Pointer type
Before formally introducing the unsafe package, we need to focus on the pointer types in the Go language.
When I started learning programming as an undergraduate, my first language was c. After that, I learned C + +, Java and Python. These languages are very powerful, but they are not as "simple" as C language. Until I began to contact Go language, I found that feeling again. Ken Thompson, one of the authors of Go language, is also the author of C language. Therefore, Go can be regarded as a C language. Many of its features are similar to C, and pointer is one of them.
However, the pointer of Go language has many limitations compared with the pointer of C. Of course, this is for the sake of security. You should know that in modern languages such as Java/Python, for fear of programmers making mistakes, what pointers (here refers to explicit pointers)? Not to mention that programmers need to clean up "garbage" like C/C + +. So it's good for Go to have pointers, even though it has many limitations.
Why do I need a pointer type? An example is given in reference go101.org:
package main
import "fmt"
func double(x int) {
x += x
}
func main() {
var a = 3
double(a)
fmt.Println(a) //3
}
Very simple. I want to double a in the double function, but the function in the example can't. Why? Because the function parameters of Go language are passed by value. x in the double function is only a copy of argument a. the operation on x inside the function cannot be fed back to argument a.
If you have a pointer at this time, you can solve the problem! This is also our common "trick".
package main
import "fmt"
func double(x *int) {
*x += *x
x = nil
}
func main() {
var a = 3
double(&a)
fmt.Println(a) //6
p := &a
double(p)
fmt.Println(a, p == nil) //12 false
}
Very routine operation, no need to explain. The only possible doubt is in this sentence:
x = nil
It takes a little thought to come to the conclusion that this line of code has no impact at all. Because it is value passing, x is only a copy of & A.
*x += *x
This sentence changes the value pointed to by X (that is, the value pointed to by & A, that is, variable a) to twice the original value. However, the operation of X itself (a pointer) will not affect the a of the outer layer, so x=nil can't lift any big waves.
The following picture can "prove your innocence":

However, compared with the flexibility of pointers in C language, Go pointers have some more limitations. But this is also the success of Go: it can not only enjoy the convenience brought by the pointer, but also avoid the danger of the pointer.
Limitation 1: the pointer of Go cannot perform mathematical operations.
a := 5 p := &a p++ p = &a + 3
The above code cannot be compiled, and a compilation error will be reported: invalid operation, that is, mathematical operations cannot be performed on the pointer.
Limitation 2: pointers of different types cannot be converted to each other.
For example, the following is a short example:
Let's take a simple example:
func main() {
a := int(100)
var f *float64
f = &a
}
Compilation errors will also be reported: cannot use &a (type * int) as type * float64 in assignment
Whether the two pointers can be converted to each other is very detailed in the go 101 related articles in resources. I don't want to expand here. Personally, I don't think it's meaningful to remember these. Students with perfectionism can read the original text. Of course, I also have perfectionism, but I sometimes restrain, hehe.
Restriction 3: different types of pointers cannot use = = or= Compare.
You can compare two pointers only if they are of the same type or can be converted to each other. In addition, the pointer can be through = = and= Compare directly with nil.
Limit 4: pointer variables of different types cannot be assigned to each other.
This is the same as limit 3.
What is unsafe
The pointer mentioned above is type safe, but it has many limitations. Go also has a non type safe pointer, which is the unsafe.Pointer provided by the unsafe package. In some cases, it makes the code more efficient and, of course, more dangerous.
The unsafe package is used for the Go compiler and is used during the compilation phase. As can be seen from the name, it is unsafe and is not recommended by the official. I feel uncomfortable when using the unsafe package. Maybe this is also the intention of the language designer.
But how can high-level Gopher not use the unsafe package? It can bypass the type system of Go language and directly operate memory. For example, generally, we can't operate on the non exported members of a structure, but we can do it through the unsafe package. The unsafe package allows me to read and write memory directly, regardless of whether you export it or not.
