Why downgrade
When developing highly concurrent systems, there are many methods to protect the system, such as caching, degradation, current limiting and so on. The following describes the downgrade strategy. When the system traffic increases, the service response time is long, or non core services affect the performance of core services. If you need to ensure the availability of core services, you need to downgrade non core services. The system can automatically degrade according to key data or configure switches for manual degradation.
Degradation policy classification
Degradation can be divided into automatic switch degradation and manual switch degradation according to whether it can be automated. According to the read-write function, it can be divided into read service degradation and write service degradation. From the whole link accessed by the user, there will be the following multi-level links
Degradation strategy:
-
Page degradation: when a promotion is in progress, some pages occupy scarce resources, and the entire page can be degraded; When some non core services such as recommendation information are loaded asynchronously on the page, if the response becomes slow, degradation can be carried out.
-
Service read degradation: generally, there will be a cache in distributed applications. Data with high query frequency will generally be obtained from the cache. However, if some data is obtained directly from the cache, it may cause customer complaints. For example, the user account balance is generally only obtained from the DB and read from the main database. When a big promotion comes, it can be downgraded to obtain balance information from the library or cache.
-
Service write degradation: in the second kill rush purchase business, due to the large number of concurrent transactions. In addition to coping with the upper limit flow and queue at all levels, you can also downgrade the write library. You can perform inventory deduction in memory. When the peak has passed, you can asynchronously synchronize it to the DB for deduction.
-
Other types: when the system is busy, the crawler traffic can be directly discarded. After the peak, it will recover automatically. In the second kill service, the risk control system can recognize the brush / robot, and then directly perform denial of service to these users.
Automatic switch degradation
Automatic degradation refers to the degradation operation based on system load, resource usage and other indicators.
- Timeout degradation
When the response of the accessed database / HTTP service / remote call is slow, if this service is not a core service, it can be automatically degraded after timeout. For example, the comment information in the product details page can be directly degraded after the query timeout, and then the front end can query the separate comment information.
- Count the number of failures
When the system relies on external interface calls and fails for a certain number of times, it can be degraded automatically. Then start an asynchronous thread to detect whether to recover, and automatically cancel the degradation after recovery (the bank / third-party channel system fails).
- Fault degradation
Most of these failures refer to internal system failures. When the system fails, the processing schemes can include: default value (inventory is available by default), bottom data (the advertising system hangs and can directly return to the previously prepared static page), cache, etc.
- Current limiting degradation
When the system load is too large, you can use queued pages, no goods or error pages. Some technical solutions for degradation will be used. Please refer to the author's distributed system degradation strategy.
Manual switch degradation
During the promotion, some problems can be found through online monitoring. If the system cannot be degraded automatically at this time, manual intervention is required. For example, some background scheduled tasks will occupy part of the system resources. At this time, if the system is running under high load, you can manually stop the scheduled task. Restart after the peak value has passed. Normally, the switch configuration file will be placed in the configuration center. The implementation of the configuration center can be realized through ZooKeeper, Redis, consult, etc.
In addition, for the new system, the drainage can be controlled by the switch when the gray test is carried out. When a problem is found in the gray environment, you can switch to the online environment through switch degradation.
Downgrade using hystrix
Hystrix was first opened by Netflix (as everyone who has seen American dramas knows, it is a giant company in American drama film and television production). Later, Spring Cloud Hystrix realized a series of service protection functions such as circuit breaker and thread isolation based on this framework. The goal of this framework is to control the nodes accessing remote systems, services and third-party libraries, Thus, delay and fault provide more powerful fault tolerance. Hystrix has powerful functions such as service degradation, service fusing, thread and signal isolation, request caching, request merging and service monitoring. It plays a microservice protection mechanism to prevent a unit from failure, which leads to dependency, fault spread, and finally the paralysis of the whole system.
- Problem generation
Suppose we have a service and then need to call the order service to obtain the order information, but the order service call fails (service paralysis). At this time, we can't return null or report an error, which will easily lead to the exception of the whole call chain and even the paralysis of the whole service. Therefore, we can provide degradation and remote request query failure (query db), But we can downgrade the query cache.
