Getting Started Guide
This getting started section will guide you through setting up a fully functional Flink cluster on Kubernetes.
Basic introduction
Kubernetes is a popular container choreography system, which is used to automate the deployment, expansion and management of computer applications. Flink's native kubernetes integration allows you to deploy Flink directly on a running kubernetes cluster. In addition, Flink can dynamically allocate and unassign task manager according to the required resources, because it can talk directly with kubernetes.
prepare
The introduction section assumes that the running Kubernetes cluster meets the following requirements:
- Kubernetes >= 1.9.
- KubeConfig, which can list, create and delete pods and services through ~ / kube/config. You can verify permissions by running kubectl auth can-I < list|create|edit|delete > pods.
- Enable Kubernetes DNS.
- Default service account with RBAC permission to create and delete pods.
If you haven't already created k8s Cluster, please refer to the article: https://lrting.top/backend/3919/ Quickly build a k8s cluster.
Start on k8s flink session
When starting the flink session on kubernetes, you need two additional jar packages, which need to be placed in the flink/lib Directory:
cd flink/lib wget https://repo1.maven.org/maven2/org/bouncycastle/bcpkix-jdk15on/1.69/bcpkix-jdk15on-1.69.jar wget https://repo1.maven.org/maven2/org/bouncycastle/bcprov-jdk15on/1.69/bcprov-jdk15on-1.69.jar
Create flick users and authorizations
kubectl create namespace flink kubectl create serviceaccount flink kubectl create clusterrolebinding flink-role-binding-flink \ --clusterrole=edit \ --serviceaccount=default:flink
If you do not create and authorize a Flink user, but use the default user to submit a Flink task, you will get the following error:
Caused by: io.fabric8.kubernetes.client.KubernetesClientException: Failure executing: GET at: https://10.10.0.1/api/v1/namespaces/default/pods?labelSelector=app%3Dkaibo-test%2Ccomponent%3Dtaskmanager%2Ctype%3Dflink-native-kubernetes. Message: Forbidden!Configured service account doesn't have access. Service account may have been revoked. pods is forbidden: User "system:serviceaccount:default:default" cannot list resource "pods" in API group "" in the namespace "default".
Once your Kubernetes cluster is running and kubectl is configured to point to it, you can start a Flink cluster in session mode
# (1) Start Kubernetes session
$ ./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dkubernetes.namespace=flink
# (2) Submit example job
$ ./bin/flink run \
--target kubernetes-session \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dkubernetes.namespace=flink \
./examples/streaming/TopSpeedWindowing.jar
# (3) Stop Kubernetes session by deleting cluster deployment
$ kubectl delete deployment/my-first-flink-clusterWhen using Minikube, you need to call minikube tunnel to expose Flink's LoadBalancer service on Minikube.
After the Flink session is started, the 8081 will be exposed to the local port by default. The following is the output of running the start k8s session command:
[root@rancher02 flink-1.13.5]# ./bin/kubernetes-session.sh \ > -Dkubernetes.cluster-id=my-first-flink-cluster \ > -Dkubernetes.namespace=flink 2022-02-26 14:49:16,203 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.address, localhost 2022-02-26 14:49:16,205 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.port, 6123 2022-02-26 14:49:16,205 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.memory.process.size, 1600m 2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.memory.process.size, 1728m 2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.numberOfTaskSlots, 1 2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: parallelism.default, 1 2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: s3.endpoint, http://10.0.2.70:9000 2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: s3.path.style.access, true 2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: s3.access.key, PCGIXWJBM78H74CWUITM 2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: s3.secret.key, ****** 2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.backend, rocksdb 2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.checkpoints.dir, s3://flink/checkpoints 2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.savepoints.dir, s3://flink/savepoints 2022-02-26 14:49:16,207 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.backend.incremental, false 2022-02-26 14:49:16,207 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.execution.failover-strategy, region 2022-02-26 14:49:16,249 INFO org.apache.flink.client.deployment.DefaultClusterClientServiceLoader [] - Could not load factory due to missing dependencies. 2022-02-26 14:49:17,310 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (160.000mb (167772162 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead 2022-02-26 14:49:17,320 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (172.800mb (181193935 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead 2022-02-26 14:49:17,437 INFO org.apache.flink.kubernetes.utils.KubernetesUtils [] - Kubernetes deployment requires a fixed port. Configuration blob.server.port will be set to 6124 2022-02-26 14:49:17,437 INFO org.apache.flink.kubernetes.utils.KubernetesUtils [] - Kubernetes deployment requires a fixed port. Configuration taskmanager.rpc.port will be set to 6122 2022-02-26 14:49:18,174 INFO org.apache.flink.kubernetes.KubernetesClusterDescriptor [] - Create flink session cluster my-first-flink-cluster successfully, JobManager Web Interface: http://10.0.2.78:8081
Check the port 8081 running the flick session. You can see:
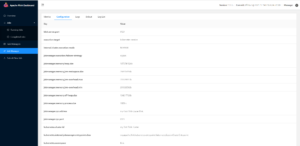
Deployment mode
For production use, we recommend deploying Flink applications in application modes because these modes provide better isolation for applications.
