
Let's review the recent conference of LLVM developers. The whole tutorial is very suitable for people without LLVM foundation to get started and operate a piece of LLVM code.
Prerequisite
IR - > intermediate representation is the so-called intermediate representation. Generally speaking, the IR used by the compiler includes DAG, three address code (close to the target machine), CFG (control flow diagram), SSA (single static assignment) and CPS (more general SSA). Since each variable is only assigned once, SSA is easier to analyze the whole IR and other constant propagation. There are not many other IR forms here. If necessary, open the pit again.
File format:
1. bc bitcode 2. ll intermediate representation file
Useful tools:
1. The llvm dis disassembly tool converts bc files into ll files
2. Llvm as assembler converts ll file into bc file
3. Lang / Lang + + are the front-end parser s of LLVM, that is, compiler tools
4. Opt is used to check or optimize or convert IR files, e.g. opt --verify x.ll
Example
Prepare a small example first
// filename main.cpp
int main() {
return 0;
}
//clang -S -emit-llvm main.cpp
//You can see that the ir file main llOpen main Ll file
; ModuleID = 'main.cpp'
source_filename = "main.cpp"
target datalayout = "e-m:o-i64:64-i128:128-n32:64-S128"
target triple = "arm64-apple-macosx11.0.0"
; Function Attrs: noinline norecurse nounwind optnone ssp uwtable
define i32 @main() #0 {
%1 = alloca i32, align 4
store i32 0, i32* %1, align 4
ret i32 0
}
attributes #0 = { noinline norecurse nounwind optnone ssp uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="non-leaf" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "probe-stack"="__chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="apple-a12" "target-features"="+aes,+crc,+crypto,+fp-armv8,+fullfp16,+lse,+neon,+ras,+rcpc,+rdm,+sha2,+v8.3a,+zcm,+zcz" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.module.flags = !{!0, !1, !2}
!llvm.ident = !{!3}
!0 = !{i32 2, !"SDK Version", [2 x i32] [i32 11, i32 3]}
!1 = !{i32 1, !"wchar_size", i32 4}
!2 = !{i32 7, !"PIC Level", i32 2}
!3 = !{!"Apple clang version 12.0.5 (clang-1205.0.22.9)"}Explain the ir file annotation of llvm; Take the lead
In the target datalayout, e represents the small end, m:o represents the name mangling of elf (the recoding technology introduced to ensure the uniqueness of the name), i64:64 abi alignment byte. For the type of i64, the same is true for i128:128, n32:64 native integer and S128 stack space alignment
target triple = "arm64-apple-macosx11.0.0"
arm64 architecture, apple vendor, mac os x 11 0.0 system and abi, MAC from M1.
1. There are two naming conventions for LLVM IR,% number (% 1),% variable name (% name)
2. LLVM IR assumes infinite registers
3. LLVM IR is a typed language. Any statement will be typed, such as% 1 = alloca i32, align 4. Allocate a local variable of i32. In addition, this sentence is actually generated through the CreateAlloca function
4. LLVM IR does not allow any implicit conversion
bad example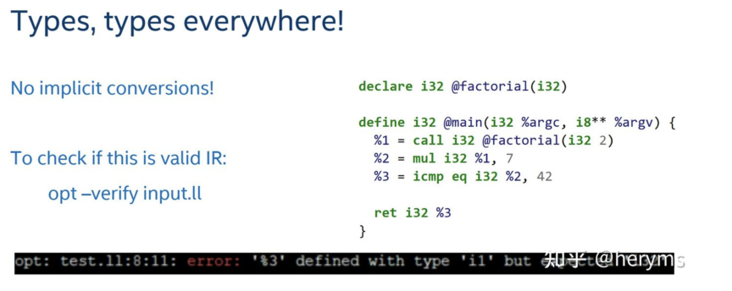
example
Finally, how to compile the ll file into an executable file
clang main.ll -o main ./main
LLVM IR BasicBlock

Fig 1.
We still explain it through Fig.1. The whole ll file is generated to calculate factorial. The basic explanation is to judge whether args is equal to 0. If yes, it will be returned as 1. If not, val will be subtracted by 1, and then recursive calculation will be carried out. Note that the block must have ret, and the block will be executed one by one if there is no jump
1. br
br is a branch, which is used to jump branches. Each label is equivalent to an alias of the whole block
ret
return
In order to facilitate the visualization of jump conditions, the conditions in SSA can also be converted into CFG through the command opt – analyze – dot CFG x.ll, as shown in Fig. 2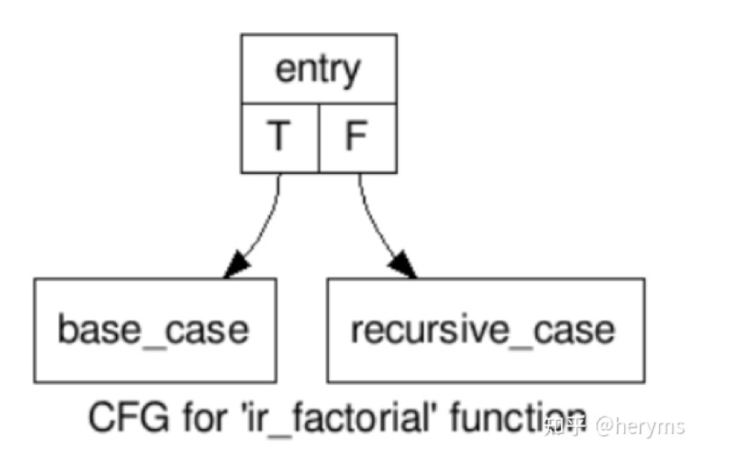
Fig2
Note that each function has a hidden label entry
LLVM PHI statement
PHI statement is the soul of LLVM
Why is there a PHI instruction in LLVM? Because the IR of LLVM is based on SSA last time, each variable can only be assigned once, so the PHI instruction is very easy to use to deal with some conditional jumps.
