ResNet-18:Train and Test Records
**Invariant: * * 200 rounds, ResNet18, input image size 32 (pad=4, randomCrop=32), batchsize=256
**Variables: * * learning rate, optimizer, policy
Note: because the experiment is at 32 × 32, so maxpooling (thank to teacher shi.) should not be used before the second layer, but I didn't know at the beginning, so the effect of training can't reach 90%. After modification, it can achieve high accuracy. Because it's the same in essence, I only do a group of experiments to compare the results (LR=0.1,SGD+M=0.9, cosiannealingwarm).
1, Fixed learning rate
1,LR=0.1 (SGD+M!!!)
Different optim
1.SGD
Experiment 1.1-SGD
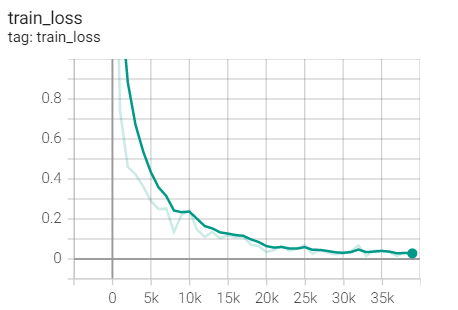
Experiment 1.2-SGD+M=0.9
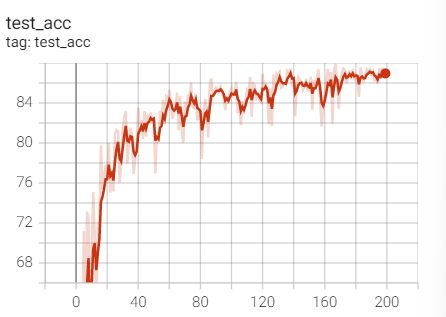
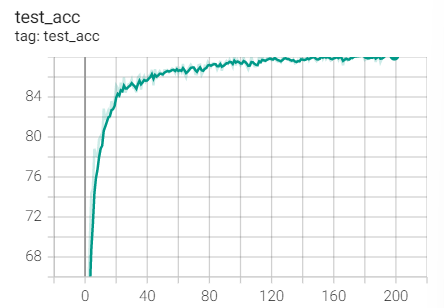
Experiment 1.3-SGD+M=0.9+weight_decay=1e-3
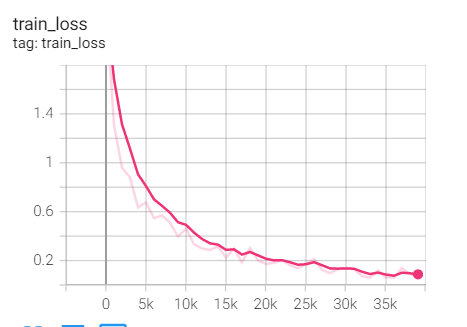
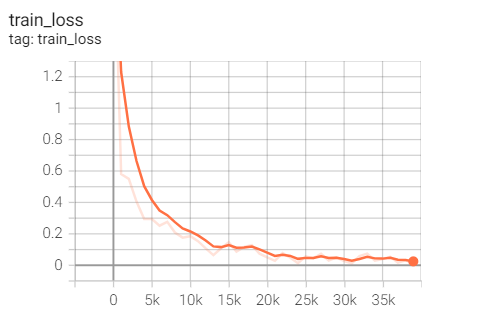
Experiment 1.4-sgd + M = 0 + nestrov = true
Experiment 1.5-SGD+M=0.9+Nesterov=True
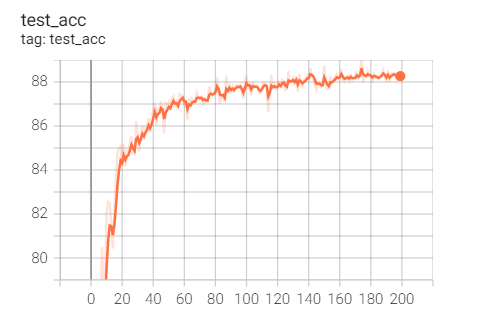
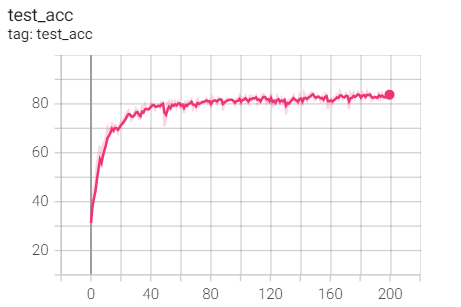
2.Adam
Experiment 1.6-Adam
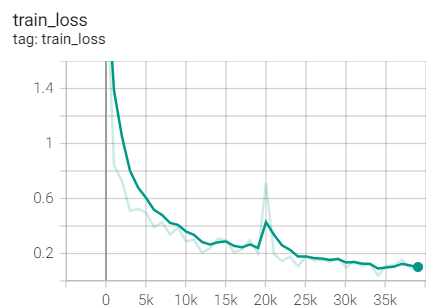
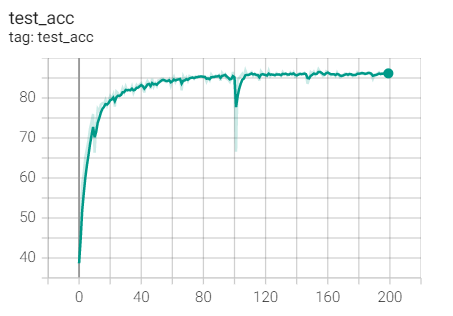
3.Adagrad
Experiment 1.7-Adagrad
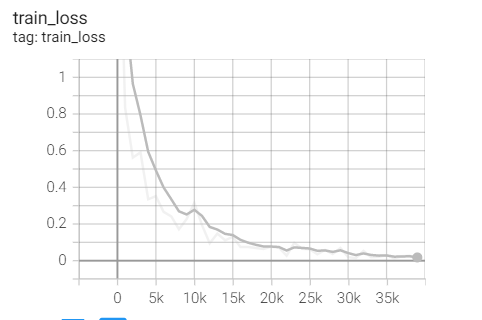
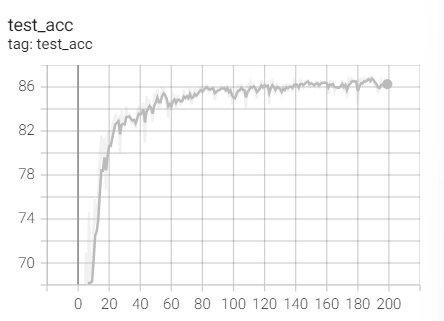
4.RMSprop
Experiment 1.8-RMSprop
2,LR=1e-2 (SGD+M!!!)
