Deeply understand the underlying data structure of Redis List queue
list underlying data structure:
-
linkedList linked list
-
Zip list zip list
-
quickList
Linked list: LinkedList
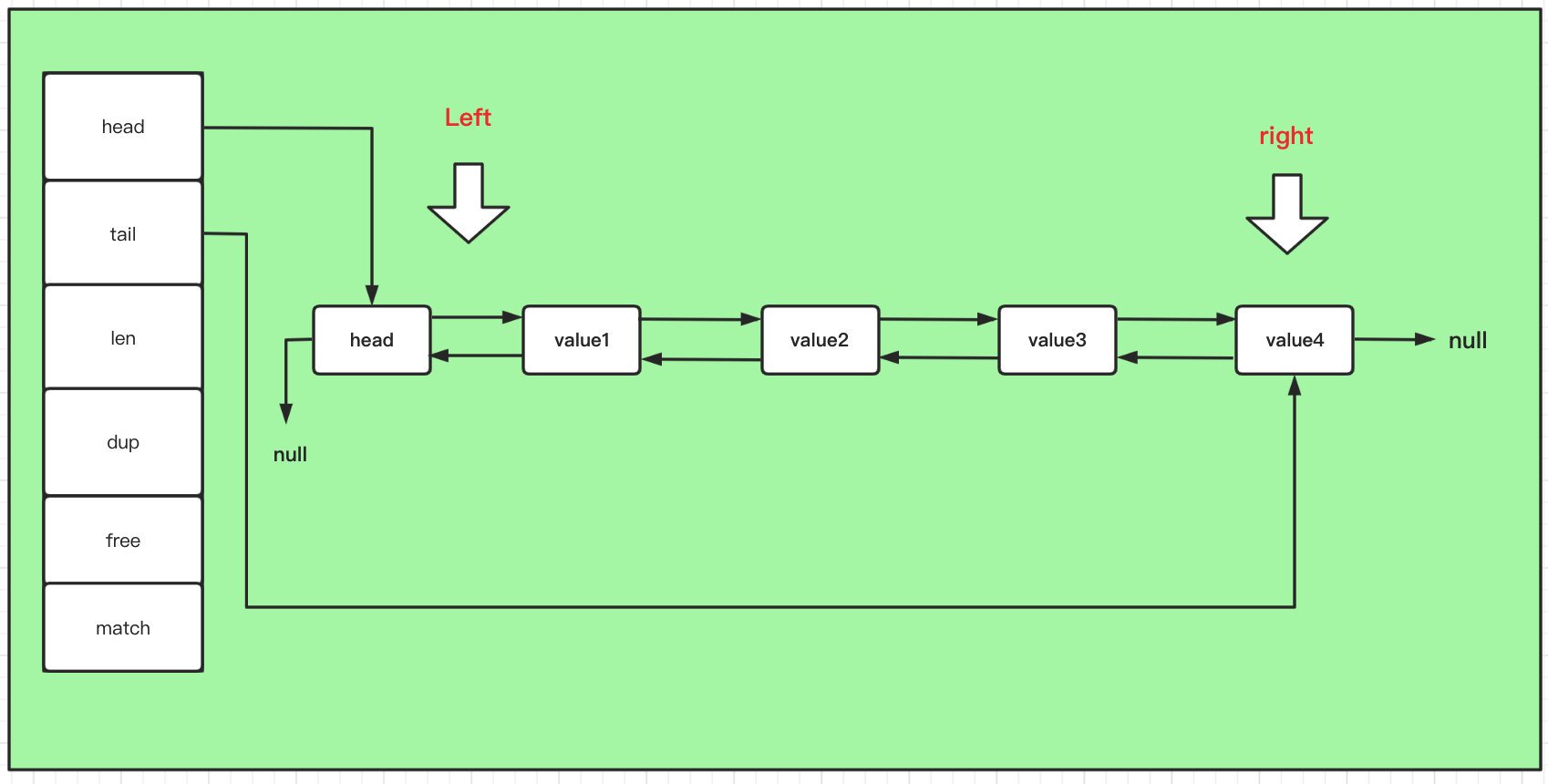
-
The two-way linked list of the leading node is commonly used in the data structure, and it has a head pointer to the head node and a tail pointer to the last node. The two-way linked list ensures that it can be traversed forward or backward from any position. However, it should be noted that the front pointer of the head node is null and the rear pointer of the tail node is null, which shows that the LinkedList data structure in redis is a null Linked list, reverse traversal is not supported
-
The second point is that in the lpush(left push), lpop(left pop) and other commands in the operation command, left represents the operation from the head of the team, and right represents the operation from the tail of the team.
