1, First, consider a question: why does redis need a distributed solution with such high performance?
1. Achieve higher performance: for highly concurrent applications, the performance of a single machine will be affected. More redis servers are needed to share the pressure and achieve load balancing
2. Achieve high availability: prevent downtime / hardware failure if stand-alone
3. Achieve scalability: there are limitations on stand-alone memory and hardware to achieve horizontal expansion
Redundant or fragmented storage implements the above characteristics.
2, Master slave replication configuration
Like Kafka, MySQL and rocketmq, redis supports cluster deployment. The cluster node can be divided into master and slave. The master node is the master node and the slave node is the slave (the latest name is replica) Slave synchronizes the latest data from the master through the replication mechanism. Redis provides a very convenient command to enable master-slave replication.
How to configure and enable master-slave replication?
Taking the pseudo cluster built by the local machine as an example, port 6379 is the slave node and 6378 is the master node.
1. From node redis Conf configure replicaof master IP master port. After starting from the node, it will automatically connect to the master node and start data synchronization

If a new master node is replaced, this configuration will be overwritten.
2. Or specify it when the redis server program starts
./redis-server --replicaof masterip masterport Copy code
3. Or log in to the client and execute the following commands
slaveof masterip masterport Copy code
Note that this method is modified during operation to achieve failover
Note: a slave node can also be the master node of other nodes, forming a cascade replication relationship. However, other nodes also synchronize data from the top-level master node.
After configuring the cluster, view the cluster status through info replication

Through the role command, you can view the role information of nodes in the cluster
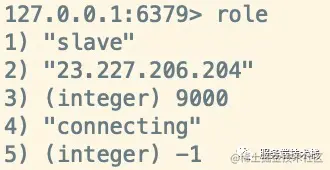
Note that the slave node is read-only. Writing a command will report an error.

How does slave exit the cluster? You can execute the following commands:
slaveof no one Copy code
3, Master slave replication process
1. First, replica joins the cluster