Experiment 1.9 SGD
Experiment 1.10 SGD+M
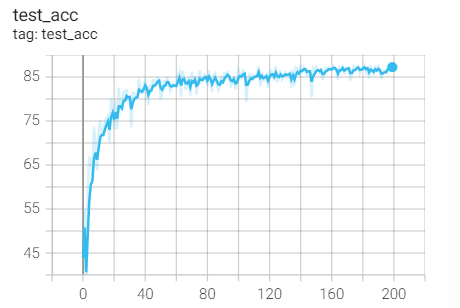
Experiment 1.11 Adam
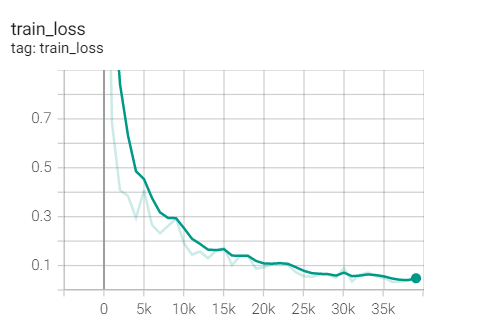
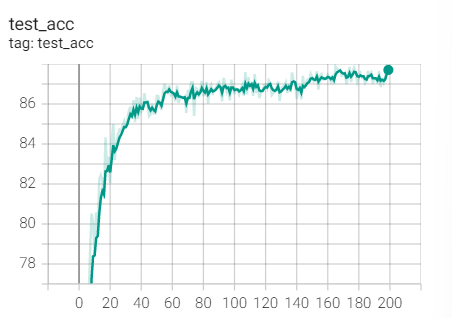
Experiment 1.12 Adagrad
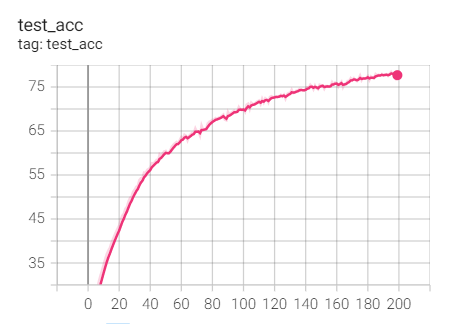
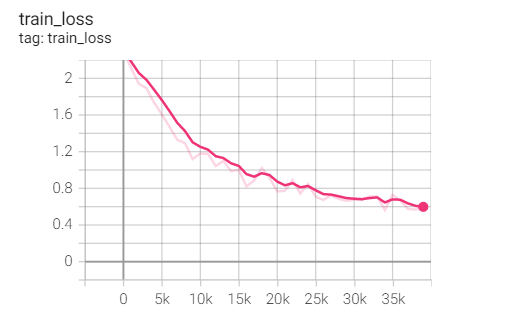
Experiment 1.13-RMSprop
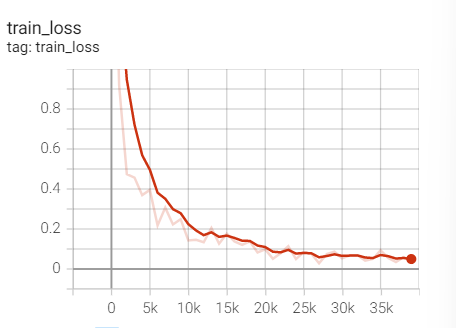
3,LR=1e-3
Experiment 1.14-SGD
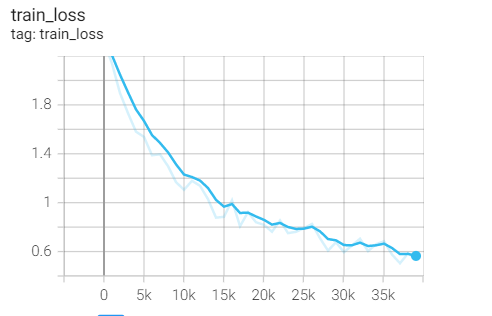
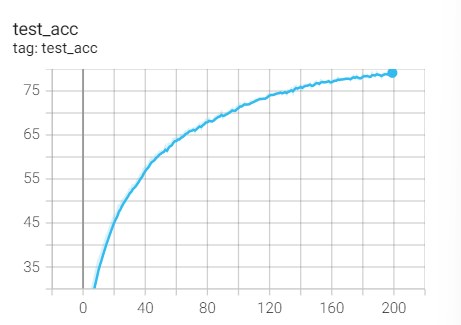
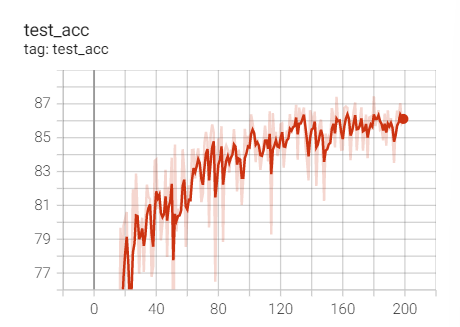
2, Change in learning rate
1. Cosine simulated annealing
T_max=25, that is, the half cycle is 25 epoch s and the full cycle is 50, then there will be 4 cycles in 200 rounds.