Why is there unsafe
Go language type system is designed for security and efficiency. Sometimes, security will lead to inefficiency. With the unsafe package, advanced programmers can use it to bypass the inefficiencies of the type system. Therefore, it has the meaning of existence. Reading the go source code, you will find a large number of examples of using the unsafe package.
Implementation principle of unsafe
Let's look at the source code:
type ArbitraryType int type Pointer *ArbitraryType
In terms of naming, Arbitrary means Arbitrary, that is, Pointer can point to any type. In fact, it is similar to void * in C language.
The unsafe package also has three other functions:
func Sizeof(x ArbitraryType) uintptr func Offsetof(x ArbitraryType) uintptr func Alignof(x ArbitraryType) uintptr
Sizeof returns the number of bytes occupied by type x, but does not contain the size of the content pointed to by x. For example, for a pointer, the size returned by the function is 8 bytes (on 64 bit machines), and the size of a slice is the size of the slice header.
Offsetof returns the number of bytes from the position of the structure member in memory to the beginning of the structure. The passed parameter must be a member of the structure.
Alignof returns m, which means that when the type is memory aligned, the memory address it allocates can be divided by M.
Note that the results returned by the above three functions are of uintptr type, which can be converted to unsafe.Pointer. All three functions are executed during compilation, and their results can be directly assigned to const variables. In addition, because the results of the three functions are related to the operating system and compiler, they are not portable.
To sum up, the unsafe package provides two important capabilities:
- Any type of pointer and unsafe.Pointer can be converted to each other.
- The uintptr type and unsafe.Pointer can be converted to each other.

Pointer cannot perform mathematical operations directly, but it can be converted into uintptr, perform mathematical operations on uintptr type, and then convert it into pointer type.
// uintptr is an integer type that is large enough to store type uintptr uintptr
It should also be noted that uintptr has no pointer semantics, which means that the object pointed to by uintptr will be ruthlessly recycled by gc. unsafe.Pointer has pointer semantics, which can protect the object it points to from garbage collection when it is "useful".
Several functions in the unsafe package are executed during compilation. After all, the compiler "knows" about memory allocation. In the / usr/local/go/src/cmd/compile/internal/gc/unsafe.go path, you can see how Go handles the functions in the unsafe package during compilation.
The deeper principle needs to study the source code of the compiler, so I won't study it here. Let's focus on its usage and move on.
How to use unsafe
-
Get slice length
We know the structure definition of slice header:// runtime/slice.go type slice struct { array unsafe.Pointer // Element pointer len int // length cap int // capacity }Call the make function to create a slice. The bottom layer calls the makeslice function and returns the slice structure:
unc makeslice(et *_type, len, cap int) slice
Therefore, we can convert unsafe.Pointer and uintptr to get the slice field value.
func main() { s := make([]int, 9, 20) var Len = *(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + uintptr(8))) fmt.Println(Len, len(s)) // 9 9 var Cap = *(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + uintptr(16))) fmt.Println(Cap, cap(s)) // 20 20 }The conversion process of Len and cap is as follows:
Len: &s => pointer => uintptr => pointer => *int =>int Cap: &s => pointer => uintptr => pointer => *int =>int
-
Get map length
The structure of the map is as followstype hmap struct { count int flags uint8 B uint8 noverflow uint16 hash0 uint32 buckets unsafe.Pointer oldbuckets unsafe.Pointer nevacuate uintptr extra *mapextra }Unlike slice, the makemap function returns a pointer to the hmap. Note that the pointer:
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap
We can still convert through unsafe.Pointer and uintpr to get the value of hamp field, but now count becomes a secondary pointer:
func main() { mp := make(map[string]int) mp["qcrao"] = 100 mp["stefno"] = 18 count := **(**int)(unsafe.Pointer(&mp)) fmt.Println(count, len(mp)) // 2 2 }Conversion process of count:
&mp => pointer => **int =>int
-
Application of map in source code
In the map source code, in the mapacess1, mapassign and mapdelete functions, you need to locate the location of the key, and you will hash the key first.