Application Mode
Application Mode requires the user code to be bundled with the Flink image because it runs the main() method of the user code on the cluster. Application Mode ensures that all Flink components are properly cleaned up after the application terminates.
Flink community provides a Basic Docker image , which can be used to bundle user codes:
FROM flink RUN mkdir -p $FLINK_HOME/usrlib COPY /path/of/my-flink-job.jar $FLINK_HOME/usrlib/my-flink-job.jar
After creating and publishing the Docker image under custom image name, you can start the application cluster with the following command:
$ ./bin/flink run-application \
--target kubernetes-application \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dkubernetes.container.image=custom-image-name \
local:///opt/flink/usrlib/my-flink-job.jarlocal is the only supported solution in application mode.
kubernetes. The cluster ID option specifies the cluster name and must be unique. If you do not specify this option, Flink generates a random name.
kubernetes. container. The image option specifies the image of the boot pod.
After you deploy an application cluster, you can interact with it:
# List running job on the cluster $ ./bin/flink list --target kubernetes-application -Dkubernetes.cluster-id=my-first-application-cluster # Cancel running job $ ./bin/flink cancel --target kubernetes-application -Dkubernetes.cluster-id=my-first-application-cluster <jobId>
You can override the configuration set in conf / flick-conf.yaml by passing the key value pair - Dkey=value to bin / flick.
Per-Job Cluster Mode
Flink on Kubernetes does not support per job cluster mode.
Session Mode
You have seen the deployment of the Session cluster in the getting started guide at the top of this page.
Session mode can be executed in two modes:
- Detach mode (default): kubernetes-session.sh Deploy the Flink cluster on Kubernetes and terminate.
- Attachment mode (- execution. Attached = true): kubernetes-session.sh Stay active and allow commands to be entered to control the running Flink cluster. For example, stop stops a running Session cluster. Type help to list all supported commands.
To reconnect to a running session cluster using the cluster ID my first Flink cluster, use the following command:
$ ./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dexecution.attached=trueYou can pass the key value pair - Dkey=value to bin / kubernetes session SH to override the configuration set in conf/flink-conf.yaml.
Stop the running Session cluster
In order to stop running the session cluster with the cluster id of my first Flink cluster, you can delete the Flink deployment or use:
$ echo 'stop' | ./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dexecution.attached=trueRun Flink on k8s for more resources
Configure Flink on Kubernetes
Kubernetes specific configuration options are listed in Configuration page Come on.
Flink use Fabric8 Kubernetes client Communicate with Kubernetes APIServer to create / delete Kubernetes resources (such as Deployment, Pod, ConfigMap, Service, etc.), and observe Pod and ConfigMap. In addition to the above Flink configuration options, there are some features of Fabric8 Kubernetes client Expert options It can be configured through system properties or environment variables.
For example, users can use the following Flink configuration options to set the maximum number of concurrent requests, which allows users to Kubernetes HA Run more jobs in the session cluster when serving. Note that each Flink job consumes 3 concurrent requests.
containerized.master.env.KUBERNETES_MAX_CONCURRENT_REQUESTS: 200 env.java.opts.jobmanager: "-Dkubernetes.max.concurrent.requests=200"
Access Flink's Web UI
Flink's Web UI and REST endpoints can be accessed through kubernetes REST-service. exposed. The type configuration option is exposed in many ways.