Different optim
1.SGD+Momentum
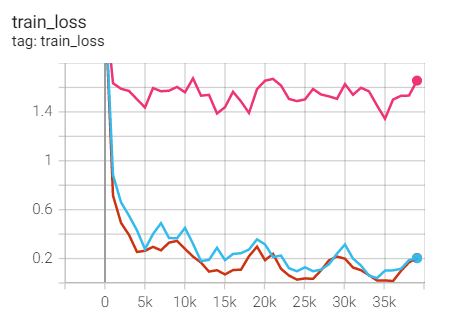
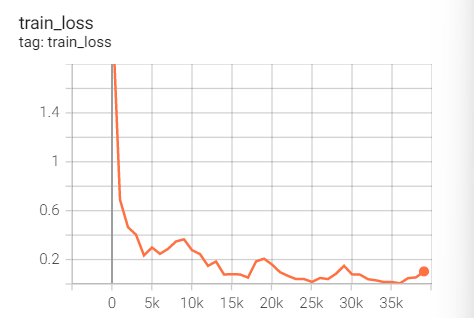
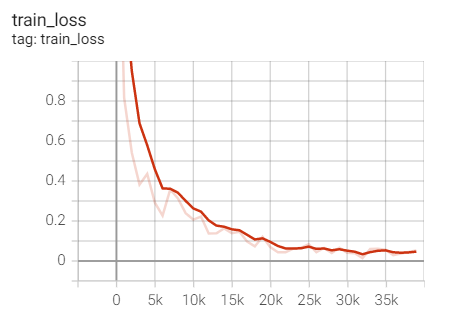
Experiment 2.1: LR=0.1, M=0.9, no weight decay
Initial learning rate 0.1, SGD optimizer with momentum (0.9), no weight decaly
optimizer = optim.SGD(net.parameters(),lr=args.lr,
momentum=0.9)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max=20)
Training set loss
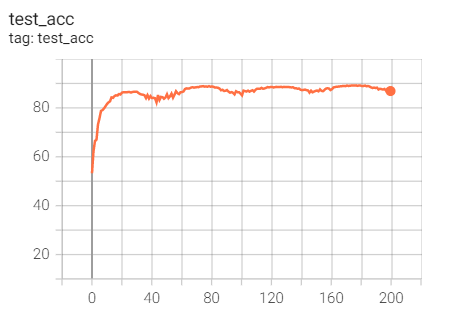
Test set acc
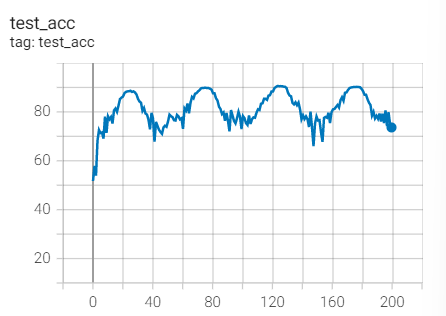
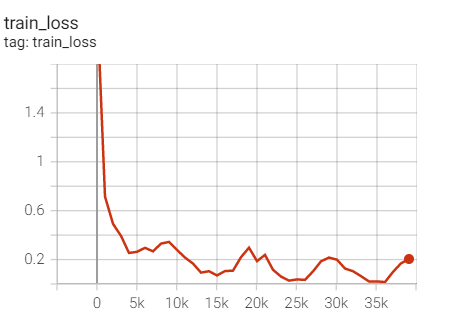
Feeling: without weight_ There will be fitting problems in decaly.
