🔥PaddleGAN Release the latest SOTA algorithm: Video super-resolution model PP-MSVSR
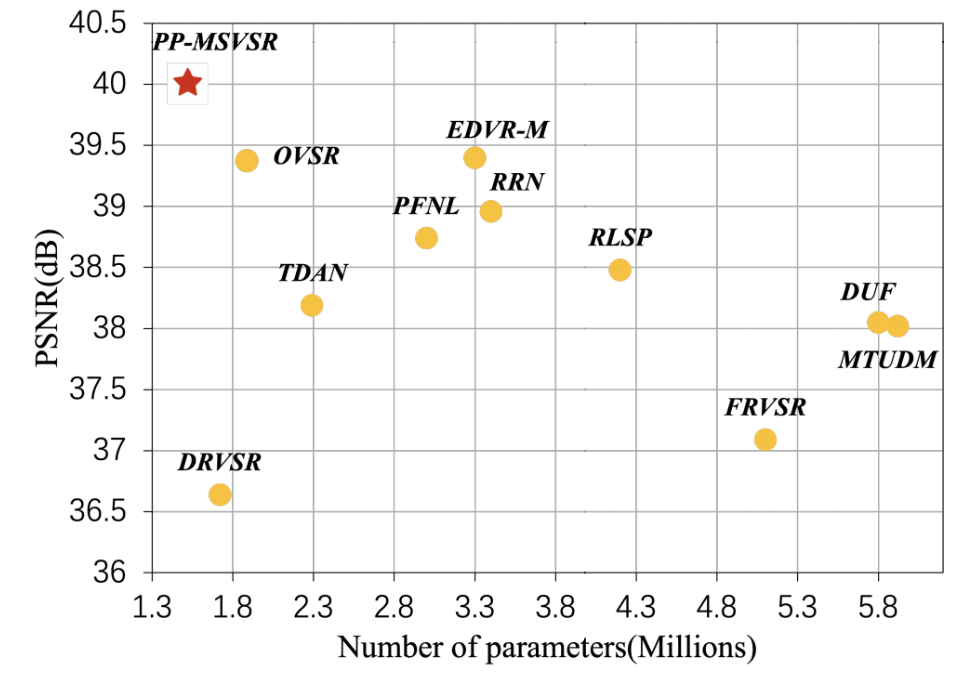
Baidu self-developed PP-MSVSR It is a multi-stage lightweight video hyper segmentation model, which achieves SOTA performance in the current lightweight video hyper segmentation model with a parameter of 1.45M. The figure shows the comparison of PSNR index of lightweight video hyper division model with current parameter less than 6M on UDM10 data set.
All codes and tutorials are completely open source to PaddleGAN Welcome, Star ⭐ Collection!

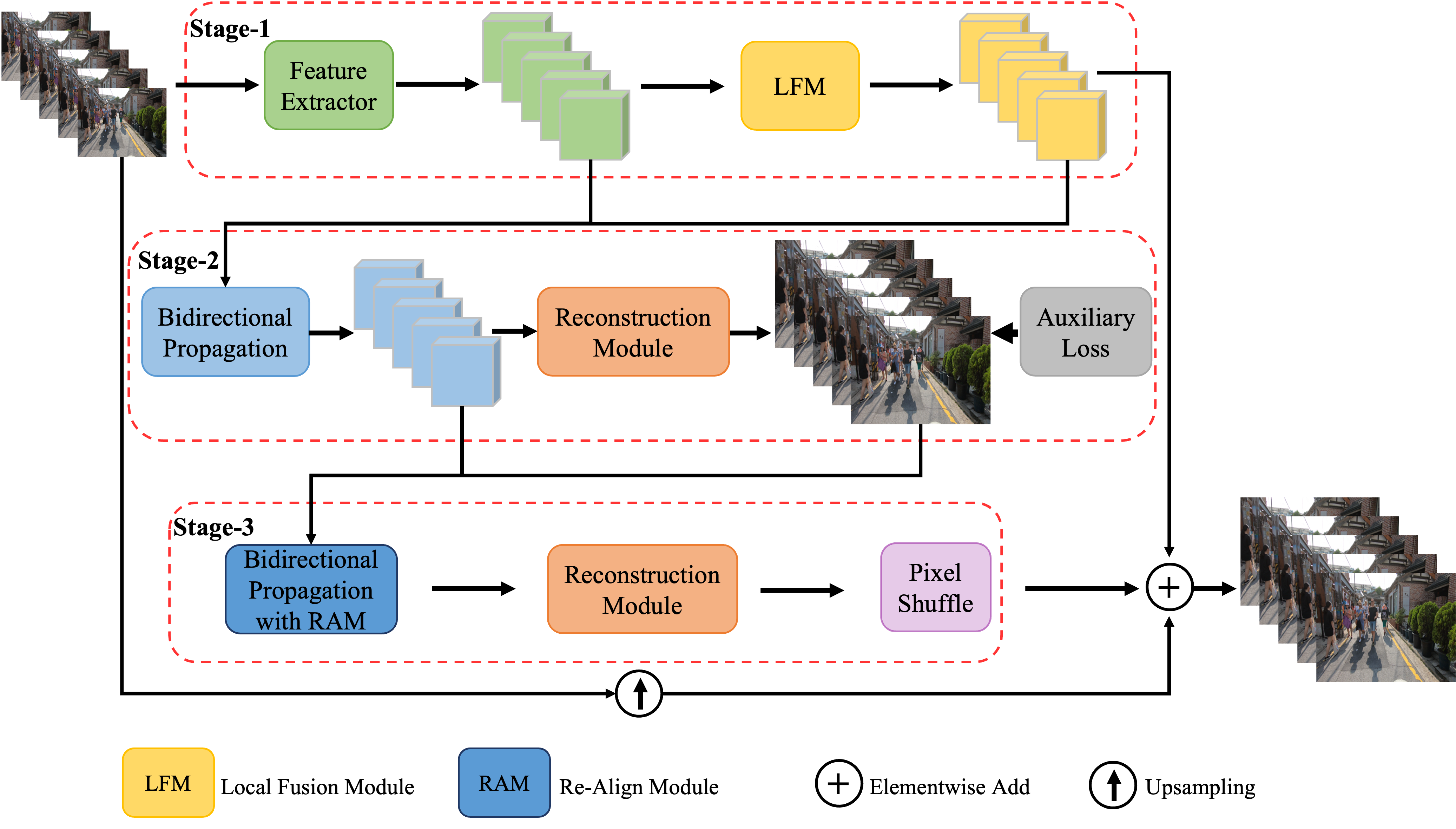
① PP-MSVSR model structure
Overview of PP-MSVSR model structure
PP-MSVSR Combining the idea of sliding window method and cyclic network method, the multi-stage strategy is used for video hypersegmentation. It has local fusion module, auxiliary Loss module and thinning alignment module to gradually refine the enhancement results. Specifically, firstly, feature extraction and local feature fusion are performed on the input video frame in the first stage; Then in the second stage, the fused features are propagated circularly and Bi directionally, and the auxiliary Loss is introduced to strengthen the feature alignment in the