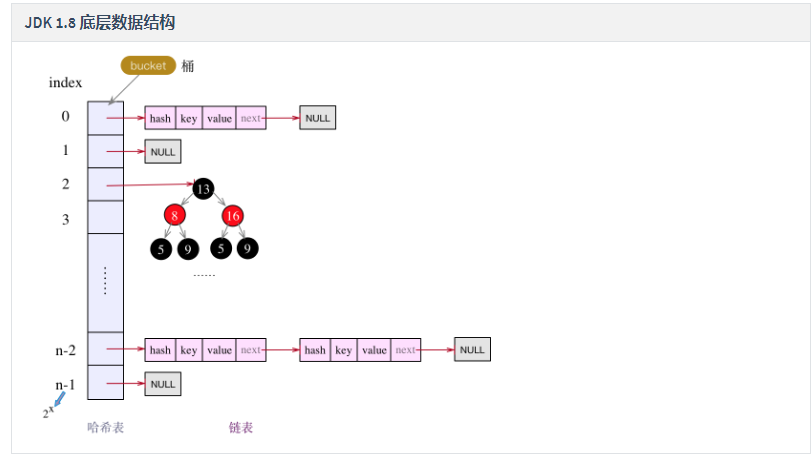
① JDK1. Before 8, HashMap was composed of array + linked list. Array is the main body of HashMap, and linked list mainly exists to solve Hash conflict. When an element is put into the set, the Hash value of key, namely hash(key), will be calculated, Then perform bitwise sum operation with the size of the array to calculate a bucket subscript (index). Put the key into the bucket subscript index corresponding to the array, and scatter the key under different bucket subscripts as much as possible, which can make the search faster, and the time complexity is O(1), However, different keys may calculate the same bucket subscript (index). At this time, you need to find the key through the equals() method. Although the search performance will be lost, the bucket subscript conflict can be solved.

The concurrency problem of the dead chain will occur during capacity expansion. With more and more elements in the array, the length of the linked list will inevitably become longer and longer, and the search performance will be affected. Both jdk7 and jdk8 will expand when the array length exceeds a threshold, This threshold is three quarters (12) of the length of the array. The capacity expansion method will recalculate the bucket subscript to double the capacity.
② JDK1. After 8, there are great changes in resolving hash conflicts. When the length of the linked list is greater than the threshold (or the boundary value of the red black tree, which is 8 by default) and the length of the current array is greater than 64, all data at this index position is stored in the red black tree instead.
Hash conflict: two different key s calculate the same bucket index through the hash function
Add: it will be judged before converting the linked list into a red black tree. Even if the threshold is greater than 8, but the array length is less than 64, the linked list will not become a red black tree at this time. Instead, you choose to expand the array. The purpose of this is to avoid the red black tree structure as much as possible because the array is relatively small. In this case, changing to the red black tree structure will reduce the efficiency, because the red black tree needs left-hand rotation, right-hand rotation and color change to maintain balance. At the same time, when the array length is less than 64, the search time is relatively faster. To sum up, in order to improve performance and reduce search time, the linked list is converted to a red black tree when the threshold is greater than 8 and the array length is greater than 64. For details, please refer to treeifyBin method.
Of course, although the red black tree is added as the underlying data structure, the structure becomes complex, but when the threshold is greater than 8 and the array length is greater than 64, the efficiency becomes more efficient when the linked list is converted to red black tree.
③ Summary:
(1) Access disordered
(2) Both key and value positions can be null, but the key position can only be null
(3) The key position is unique, and the underlying data structure controls the key position
(4) The data structure before jdk1.8 is: linked list + array; after jdk1.8 is: linked list + array + red black tree
(5) Only when the threshold (boundary value) > 8 and the array length is greater than 64 can the linked list be converted into a red black tree. The purpose of changing into a red black tree is to query efficiently.
(6) The implementation of HashMap is not synchronous, which means that it is not thread safe.
