introduce
Tablib is a format-independent table dataset database written in Python. It allows pythonical import, export, and manipulation of tabular datasets. Advanced functionality includes isolation, dynamic columns, tag/filter, and seamless format import/export.
install
pip install tablib
You can also choose to install more dependencies to get more import/export formats:
pip install "tablib[xlsx]"
Or all possible formats:
pip install "tablib[all]"
Amount to:
pip install "tablib[html, pandas, ods, xls, xlsx, yaml]"
Quick Start
Create Dataset
tablib's set of data for Dataset Express.
Establish tablib.Dataset object
data = tablib.Dataset()
Now you can start filling this Dataset Objects and data.
add rows
Suppose you want to collect a simple list of names:
# collection of names
names = ['Kenneth Reitz', 'Bessie Monke']
for name in names:
# split name appropriately
fname, lname = name.split()
# add names to Dataset
data.append([fname, lname])
View the dataset Dataset.dict:
>>> data.dict
[('Kenneth', 'Reitz'), ('Bessie', 'Monke')]
Add Title
Set Dataset.headers:
data.headers = ['First Name', 'Last Name']
Now the data looks a little different.
>>> data.dict
[{'Last Name': 'Reitz', 'First Name': 'Kenneth'},
{'Last Name': 'Monke', 'First Name': 'Bessie'}]
Add Columns
Now that we have a basic Dataset, add a list of ages to it:
data.append_col([22, 20], header='Age')
>>> data.dict
[{'Last Name': 'Reitz', 'First Name': 'Kenneth', 'Age': 22},
{'Last Name': 'Monke', 'First Name': 'Bessie', 'Age': 20}]
Import data
Create one by importing a pre-existing file tablib.Dataset Object:
with open('data.csv', 'r') as fh:
imported_data = Dataset().load(fh)
This will detect the incoming data type and import it using the appropriate formatter. Therefore, you can import from a variety of different file types.
When the format is csv, tsv, dbf, xls or xlsx and the data source has no header, you should import it as follows:
with open('data.csv', 'r') as fh:
imported_data = Dataset().load(fh, headers=False)
Export Data
Tablib's killer function is to convert Dataset objects into multiple formats.
To csv format:
>>> data.export('csv')
Last Name,First Name,Age
Reitz,Kenneth,22
Monke,Bessie,20
To json format:
>>> data.export('json')
[{"Last Name": "Reitz", "First Name": "Kenneth", "Age": 22}, {"Last Name": "Monke", "First Name": "Bessie", "Age": 20}]
To yaml format:
>>> data.export('yaml')
- {Age: 22, First Name: Kenneth, Last Name: Reitz}
- {Age: 20, First Name: Bessie, Last Name: Monke}
To Microsoft Excel format:
>>> data.export('xls')
<redacted binary data>
To DataFrame Format:
>>> data.export('df')
First Name Last Name Age
0 Kenneth Reitz 22
1 Bessie Monke 21
Select Rows and Columns
Rows can be sliced and accessed like standard Python lists.
>>> data[0]
('Kenneth', 'Reitz', 22)
Access columns through column names.
>>> data['First Name'] ['Kenneth', 'Bessie']
View column names and access columns through indexes.
>>> data.headers ['Last Name', 'First Name', 'Age'] >>> data.get_col(1) ['Kenneth', 'Bessie']
The results of a column are presented as a list that can be further processed, such as calculating the average age.
>>> ages = data['Age'] >>> float(sum(ages)) / len(ages) 21.0
Delete rows and columns
Delete a column:
>>> del data['Col Name']
Delete rows by range:
>>> del data[0:12]
Dynamic Column
(New 0.8.3 functionality) The dynamic column is a single callable object (e.g. function).
Insert a dynamic column into the Dataset object as follows, where the function random_grade generates a random score.
import random
def random_grade(row):
return random.randint(60,100)
data.append_col(random_grade, header='Grade')
Output results:
>>> data.export('df')
First Name Last Name Age Grade
0 Kenneth Reitz 22 89
1 Bessie Monke 20 74
When adding a dynamic column, the first parameter passed to a given callable item is the current data row. You can use this method to perform calculations on rows of data.
For example, we can use available data to guess students'gender.
def guess_gender(row):
"""Calculates gender of given student data row."""
m_names = ('Kenneth', 'Mike', 'Yuri')
f_names = ('Bessie', 'Samantha', 'Heather')
name = row[0]
if name in m_names:
return 'Male'
elif name in f_names:
return 'Female'
else:
return 'Unknown'
Add this function to the dataset as a dynamic column:
>>> data.append_col(guess_gender, header="Gender")
>>> data.export('df')
First Name Last Name Age Grade Gender
0 Kenneth Reitz 22 62 Male
1 Bessie Monke 20 100 Female
Filtering datasets using tags
New 0.9.0 functionality.