-
The len field in the structure records the length of the entire linked list.
-
Due to the characteristics of the linked list itself, it takes very little time to add or delete the linked list, and the time complexity is only O(1); however, if it is necessary to find a value in the linked list by index, the time cost is a little high, and the time complexity is O(n)
-
The dup function is used to copy a chain node
-
The free function is used to release a chain node, that is, delete it
-
The match function is used to judge whether the value of a chain node is equal to the input value.
Compressed list: ZipList
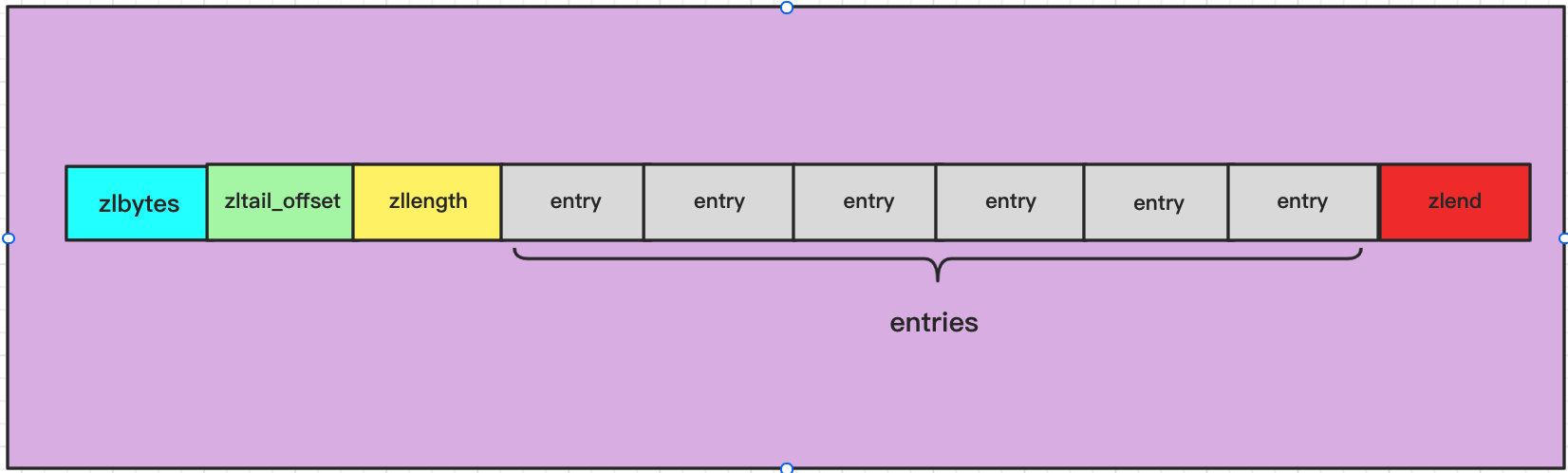
- The compressed list in redis uses byte array as its data structure.