2. Properties
/** * Default initial capacity - must be a power of 2 */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 /** * The maximum capacity is the 30th power of 2 - it must be the power of 2 */ static final int MAXIMUM_CAPACITY = 1 << 30; /** * The default load factor is used when it is not specified in the constructor */ static final float DEFAULT_LOAD_FACTOR = 0.75f; /** * When the number of elements in a bucket is greater than or equal to 8, the linked list is transformed into a red black tree */ static final int TREEIFY_THRESHOLD = 8; /** * When the number of elements in a bucket is less than or equal to 6, the red black tree is transformed into a linked list */ static final int UNTREEIFY_THRESHOLD = 6; /** * When the length of the linked list is greater than 8 and the length of the array is greater than 64, the linked list is transformed into a red black tree */ static final int MIN_TREEIFY_CAPACITY = 64; /** * Array, also known as bucket */ transient HashMap.Node<K,V>[] table; /** * Cache as entrySet() */ transient Set<Map.Entry<K,V>> entrySet; /** * Number of elements */ transient int size; /** * Modification times, which is used to execute the quick failure strategy during iteration */ transient int modCount; /** * Expand the capacity when the number of buckets reaches, threshold = capacity * loadFactor */ int threshold; /** * Load factor */ final float loadFactor;
- Capacity: refers to the length of the array, that is, the number of buckets. The default is 16, and the maximum is the 30th power of 2. When the capacity reaches 64, the linked list can be transformed into a red black tree
- Load factor: used to calculate the capacity expansion when the capacity reaches. The default load factor is 0.75.
- Tree: tree when the capacity is greater than 64 and the length of the linked list is greater than 8. When the length of the linked list is less than 6, turn the red black tree into a linked list.
3. Single linked list Node class
Node is a typical single linked list node, in which hash is used to store the hash value calculated by key.
/**
* Node Is a typical single linked list node, where hash is used to store the hash value calculated by key.
* @param <K> key
* @param <V> value
*/
static class Node<K, V> implements Entry<K, V> {
final int hash;
final K key;
V value;
HashMap.Node<K, V> next;
Node(int hash, K key, V value, HashMap.Node<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
4. Red black tree node class
TreeNode is a typical tree node. prev is a node in the linked list. It is used to quickly find its front node when deleting an element.
static final class TreeNode<K, V> extends java.util.LinkedHashMap.Entry<K, V> {
HashMap.TreeNode<K, V> parent;
HashMap.TreeNode<K, V> left;
HashMap.TreeNode<K, V> right;
HashMap.TreeNode<K, V> prev;
boolean red;
TreeNode(int hash, K key, V val, HashMap.Node<K, V> next) {
super(hash, key, val, next);
}
}
5. Constructor
5.1 HashMap()
Null parameter construction method, all using default values.
/**
* Default constructor: the default initial capacity is 16, and the default load factor is 0.75
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
5.2 HashMap(int initialCapacity)
/**
* Constructor for specifying initial capacity: use the specified initialCapacity, and the default load factor is 0.75
*
* @param initialCapacity Initial capacity
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
5.3 HashMap(int initialCapacity, float loadFactor)
/**
* Constructor for specifying initial capacity and load factor: use the specified initialCapacity and the specified loadFactor
*
* @param initialCapacity Initial capacity
* @param loadFactor Load factor
*/
public HashMap(int initialCapacity, float loadFactor) {
// Check whether the incoming initial capacity is legal
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// If the incoming initial capacity is greater than the maximum capacity, set the initial capacity to the maximum capacity_ Capability -- > the 30th power of 2
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// Check whether the loading factor is legal
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
/*
tableSizeFor(initialCapacity) Judge whether the specified initialization capacity is the nth power of 2. If not, it will become the smallest nth power of 2 greater than the specified initialization capacity.
Note, however, that in the tableSizeFor method body, the calculated data is returned to the call and directly assigned to the threshold boundary value. Some people will think that this is a bug and should be written as follows:
this.threshold = tableSizeFor(initialCapacity) * this.loadFactor;
Only in this way can it meet the meaning of threshold (the capacity will be expanded when the size of HashMap reaches the threshold).