Experiment 2.2: LR=0.1, M=0.9, Weight_decay=1e-3
Initial learning rate 0.1, SGD optimizer with momentum (0.9), T_max=25,weight _decay=1e-3
optimizer = optim.SGD(net.parameters(),lr=args.lr,
momentum=0.9,weight_decay=1e-3)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max=20)
Training set loss
Test set acc
Experiment 2.3: LR=0.1, M=0.9, Weight_decay=1e-4
Initial learning rate 0.1, SGD optimizer with momentum (0.9), weight decay=1e-4
optimizer = optim.SGD(net.parameters(),lr=args.lr,
momentum=0.9,weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max=20)
Training set loss
Test set acc
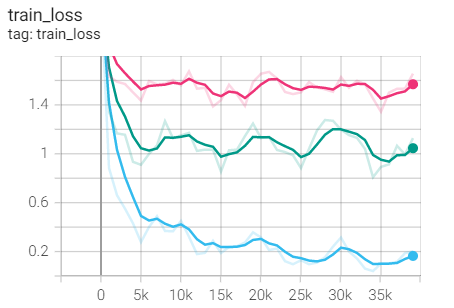
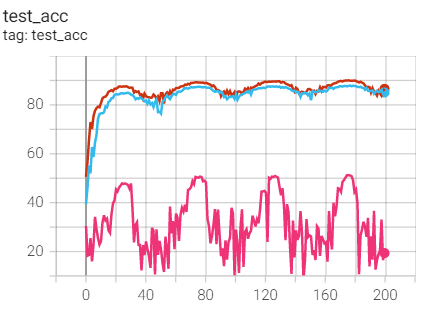
Comparison of the first three experiments
2.Adam
Experiment 2.4: LR=0.1, l1=0.9,l2=0.999, no weight decay
Initial learning rate 0.1, Adam optimizer, l1=0.9,l2=0.999, no weight decay
optimizer_Adam = optim.Adam(net.parameters(),args.lr,(0.9, 0.999)) scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_Adam,T_max=25)
Training set loss
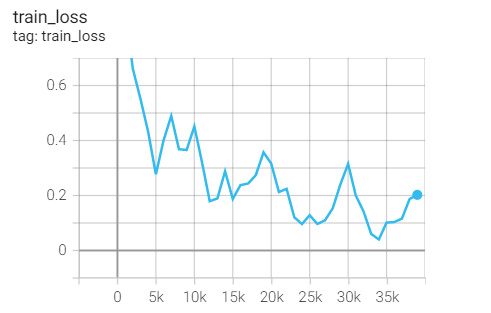
Test set acc
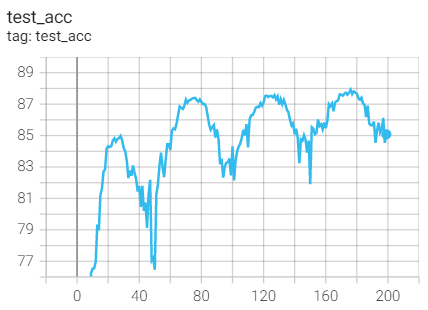
Compared with ResNet18 of no weight decaly:
Experiment 2.5: LR=0.1, l1=0.9,l2=0.999, weight decay=1e-3
The initial learning rate is 0.1, Adam optimizer, l1=0.9,l2=0.999, weight decay=1e-3
optimizer_Adam = optim.Adam(net.parameters(),args.lr,(0.9, 0.999),weight_decay=1e-3) scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_Adam,T_max=25)
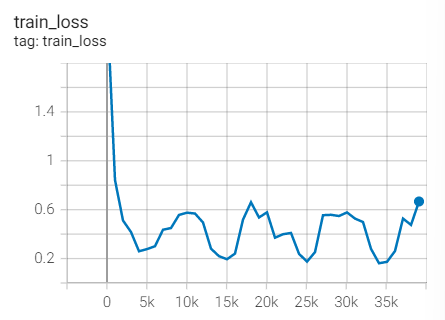
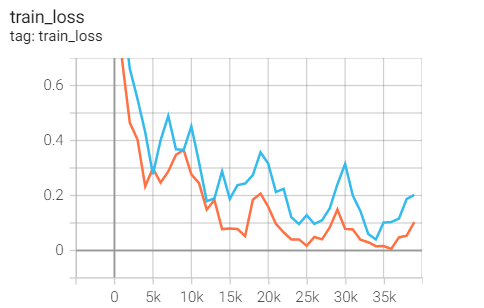
Training set loss
Test set acc
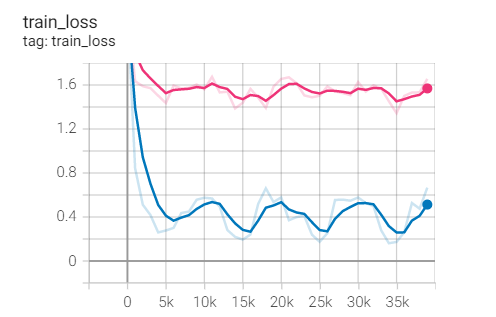
The effect is too bad
Same weight as SGD_ Dacay for comparison
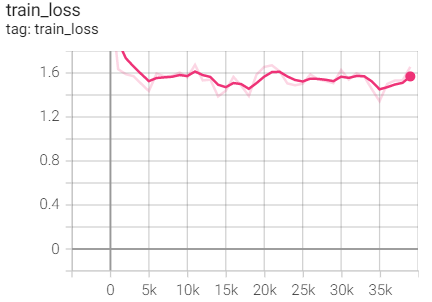