Introducing pom:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
- Realized by annotation
controller:
@RestController
public class OrderController {
@Resource
private OrderService orderService;
/**
* Get order information
*/
@GetMapping("/order")
public String getOrderInfo(@RequestParam Long orderId) {
return orderService.orderDetail(orderId);
}
}
Service:
@Service
@EnableHystrix
public class OrderService {
@HystrixCommand(fallbackMethod = "fallbackException")
public String orderDetail(Long orderId) {
//Simulate remote call of order details service
return remoteOrderDetail(orderId);
}
/**
* Remote call order failed to get order details from cache
*/
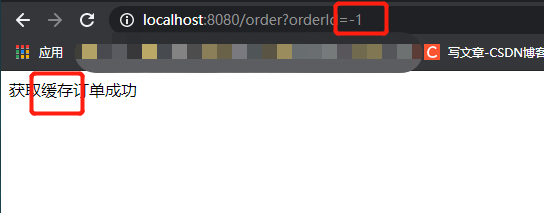
public String fallbackException(Long orderId) {
//Simulate cache query
return "Get cached order succeeded";
}
public String remoteOrderDetail(Long orderId) {
//Simulate calling remote order detail service
if (orderId < 0) {
throw new IllegalArgumentException("Illegal order number");
}
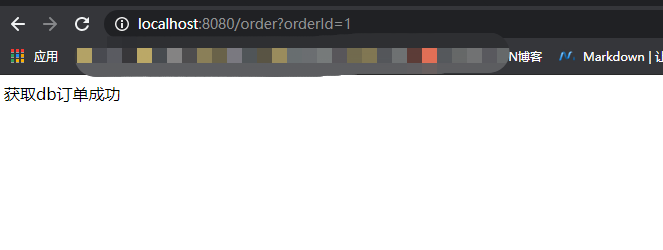
return "obtain db Order succeeded";
}
}
Start demotion with @ EnableHystrix annotation, and then specify the demotion method with @ HystrixCommand(fallbackMethod = "fallbackException").
Verification results:
Normal conditions:
Abnormal conditions:
- Custom implementation
- Custom inherit HystrixCommand
package com.lht.boot.distribution.hystrix;
import com.netflix.hystrix.HystrixCommand;
import com.netflix.hystrix.HystrixCommandGroupKey;
import com.netflix.hystrix.HystrixCommandProperties;
/**
* custom
*/
public class HystrixStubbedFallback extends HystrixCommand<String> {
public HystrixStubbedFallback() {
super(setter());
}
private static Setter setter() {
HystrixCommandProperties.Setter commandProperties = HystrixCommandProperties
.Setter()
.withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.THREAD)
//Whether degradation is enabled. If enabled, it will be called when timeout or exception occurs
.withFallbackEnabled(true)
//If the semaphore configuration of the fallback method exceeds the semaphore configuration, the getFallback method will not be called again, but will fail quickly
.withFallbackIsolationSemaphoreMaxConcurrentRequests(100)
//When the isolation policy is THREAD, whether to interrupt when the execution THREAD times out, that is, Future#cancel(true) processing. The default is false
.withExecutionIsolationThreadInterruptOnFutureCancel(true)
//When the isolation policy is THREAD, whether to interrupt when the execution THREAD times out. The default value is true
.withExecutionIsolationThreadInterruptOnTimeout(true)
//Whether to enable the execution timeout mechanism. The default value is true
.withExecutionTimeoutEnabled(true)
//The execution timeout is 1000 ms by default. If threads are isolated during command and withExecutionIsolationThreadInterruptOnTimeout=true is configured
//Execute thread interrupt processing. If the command is semaphore isolation, terminate the operation. Because semaphore isolation and the main thread are executed in one thread, it will not interrupt thread processing, so
//Whether to use semaphore isolation is adopted according to the actual situation, especially in the case of network access
.withExecutionTimeoutInMilliseconds(1000);
return Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"))
.andCommandPropertiesDefaults(commandProperties);
}
/**
* Method of triggering service
*/
@Override
protected String run() {
throw new RuntimeException("failure for example"); //Simulated exceptions are used to trigger rollback
}
/**
* run Execute after method fails
*/
@Override
protected String getFallback() {
return "in stock";
}
}
Verification results:
@Test
public void test() {
HystrixStubbedFallback command = new HystrixStubbedFallback();
//results of enforcement
String result = command.execute();
//Whether the execution failed, such as throwing an exception
boolean failedExecution = command.isFailedExecution();
//Whether the response timed out
boolean responseTimedOut = command.isResponseTimedOut();
//Is it the response returned by getFallback
boolean responseFromFallback = command.isResponseFromFallback();
//Gets the exception executed after the failure. That is, the exception thrown by the run method
Throwable failedExecutionException = command.getFailedExecutionException();
System.out.println("Whether the response timed out: " + responseTimedOut);
System.out.println("Did the execution fail: " + failedExecution);
System.out.println("Is it getFallback Response returned: " + responseFromFallback);
System.out.println("Returned results: " + result);
System.out.println("Get exception executed after failure: "+failedExecutionException.getMessage());
}

Alibaba sentinel downgrades
- What is Sentinel?