However, please note that in the construction methods after jdk8, the member variable table is not initialized. The initialization of table is postponed to the put method, where the threshold will be recalculated
*/
this.threshold = tableSizeFor(initialCapacity);
}
/**
* Returns the n-th power of the smallest 2 larger than the specified initialization capacity
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
6. Calculate the hash value of the key
/**
* Calculate the hash value of the key. In order to use the low and high information at the same time, move the unsigned right 16 bits and perform XOR operation.
* Step 1: calculate the hashCode of the key, return the hash value, and assume a randomly generated value.
* Step 2: set H ^ (H > > > 16)
* The 16 bit hash value is calculated by mixing the high 16 bit and low 16 bit, and the hash value is calculated by making full use of all information to reduce hash conflict
*
* @param key key
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
7. Add the element put(K key, V value)
/**
* Add elements to the collection
* @param key key
* @param value value
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash key hash of
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
// Represents an array that stores elements in a Map collection
HashMap.Node<K,V>[] tab;
// Define a linked list node variable
HashMap.Node<K,V> p;
int n;
int i;
// If tab==null, the number of buckets is 0. Initialize the tab array
if ((tab = table) == null || (n = tab.length) == 0){
n = (tab = resize()).length;
}
// I = (n - 1) & hash: calculates which bucket the element should be added to
// If there is no element in the bucket, put the element in the first position in the bucket
if ((p = tab[i = (n - 1) & hash]) == null) {
// Construct this element (key,value) as a Node node and add it to the first position of the bucket
tab[i] = newNode(hash, key, value, null);
} else {
// If an element already exists in this bucket
HashMap.Node<K,V> e;
K k;
/**
* If the key of the first element in the bucket is the same as that of the element to be inserted, save it to e for subsequent modification of the value value
* 1,p.hash == hash: Compare whether the hash value of the element in the bucket is equal to the hash value of the newly added element key
* 2,p.key == key: Compare whether the address values of two key s are equal (call = =, compare the address values)
* 3,key != null && key.equals(p.key) : Judge whether the contents of two key s are equal (call equals to compare the contents)
*/
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))){
e = p;
} else if (p instanceof HashMap.TreeNode){
// If the first element is a tree node, the putTreeVal of the tree node is called to insert the element
e = (( HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
} else {
// Otherwise, the first element is the linked list node, traverse the linked list in the bucket, and then add the node to the linked list
// binCount is used to store the number of elements in the linked list
for (int binCount = 0; ; ++binCount) {
// If no element with the same key is found after traversing the linked list, it indicates that the element corresponding to the key does not exist, and a new node is inserted at the end of the linked list
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// If the length of the linked list after inserting a new node is greater than 8, judge whether it needs to be transformed into a red black tree. Because the first element is not added to binCount, it is tree here_ THRESHOLD - 1
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// If the key to be inserted is found in the linked list, exit the loop
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))){
break;
}
p = e;
}
}
// If the element corresponding to the key is found
if (e != null) { // existing mapping for key
// Record the old value
V oldValue = e.value;
// Determine whether the old value needs to be replaced
if (!onlyIfAbsent || oldValue == null){
e.value = value;
}
afterNodeAccess(e);
// Return old value
return oldValue;
}
}
// That's it. No element found
// Element not found, change times plus 1
++modCount;
// Add 1 to the number of elements to determine whether expansion is required
if (++size > threshold){
resize();
}
afterNodeInsertion(evict);
// Element not found returned null
return null;
}
-
Calculate the hash value of the key;
-
If the number of buckets (array) is 0, initialize the bucket;
-
If there is no element in the bucket where the key is located, insert it directly;
-
If the key of the first element in the bucket where the key is located is the same as the key to be inserted, it means that the element is found and transferred to the subsequent process (8) to determine whether the old value needs to be replaced and directly return the old value;
-
If the first element is a tree node, call putTreeVal() of the tree node to find the element or insert the tree node;
-
If not, traverse the linked list corresponding to the bucket to find out whether the key exists in the linked list;
-
If the element corresponding to the key is not found, insert a new node at the end of the linked list and judge whether it needs to be trealized;
-
If the element corresponding to the key is found, judge whether to replace the old value and directly return the old value;
-
If an element is inserted, add 1 to the quantity and judge whether expansion is required;
8. Capacity expansion (resize)
When the number of elements in the HashMap exceeds the array size * loadFactor, the array will be expanded. The default value of loadFactor is 0.75, which is a compromise value. That is, by default, the array size is 16, so when the number of elements in the HashMap exceeds 16 × When 0.75 = 12 (this value is the threshold or boundary value threshold value), the size of the array is expanded to 2 × 16 = 32, that is, double the size, and then recalculate the position of each element in the array, which is a very performance consuming operation. Therefore, if we have predicted the number of elements in the HashMap, predicting the number of elements can effectively improve the performance of the HashMap.