Experiment 2.6: LR=0.1, l1=0.9,l2=0.999, weight decay=1e-4
The initial learning rate is 0.1, Adam optimizer, l1=0.9,l2=0.999, weight decay=1e-4
optimizer_Adam = optim.Adam(net.parameters(),args.lr,(0.9, 0.999),weight_decay=1e-4) scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_Adam,T_max=25)
Training set loss
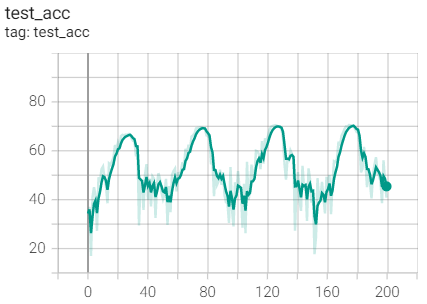
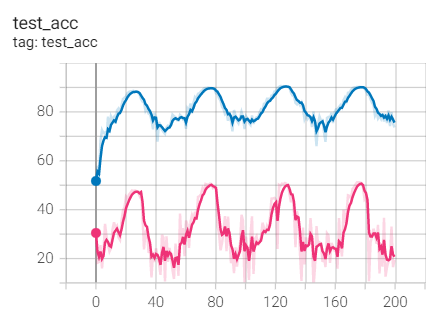
Test set acc
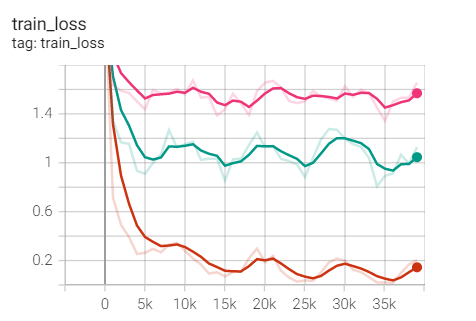
The effect is too bad
Same weight as SGD_ Dacay for comparison and 1e-3 for comparison
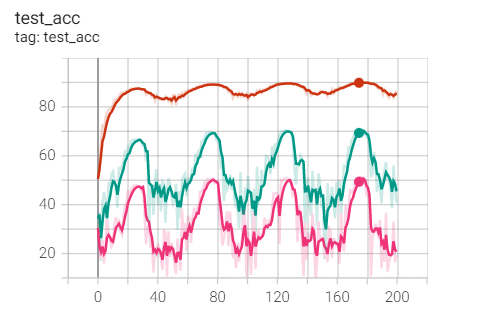
Summary: same weight as_ Compare the SGD optimizer of decay and find the train of SGD_ Loss and test_acc is better, but better than weight_decay=1e-3 (pink line) should make progress
3.Adagrad
Experiment 2.7: LR=0.1
Initial learning rate 0.1, Adagrad optimizer
optimizer = optim.Adagrad(net.parameters(),lr=args.lr) scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_Adam,T_max=25)
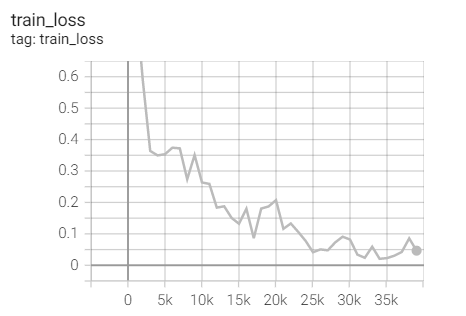
Training set loss
Test set acc
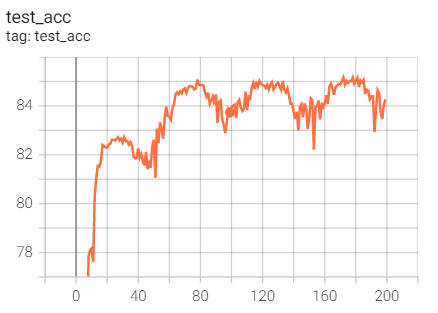
The accuracy is not what we want. Because the official document of pytorch says that the default is 0.01, and we are 0.1, we plan to adjust the initial learning rate and try again.
Experiment 2.8: LR=0.01
Initial learning rate 0.01, Adagrad optimizer
optimizer = optim.Adagrad(net.parameters(),lr=1e-2) scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_Adam,T_max=25)
Training set loss
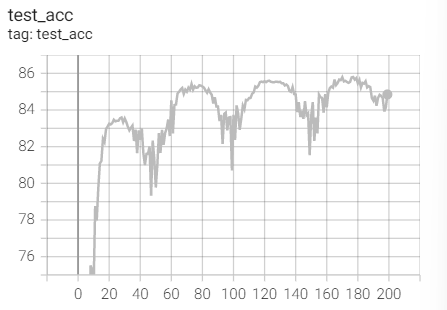
Test set acc
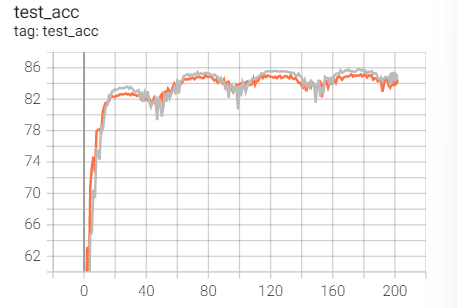
Comparison of the above two adagrads
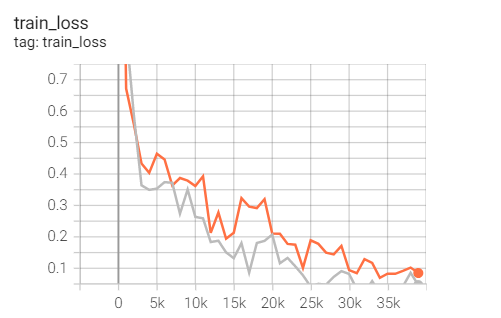
The findings are very similar, so we plan to use a set of improved algorithms - RMSprop to observe whether there is progress.
