Recently, cluster storage has been skewed, with individual node storage exceeding 85%. After balancer is started, the effect is obvious, but sometimes balancer startup can not solve the problem. From the operation and maintenance stage, we know that there is such a balancer. Today, we finally hold our breath to see what happened to the balancer. Version 1.0.3
Firstly, balance is started as an independent program at org. apache. Hadoop. hdfs. server. balance. It was inside namenode before I heard it. I haven't seen it before.
public static void main(String[] args) {
try {
System.exit( ToolRunner.run(null, new Balancer(), args) );
} catch (Throwable e) {
LOG.error(StringUtils.stringifyException(e));
System.exit(-1);
}
} I wipe, look, is familiar with ToolRunner, it goes without saying that Balancer is a tool, rewriting the run method.
Go in to balance run and see.
run code is relatively long, not all of them are posted out, take a step by step look at it.
init(parseArgs(args)); First, parse the program to pass parameters, and then execute the init method. What program parameters? Simple, because balance is bin/start-balancer.sh-threshold 5, see, there is a threshold that needs to be specified by the administrator.
What's the threshold? Next, the parsing parameter is to get the value of our threshold, which is 5, so pass 5 to init.
this.threshold = threshold;
this.namenode = createNamenode(conf);//Get the cluster namenode object
this.client = DFSClient.createNamenode(conf);//Get a client object
this.fs = FileSystem.get(conf);//File System Objects That's the main method of init, not to mention the rest of security authentication. Here's the agent of namenode, the client of hdfs, and the object of HDFS file system. Okay, go on:
out = checkAndMarkRunningBalancer();
/*There can only be one balance at any time. How to judge? Write a file / system/balancer.id to the cluster, and when it is written, it will return an existing error to null.
* It should be written in byte data, the machine information where balance is located.
* */
if (out == null) {
System.out.println("Another balancer is running. Exiting...");
return ALREADY_RUNNING;
} Here, check that the balancer process is already working. This method is very simple. The program is written to hdfs / system/balancer.id file to write something, which is balancer's machine information:
private OutputStream checkAndMarkRunningBalancer() throws IOException {
try {
DataOutputStream out = fs.create(BALANCER_ID_PATH);
out. writeBytes(InetAddress.getLocalHost().getHostName());
out.flush();
return out; Did you see? Then the process of writing to determine whether the file exists, if there are other balancers running, because balancers are created at startup and deleted at exit. This is a way, but if we delete it manually when running, we can still start balancer, so there are multiple balancers, which is harmful, let's talk about later.
With such a simple judgment, balance can start shamefully and enter a big circle. Until the cluster is "balanced", the process exits.
ok, come in and have a look.
while (true ) {
/* get all live datanodes of a cluster and their disk usage
* decide the number of bytes need to be moved
*/
long bytesLeftToMove = initNodes();
if (bytesLeftToMove == 0) {
System.out.println("The cluster is balanced. Exiting...");
return SUCCESS;
} else {
LOG.info( "Need to move "+ StringUtils.byteDesc(bytesLeftToMove)
+" bytes to make the cluster balanced." );
}
/* Decide all the nodes that will participate in the block move and
* the number of bytes that need to be moved from one node to another
* in this iteration. Maximum bytes to be moved per node is
* Min(1 Band worth of bytes, MAX_SIZE_TO_MOVE).
*/
long bytesToMove = chooseNodes();
//At this point, the corresponding relationship between the source and the end, i.e. the transmission plan, has been established.
if (bytesToMove == 0) {
System.out.println("No block can be moved. Exiting...");
return NO_MOVE_BLOCK;
} else {
LOG.info( "Will move " + StringUtils.byteDesc(bytesToMove) +
"bytes in this iteration");
}
formatter.format("%-24s %10d %19s %18s %17s\n",
DateFormat.getDateTimeInstance().format(new Date()),
iterations,
StringUtils.byteDesc(bytesMoved.get()),
StringUtils.byteDesc(bytesLeftToMove),
StringUtils.byteDesc(bytesToMove)
);
/* For each pair of <source, target>, start a thread that repeatedly
* decide a block to be moved and its proxy source,
* then initiates the move until all bytes are moved or no more block
* available to move.
* Exit no byte has been moved for 5 consecutive iterations.