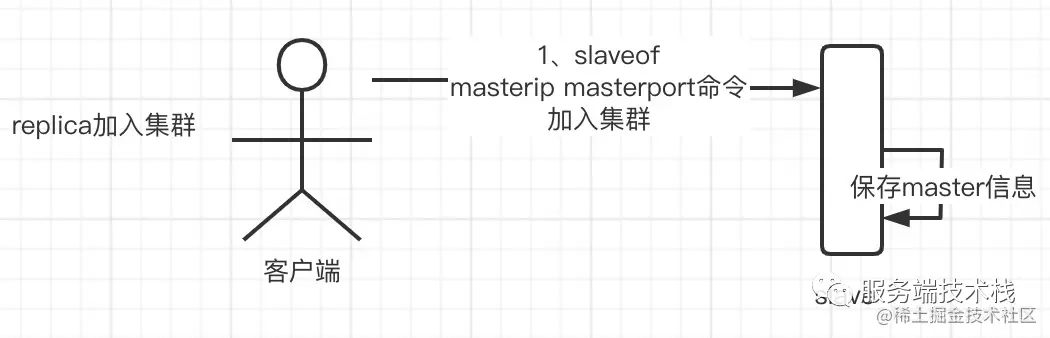
2. Establish a connection with the master and check regularly whether to synchronize data from the master node through a timer
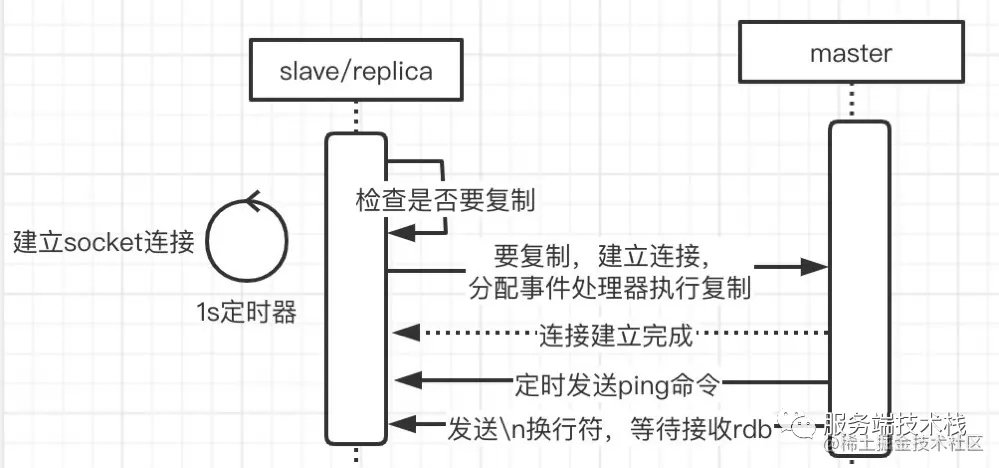
Source code Description:
//Execute this method every 1s void replicationCron(void) {... / / check whether you need to connect to the master. If it is REPL_STATE_CONNECT, you must connect to the master / /#define REPL_STATE_CONNECT 1 must connect to master if (server. Repl_state = = REPL_STATE_CONNECT) {serverlog (ll_note, "connecting to master% s:% d" , server. masterhost, server. masterport); // Create a connection with the master if (connectwithmaster() = = C_ OK) { serverLog(LL_NOTICE,"MASTER <-> REPLICA sync started"); } } // Send ping command to slave if ((replication_cron_loops% server. Repl_ping_slave_period) = = 0 & & listlength (server. Slaves)) { /* Note that we don't send the PING if the clients are paused during * a Redis Cluster manual failover: the PING we send will otherwise * alter the replication offsets of master and slave, and will no longer * match the one stored into 'mf_master_offset' state. */ int manual_failover_in_progress = server. cluster_ enabled && server. cluster->mf_ end && clientsArePaused(); if (!manual_failover_in_progress) { ping_argv[0] = createStringObject("PING",4); replicationFeedSlaves(server.slaves, server.slaveseldb, ping_argv, 1); decrRefCount(ping_argv[0]); } } // Send a newline character to all slaves and tell them to wait for receiving the RDB file listrewind (server. Slaves, & Li); while((ln = listNext(&li))) { client *slave = ln->value; int is_presync = (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START || (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END && server.rdb_child_type != RDB_CHILD_TYPE_SOCKET)); if (is_presync) { if (write(slave->fd, "\n", 1) == -1) { /* Don't worry about socket errors, it's just a ping. */ } } } ...}
Copy code3. Full replication process - supports diskless replication or rdb persistent replication
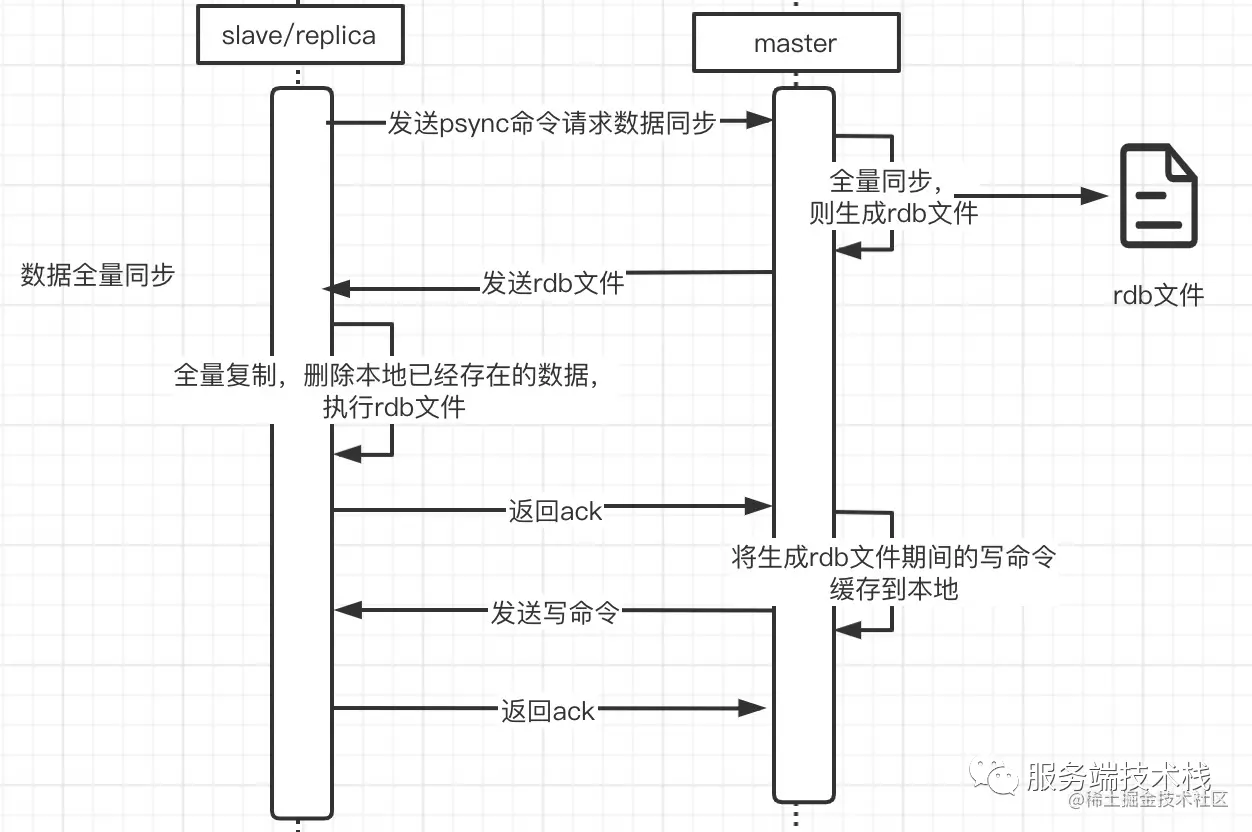
After the slave is connected to the master, use PSYNC (previously the sync command, which does not allow partial resynchronization, so now use PSYNC) to initialize replication, and send the master node replication id and the processed maximum offset to the master.