4.RMSprop
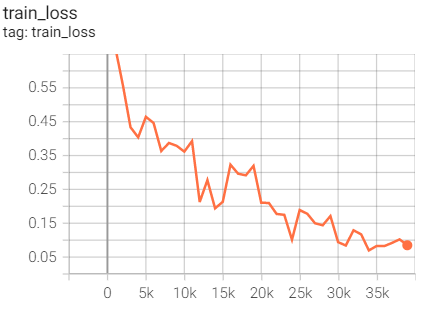
Experiment 2.9: LR=0.1
Initial learning rate 0.1, RMSprop optimizer
optimizer = optim.RMSprop(net.parameters(),lr=args.lr) scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_Adam,T_max=25)
Training set loss
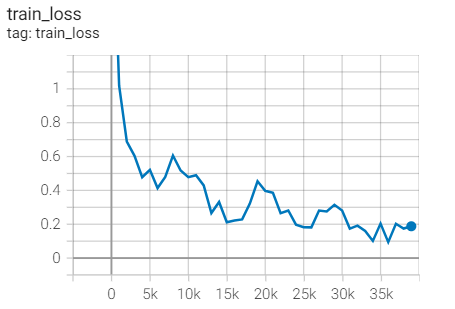
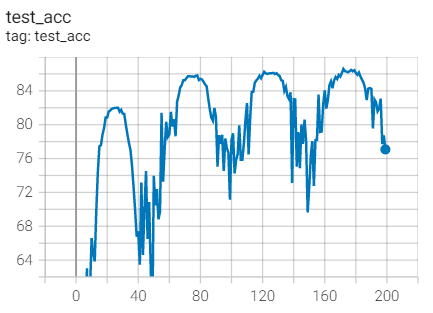
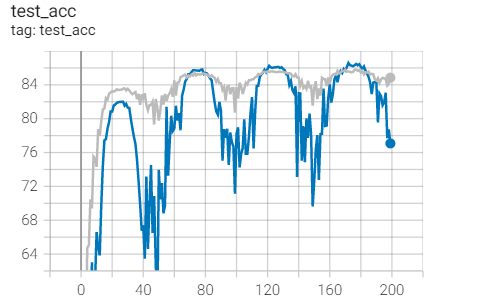
Test set acc
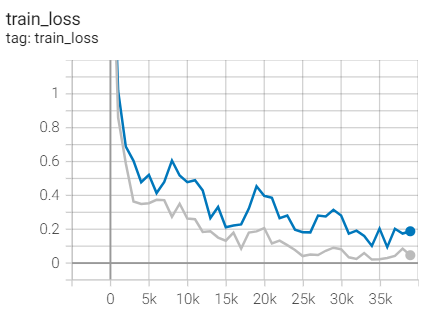
Compared with Adagrad with the same parameters:

2. Cosine simulated annealing with preheating (WarmStart)
SGDR: Stochastic Gradient Descent with Warm Restarts.
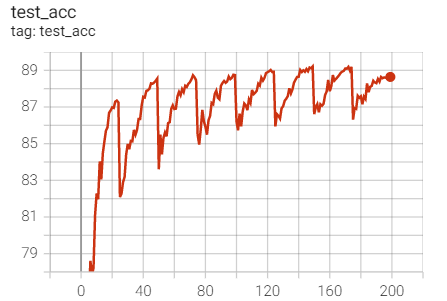
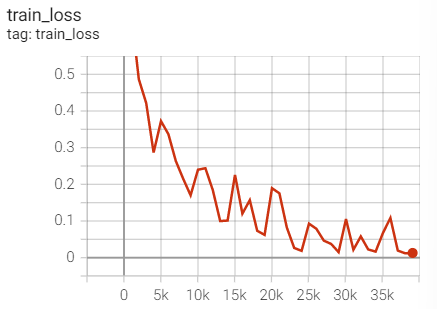
1.SGD+Momentum
Experiment 2.10: LR=0.1, M=0.9, T_0=25,T_mult=1
The initial learning rate is 0.1, and the learning rate is adjusted every 25 rounds
optimizer = optim.SGD(net.parameters(),lr=args.lr,momentum=0.9) scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=25)
Training set loss
Test set acc
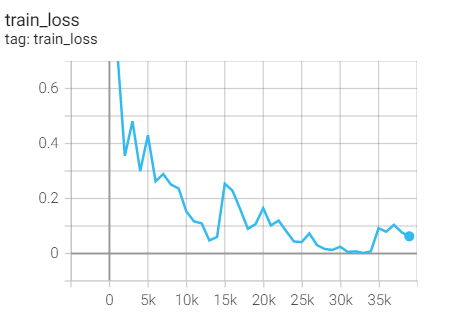
Experiment 2.11: LR=0.1, M=0.9, T_0=25,T_mult=2
The initial learning rate is 0.1, and the learning rate is adjusted every 25 rounds
optimizer = optim.SGD(net.parameters(),lr=args.lr,momentum=0.9) scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=25,T_mult=2)
Training set loss
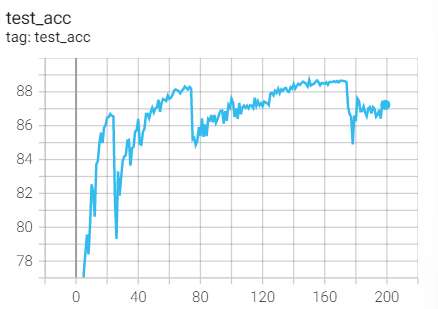
Test set acc
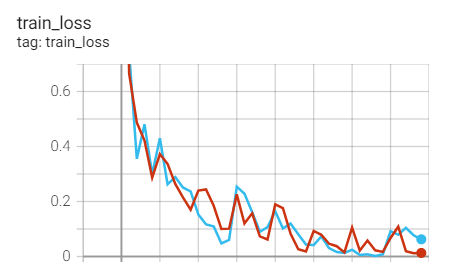
contrast
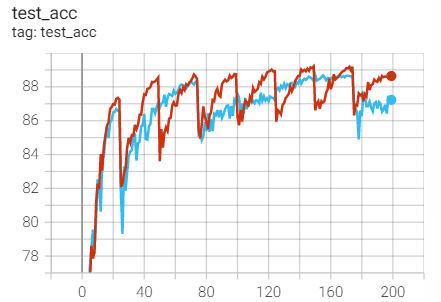
3. Equal interval adjustment (StepLR)
Experiment 12: step_size=40
Adjust every 40 rounds
optimizer = optim.SGD(net.parameters(),lr=args.lr,momentum=0.9) scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=40,gamma=0.1, last_epoch=-1)
Training set loss
Test set acc
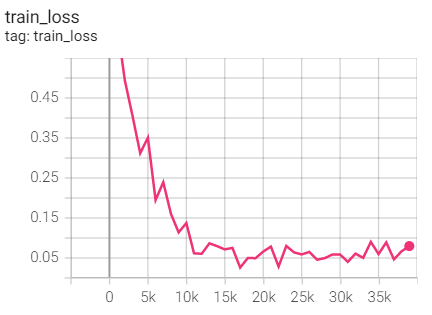
Experiment 13: step_size=40
Adjust every 40 rounds
optimizer = optim.SGD(net.parameters(),lr=args.lr,momentum=0.9) scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=40,gamma=0.1, last_epoch=-1)
Training set loss
Test set acc
3, New experiment
The reason for this experiment has been indicated at the beginning of the article.