When the number of objects in one of the linked lists in the HashMap reaches 8, if the array length does not reach 64, the HashMap will be expanded first. If it reaches 64, the linked list will become a red black tree and the Node type will change from Node to TreeNode. Of course, if the number of nodes in the tree is lower than 6 when the resize method is executed next time after the mapping relationship is removed, the tree will also be converted into a linked list.
Capacity expansion will be accompanied by a re hash allocation, and all elements in the hash table will be traversed, which is very time-consuming. When writing programs, try to avoid resize.
The rehash method used by HashMap during capacity expansion is very ingenious, because each capacity expansion is doubled. Compared with the original calculated (n-1) & hash result, there is only one bit more, so the node is either in the original position or assigned to the position of "original position + old capacity".
How to understand? For example, when we expand from 16 to 32, the specific changes are as follows:
After the element recalculates the hash, because n becomes twice, the marking range of n-1 is 1 bit more in the high order (red), so the new index will change like this:
final HashMap.Node<K,V>[] resize() {
// Get the current array
HashMap.Node<K,V>[] oldTab = table;
// Old capacity: the capacity of the current array
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// Old capacity expansion threshold (threshold): the default is 12 (16 * 0.75)
int oldThr = threshold;
int newCap, newThr = 0;
/**
* 1,If array capacity > 0
* 2,If the array capacity = 0, the capacity expansion threshold oldthr > 0: for the map created by the parameterized construction method, the first inserted element will go here
* 3,If the array capacity = 0 and the capacity expansion threshold oldThr = 0: call the map created by the null parameter construction method, and the element will be inserted here for the first time
*/
if (oldCap > 0) {
// If the old capacity reaches the maximum capacity, it will not be expanded, so you have to collide with it
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
// If the old capacity does not exceed the maximum capacity and the old capacity is greater than the default initial capacity (16), the array capacity will be expanded to twice the original capacity, newCap = 16*2=32
} else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY){
// The expansion threshold has also been doubled
newThr = oldThr << 1; // double threshold
}
} else if (oldThr > 0) {
// Using the map created by the constructor with parameters, if the element is inserted here for the first time, the old threshold is assigned to the new capacity
newCap = oldThr;
} else {
// If the old capacity and the old capacity expansion threshold are all 0, it means that they have not been initialized
// For the map created with the null parameter constructor, the first insertion of the element will come here: use the default value directly
// The initialization capacity is the default capacity, and the expansion threshold is: (default capacity * default loading factor)
newCap = DEFAULT_INITIAL_CAPACITY; // 16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // 16*0.75=12
}
if (newThr == 0) {
// If the new capacity expansion threshold is 0, it is calculated as capacity * loading factor, but it cannot exceed the maximum capacity
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
// The capacity expansion threshold is newThr
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// Create a new capacity array with the size of newCap
HashMap.Node<K,V>[] newTab = (HashMap.Node<K,V>[])new HashMap.Node[newCap];
// Assign bucket to new array
table = newTab;
// Judge that the old array is not empty, traverse the old hash table, recalculate the new position of the elements in the bucket, and move each bucket to the new buckets
if (oldTab != null) {
// Traverse old array
for (int j = 0; j < oldCap; ++j) {
HashMap.Node<K,V> e;
// If the first element in the bucket is not empty, it is assigned to e
if ((e = oldTab[j]) != null) {
// Empty the old bucket for GC recycling
oldTab[j] = null;
if (e.next == null){
// If there is only one element in this bucket, calculate its position in the new bucket and move it to the new bucket
// Because the capacity is expanded twice every time, there must be no element in the new bucket when the first element here is moved to the new bucket
newTab[e.hash & (newCap - 1)] = e;
} else if (e instanceof HashMap.TreeNode){
// If the first element is a tree node, break up the tree into two trees and insert them into a new bucket
((HashMap.TreeNode<K,V>)e).split(this, newTab, j, oldCap);
} else { // preserve order
// If the linked list has more than one element and is not a tree