propagation process; Finally, the realignment module is introduced in the third stage, and the mask and offset generated in the second stage are reused to realign and enhance the propagation of features. Then the super divided video frames are obtained through a reconstruction module and pixels huffle.
⭐ Model innovation ⭐
- A multi-stage video super depth architecture is designed
- In the first stage, the local fusion module is designed to carry out local feature fusion before feature propagation, so as to strengthen the fusion of cross frame features in feature propagation.
- In the second stage, an auxiliary loss is introduced to make the features obtained by the propagation module retain more information related to high-resolution space.
- In the third stage, a realignment module is introduced to make full use of the characteristic information of the propagation module in the previous stage.
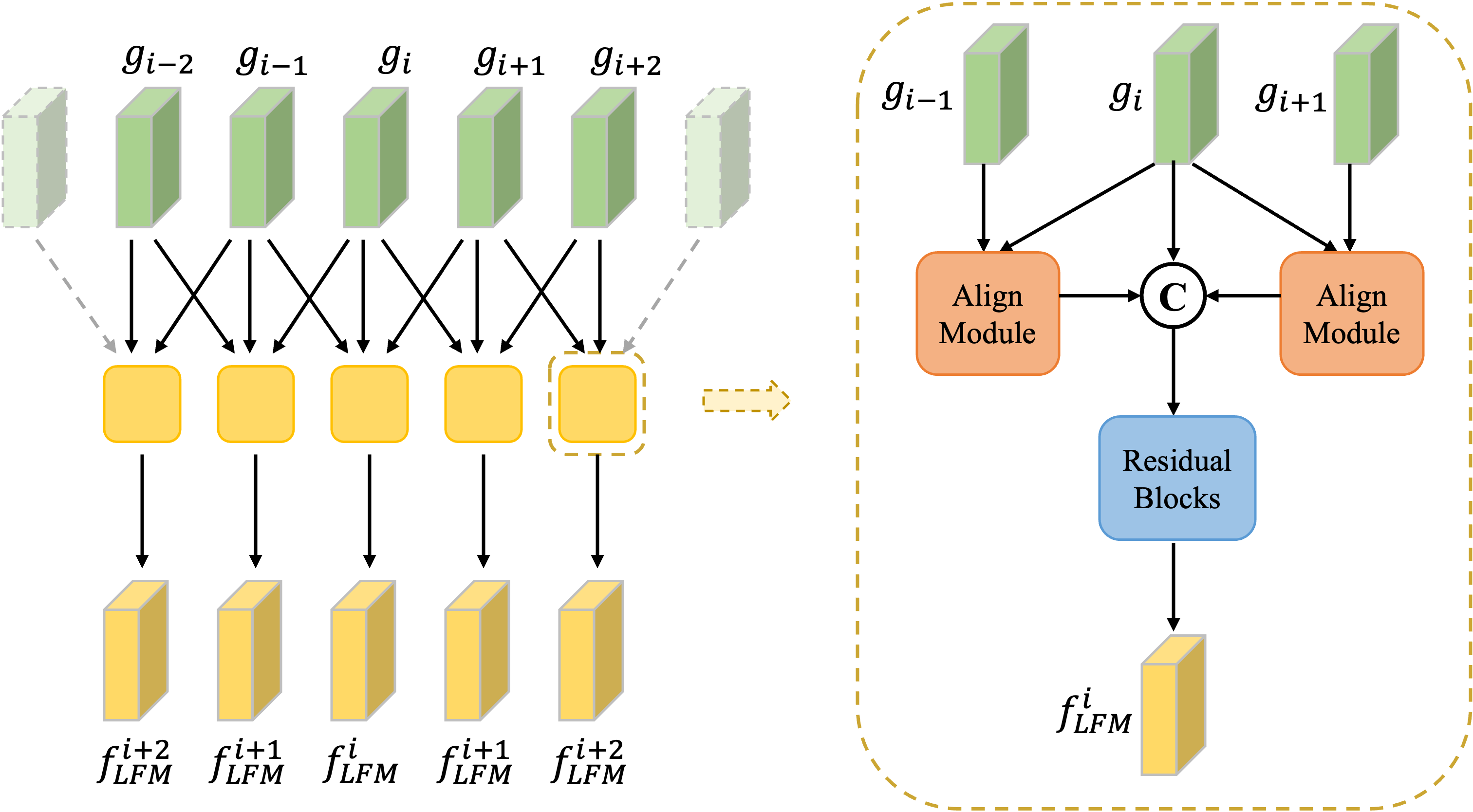
Local fusion module of PP-MSVSR model
Inspired by the idea of sliding window method, PP-MSVSR designs a local fusion module LFM in the first stage. The module performs local feature fusion before feature propagation to strengthen cross frame feature fusion in feature propagation. Specifically, the purpose of LFM is to fuse the features of the current frame with the information of its adjacent frames, and then transmit the fused features to the propagation module of the next stage.
