Summary
DataX is an offline data synchronization tool/platform widely used in Alibaba Group. It implements efficient data synchronization among various heterogeneous data sources, including MySQL, Oracle, SqlServer, Postgre, HDFS, Hive, ADS, HBase, TableStore(OTS), MaxCompute(ODPS), DRDS and so on.
Aliyun has already source this tool, the current version is datax3.0.
Download and install
download
Githup address: https://github.com/alibaba/DataX
If you have the ability to download datax source packages directly from Git clone or Clone or download, you need to compile them manually.
So I chose to pull down the page a little and click
Download the compiled installation package directly
Server configuration
I use ECS-centos deployment datax on the Ali cloud, which generally meets the following points:
- JDK (above 1.8, recommended 1.8)
- Python (recommended Python 2.6.X)
- Apache Maven 3.x (Compile DataX)
1. I'll install JDK first.
Installation with yum
# yum search java|grep jdk # yum install java-1.8.0-openjdk -y
After the installation is complete, you can view the installed version.
[root@stephen ~]# java -version openjdk version "1.8.0_222" OpenJDK Runtime Environment (build 1.8.0_222-b10) OpenJDK 64-Bit Server VM (build 25.222-b10, mixed mode)
2,Python
General centos comes with Python
[root@stephen ~]# python --version Python 2.7.5
3, Apache Maven 3.x
Download address: https://maven.apache.org/download.cgi
I downloaded version 3.6.1 and uploaded it to the server to decompress bin.
[root@stephen ~]# ls apache-maven-3.6.1-bin.tar.gz [root@stephen ~]# tar -xvzf apache-maven-3.6.1-bin.tar.gz
For convenience, create a directory
[root@stephen ~]# mkdir /opt/maven [root@stephen ~]# mv apache-maven-3.6.1/* /opt/maven/ [root@stephen maven]# ln -s /opt/maven/bin/mvn /usr/bin/mvn
Add vi/etc/profile.d/maven.sh
export M2_HOME=/opt/maven export PATH=${M2_HOME}/bin:${PATH}
Look at the version after the creation is complete
[root@stephen maven]# mvn -v Apache Maven 3.6.1 (d66c9c0b3152b2e69ee9bac180bb8fcc8e6af555; 2019-04-05T03:00:29+08:00) Maven home: /opt/maven Java version: 1.8.0_222, vendor: Oracle Corporation, runtime: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64/jre Default locale: en_US, platform encoding: UTF-8 OS name: "linux", version: "3.10.0-514.26.2.el7.x86_64", arch: "amd64", family: "unix"
At this point, the server configuration is complete
Start installation
Upload the downloaded datax package to the server and extract it
[root@stephen opt]# tar -xvzf datax.tar.gz [root@stephen opt]# ls datax bin conf job lib log log_perf plugin script tmp
If you download a compiled installation package, it's basically installed. You can use the self-test script to test it.
python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
When the test shows the following, it indicates that datax has been installed successfully.
[root@stephen datax]# python bin/datax.py job/job.json DataX (DATAX-OPENSOURCE-3.0), From Alibaba ! Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved. Show ellipsis... 2019-08-21 12:08:36.709 [job-0] INFO JobContainer - Task start time: 2019-08-21 12:08:26 End of mission: 2019-08-21 12:08:36 Total Task Time: 10s Task average traffic: 253.91KB/s Record writing speed: 10000rec/s Total number of readout records: 100000 Total number of reading and writing failures: 0
Test usage
Test environment: Aliyun ECS built MySQL 5.7 and PostgreSQL 11.2 database
It is planned to synchronize 100,000 rows of data from a table in MySQL to the PostgreSQL database as follows:
Preparing data
Original table structure in mysql
mysql> show create table datax_test; | Table | Create Table | | datax_test | CREATE TABLE `datax_test` ( `id` int(11) NOT NULL, `name` varchar(20) DEFAULT NULL, `birthday` date DEFAULT NULL, `memo` varchar(32) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
Using data tools to generate 100,000 rows of data
mysql> select count(*) from datax_test; +----------+ | count(*) | +----------+ | 100000 | +----------+
In Postgresql database, the tables with the same structure are built first. The field types need to be converted accordingly, as follows:
stephen=# \d datax_test Table "public.datax_test" Column | Type | Collation | Nullable | Default ----------+--------------------------------+-----------+----------+----------------------------------- id | integer | | not null | name | text | | | birthday | timestamp(0) without time zone | | | NULL::timestamp without time zone memo | text | | | Indexes: "datax_test_pkey" PRIMARY KEY, btree (id) stephen=# select count(*) from datax_test ; count -------- 0 (1 row)
create profile
Configuration templates can be viewed by command: Python datax.py-r {YOUR_READER} - w {YOUR_WRITER}
As follows, read and write data from MySQL to PostgreSQL database
As you can see, when the command is executed, two URL s are given, mysqlreader and postgresqlwriter's json configuration description. You can read the two files carefully to see them.