// It is divided into two linked lists and inserted into a new bucket
// For example, if the original capacity is 4, 3, 7, 11 and 15, these four elements are all in bucket 3
// Now when the capacity is expanded to 8, 3 and 11 are still in barrel 3, and 7 and 15 will be moved to barrel 7
// That is, it is divided into two linked lists
HashMap.Node<K,V> loHead = null, loTail = null;
HashMap.Node<K,V> hiHead = null, hiTail = null;
HashMap.Node<K,V> next;
do {
next = e.next;
// (e.hash & oldcap) = = 0 elements are placed in the low linked list
// For example, 3 & 4 = = 0
if ((e.hash & oldCap) == 0) {
if (loTail == null){
loHead = e;
} else{
loTail.next = e;
}
loTail = e;
} else {
// (e.hash & oldCap) != The element of 0 is placed in the high-order linked list
// For example, 7 & 4= 0
if (hiTail == null){
hiHead = e;
} else{
hiTail.next = e;
}
hiTail = e;
}
} while ((e = next) != null);
// The traversal is completed and divided into two linked lists
// The position of the low linked list in the new bucket is the same as that in the old bucket (i.e. 3 and 11 are still in bucket 3)
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// The position of the high-level linked list in the new bucket is exactly the original position plus the old capacity (that is, 7 and 15 have been moved to bucket 7)
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
-
If the null parameter construction method is used, it is initialized to the default value when the element is inserted for the first time, the capacity is 16, and the expansion threshold is 12;
-
If the construction method with parameters is used, the initialization capacity is equal to the expansion threshold when the element is inserted for the first time, and the expansion threshold is equal to the nth power of the nearest 2 upward of the incoming capacity in the construction method;
-
If the old capacity is greater than 0, the new capacity is equal to 2 times of the old capacity, but does not exceed the 30th power of the maximum capacity 2, and the new capacity expansion threshold is 2 times of the old capacity expansion threshold;
-
Create a new capacity bucket;
-
Moving elements, the original linked list is divided into two linked lists, the low-level linked list is stored in the position of the original bucket, and the high-level linked list is moved to the position of the original bucket plus the old capacity;
10. Convert linked list into red black tree treeifyBin()
final void treeifyBin(HashMap.Node<K,V>[] tab, int hash) {
int n, index;
HashMap.Node<K,V> e;
// If the number of barrels is less than 64, it can be expanded directly without converting to red black tree
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY){
resize();
// The execution here shows that the length of the array in the hash table is greater than the threshold 64, and the linked list is transformed into a red black tree
} else if ((e = tab[index = (n - 1) & hash]) != null) {
HashMap.TreeNode<K,V> hd = null, tl = null;
do {
// Replace all nodes with tree nodes
HashMap.TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
// Let the first element in the bucket, that is, the element in the array, point to the node of the new red black tree. In the future, the element in the bucket is the red black tree, not the linked list data structure
if ((tab[index] = hd) != null){
hd.treeify(tab);
}
}
}
11. Get the element get(Object key)
public V get(Object key) {
HashMap.Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final HashMap.Node<K,V> getNode(int hash, Object key) {
HashMap.Node<K,V>[] tab;
HashMap.Node<K,V> first, e;
int n; K k;
// If the number of buckets is greater than 0, and the first element of the bucket where the key to be found is located is not empty
if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) {
// always check first node
// Check whether the first element is the element to be checked. If it is, it will be returned directly
if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) {
return first;
}
if ((e = first.next) != null) {
// If the first element is a tree node, look it up as a tree
if (first instanceof HashMap.TreeNode)
return (( HashMap.TreeNode<K,V>)first).getTreeNode(hash, key);
// Otherwise, it will traverse the entire linked list to find the element
do {
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))){
return e;
}
} while ((e = e.next) != null);
}
}
return null;
}
-
Calculate the hash value of the key;
-
Find the bucket where the key is located and its first element;
-
If the key of the first element is equal to the key to be found, it is returned directly;
-
If the first element is a tree node, search by tree, otherwise search by linked list;
12. Relevant interview questions
1. Why not use the red black tree directly when resolving hash conflicts? And choose to use the linked list first, and then turn to the red black tree?