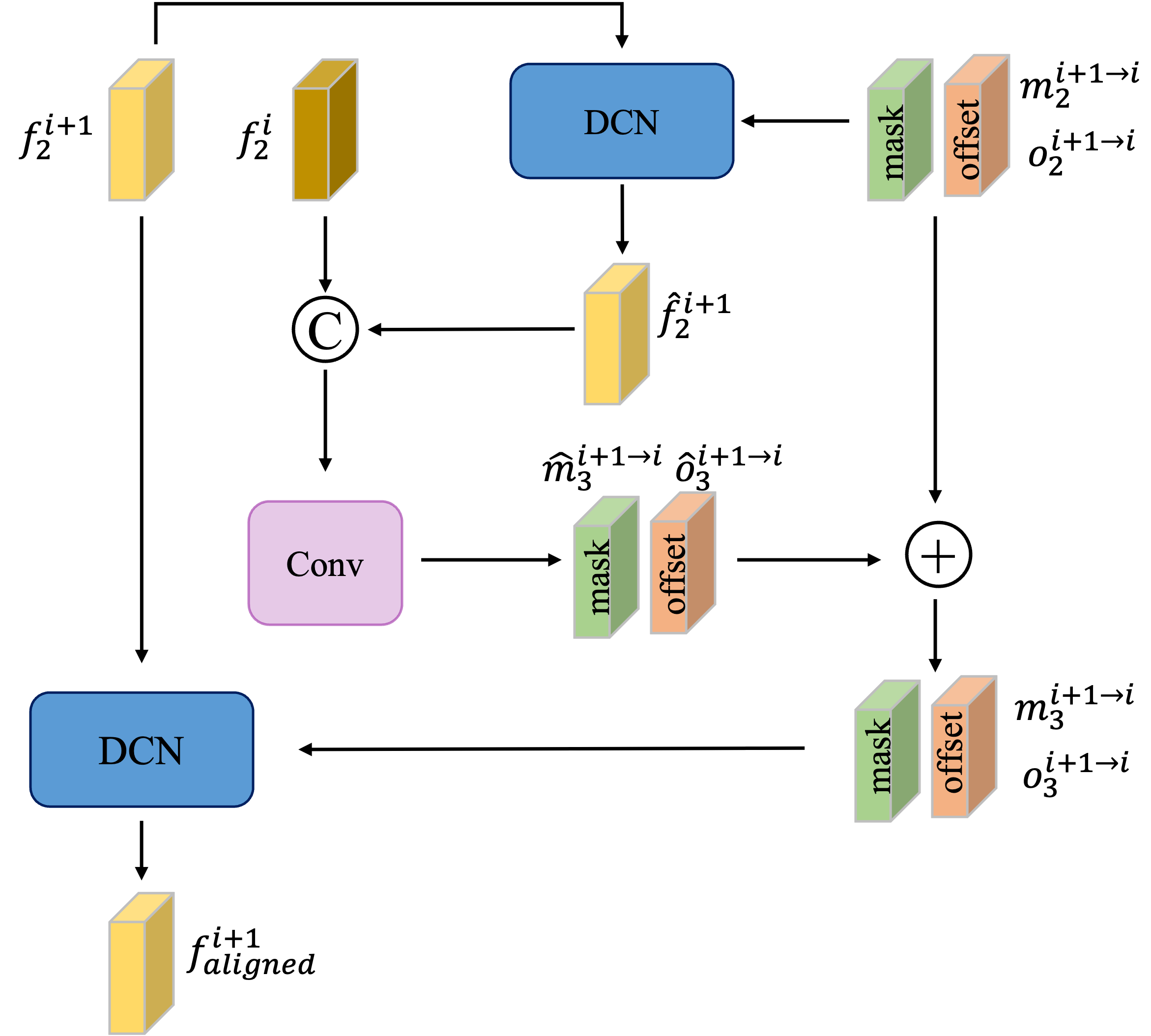
Realignment module of PP-MSVSR model
Unlike image hypersegmentation, video hypersegmentation usually needs to align adjacent frames with the current frame to better integrate the information of adjacent frames. In some large-scale motion video super segmentation tasks, the role of alignment is particularly obvious. In the process of using bidirectional cyclic network, there are often many times of the same alignment operation. In order to make full use of the results of previous alignment operations, PP-MSVSR proposes a refined alignment module RAM, which can make use of the parameters of previous alignment and obtain better alignment results.
Specifically, firstly, the mask and offset generated by the second stage feature alignment are used to pre align the input features of the third stage to obtain the pre aligned features. Then, the pre alignment feature and the current frame feature are used to generate the residuals of mask and offset. The last two pairs of mask and offset are used for final alignment to obtain the features of the final alignment.
Optical flow network based on PP-MSVSR model
The alignment used in the first and second stages of PP-MSVSR model is optical flow guided deformable convolution, and the alignment used in the third stage is realignment module. The optical flow network in the optical flow guided deformable convolution and realignment module is improved based on SPyNet. Specifically, we use
- kernel_ Convolution kernel with size 3_ Convolution with size 7
- Reduce the number of basic modules
Make SPyNet
- The accuracy is almost constant (decreased by 0.3%)
- The model size is reduced from 5.5M to 0.56M, and the parameters are reduced by 90%.
Large model PP-MSVSR-L
In order to improve the accuracy, we obtained a large model PP-MSVSR-L by increasing the number of basic modules of PP-MSVSR model.
Developers can choose flexibly according to the accuracy and speed requirements in the actual business scenario.
② PP-MSVSR model performance
Numerical performance of PP-MSVSR model
PP-MSVSR model has excellent performance. Compared with other current lightweight video hyper segmentation models, PP-MSVSR uses only 1.45M parameters and achieves the best results on four common video hyper segmentation test data sets.