- In the data structure of zipList, there are the following fields:
- zlbytes: the number of bytes occupied by the whole compressed list is 4 bytes, that is, 32 bits. Therefore, the maximum length of the compressed linked list is (2 ^ 32-1) bytes
- zltail_offset: compress the offset from the elements at the end of the list to the starting address. You can directly find the elements at the end of the list, that is, traversal in reverse order is supported
- zlength: the number of elements in the table, accounting for 2 bytes. If the number of elements in the list exceeds (2 ^ 16-1), you need to traverse the whole list to get the number of elements
- entry: the elements stored in the list may be integers or byte arrays. See the following figure for specific results
- zlend: the end flag of the element, accounting for one byte, is a constant OXFF
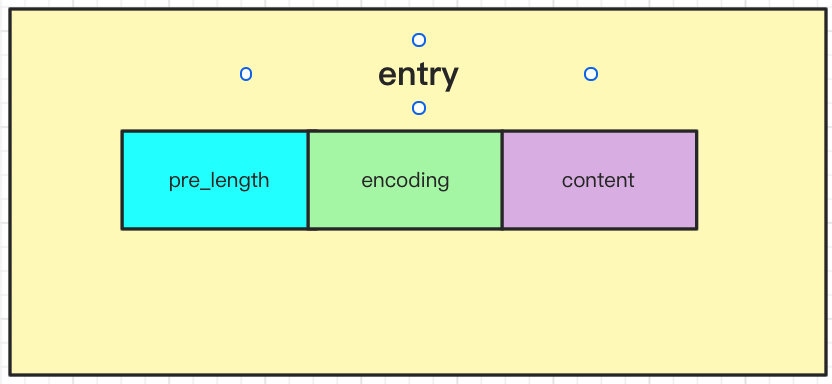
-
entry saves the elements in the list, which may be integers or byte arrays. Its structure has three fields:
-
pre_length: the length of the previous element. It is convenient to directly find the starting position of the previous node when traversing in reverse order. When the length of the current element is less than 254 bytes, it is represented by one byte; when the length of the current element is greater than or equal to 254 bytes, it is represented by five bytes. At this time, the previous byte stores a fixed value of 254.
-
encoding: the length is two bit s. Its values can be 00, 01, 10 and 11. 00, 01 and 10 indicate that the content part holds the character array, and 11 indicates that the content part holds the integer.