Because red and black trees need left-handed, right-handed and color changing operations to maintain balance, while single chain tables do not. When the number of elements is less than 8, the linked list structure can ensure the query performance. When there are more than 8 elements, the search time complexity of the red black tree is O(logn) and the linked list is O(n). At this time, the red black tree is needed to speed up the query, but the efficiency of adding new nodes slows down.
2. Why is the threshold of changing the linked list to red black tree 8?
Because of Poisson distribution, let's look at the author's comments in the source code:
0: 0.60653066 1: 0.30326533 2: 0.07581633 3: 0.01263606 4: 0.00157952 5: 0.00015795 6: 0.00001316 7: 0.00000094 8: 0.00000006 more: less than 1 in ten million
Ideally, the random hash code is used, and the frequency of nodes in the container distributed in the hash bucket follows the Poisson distribution. According to the calculation formula of Poisson distribution, the comparison table of the number of elements in the bucket and the probability is calculated. It can be seen that the probability is very small when the number of elements in the linked list is 8, and there are fewer when there are more, so the original author chose 8 when selecting the number of elements in the linked list, It is selected according to probability and statistics.
3. What is the default loading factor? Why 0.75, not 0.6 or 0.8?
int threshold; // Maximum value to accommodate key value pairs final float loadFactor; // Load factor int modCount; int size;
The initialization length of Node[] table is length (the default value is 16), the load factor is the load factor (the default value is 0.75), and the threshold is the maximum value of key value pairs that can be accommodated by HashMap. threshold = length * Load factor=12. In other words, after the length of the array is defined, the larger the load factor, the more key value pairs can be accommodated.
The default loadFactor is 0.75. 0.75 is a balanced choice for space and time efficiency. Generally, it should not be modified unless time and space are special:
- If there is a lot of memory space and time efficiency is required, the value of Load factor can be reduced.
- On the contrary, if memory space is tight and time efficiency is not required, you can increase the value of load factor, which can be greater than 1.
As a general rule, The default load factor (0.75) provides a good compromise between time and space costs. Higher values reduce space overhead but increase discovery costs (this is reflected in the operations of most HashMap classes, including get and put). When setting the initial size, the expected number of entries in the map and its load factor should be considered, and the number of rehash operations should be minimized. If the initial capacity is greater than the maximum number of entries divided by the load factor, the rehash operation will not occur.
4. How to calculate the storage index of key in HashMap?
First, calculate the value of hashcode according to the value of key, then calculate the hash value according to hashcode, and finally calculate the storage location through hash & (length-1).
5. How is the hash function implemented in HashMap? What are the implementation methods of hash functions?
key. The hashcode() function calls the hash function of the key value type and returns the int type hash value. Theoretically, the hash value is an int type. If you directly access the HashMap main array with the hash value as a subscript, consider that the binary 32-bit signed int table values range from * * - 2147483648 to 2147483648 * *. Add up to about 4 billion mapping space. As long as the hash function is mapped evenly and loosely, it is difficult to collide in general applications.