For example:b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))
h.buckets is an unsafe.Pointer. Convert it into uintptr, and then add (hash & M) * uintptr (t.bucketsize). The result of the addition of the two is converted into unsafe.Pointer again. Finally, convert it into bmap pointer to get the bucket position where the key falls. If you are not familiar with this formula, you can look at the previous article, which is easy to understand.
The above example is relatively simple. Let's take a more difficult example of assignment:
if t.indirectkey { kmem := newobject(t.key) *(*unsafe.Pointer)(insertk) = kmem insertk = kmem } if t.indirectvalue { vmem := newobject(t.elem) *(*unsafe.Pointer)(val) = vmem } typedmemmove(t.key, insertk, key)This code performs the "assignment" operation after finding the location where the key is to be inserted. Insertk and val respectively represent the addresses where key and value are to be "placed". If t.indirectkey is true, it means that the bucket stores a pointer to the key. Therefore, insertk needs to be regarded as a pointer to the pointer. In this way, the value at the corresponding position in the bucket can be set to the address value pointing to the real key, that is, the key stores a pointer.
The following figure shows all operations of setting key:
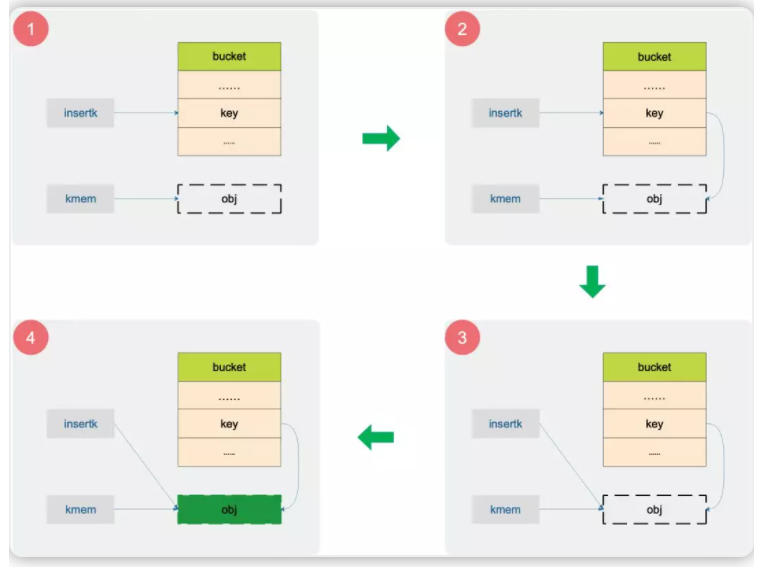
Obj is where real key s are stored. In Figure 4, obj indicates that the typedmemove function is successfully assigned after execution. -
Offsetof gets the member offset
For a structure, the offset of the structure member can be obtained through the offset function, and then the address of the member can be obtained. The purpose of changing the member value can be achieved by reading and writing the memory of the address.Here is a memory allocation related fact: the structure will be allocated a continuous piece of memory, and the address of the structure also represents the address of the first member.
Let's take an example:package main import ( "fmt" "unsafe" ) type Programmer struct { name string language string } func main() { p := Programmer{"stefno", "go"} fmt.Println(p) name := (*string)(unsafe.Pointer(&p)) *name = "qcrao" lang := (*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&p)) + unsafe.Offsetof(p.language))) *lang = "Golang" fmt.Println(p) }The operation results are as follows
{stefno go} {qcrao Golang}name is the first member of the structure, so you can directly resolve & P to * string. The same principle is used to obtain the count member of the map.
For the private member of the structure, there is now a way to change its value through unsafe.Pointer.