-
content: save the real element.
-
summary
-
When there are few stored elements, zipList is usually used as the basic data structure, while LinkedList is used when there are many data elements.
-
In terms of the characteristics of the data structure itself: LinkedList has great advantages in inserting and deleting elements. However, it needs to store two additional pointers, which has a large storage overhead. Moreover, each element is a separate memory space with discontinuous addresses, which is easy to cause memory fragmentation.
-
The compressed list is stored in a continuous memory space, but the cost of adding and deleting elements is large. A large number of copy operations are required when performing realloc operation in memory expansion
Quick list: QuickList
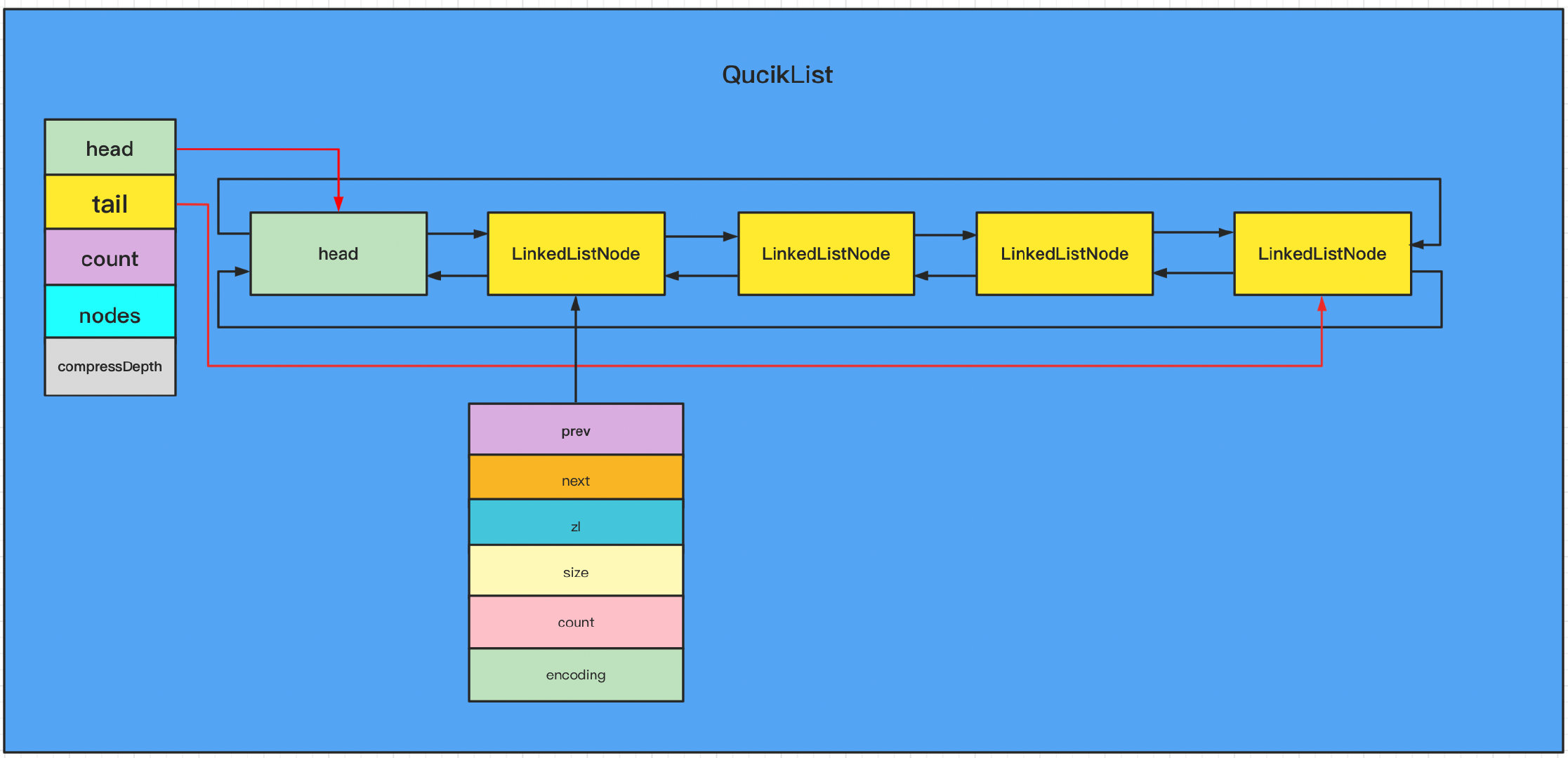
After redis 3.2, a new data structure, QuickList, is added. It combines the advantages of LinkedList and zipList. It stores each node of LinkedList in the form of zipList. LinkedList nodes are still connected by two-way linked list, but there are not only one element but multiple elements on a node, all of which are compressed in the form of list Stored on node.
Fields in QuickList structure:
- Head: points to the head node in the linked list
- tail: points to the last node in the linked list
- count: the number of QuickList storage elements
- Nodes: number of QuickList nodes
- compressDepth: the depth of the compression algorithm used. In order to further save space, redis will lzf compress the ziplost, which is a lossless compression algorithm.