*/
if (dispatchBlockMoves() > 0) {
notChangedIterations = 0;
} else {
notChangedIterations++;
if (notChangedIterations >= 5) {
System.out.println(
"No block has been moved for 5 iterations. Exiting...");
return NO_MOVE_PROGRESS;
}
}
// clean all lists
resetData();
try {
Thread.sleep(2*conf.getLong("dfs.heartbeat.interval", 3));
} catch (InterruptedException ignored) {
}
iterations++;
} I wipe, first calculate how much data to balance, this part is completed in the initNodes method, and then chooseNodes, establish the transmission scheme. 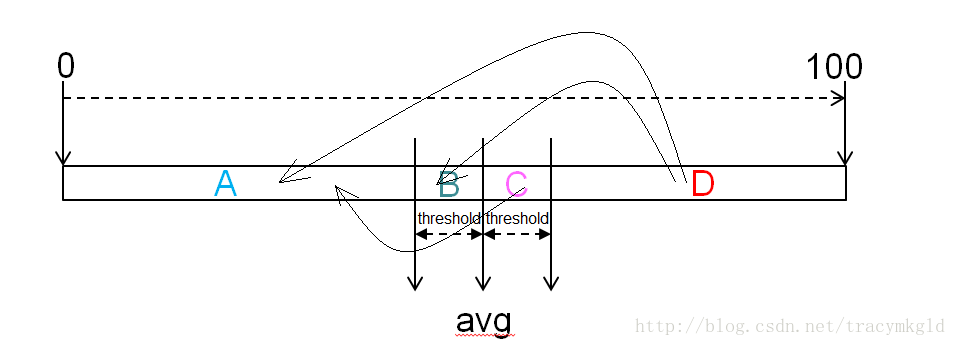
Look at the figure above. 0-100 represents the storage rate of the cluster. avg is the average storage value of the cluster (all live dns). balancer reports data to namenode through client request. namenode returns data node Info to balancer. balancer calculates the average storage rate of the cluster. DfsUsed of all live DN adds and divides the capacity of all DN (data.dir capacity of all DN configurations). In this way, the avg and threshold on the graph are passed in at startup, which means the floating value of cluster average storage rate, such as threshold=5, which means the floating value of up and down 5%. It's easy to understand, right? ok. Look at the figure above. After thresholds are given, the DN with different storage usage is divided into four kinds. It's not ABCD. Needless to say, the DN in D region is relatively high. For example, average 70, threshold 5, D region is above 75% dn, right; A is below 65% dn.
The initNodes method is to divide dn into ABCD IV. As you can see, the initNodes method returns a value called the total amount of data to be moved. What is the data to be moved?
Looking at the figure above, the DN in the D region can be said to have data that needs moving. For example, in the previous example, the average value is 70, the threshold is 5. If a dn store is 85%, the data that needs moving is 85 - (70 + 5) = 10, 10% of the total amount of the machine itself. ok, the sum of these quantities in D is called overLoaded Bytes, the overloaded data.
At this point, the initNodes method is not finished yet, and we need to calculate underLoaded Bytes - no load, I erase, the name of their own, to make sense of Ha. What is underLoaded Bytes? This corresponds to overload data, that is, in Area A, where the single-machine storage rate of DN is lower than the average cluster level, or the previous example, if there is a dn storage rate of 50% in Area A, then 70-5-50=15, that is to say, 15% of the space of this DN is empty, and it can also fill things in. Under Loaded Bytes is the sum of all DN data in Area A.
Now there are overloaded data and no-load data. Okay, what about the total amount of data to be moved? balancer takes a larger value. Whether overloaded or unloaded, it moves a little more. Cluster is more balanced. Ha-ha, that's probably what it means. balancer does not end in one round, as you will see later, it's a big one. The process of iteration.
ok, after initialization, we know how much data the cluster needs to move, but how? This step is tantamount to knowing the needs, and the next step is to develop feasible solutions.
The chooseNodes method does this.
In the previous initnodes, four sets need to be counted. At this time, a class is needed to describe the node that needs to transfer data, BalancerDatanode. When this class is created, three parameters are passed in. One is the datanodeInfo object, which is the complete information of dn. Then the average utilization rate and threshold of the cluster are notified. Sue it, this Balancer Datanode I wiped started to calculate, according to the figure above, calculate the maximum movable data.
private BalancerDatanode(
DatanodeInfo node, double avgUtil, double threshold) {
datanode = node;
utilization = Balancer.getUtilization(node);
/*Well, this threshold is the fluctuation of the average cluster utilization. The avgUtil passed in ahead is the percentage multiplied by 100, which means the threshold is the percentage.*/
if (utilization >= avgUtil+threshold//If the current cluster is 70% and threshold is 10, then the dn is greater than 80 or less than 60
|| utilization <= avgUtil-threshold) {
maxSizeToMove = (long)(threshold*datanode.getCapacity()/100);
//The size of the data to be moved is 10% of its configuration capacity, which is equal to the threshold.