1. Cosine simulated annealing with preheating (WarmStart)
SGD+Momentum
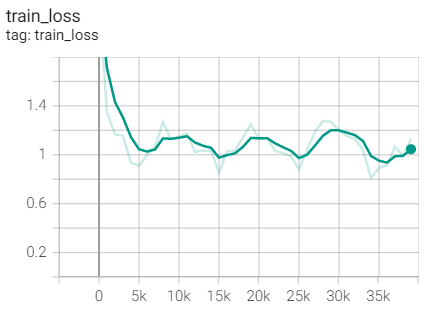
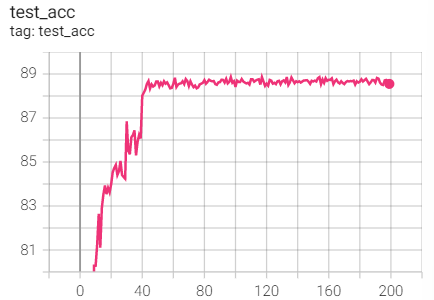
Experiment 3.1: LR=0.1, M=0.9, T_0=25,T_mult=2
The initial learning rate is 0.1, and the learning rate is adjusted every 25 rounds
optimizer = optim.SGD(net.parameters(),lr=args.lr,momentum=0.9) scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=25,T_mult=2)
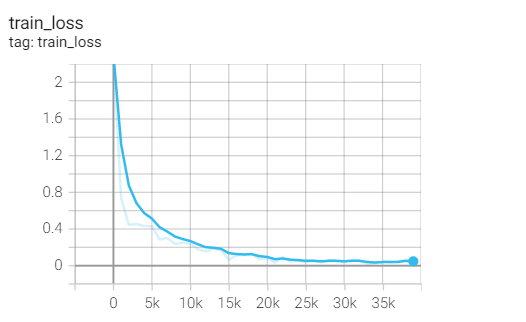
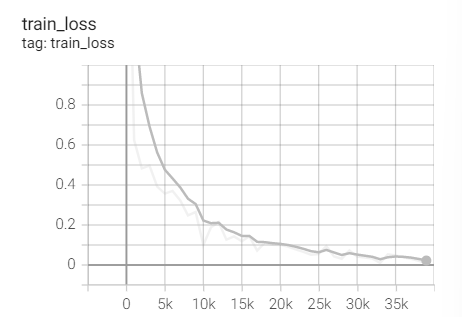
Training set loss
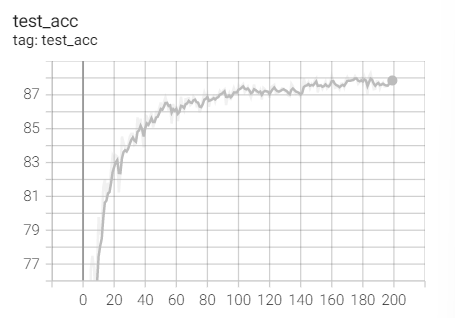
Test set acc
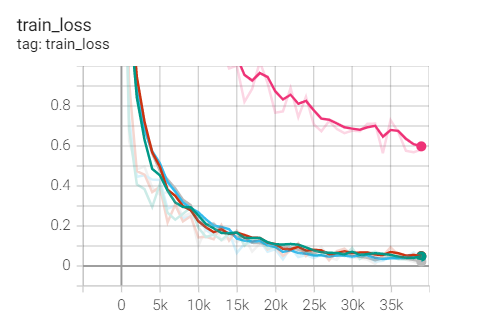
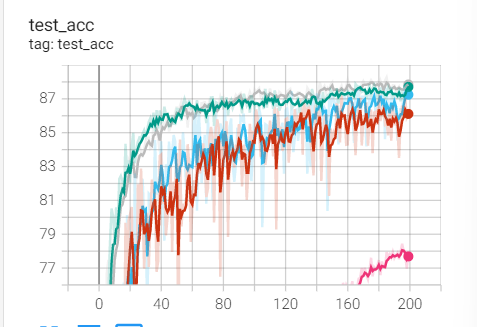
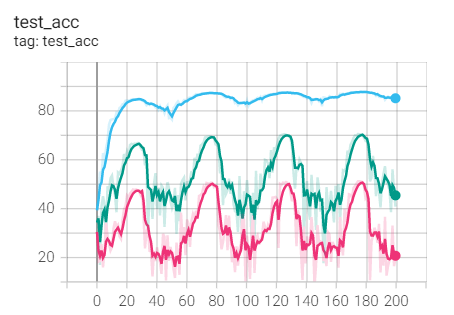
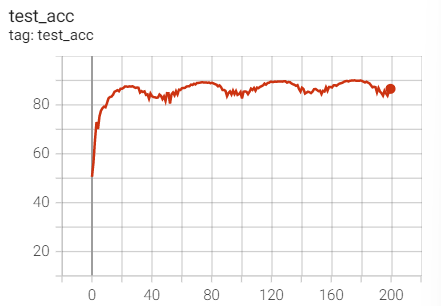
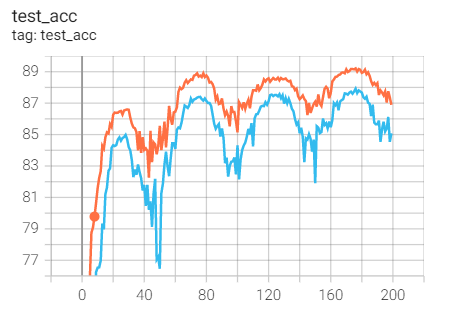
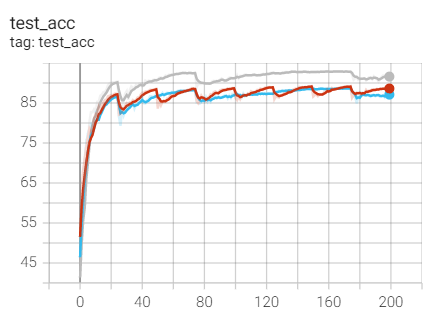
2. Experimental control
Conclusion: it is found that ResNet18 with modified structure performs better in performance.