Data structure of each node in QuickList:
- prev: pointer to the previous node
- Next: pointer to the next node
- zl: compressed linked list
- size: zplist occupied space
- count: the number of elements in the zipList
List common operations and examples
Insert header lpush key value1 [value2
If the key does not exist, create it first and then insert it
127.0.0.1:6379> flushdb OK 127.0.0.1:6379> lpush list 1 (integer) 1 127.0.0.1:6379> lpush list 2 (integer) 2 127.0.0.1:6379> lpush list 3 (integer) 3
Insert header lpushx key value1 [value2
If the key does not exist, no operation will be performed
127.0.0.1:6379> lpushx queue 1 2 3 (integer) 0 127.0.0.1:6379> exists quequ (integer) 0 127.0.0.1:6379> lpushx queue 1 2 3 (integer) 0 127.0.0.1:6379> exists quequ (integer) 0
Insert tail rpush
127.0.0.1:6379> lrange list 0 -1 1) "3" 2) "2" 3) "1" 127.0.0.1:6379> rpush list 4 (integer) 4 127.0.0.1:6379> lrange list 0 -1 1) "3" 2) "2" 3) "1" 4) "4"
View the specified range of the queue lrange start end
127.0.0.1:6379> lrange list 0 -1 1) "3" 2) "2" 3) "1"
Remove the first element of the list header: lpop key
127.0.0.1:6379> lrange list 0 -1 1) "3" 2) "2" 3) "1" 4) "4" 127.0.0.1:6379> lpop list 1) "3" 127.0.0.1:6379> lrange list 0 -1 1) "2" 2) "1" 3) "4"
Remove the first element at the end of the list: rpop key
127.0.0.1:6379> lrange list 0 -1 1) "2" 2) "1" 3) "4" 127.0.0.1:6379> rpop list "4" 127.0.0.1:6379> lrange list 0 -1 1) "2" 2) "1"
Get a value in the queue by subscript: lindex key index
127.0.0.1:6379> lrange list 0 -1 1) "2" 2) "1" 127.0.0.1:6379> lindex list 1 "1" 127.0.0.1:6379> lindex list 0 "2"
Get queue key
127.0.0.1:6379> lpush list 7 8 9 0 11 (integer) 7 127.0.0.1:6379> llen list (integer) 7
Remove the specified value: lrem key num value
Remove num elements with value from the key queue. By default, the value of the queue head is removed first
127.0.0.1:6379> lpush list 1 1 3 2 3 4 1 1 (integer) 8 127.0.0.1:6379> lrange list 0 -1 1) "1" 2) "1" 3) "4" 4) "3" 5) "2" 6) "3" 7) "1" 8) "1" 127.0.0.1:6379> lrem list 1 1 (integer) 1 127.0.0.1:6379> lrange list 0 -1 1) "1" 2) "4" 3) "3" 4) "2" 5) "3" 6) "1" 7) "1" 127.0.0.1:6379> lrem list 2 1 (integer) 2 127.0.0.1:6379> lrange list 0 -1 1) "4" 2) "3" 3) "2" 4) "3" 5) "1"
Truncate the list according to the specified location: ltrim
127.0.0.1:6379> lpush list 1 2 3 4 5 6 (integer) 6 127.0.0.1:6379> ltrim list 3 4 OK 127.0.0.1:6379> lrange list 0 -1 1) "3" 2) "2"
Remove the last element from list 1 and add it to the first location in list 2: rpoplpush list1 list2
127.0.0.1:6379> lrange list 0 -1 1) "3" 2) "2" 127.0.0.1:6379> rpoplpush list list1 "2" 127.0.0.1:6379> lrange list 0 -1 1) "3" 127.0.0.1:6379> lrange list1 0 -1 1) "2"
Specified location of update list: lset key index value
1. If the list does not exist, an error is reported
2. Overwrite values within the existing index range of the list
127.0.0.1:6379> lrange list 0 -1 1) "l" 127.0.0.1:6379> lset list 1 2 (error) ERR index out of range 127.0.0.1:6379> lset list 0 2 OK 127.0.0.1:6379> lrange list 0 -1 1) "2"
Insert a value before / after an element: linsert key before / after pivot value
When there are multiple same values in the list, the corresponding insertion operation will be performed on the first value of the header
127.0.0.1:6379> lrange list 0 -1 1) "2" 127.0.0.1:6379> linsert list before 2 before (integer) 2 127.0.0.1:6379> lrange list 0 -1 1) "before" 2) "2" 127.0.0.1:6379> linsert list after 2 after (integer) 3 127.0.0.1:6379> lrange list 0 -1 1) "before" 2) "2" 3) "after" #When there are multiple same values in the list, the corresponding insertion operation will be performed on the first value of the header 127.0.0.1:6379> lpush list2 1 3 4 1 3 4 (integer) 6 127.0.0.1:6379> lrange list2 0 -1 1) "4" 2) "3" 3) "1" 4) "4" 5) "3" 6) "1" 127.0.0.1:6379> linsert list2 before 1 before (integer) 7 127.0.0.1:6379> lrange list2 0 -1 1) "4" 2) "3" 3) "before" 4) "1" 5) "4" 6) "3" 7) "1"