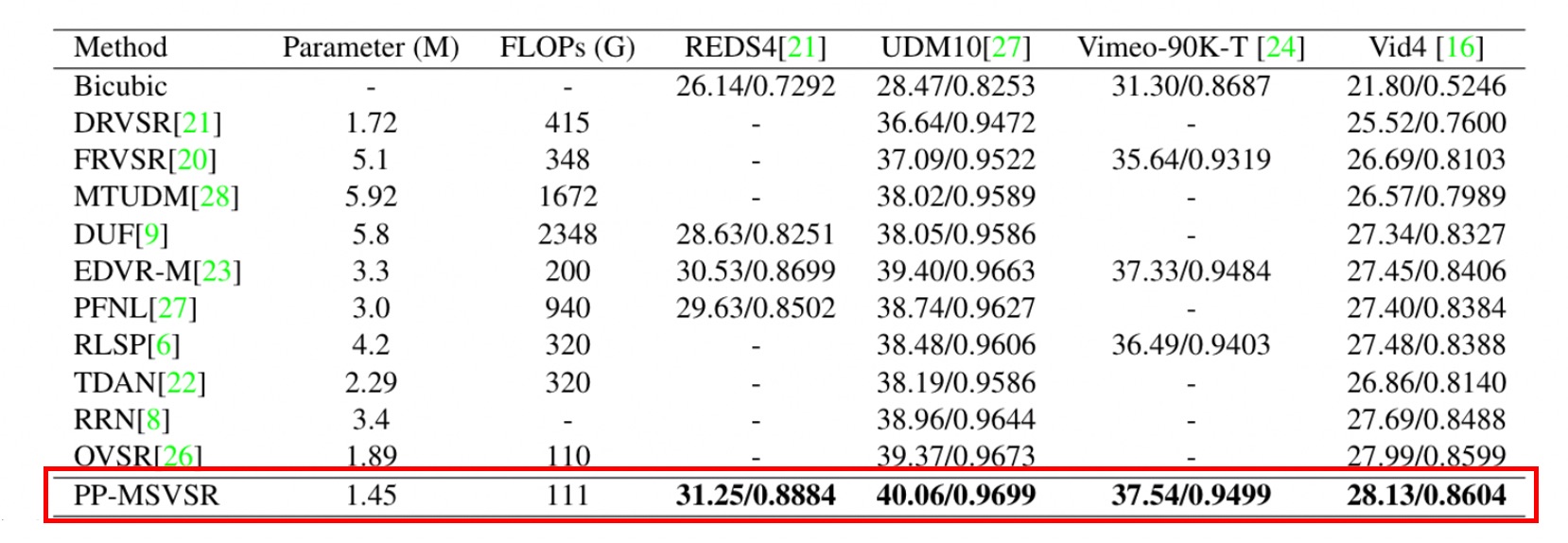
Visualization of PP-MSVSR model effect
The figure shows the visualization effect on Vid4 dataset. PP-MSVSR model has better detail recovery and visualization.

Numerical performance of PP-MSVSR-L model
PP-MSVSR-L model has the advantage of accuracy. Compared with the current basic VSR + + with the best accuracy, PP-MSVSR-L achieves higher accuracy with similar parameters.
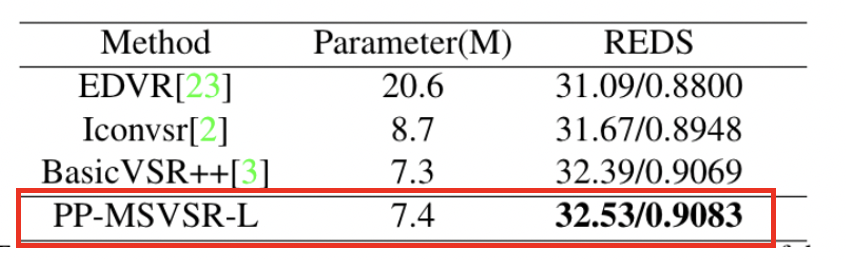
Visualization of PP-MSVSR-L model effect
The figure shows the visualization effect on reds4 dataset. PP-MSVSR model has better detail recovery and visualization.

③ PP-MSVSR model video super division effect
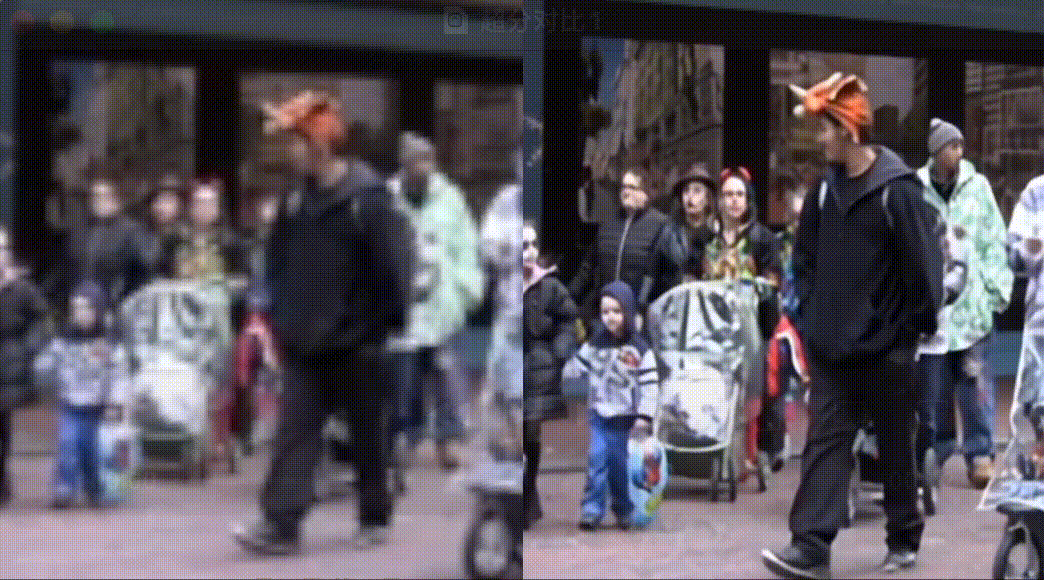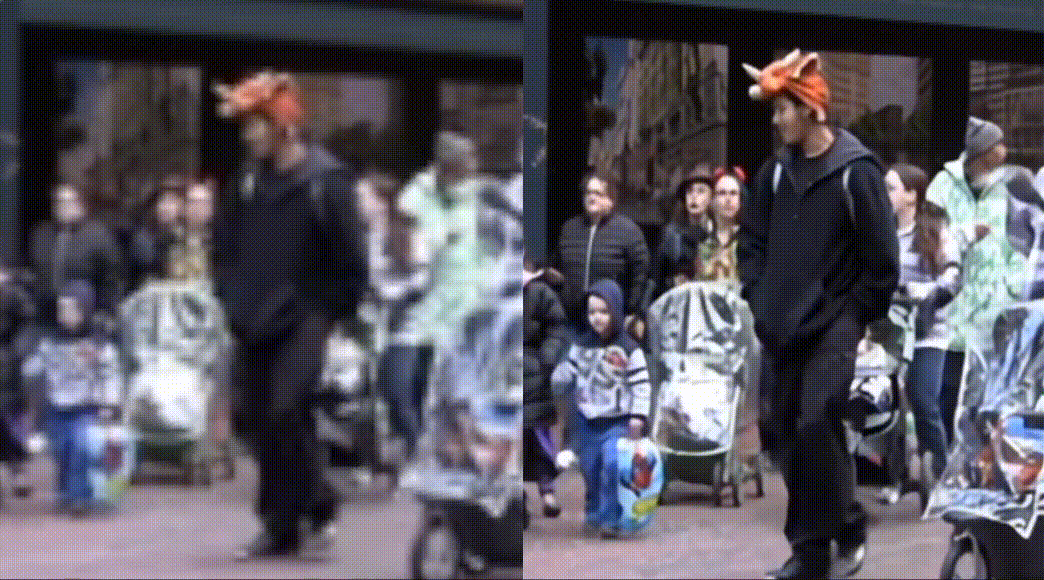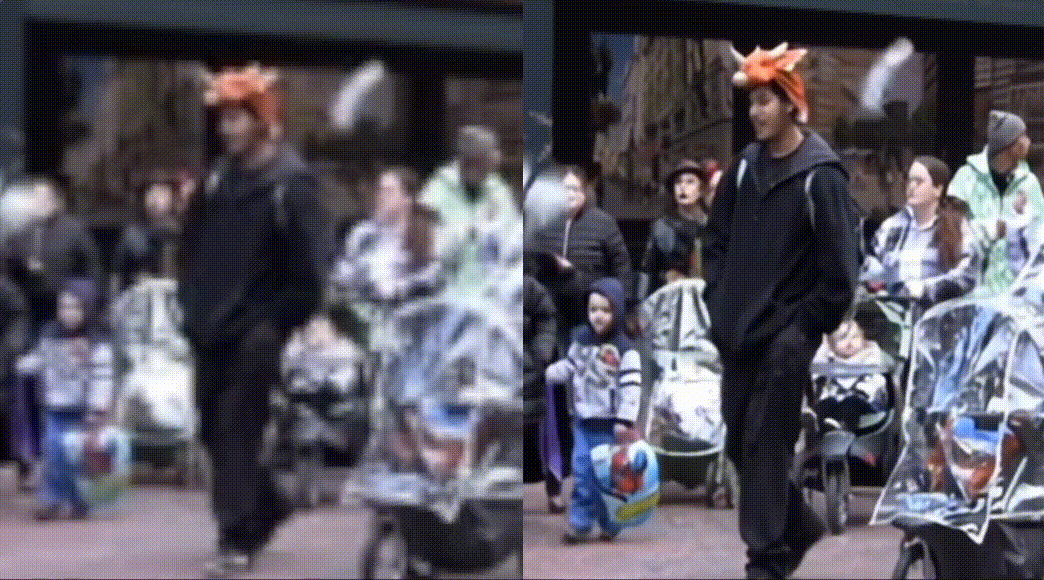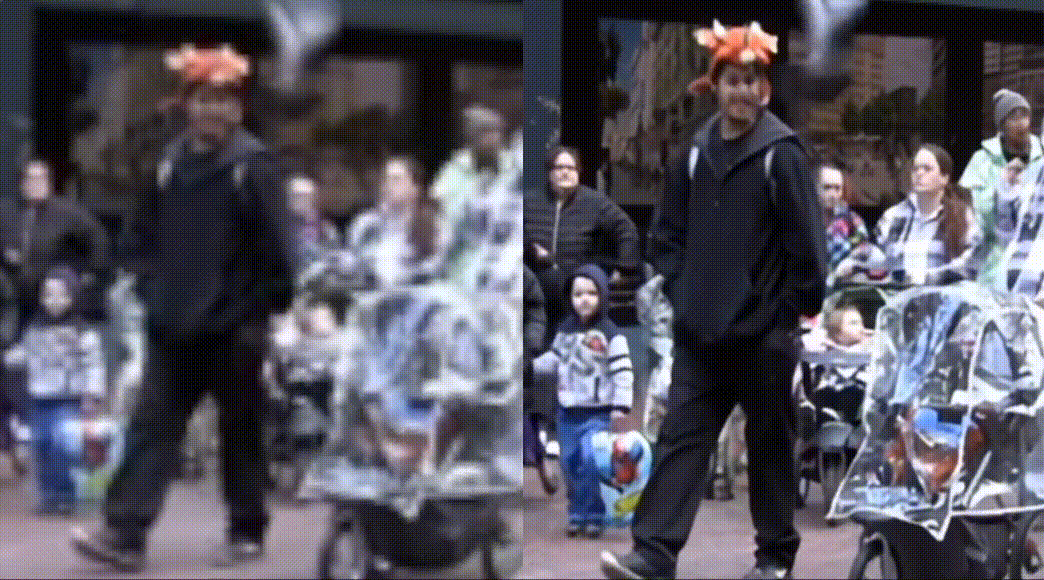


Practice of PP-MSVSR video super Division
PP-MSVSR provides two volume models, which can be flexibly selected by developers according to the actual scene: PP-MSVSR (parameter quantity 1.45M) and PP-MSVSR-L (parameter quantity 7.42).
ppgan.apps.PPMSVSRPredictor(output='output', weight_path=None, num_frames)
ppgan.apps.PPMSVSRLargePredictor(output='output', weight_path=None, num_frames)
parameter
- output_path (str, optional): the path of the output folder. The default value is output
- weight_path (None, optional): the loaded weight path. If it is not set, the default weight will be downloaded from the cloud to the local. Default: None