When constructing a Dataset object, you can filter the Dataset by specifying the tags parameter. This is useful for separating rows of data based on any standard. e.g. Construct the following Dataset.
students = tablib.Dataset() students.headers = ['first', 'last'] students.rpush(['Kenneth', 'Reitz'], tags=['male', 'technical']) students.rpush(['Daniel', 'Dupont'], tags=['male', 'creative' ]) students.rpush(['Bessie', 'Monke'], tags=['female', 'creative'])
>>> students.df
first last
0 Kenneth Reitz
1 Daniel Dupont
2 Bessie Monke
There is now additional metadata on the row to easily filter the data Dataset. For example, look at male students:
>>> students.filter(['male']).df
first last
0 Kenneth Reitz
1 Daniel Dupont
By default, when the tag list is passed, the filtered dataset is either logical or Get Filtered.
>>> students.filter(['famale','creative']).df
first last
0 Daniel Dupont
1 Bessie Monke
You can logically "get filtered datasets" and "get filtered datasets" as follows.
>>> students.filter('male').filter('creative').json
'[{"first": "Daniel", "last": "Dupont"}]'
In the above operation, the original Dataset was not changed.
>>> students.df
first last
0 Kenneth Reitz
1 Daniel Dupont
2 Bessie Monke
Open Excel workbook and read the first sheet
Open a workbook containing Excel2007 and later versions of a single worksheet (or a workbook containing multiple worksheets but only the first one):
data = tablib.Dataset()
with open('site.xlsx', 'rb') as fh:
data.load(fh, 'xlsx')
print(data)
name |site |age ------|-----------------|--- Google|www.google.com |90 Runoob|www.runoob.com |40 Taobao|www.taobao.com |80 Wiki |www.wikipedia.org|98
Save a worksheet to an Excel Workbook
with open('class.xlsx', 'wb') as f:
f.write(data.export('xlsx'))
Save multiple sheets to Excel Workbook
It is common to save multiple spreadsheets as an excel file (called a workbook) when working with a large number of datasets. Tablib is quite convenient to save Excel workbooks with multiple worksheets.
Suppose you have three datasets dataset1, dataset2, and dataset3, add them to the Databook object, and export them:
book = tablib.Databook((dataset1, dataset2, dataset3))
with open('students.xlsx', 'wb') as f:
f.write(book.export('xlsx'))
Note: Make sure the output file is opened in binary mode.
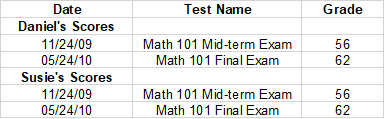
separator
0.8.2 New Version Functions.
When you build a spreadsheet, you usually need to create an empty row containing upcoming data information. So,
daniel_tests = [('11/24/09', 'Math 101 Mid-term Exam', 56.),
('05/24/10', 'Math 101 Final Exam', 62.)]
suzie_tests = [('11/24/09', 'Math 101 Mid-term Exam', 56.),
('05/24/10', 'Math 101 Final Exam', 62.)]
# Create new dataset
tests = tablib.Dataset()
tests.headers = ['Date', 'Test Name', 'Grade']
# Daniel's Tests
tests.append_separator('Daniel\'s Scores')
for test_row in daniel_tests:
tests.append(test_row)
# Susie's Tests
tests.append_separator('Susie\'s Scores')
for test_row in suzie_tests:
tests.append(test_row)
# Write spreadsheet to disk
with open('grades.xls', 'wb') as f:
f.write(tests.export('xls'))
The results grades.xls are as follows:
Advanced Usage API
Dataset object
class tablib.Dataset(*args, **kwargs)[Source Code]
Dataset Object is the core of tablib. It provides all core functions. Usually one is created in the main module Dataset Instance that appends rows when collecting data.
data = tablib.Dataset()
data.headers = ('name', 'age')
for (name, age) in some_collector():
data.append((name, age))
Setting columns is similar. Column data must be equal to the current height of the data, and a title must be set.
data = tablib.Dataset()
data.headers = ('first_name', 'last_name')
data.append(('John', 'Adams'))
data.append(('George', 'Washington'))
data.append_col((90, 67), header='age')
If you handle dozens or hundreds Dataset Object that allows you to set row and column headers when instantiating.
headers = ('first_name', 'last_name')
data = [('John', 'Adams'), ('George', 'Washington')]
data = tablib.Dataset(*data, headers=headers)
parameter
- *args - Optional Row List to populate dataset
- headers - Optional list string of dataset header rows
- Title -- (optional) string used as dataset title
add_formatter(col, handler) [Source Code]
Add Formatter to Dataset (New 0.9.5 feature)
parameter
- col - Accepts index int or header str.