ClusterIP: expose services on the internal IP of the cluster. The service can only be accessed within the cluster. If you want to access the JobManager UI or submit a job to an existing session, you need to start the local agent. You can then submit the Flink job to the session or view the dashboard using localhost:8081.
$ kubectl port-forward service/<ServiceName> 8081
NodePort: exposes services on the static port (NodePort) on the IP of each Node Can be used to contact the JobManager service. NodeIP can also be replaced by Kubernetes ApiServer address. You can find its address in your kube configuration file.
LoadBalancer: use the load balancer of the cloud provider to expose services to the outside world. Since the cloud provider and Kubernetes need some time to prepare the load balancer, you may get a NodePort JobManager Web interface in the client log. You can use kubectl get services/-rest to obtain EXTERNAL-IP and manually build the load balancer JobManager Web interface http://:8081.
For more information, please refer to Kubernetes publishing service Official documents.
Depending on your environment, starting a Flink cluster using the LoadBalancer REST service exposure type may make the cluster publicly accessible (usually with the ability to execute arbitrary code).
journal
Kubernetes integrates conf / log4j console Properties and conf / logback console XML is exposed to pod as ConfigMap. Changes to these files will be visible to the newly started cluster.
Access log
By default, JobManager and TaskManager will output logs to the console and / opt/flink/log in each pod at the same time. STDOUT and STDERR output will only be redirected to the console. You can access them in the following ways
$ kubectl logs <pod-name>
If the pod is running, you can also use the kubectl exec - it bash tunnel to enter and view the log or debug the process.
Access the task manager's log
Flink will automatically unassign idle taskmanagers to avoid wasting resources. This behavior makes it more difficult to access the logs of each pod. You can configure resource manager Task manager timeout to increase the time before the idle task manager is released so that you have more time to check the log files.
Dynamically modify log level
If you have configured the logger to Automatically detect configuration changes , you can dynamically adjust the log level by changing the corresponding ConfigMap (assuming that the cluster id is my first Flink cluster):
$ kubectl edit cm flink-config-my-first-flink-cluster
Using plug-ins
In order to use the plug-ins, you must copy them to the correct location in the Flink JobManager/TaskManager pod. You can use Built in plug-in , without installing volumes or building custom Docker images. For example, use the following command to enable the S3 plug-in for your Flink session cluster.
$ ./bin/kubernetes-session.sh
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.13.5.jar \
-Dcontainerized.taskmanager.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.13.5.jarCustom Docker image
If you want to use a custom Docker image, you can configure the option kubernetes container. Image to specify it. The Flink community offers rich Flink Docker image , can be a good starting point. understand How to customize the Docker image of Flink , learn how to enable plug-ins, add dependencies, and other options.
Use key
Kubernetes Secrets is an object that contains a small amount of sensitive data, such as passwords, tokens, or keys. Such information may be put into a specific pod or image in other ways. Flink on Kubernetes can use Secret in two ways:
- Use Secrets as the file in pod;
- Use Secrets as the environment variable;
Use Secrets as the file in pod
The following command will mount the key mysecret under the path / path/to/secret in the started pod:
$ ./bin/kubernetes-session.sh -Dkubernetes.secrets=mysecret:/path/to/secret
The user name and password for the key mysecret can then be found in the files / path/to/secret/username and / path/to/secret/password. For more details, see Kubernetes official documents.
Use Secrets as the environment variable
The following command will expose the key mysecret as an environment variable in the started pod:
$ ./bin/kubernetes-session.sh -Dkubernetes.env.secretKeyRef=\
env:SECRET_USERNAME,secret:mysecret,key:username;\
env:SECRET_PASSWORD,secret:mysecret,key:passwordEnvironment variable SECRET_USERNAME contains the user name and the environment variable SECRET_PASSWORD contains the password for the key mysecret. For more details, see Kubernetes official documents.