[root@stephen bin]# python datax.py -r mysqlreader -w postgresqlwriter DataX (DATAX-OPENSOURCE-3.0), From Alibaba ! Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved. Please refer to the mysqlreader document: https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md Please refer to the postgresqlwriter document: https://github.com/alibaba/DataX/blob/master/postgresqlwriter/doc/postgresqlwriter.md Please save the following configuration as a json file and use python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json to run the job. { "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "column": [], "connection": [ { "jdbcUrl": [], "table": [] } ], "password": "", "username": "", "where": "" } }, "writer": { "name": "postgresqlwriter", "parameter": { "column": [], "connection": [ { "jdbcUrl": "", "table": [] } ], "password": "", "postSql": [], "preSql": [], "username": "" } } } ], "setting": { "speed": { "channel": "" } } } }
Configure json files based on your own database information on both sides
{ "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "column": ["id" , "name" , "birthday" , "memo"], #Fields that need to be synchronized can be written as * to match all fields "connection": [ { "jdbcUrl": ["jdbc:mysql://172.16.21.167:3306/test"], # MySQL data source access address, and the database in which it is located "table": ["datax_test"] # The table name of the destination table. Support writing to one or more tables. When configuring multiple tables, you must ensure that all table structures are consistent. } ], "password": "mysql", #Password "username": "root", #user "where": "" } }, "writer": { "name": "postgresqlwriter", "parameter": { "column": ["id" , "name" , "birthday" , "memo"], #Fields at the PG end "connection": [ { "jdbcUrl": "jdbc:postgresql://172.16.21.167:5432/stephen", #PG Data Source Address and Data Name "table": ["datax_test"] #Table names in PG } ], "password": "postgres", # Password "postSql": [], "preSql": [], "username": "postgres" # user } } } ], "setting": { "speed": { "channel": "5" #Concurrent channels, depending on their own database performance, are not recommended for more than 32 general databases } } } }
Perform synchronization
Perform data synchronization using the json file just prepared
[root@stephen datax]# python bin/datax.py job/mysql2pg.json DataX (DATAX-OPENSOURCE-3.0), From Alibaba ! Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved. 2019-08-21 15:52:26.746 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl 2019-08-21 15:52:26.754 [main] INFO Engine - the machine info => ........Display ellipsis.......... [total cpu info] => averageCpu | maxDeltaCpu | minDeltaCpu -1.00% | -1.00% | -1.00% [total gc info] => NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime Copy | 1 | 1 | 1 | 0.049s | 0.049s | 0.049s MarkSweepCompact | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s 2019-08-21 15:52:37.605 [job-0] INFO JobContainer - PerfTrace not enable! 2019-08-21 15:52:37.605 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2488939 bytes | Speed 243.06KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 5.170s | All Task WaitReaderTime 0.848s | Percentage 100.00% 2019-08-21 15:52:37.606 [job-0] INFO JobContainer - //Task start time: 2019-08-21 15:52:26 //End of mission: 2019-08-21 15:52:37 //Total Task Time: 10s //Task average traffic: 243.06KB/s //Record writing speed: 10000rec/s //Total number of readout records: 100000 //Total number of reading and writing failures: 0
Synchronization success! Go to Postgresql to see if the data has been synchronized
stephen=# select count(*) from datax_test ; count -------- 100000 (1 row) stephen=# stephen=# select * from datax_test limit 10 ; id | name | birthday | memo ----+------------+---------------------+-------------- 0 | g=14}9v7x | 2006-11-25 00:00:00 | ujGPtH/I\r 1 | *O | 2015-12-14 00:00:00 | Vg\r 2 | kD}ExP6d!0 | 2001-09-07 00:00:00 | ?\r 3 | ll3--zr | 2008-12-10 00:00:00 | |+\r 4 | Mj!j5~_~ | 2010-11-04 00:00:00 | ypE@\r 5 | mJW | 2004-08-25 00:00:00 | *Ish&NS>4k\r 6 | 65xl | 2003-09-25 00:00:00 | |HAtL2\r 7 | %6V6c7*4 | 2009-06-16 00:00:00 | dS|Ul6H\r 8 | 8:0O | 2006-01-25 00:00:00 | rOA10>zL|\r 9 | CHjFqa_ | 2018-09-26 00:00:00 | 4TY-xX\r
summary
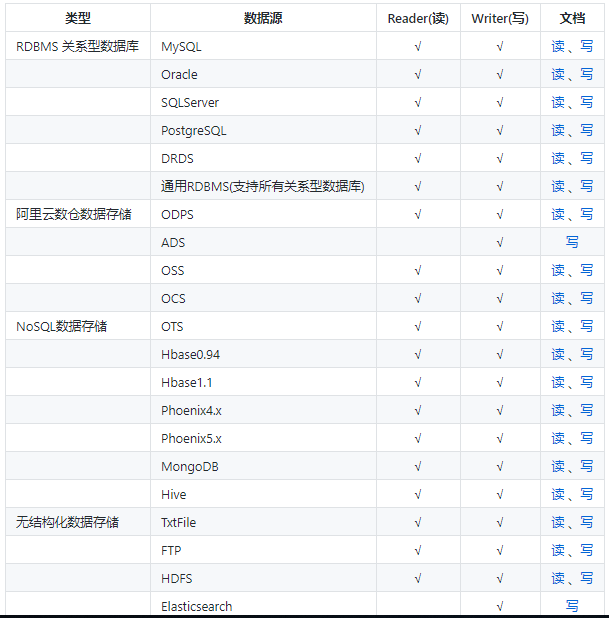
Officially, datax can read and write between the following data sources, basically covering the products about databases seen and heard in daily life.
I can only say, a compliment, good stuff. Migrate data to find it