} else {//Otherwise, if between 60 and 80, the absolute value of x-70 needs to be moved, such as 65, then 5% of the data needs to be moved, which is less than the threshold value.
maxSizeToMove =
(long)(Math.abs(avgUtil-utilization)*datanode.getCapacity()/100);
}
if (utilization < avgUtil ) {//If the cluster as a whole is very high, but the single machine is lighter than the cluster.
maxSizeToMove = Math.min(datanode.getRemaining(), maxSizeToMove);
}
maxSizeToMove = Math.min(MAX_SIZE_TO_MOVE, maxSizeToMove);
/*The maximum amount of data to be moved by a machine should not exceed 10G.*/
} For the nodes in area D or A, the maximum movable data is the threshold size. If in area BC, the absolute value of the difference between them and the average value is taken as the maximum movable data, which obviously does not exceed the threshold size.
If the capacity of dn is 20T, what is 10%? 2T, I wipe such a large amount of data is not allowed to be moved at one time, the system has been limited, the maximum number of movable at one time can not exceed 10G.
There is also the maximum removable size, for the AB area of the node is the maximum receivable data, in the CD area is the maximum amount of data that can be sent away.
ok, Balancer Datanode knows, from the constructor point of view, the nodes of four regions are applicable, that is not enough now, now want to build a specific implementation plan, what is the implementation plan, is a clear source-end pair.
private void chooseTargets(
Iterator<BalancerDatanode> targetCandidates, boolean onRackTarget ) {
for (Iterator<Source> srcIterator = overUtilizedDatanodes.iterator();
srcIterator.hasNext();) {//Take the maximum src as the object to move, move into the low storage
Source source = srcIterator.next();
while (chooseTarget(source, targetCandidates, onRackTarget)) {
}//Find all the nodes that can receive data in a round
if (!source.isMoveQuotaFull()) {
srcIterator.remove();
}
}
return;
} Source s in Area D first look for target s in Area A, because Area A is the richest and Area D is the poorest, which makes it easier to balance. Before going on, I have to add that the object of Balancer Datanode, which describes the node that needs to transfer or receive data, must have a data to control its transferred amount. As mentioned earlier, if zone D has 2T to send, it will take many times, so the next one will be less. There is a member in this matter. Recorded, it is scheduled Size that represents the total amount of data received or sent away. Okay, go on:
The specific process of finding a target is as follows: traverse the source, take out one, and check one by one from the candidate set of the target, that is, a source can correspond to multiple targets, how can the two sets match, only two cycles to match one by one! How to match?
For example, to get a node in D area, and then to get a node in A area, first to see how much data two nodes can move, what is mobile data, D is able to send away, A is able to receive, how to calculate this? The former said scheduled Size, subtract this from the maximum movable value, and then compare src and target, which small, according to which, or else can send more, can receive smaller, press larger, will not break the rules!
At this point, bind the target and the amount of data it will send away in this iteration to a NodeTask object and add it to the source dispatch queue. Sorce sends data back in this delivery queue. Any target added to the delivery queue by source will increase the received amount, and source will increase the delivery amount accordingly. Although this thing is still planned, just executing the plan and delivering it unsuccessfully, it still needs to be recorded in an iteration. Then add all the sources and targets that have established the delivery plan to the balancer managed sources and targets collections, respectively.
Delivery direction and source selection are indicated by arrows on the graph.
It should be noted that the first is to establish a delivery relationship with the same rack, and then to establish a delivery relationship between the racks, because when the inclination is serious, the delivery before the rack will basically destroy the rack placement strategy, which is not conducive to data security.
In the previous initNodes, the total amount of data that a CD node needs to send away is calculated, which is a gross amount, that is, the amount you want to move, but not necessarily the total amount of data that can be dispatched. The chooseNodes method returns all the data to be dispatched by the dispatch plan. This amount is the total amount of data actually transmitted in an iteration. The front one is called need to move, and the plan is called will to move.
Now that the iteration plan is completed, the delivery will be executed.