Let's take an example from phi_example above, thanks for the example provided. We still insert a simple piece of code.
// phi.cpp clang phi.cpp -emit-llvm -S -o phi.ll
void m(bool r, bool y){
bool l = y || r ;
}
// Theoretically, l has two results: 0 and 1. Of course, we can also use the following if in this code,
// But the generated ir file is different
// phi2.cpp
void m2(bool r, bool y){
bool l = false;
if (r)
l = true;
if (l)
l = true;
}After compiling, the ll file is obtained. After opening, it is roughly in the following form (attribute is omitted)
; Function Attrs: noinline nounwind optnone ssp uwtable
define void @_Z1mbb(i1 zeroext %0, i1 zeroext %1) #0 {
%3 = alloca i8, align 1
%4 = alloca i8, align 1
%5 = alloca i8, align 1
%6 = zext i1 %0 to i8
store i8 %6, i8* %3, align 1
%7 = zext i1 %1 to i8
store i8 %7, i8* %4, align 1
%8 = load i8, i8* %4, align 1
%9 = trunc i8 %8 to i1
br i1 %9, label %13, label %10
10: ; preds = %2
%11 = load i8, i8* %3, align 1
%12 = trunc i8 %11 to i1
br label %13
13: ; preds = %10, %2
%14 = phi i1 [ true, %2 ], [ %12, %10 ]
%15 = zext i1 %14 to i8
store i8 %15, i8* %5, align 1
ret void
}We can analyze the first sentence of Block%13, which is the LLVM Phi instruction
%14 = phi i1 [ true, %2 ], [ %12, %10 ]
Because we want to assign different values to% 14. In different cases, if the precursor node of% 14 comes from% 2 and is the entry function, it means that the value of r is true, then% 14 is true. If it comes from block% 10, it means that r is false. At this time, the value of% 14 is determined by the value of l, that is, the value of% 12 in IR.
In fact, the above description is very simple in high-level language, which is transformed into pseudo code
r = load arg1 l = load arg0 if l: %14 = true; else: if l: %14 = true; else: $14 = false; save %14 to %out
However, at this time, due to SSA,% 14 can only be assigned once, so the phi instruction is introduced. Simply put, it is to determine the current value according to the precursor block(preprocessor) of the current block.
phi instruction
Of course, the phi instruction is more useful. In this example, you can also rewrite it with if. Tutorial also introduces a case where the phi statement can ensure the update of variables. You can imagine how to update a variable according to conditions in the loop body of SSA. If you are interested, you can also taste it in the original tutorial. Finally, tutorial also provides some ways to cheat SSA, see godbolt_example
LLVM Type and GEP
Finally, tutorial introduces the type system of llvm in a more general way. In addition, it describes GEP, which is how to operate pointers in llvm. Note that GEP is not allowed to operate memory.

void m3(int* a){
int s = a[0];
}
// ir file
define void @_Z2m3Pi(i32* %0) #0 {
%2 = alloca i32*, align 8
%3 = alloca i32, align 4
store i32* %0, i32** %2, align 8
%4 = load i32*, i32** %2, align 8
%5 = getelementptr inbounds i32, i32* %4, i64 0
%6 = load i32, i32* %5, align 4
store i32 %6, i32* %3, align 4
ret void
}
Getelementptr - > GEP. GEP can be used to index the pointer. If you want to get the content of the address pointed to by the pointer, load it
C/C++ API
llvm::IRBuilderBase::CreatePHI()
The Often Misunderstood GEP Instruction
REFERENCE
LLVM Language Reference Manual
Tutorial-Bridgers-LLVM_IR_tutorial
https://stackoverflow.com/quest
About DeepRoute Lab
Shenzhen Yuanrong QIHANG Technology Co., Ltd. (deeroute. AI) is a technology company focusing on the research and development of L4 level automatic driving technology. It focuses on two scenes of travel and intra city freight transportation, and has two product lines of "Yuanqi" (Robotaxi automatic driving passenger car) and "Yuanqi" (Robotruck automatic driving light truck).
[deep route lab] is the cutting-edge knowledge sharing platform of automatic driving academic industry founded by us. We will share the internal paper reading of the company here, so that you can easily read paper; We will also share our understanding of the industry here and look forward to more and more students knowing about automatic driving and joining the industry!