- num_frames (int, optional): enter the number of frames for the model. Default: 10 The larger the number of input frames, the better the model over division effect.
# Install ppgan # The current directory is: / home/aistudio /, which is also the directory where the files and folders on the left are located # Clone the latest paddegan repository to the current directory # !git clone https://github.com/PaddlePaddle/PaddleGAN.git # If downloading from github is slow, you can download from gitee clone: !git clone https://gitee.com/paddlepaddle/PaddleGAN.git %cd /home/aistudio/PaddleGAN/ !pip install -v -e . !git checkout develop
# Import some packages needed for visualization
import cv2
import imageio
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
import warnings
warnings.filterwarnings("ignore")
# Define a function to display video
def display(driving, fps, size=(8, 6)):
fig = plt.figure(figsize=size)
ims = []
for i in range(len(driving)):
cols = []
cols.append(driving[i])
im = plt.imshow(np.concatenate(cols, axis=1), animated=True)
plt.axis('off')
ims.append([im])
video = animation.ArtistAnimation(fig, ims, interval=1000.0/fps, repeat_delay=1000)
plt.close()
return video
# Show me the input video. If the video is too large, it will take a long time. You can skip this step
video_path = '/home/aistudio/011.mp4'
video_frames = imageio.mimread(video_path, memtest=False)
# Obtain the original resolution of the video
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps).to_html5_video())
# PPMSVSR model fixes the video
# The input parameter indicates the input video path
# output represents the storage folder of the processed video
# proccess_order indicates the model and order used (currently supported)
# num_frames indicates the number of input frames of the model
%cd applications/
!python tools/video-enhance.py --input /home/aistudio/011.mp4 \
--process_order PPMSVSR \
--output /home/aistudio/output_dir \
--num_frames 100
# Show me the processed video. If the video is too large, it will take a long time. You can download it and watch it
# This path allows you to view the last printed output video path of the last code cell
output_video_path = '/home/aistudio/output_dir/PPMSVSR/011_PPMSVSR_out.mp4'
video_frames = imageio.mimread(output_video_path, memtest=False)
# Obtain the original resolution of the video
cap = cv2.VideoCapture(output_video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps, size=(16, 12)).to_html5_video())
PaddleGAN Video coloring and frame insertion
In addition to video super, PaddleGAN It also provides the functions of video coloring and frame supplement. When used together with the above PP-MSVSR, it can improve the video definition, rich colors and smooth playback!