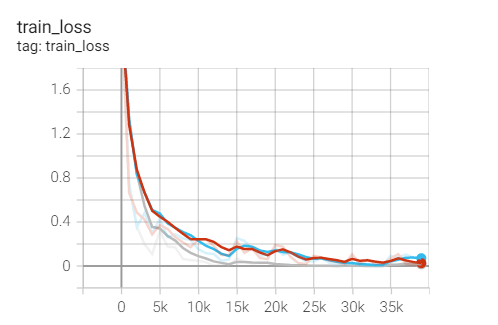
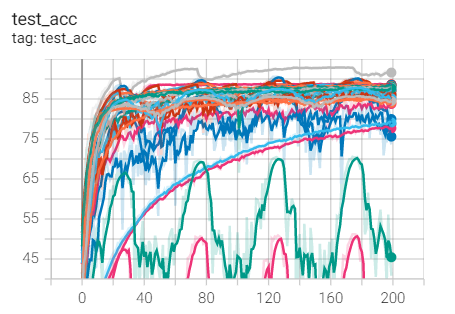
4, Summary
Learning rate, optimizer and schedule are really important. The deficiency of this experiment is that dropout is not used, but it has deepened my proficiency in deep learning parameter adjustment. At the same time, it should be noted that different network models, different data sets and different image sizes will have different effects on the learning rate, optimizer and scheduler. Do not generalize.
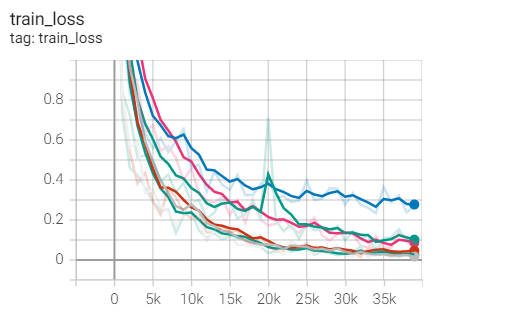
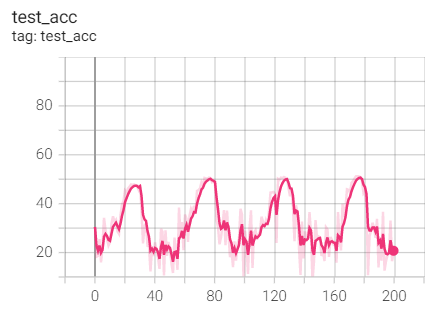
Finally, put a set diagram of these 28 experiments, hh:
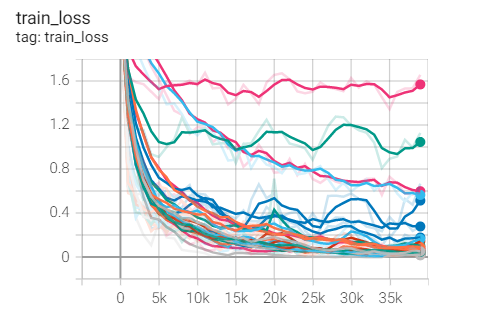
oss**
[external chain picture transferring... (img-czlRQCC2-1637387103638)]
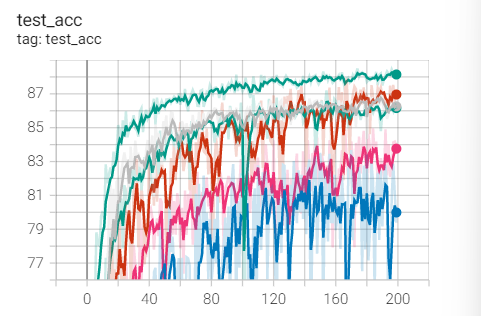
Test set acc
[external chain picture transferring... (IMG opuvtto0-1637387103639)]
2. Experimental control
Conclusion: it is found that ResNet18 with modified structure performs better in performance.
[external chain picture transferring... (img-K7j06G5z-1637387103641)]
[external chain picture transferring... (img-E5orBSnt-1637387103643)]
4, Summary
Learning rate, optimizer and schedule are really important. The deficiency of this experiment is that dropout is not used, but it has deepened my proficiency in deep learning parameter adjustment. At the same time, it should be noted that different network models, different data sets and different image sizes will have different effects on the learning rate, optimizer and scheduler. Do not generalize.
Finally, put a set diagram of these 28 experiments, hh:
[external chain picture transferring... (img-8qJtVuOL-1637387103644)]