But the problem is that there is no memory for an array with a length of 4 billion. If you want, the initial size of the array before HashMap expansion is only 16. Therefore, the hash value cannot be used directly. Before using it, the length of the array must be modulo calculated, and the remainder can be used to access the array subscript. The range of the array subscript is [0,table.length]:
public int hash(Object key){
return key.hashCode() % table.length;
}
In order to improve the efficiency, we change the remainder operation% to & and operation, but the premise is that the length of the array is the power of 2:
public int hash(Object key){
return key.hashCode() & (table.length-1);
}
The reason for making the length of the array to the power of 2 is to & operate the hash value of the key with all 1 (the length of the array - 1 is exactly equivalent to a "low mask"), and the result must be less than the length of the array:
1 2^1-1 11 2^2-1 111 2^3-1 1111 2^4-1
&The result of the operation is that all the high bits of the hash value return to zero, and only the low bits are reserved for array subscript access. Take the initial length 16 as an ex amp le, 16-1 = 15. Binary means 00000000 00000000 00001111. Do & the following with a hash value, and the result is to intercept the lowest four digit value. It can be seen that we only use the low order information of the hash value when calculating the index through the hash value:
10100101 11000100 00100101
& 00000000 00000000 00001111
----------------------------------
00000000 00000000 00000101 //All high bits are zeroed, and only the last four bits are retained
In order to make full use of all the information of hash value, that is, both low-order information and high-order information are used, > > > and ^:
h 1011 0110 0011 1001 0110 1111 1100 1010 key of hash value
h >>>16 0000 0000 0000 0000 1011 0110 0011 1001 key of hash Value unsigned right shift 16 bits
-----------------------------------------------------------------------------------
^ 1011 0110 0011 1001 1101 1001 1111 0011 XOR both^operation
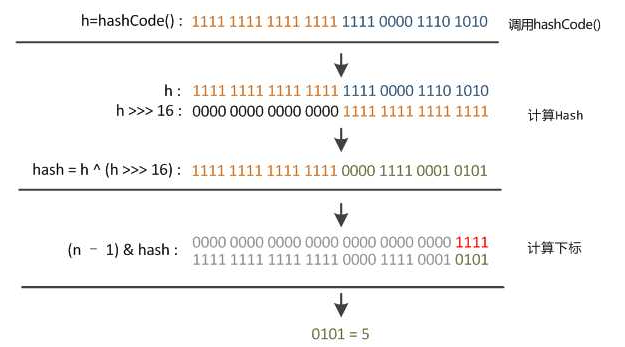
The right shift is 16 bits, which is exactly half of 32bit. The purpose of XOR in its high half region and low half region is to mix the high and low bits of the original hash code, so as to increase the randomness of the low bits. Moreover, the mixed low-level is doped with some characteristics of the high-level, so that the high-level information is retained in disguise.
Therefore, a good hash function can make the hash values more evenly distributed, reduce the number of hash conflicts, and improve the performance of the hash table. Otherwise, data may never be inserted in some positions of the array, wasting array space and increasing hash conflicts.
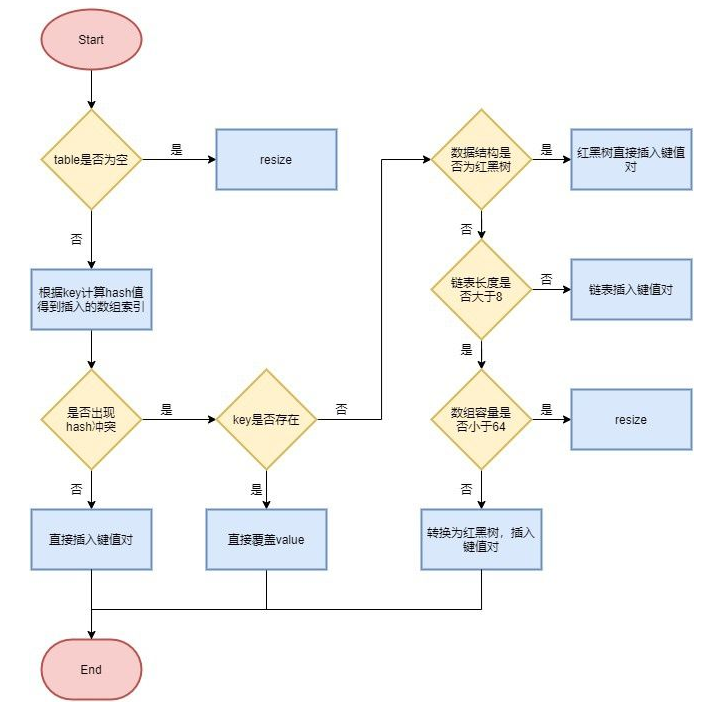
6. put method flow of HashMap
- First, calculate the hash value according to the value of the key, and find the subscript of the element stored in the array;
- If the array is empty, call resize to initialize;
- If there is no hash conflict, it is directly placed in the corresponding array subscript;
- If there is a conflict and the key already exists, overwrite the value;
- If the node is found to be a red black tree after the conflict, hang the node on the tree;
- If there is a linked list after the conflict, judge whether the linked list is greater than 8. If it is greater than 8 and the array capacity is less than 64, expand the capacity; If the linked list node is greater than 8 and the capacity of the array is greater than 64, the structure is converted into a red black tree; Otherwise, the linked list inserts a key value pair. If the key exists, the value will be overwritten.