- handler - Reference to the callback function executed for each cell value.
append(row, tags=[])[Source Code]
Add rows to Dataset See Dataset.insert Other files.
append_col(col, header=None)[Source Code]
Add Columns to Dataset See Dataset.insert_col Other files.
append_separator(text='-')[Source Code]
Add one separator reach Dataset .
property dict
Local python Dataset Object. If a title is set, a python dictionary list is returned. If no title is set, a tuple (row) list is returned. You can also import dataset objects by setting up a dataset. Dataset.dict property:
data = tablib.Dataset()
data.dict = [{'age': 90, 'first_name': 'Kenneth', 'last_name': 'Reitz'}]
-
export(format, **kwargs)[Source Code]
export Dataset Object to a given format.
Parameters: **kwargs - Optional Custom Format Configuration export_set.
-
extend(rows, tags=[])[Source Code]
Add Row List to Dataset Use Dataset.append
-
filter(tag)[Source Code]
Return a new instance Dataset Contains only the given tags .
-
get_col(index)[Source Code]
Returns the Dataset .
-
property headers
(Optional) A list of strings used for header rows and attribute names. It must be set manually. The given list length must be equal to Dataset.width .
-
property height
Currently Dataset Direct modification is not supported in.
-
insert(index, row, tags=[])[Source Code]
stay Dataset Insert row at given index. The inserted row size (height or width) must be correct. The default is to insert a given row into Dataset The index given by the object.
-
insert_col(index, col=None, header=None)[Source Code]
stay Dataset Insert a column at the given index. Columns must be inserted at the correct height. You can also insert a column of a single callable object, which will add a new column with the return value of each column as an item in the column.
data.append_col(col=random.randint)
When inserting columns, if set Dataset.headers The title property must be set and treated as the title of the column. see Dynamic Column .
New 0.9.0 feature: If you insert a row, you can add tags To the row to insert, so easy filter Dataset .
-
insert_separator(index, text='-')[Source Code]
Add separator to Dataset At the given index.
-
load(in_stream, format=None, **kwargs)[Source Code]
Load in_using format format Stream to Dataset Object. in_stream can be a file-like object, string, or bytestring. Parameter ****kwargs** - optionally configured for custom format.
-
lpop()[Source Code]
Delete and Return Dataset .
-
lpush(row, tags=[])[Source Code]
see Dataset.insert.
-
lpush_col(col, header=None)[Source Code]
Add Columns to Dataset See Dataset.insert.
-
pop()[Source Code]
Delete and Return Dataset .
-
remove_duplicates()[Source Code]
Remove from Dataset All duplicate rows of the object, keeping the original order.
-
rpop()[Source Code]
Delete and Return Dataset .
-
rpush(row, tags=[])[Source Code]
see Dataset.insert.
-
rpush_col(col, header=None)[Source Code]
Add Columns to Dataset See Dataset.insert .
-
sort(col, reverse=False)[Source Code]
In a particular column, pairs are based on a string (for headings) or an integer (for sorting column indexes) Dataset Sort. The order can be reversed by setting reverse = True. Returns a dataset instance that has sorted columns.
-
stack(other)[Source Code]
By Dataset Join instances on rows and return a new composite instance Dataset.
-
stack_cols(other)[Source Code]
By Dataset Join instances on columns and return a new composite instance Dataset. If either Dataset has a title set, the other must.
-
subset(rows=None, cols=None)[Source Code]
Return a new instance Dataset Includes only the specified rows and columns.
-
transpose()[Source Code]
Transpose Dataset Converts rows to columns and vice versa. Returns a new Dataset instance. The first column of the original instance becomes the new header row.
-
property width
It cannot be modified directly at this time.
wipe()[Source Code]
from Dataset Object removes all instances.
Databook object
-
class tablib.Databook(sets=None)[Source Code]
add_sheet(dataset)[Source Code]
Add given Dataset reach Databook .
export(format, kwargs)[Source Code]
Export in format format Databook Object.Parameter******kwargs**- Optional custom format configuration.
load(in_stream, format, kwargs)[Source Code]
Import in_using format format Stream to Databook Object. in_stream can be a file-like object, string, or bytestring. Parameter ****kwargs**- Optional custom format configuration.
property size
Yes Databook Internal Dataset Object number.
wipe()[Source Code]
function
-
tablib.detect_format(stream)[Source Code]
Returns the object in the given format.
-
tablib.import_set(stream, format=None, **kwargs)[Source Code]
Returns a dataset in a given format.