I upgraded the Programmer structure and added an additional field:
type Programmer struct { name string age int language string }And put it in other packages, so that in the main function, its three fields are private member variables and cannot be modified directly. But I can get the size of the member through the unsafe.Sizeof() function, then calculate the address of the member and modify the memory directly.
func main() { p := Programmer{"stefno", 18,"go"} fmt.Println(p) lang := (*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&p)) + unsafe.Sizeof(0)+unsafe.Sizeof(""))) *lang = "Golang" fmt.Println(p) }Output:
{stefno 18 go} {stefno 18 Golang} -
Conversion between string and slice
This is a very classic example. To realize the conversion between string and bytes slice, it is required to be zero copy. Think about it. In general, you need to traverse strings or bytes slices, and then assign values one by one.To complete this task, we need to understand the underlying data structures of slice and string:

The above is the structure under the reflection package. The path is src/reflect/value.go. You only need to share the underlying [] byte array to implement zero copy.package main import ( "fmt" "reflect" "unsafe" ) func string2bytes(s string) []byte { stringHeader := (*reflect.StringHeader)(unsafe.Pointer(&s)) bh := reflect.SliceHeader{ Data: stringHeader.Data, Len: stringHeader.Len, Cap: stringHeader.Len, } return *(*[]byte)(unsafe.Pointer(&bh)) } func bytes2string(b []byte) string { sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&b)) sh := reflect.StringHeader{ Data: sliceHeader.Data, Len: sliceHeader.Len, } return *(*string)(unsafe.Pointer(&sh)) } func main() { testStringConvertBytes := "this is a string" fmt.Println(string2bytes(testStringConvertBytes), []byte(testStringConvertBytes)) // [116 104 105 115 32 105 115 32 97 32 115 116 114 105 110 103] [116 104 105 115 32 105 115 32 97 32 115 116 114 105 110 103] testBytesConvertString := []byte("this is a bytes") fmt.Println(bytes2string(testBytesConvertString), string(testBytesConvertString)) //this is a bytes this is a bytes }
summary
The unsafe package bypasses the Go type system and achieves the purpose of directly operating memory. Using it has certain risks. However, in some scenarios, using the functions provided by the unsafe package will improve the efficiency of the code. The unsafe package is also widely used in the Go source code.
The unsafe package defines Pointer and three functions:
type ArbitraryType int type Pointer *ArbitraryType func Sizeof(x ArbitraryType) uintptr func Offsetof(x ArbitraryType) uintptr func Alignof(x ArbitraryType) uintptr
The size, offset, alignment and other information of variables can be obtained through three functions.
Uintptr can be converted with unsafe.Pointer, and uintptr can perform mathematical operations. In this way, the limitation that the Go pointer cannot perform mathematical operations is solved through the combination of uintptr and unsafe.Pointer.
Through the unsafe correlation function, you can obtain the address of the private member of the structure, and then do further reading and writing operations on it, breaking through the type security restriction of Go. For the unsafe package, we pay more attention to its usage.
By the way, after using too many unsafe packages, I don't think its name is so "ugly". On the contrary, I feel a little cool because I use something that the official does not advocate. This is the feeling of rebellion.
reference material
[original author's address] https://mp.weixin.qq.com/s/uTlzmsEg5OtbzObMbt3p0w
[Feixue ruthless blog] https://www.flysnow.org/2017/07/06/go-in-action-unsafe-pointer.html
[detailed explanation of unsafe package] https://gocn.vip/question/371
[official documents] https://golang.org/pkg/unsafe/
[example] http://www.opscoder.info/golang_unsafe.html
[fried fish boss's blog] https://segmentfault.com/a/1190000017389782
[go language Bible] https://www.kancloud.cn/wizardforcel/gopl-zh/106477
[pointer and system calls]https://blog.gopheracademy.com/advent-2017/unsafe-pointer-and-system-calls/
[pointer and uintptr]https://my.oschina.net/xinxingegeya/blog/729673
[unsafe.pointer]https://go101.org/article/unsafe.html
[go pointer type] https://go101.org/article/pointer.html
[code hole quickly learn Go language unsafe] https://juejin.im/post/5c189dce5188256b2e71e79b
[official documents] https://golang.org/pkg/unsafe/
[jasper's nest] http://www.opscoder.info/golang_unsafe.html