Complementary frame model DAIN
The DAIN model explicitly detects occlusion by exploring the depth information. A depth aware stream projection layer is developed to synthesize intermediate streams. It has a good effect in video frame supplement.
ppgan.apps.DAINPredictor(
output_path='output',
weight_path=None,
time_step=None,
use_gpu=True,
remove_duplicates=False)
parameter
- output_path (str, optional): the path of the output folder. The default value is output
- weight_path (None, optional): the loaded weight path. If it is not set, the default weight will be downloaded from the cloud to the local. Default: None.
- time_step (int): the time coefficient of complementary frames. If it is set to 0.5, the video originally 30 frames per second will become 60 frames per second after complementary frames.
- remove_duplicates (bool, optional): whether to delete duplicate frames. Default: False
Coloring model DeOldifyPredictor
DeOldify uses self attention mechanism to generate confrontation network, and the generator is a network with U-NET structure. It has a good effect in image coloring.
ppgan.apps.DeOldifyPredictor(output='output', weight_path=None, render_factor=32)
parameter
- output_path (str, optional): the path of the output folder. The default value is output
- weight_path (None, optional): the loaded weight path. If it is not set, the default weight will be downloaded from the cloud to the local. Default: None.
- render_factor (int): this parameter will be multiplied by 16 as the resize value of the input frame. If the value is set to 32,
The input frame will be resize d to (32 * 16, 32 * 16) and then input into the network.
Coloring model deep remasterpredictor
Deep Remaster model is based on spatiotemporal convolutional neural network and self attention mechanism. And the picture can be colored according to any number of input reference frames.
ppgan.apps.DeepRemasterPredictor(
output='output',
weight_path=None,
colorization=False,
reference_dir=None,
mindim=360):
parameter
- output_path (str, optional): the path of the output folder. The default value is output
- weight_path (None, optional): the loaded weight path. If it is not set, the default weight will be downloaded from the cloud to the local. Default: None.
- colorization (bool): whether to color the input video. If the option is set to True, the folder path of the reference frame must also be set. Default: False.
- reference_dir (bool): the folder path of the reference frame. Default: None.
- mindim (bool): enter the size of the short side of the frame after resizing. Default: 360.
use PaddleGAN Old video repair
# Import some packages needed for visualization
import cv2
import imageio
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
import warnings
warnings.filterwarnings("ignore")
# Define a function to display video
def display(driving, fps, size=(8, 6)):
fig = plt.figure(figsize=size)
ims = []
for i in range(len(driving)):
cols = []
cols.append(driving[i])
im = plt.imshow(np.concatenate(cols, axis=1), animated=True)
plt.axis('off')
ims.append([im])
video = animation.ArtistAnimation(fig, ims, interval=1000.0/fps, repeat_delay=1000)
plt.close()
return video
# Show me the input video. If the video is too large, it will take a long time. You can skip this step
video_path = '/home/aistudio/Peking_input360p_clip6_5s.mp4'
video_frames = imageio.mimread(video_path, memtest=False)
# Obtain the original resolution of the video
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps).to_html5_video())
# The video is repaired by using three models: Dain, deoldify and msvsr
# The input parameter indicates the input video path
# output represents the storage folder of the processed video
# proccess_order indicates the model and order used (currently supported)
%cd applications/
!python tools/video-enhance.py --input /home/aistudio/Peking_input360p_clip6_5s.mp4 \
--process_order DAIN DeOldify PPMSVSR \
--output /home/aistudio/output_dir
# Show me the processed video. If the video is too large, it will take a long time. You can download it and watch it
# This path allows you to view the last printed output video path of the last code cell
output_video_path = '/home/aistudio/output_dir/PPMSVSR/Peking_input360p_clip6_5s_deoldify_out_PPMSVSR_out.mp4'
video_frames = imageio.mimread(output_video_path, memtest=False)
# Obtain the original resolution of the video
cap = cv2.VideoCapture(output_video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps, size=(16, 12)).to_html5_video())
Paddegan's tricks~
So far, this project has taken you through the use of paddegan's PP-MSVSR to complete video super score and old video repair. You are welcome to try different types of Video repair in this project~
Of course, the application of paddegan will not stop here. Paddegan can also provide various graphics and image generation and processing capabilities. Face attribute editing ability can manipulate single or multiple attributes of face image on the basis of face recognition and face generation, so as to change makeup, age, youth, gender and hair color, and make it possible to change face with one click; Movement migration can realize limb movement transformation, facial expression movement migration and so on.
We strongly encourage everyone to play and stimulate paddegan's potential!


Welcome to join the official QQ group (1058398620) to communicate with various technical experts~~