The master node has the following two attributes: a replication id (flag instance) and an offset (flag written to the stream of the slave node)
Replication ID, offset Copy code
A full resynchronization occurs if there is not enough backlog in the master node buffer, or if the replica references a history (replication ID) that is no longer known
Source code Description:
//Not in the RDB process, No AOF rewrite process if (server.rdb_child_pid = = - 1 & & server.aof_child_pid = = - 1) {time_t idle, max_idle = 0; int slides_waiting = 0; int mincapa = - 1; listnode * ln; listiter Li; listrewind (server.slides, & Li); while ((LN = listnext & Li))) {client * slave = ln - > value; / / judge whether the slave is waiting for bgsave status if (slave - > replstate = = slave_state_wait_bgsave_start) {/ / how long has the idle time interval between sending heartbeat or querying data? Idle = server.unixtime - slave - > lastaction; if (idle > max_idle) max_ idle = idle; slaves_ waiting++; mincapa = (mincapa == -1) ? slave->slave_ capa : (mincapa & slave->slave_capa); } } if (slaves_waiting && (!server.repl_diskless_sync || max_idle > server.repl_diskless_sync_delay)) {/ * start the bgsave. The called function may start a * bgsave with socket target or disk target dependent on the * configuration and slave capabilities. * / / / bgsave RDB generate startBgsaveForReplication(mincapa);}}
Copy codeDuring the replication process, the slave state transition process.
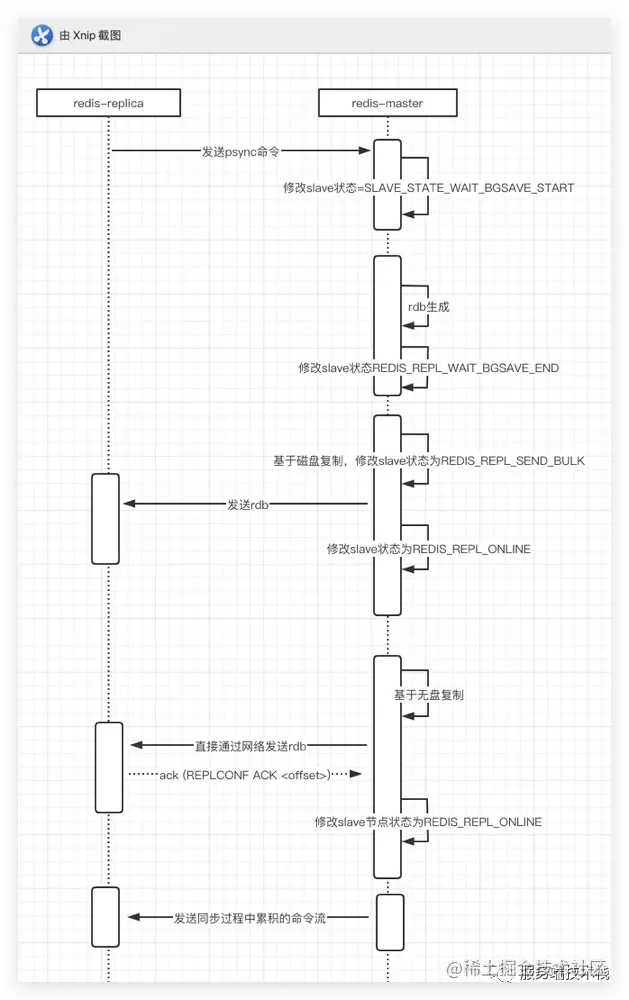
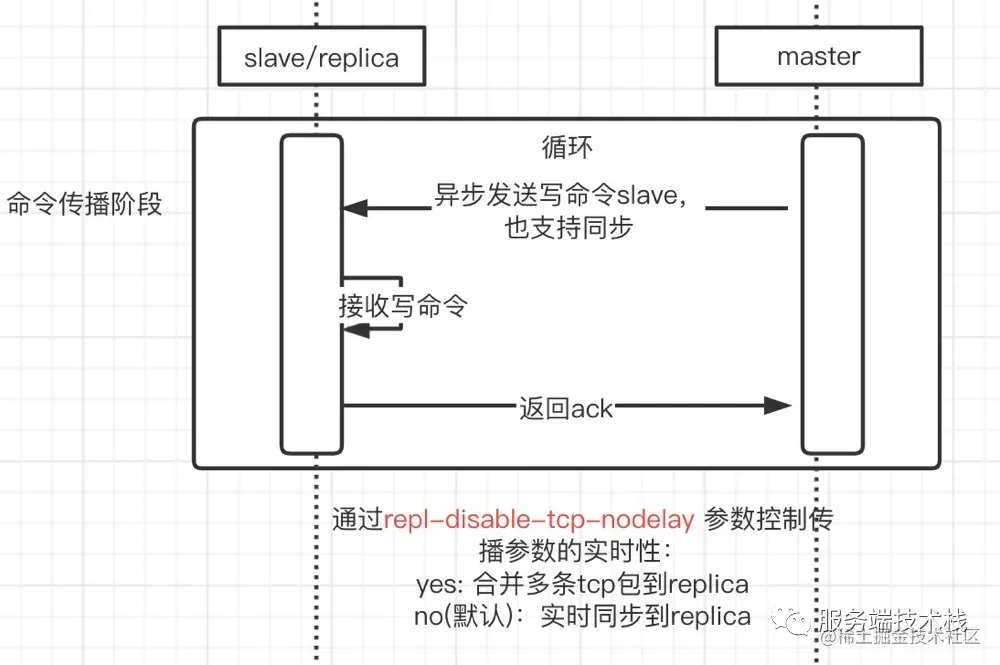
4. In the command propagation stage, after full synchronization, the master and slave will propagate the command to achieve data consistency.
4, Copy id understanding
Each time an instance is restarted from scratch as the primary instance, or the replica is promoted as the primary instance, a new replication ID is generated for this instance. If the replication IDs of two replicas are the same, they may have the same data at different times. For a given history (replication ID) that saves the latest dataset, the offset is understood as a logical time. It needs to be judged by replication ID and offset. Used to determine where the synchronized data from the node has gone.
5, Master slave replication FAQ
1. What happens if the slave itself has data?