With the popularity of microservices, the stability between services and services becomes more and more important. Sentinel takes traffic as the starting point to protect the stability of services from multiple dimensions such as traffic control, fuse degradation and system load protection.
- Using Sentinel
Be sure to read the official website before use Sentinel official website
Here we use nacos to persist the degradation rules to nacos.
- pom
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<!-- Sentinel in the light of Nacos After adaptation, the bottom layer can be used Nacos Configure data sources as rules -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
- yml configuration
spring:
cloud:
sentinel:
transport:
dashboard: XXXXXXXXXX:8070 #Configure sentinel dashboard address
port: 8721 #Specify the port for communication and control. The default value is 8719. If it is not set, it will automatically start scanning from 8719 and + 1 in turn until an unoccupied port is found
datasource:
#Grade is the name of the data source and can be modified at will
degrade:
nacos:
server-addr: 10.100.217.145:8848
dataId: ${spring.application.name}-degrade-rules
groupId: SENTINEL_GROUP
rule-type: degrade
Define a Controller and write the name of the rule resource you want to define through the annotation @ SentinelResource, SentinelResource annotation support document
/**
* Query by id
*
* @param id Primary key
* @return Query result topic
*/
@ApiOperation("according to id Query (downgrade)")
@ApiImplicitParams({
@ApiImplicitParam(paramType = PATH, dataType = INTEGER, name = "id", value = "Primary key id", required = true)
})
@GetMapping("/{id}")
@ResponseBody
@SentinelResource(value = "tcly-operations-center-degrade-rules", blockHandlerClass = TopicExceptionUtils.class, blockHandler = "queryException")
public CommonResult<TopicVO> query(@PathVariable Long id) {
if (id <= 0) {
//An exception is thrown when the simulation interface is running
throw new IndexOutOfBoundsException();
}
return CommonResult.success(entityToVo(service.getById(id)));
}
Exception handling code:
public class TopicExceptionUtils {
/**
* Hide constructor
*/
private TopicExceptionUtils(){}
/**
* Topic query degradation processing
* @param id query criteria
* @param blockException Degradation exception
* @return Failure result
*/
public static CommonResult<TopicVO> queryException(Long id, BlockException blockException) {
return CommonResult.failed("according to id: " + id + "Query failed, downgrade");
}
The above is all the code;
Next, configure rules through sentinel dashboard:
The resource name is the value of @ SentinelResource:
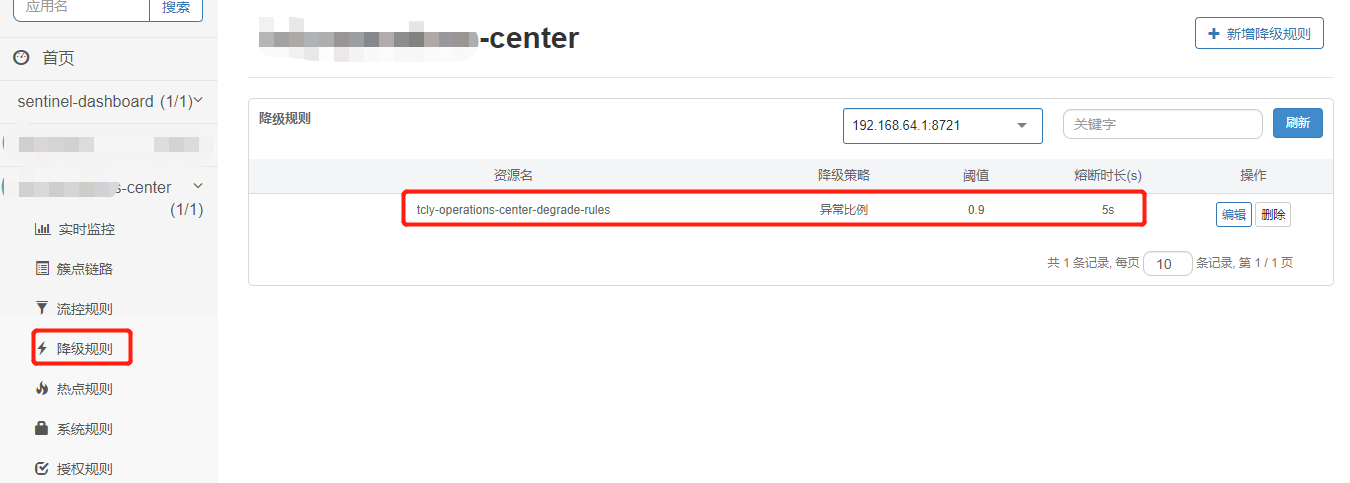
After the dashboard is configured, the dashboard will automatically synchronize to nacos through

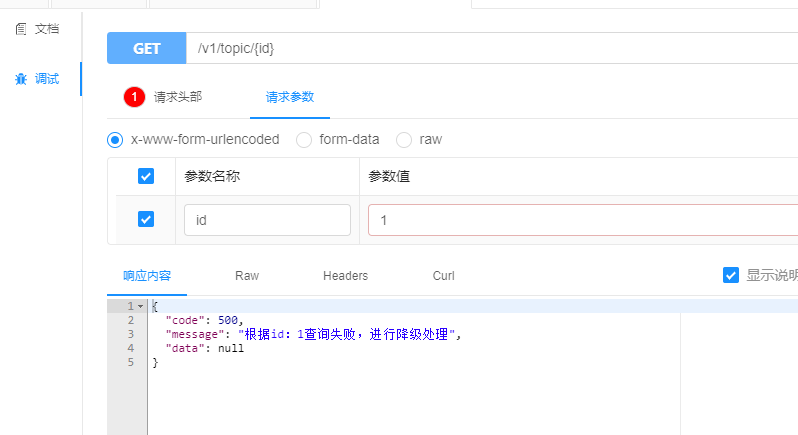
Call test:
Operation failure is a normal return
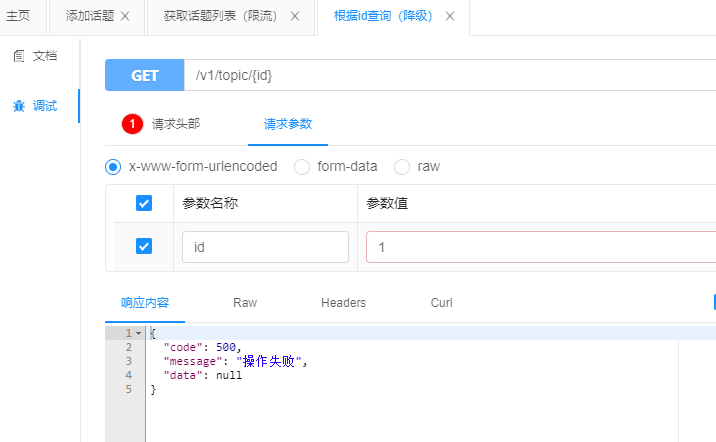
Degradation occurred