High availability settings on K8s
Refer to: https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/deployment/ha/overview/
Manual resource cleanup
Flink uses Kubernetes OwnerReference to clean up all cluster components. All resources created by Flink, including ConfigMap, Service and Pod, set OwnerReference to deployment /. When the deployment is deleted, all related resources will be deleted automatically.
$ kubectl delete deployment/<cluster-id>
Supported K8S versions
At present, all k8s versions larger than 1.9 are supported
namespace
The namespace in Kubernetes divides cluster resources among multiple users through resource quotas. Flink on Kubernetes can use namespaces to start Flink clusters. Namespaces can be accessed through Kubernetes Namespace.
RBAC
Role based access control (RBAC) is a method to adjust the access to computing or network resources according to the role of individual users in the enterprise. Users can configure the RBAC role and service account used by JobManager to access the Kubernetes API server in the Kubernetes cluster.
Each namespace has a default service account. However, the default service account may not have permission to create or delete pods in the Kubernetes cluster. Users may need to update the permissions of the default service account or specify another service account bound to the correct role.
$ kubectl create clusterrolebinding flink-role-binding-default --clusterrole=edit --serviceaccount=default:default
If you don't want to use the default service account, you can use the following command to create a new Flink service account and set the role binding. Then use the configuration option - dkubernets Service account = flip service account enables the JobManager pod to create / delete TaskManager pods and leader ConfigMaps using the flip service account service account. This will also allow TaskManager to monitor leader ConfigMaps to retrieve the addresses of JobManager and ResourceManager.
$ kubectl create serviceaccount flink-service-account $ kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=default:flink-service-account
For more information, see about RBAC authorization Official Kubernetes documentation.
Pod template
Flink allows users to define JobManager and TaskManager pod through template files. This allows direct support for Flink Kubernetes configuration options Unsupported advanced features. Use kubernetes Pod template file specifies the local file containing the pod definition. It will be used to initialize JobManager and TaskManager. The main container should be defined with the name Flink main container. For more information, see the sample pod template.
Fields overwritten by Flink
Some fields of the pod template will be overwritten by Flink. Mechanisms for resolving valid field values can be divided into the following categories:
- Flink definition: user cannot configure.
- User defined: the user is free to specify this value. The Flink framework does not set any additional values. The valid values come from the config option and template.
- Priority: first use the explicit configuration option value, then the value in the pod template, and finally the default value of the configuration option (if not specified).
- Merge with Flink: Flink merges the set value with the user-defined value (see "user defined" priority). In the case of a field with the same name, the Flink value has priority.
For a complete list of pod fields to be overwritten, refer to: Pod Template . All fields defined in the pod template that are not listed in the table will not be affected.
Example of Pod Template
pod-template.yaml
apiVersion: v1
kind: Pod
metadata:
name: jobmanager-pod-template
spec:
initContainers:
- name: artifacts-fetcher
image: artifacts-fetcher:latest
# Use wget or other tools to get user jars from remote storage
command: [ 'wget', 'https://path/of/StateMachineExample.jar', '-O', '/flink-artifact/myjob.jar' ]
volumeMounts:
- mountPath: /flink-artifact
name: flink-artifact
containers:
# Do not change the main container name
- name: flink-main-container
resources:
requests:
ephemeral-storage: 2048Mi
limits:
ephemeral-storage: 2048Mi
volumeMounts:
- mountPath: /opt/flink/volumes/hostpath
name: flink-volume-hostpath
- mountPath: /opt/flink/artifacts
name: flink-artifact
- mountPath: /opt/flink/log
name: flink-logs
# Use sidecar container to push logs to remote storage or do some other debugging things
- name: sidecar-log-collector
image: sidecar-log-collector:latest
command: [ 'command-to-upload', '/remote/path/of/flink-logs/' ]
volumeMounts:
- mountPath: /flink-logs
name: flink-logs
volumes:
- name: flink-volume-hostpath
hostPath:
path: /tmp
type: Directory
- name: flink-artifact
emptyDir: { }
- name: flink-logs
emptyDir: { }This article is an original article from big data to artificial intelligence blogger "xiaozhch5", which follows the CC 4.0 BY-SA copyright agreement. Please attach the original source link and this statement for reprint.
Original link: https://lrting.top/backend/3922/