7. JDK1. What is the difference between the put method of 7 and 1.8?
When inserting elements into the linked list, jdk1 7. Inserting elements with header insertion method may lead to the emergence of ring linked list in multi-threaded environment, and dead loop will be caused during capacity expansion. Therefore, jdk1 8. Insert elements with tail interpolation method, and the original order of linked list elements will be maintained during capacity expansion, so there will be no problem of linked list forming a ring, but jdk1 The HashMap of 8 is still thread unsafe. The specific reasons will be analyzed in another article.
8. How to expand HashMap?
After the capacity of Hashmap exceeds the capacity defined by the load factor, it will expand. Arrays in Java cannot be expanded automatically. The method is to expand the size of Hashmap to twice the original array and put the original objects into a new array.
9. Expansion at jdk1 What's different in 8?
-
After resize, the position of the element is in the original position, Or the original position + oldCap (the length of the original hash table). There is no need to recalculate the hash like the implementation of JDK1.7. Just look at whether the new bit of the original hash value is 1 or 0. If it is 0, the index remains unchanged, and if it is 1, the index becomes "original index + oldCap". This design is very clever and saves the time of recalculating the hash value.
-
JDK1. When rehash in 7, when the old linked list is migrated to the new linked list, if the array index position of the new list is the same, the linked list elements will be inverted (head interpolation). JDK1.8 will not be inverted, but tail interpolation is used.
10. What other hash algorithms do you know?
Hash function refers to mapping a large range to a small range. The purpose is often to save space and make the data easy to save. MurmurHash, MD4, MD5 and so on are more famous.
11. Disadvantages of traditional hashMap, 1.8 why introduce red black tree?
The implementation of HashMap before JDK 1.8 is array + linked list. Even if the hash function is better, it is difficult to achieve 100% uniform distribution of elements. When a large number of elements in the HashMap are stored in the same bucket, there is a long linked list under the bucket. At this time, HashMap is equivalent to a single linked list. If the single linked list has n elements, the traversal time complexity is O(n), which completely loses its advantage. To solve this problem, JDK 1.8 introduces a red black tree (the search time complexity is O(logn)) to optimize this problem. When the length of the linked list is very small, the traversal speed is very fast, but when the length of the linked list continues to grow, it will certainly have a certain impact on the query performance, so it needs to be transformed into a tree.
12. How is the hash function implemented in HashMap?
For the hashCode of the key, perform the hash operation, move the unsigned right 16 bits, and then perform the XOR operation. There are also square middle method, pseudo-random number method and remainder method. These three kinds of efficiency are relatively low. The operation efficiency of unsigned right shift 16 bit XOR is the highest.
13. What happens when the hashcodes of two objects are equal?
Hash collision will occur. If the key value content is the same, replace the old value Otherwise, if it is connected to the back of the linked list and the length of the linked list exceeds the threshold 8, it will be converted to red black tree storage.
14. When and what is hash collision, and how to solve hash collision?
As long as the hash code value calculated by the key of two elements is the same, hash collision will occur. Use linked list to solve hash collision before jdk8. Jdk8 then uses linked list + red black tree to solve hash collision.
15. If the hashcode s of two keys are the same, how to store key value pairs?
Hashcode is the same. Compare whether the contents are the same through equals. If the hashcode is the same, the new value overwrites the previous value. If the hashcodes are different, a new key value pair is added to the hash table.