The slave deletes its own data first, and then loads the rdb file.
2. In the process of generating rdb files, how to deal with the commands written by the client?
Save it to the memory cache, and send it to the slave after the rdb is sent.
3. How does Redis replication handle expired key s?
1. The replica will not expire the key, but wait for the host to expire the key. When the host expires the key (or evicts it due to LRU), it will synthesize a DEL command, which will be transmitted to all replicas.
2. However, due to the host driven expire, sometimes the replica may still have a logically expired memory key because the master server cannot provide the DEL command in time. To deal with this problem, the replica uses its logical clock to report that a key does not exist and is only used for read operations that do not violate the consistency of the dataset (because new commands from the master server will arrive)
3. Key expiration is not performed during Lua script execution. When Lua script runs, conceptually, the time in the master node is frozen, so the given key will exist or not exist at all times when the script runs. This prevents the key from expiring in the middle of the script and requires the key to send the same script to the copy in a way that ensures the same effect in the dataset.
Once the replica is promoted to the primary, it will begin to independently expire the key without any help from the old primary.
6, Master slave replication summary
1. It solves the problem of data backup, but the rdb file is large, the transmission file is large, and the recovery time is also long
2. If the master is abnormal, you need to manually select the replica as the master
3. In the case of 1 master and 1 slave, there is still a single point problem
4. Redis version 2.8.18 supports diskless replication with higher performance.
7, Copy description
1. Asynchronous replication is used by default, and the number of synchronous commands is confirmed asynchronously
2. One master can have multiple replicas
3. Replicas can also have their own replicas from redis4 Starting from 0, replicas will receive exactly the same replication flow from the primary node
4. Replication can be used for scalability or for multiple copies of read-only queries