Two dimensional data, Series container, with both row index and column index

1. Create DataFrame
1.1 create DataFrame through list
You need to specify data, index row and columns
Specify that data and index/columns are of type list or NP arange
df1 = pd.DataFrame(data=[[1, 2, 3], [11, 12, 13]], index=['r_1', 'r_2'], columns=['A', 'B', 'C'])
df2 = pd.DataFrame(data=[[1], [11]], index=['r_1', 'r_2'], columns=['A'])
df3 = pd.DataFrame(data=np.arange(12).reshape(3, 4), index=list("abc"), columns=list("ABCD"))
Copy codeA B C
r_1 1 2 3 r_2 11 12 13
A r_1 1 r_2 11
A B C D a 0 1 2 3 b 4 5 6 7 c 8 9 10 11
1.2 create DataFrame through dictionary
1.2.1 method 1: input a single dictionary. Note that it must be one key with multiple values (in case of single value, it must also add [])
dict = {"name": ["jack", "HanMeimei"], "age": ["100", "100"]}
# dict = {"name": "jack", "age": "100"}#Writing like this will report an error
# dict = {"name":["jack"], "age": ["100"]}#If it is a single value, you must add []
df3 = pd.DataFrame(dict, index=list("ab"))
Copy codeage age1 name
a 100.0 NaN MaYun1 b 100.0 NaN MaYun2 c NaN 100.0 MaYun3
1.2.2 method 2: input the dictionary list. Each dictionary is a row of data, and the missing column will supplement nan
dict = [{"name": "MaYun1", "age": 100}, {"name": "MaYun2", "age": 100}, {"name": "MaYun3", "age1": 100}]
# dict = {"name": "jack", "age": "100"}
df4 = pd.DataFrame(dict, index=list("abc"))
Copy code2. Basic properties of dataframe

dict = {"name": ["jack", "HanMeimei", "Lucy"], "age": ["100", "90","98"], "salary": [30000, 50000, 999000]}
df5 = pd.DataFrame(dict)
print(df5)
print(df5.head(1))
print(df5.tail(1))
print(df5.info())
print(df5.index)
print(df5.columns)
print(df5.values)
print(df5.describe())
Copy code3. All data are sorted according to the specified column
df5 = df5.sort_values(by='salary', ascending=True) print(df5) Copy code

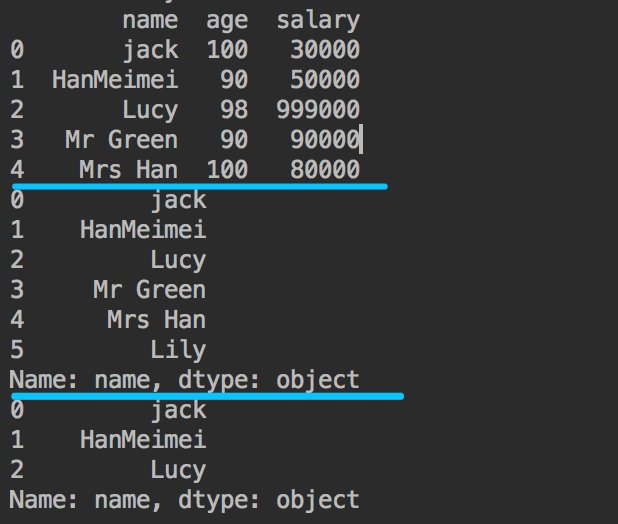
4. DataFrame simple row and column slicing
dict = {"name": ["jack", "HanMeimei", "Lucy","Mr Green", "Mrs Han", "Lily"],
"age": [100, 90,98,90,100,30], "salary": [30000, 50000, 999000,90000,80000,75000]}
df6 = pd.DataFrame(dict)
print(df6)
# Take out the first five lines
print(df6[0:5])
# Take out the name column
print(df6["name"])
# Take out the name column of the first three rows
print(df6[0:3]["name"])
Copy code
5. loc row and column slicing
5.2 * just remember the following one. It's troublesome to remember too much
The basic format is:
df7.loc[that 's ok,column] Copy code
If you take consecutive rows or columns --- use slice:
If you take out discontinuous rows or columns - use list []
Slice and list can be mixed
Examples:
5.5.1 continuous multi row and multi column
df7.loc['a':'c','name':'age'] Note: includes b OK, because it's a row slice > name age a jack 100 b HanMeimei 90 c Lucy 98 Copy code
5.5.2 discontinuous multiple rows + continuous multiple columns
df7.loc[['a','c'],'name':'salary'] Note: the row is a discontinuous selection, only a and c The column is a continuous slice, including the middle age > name age salary a jack 100 30000 c Lucy 98 999000 Copy code
5.5.3 discontinuous multiple rows + discontinuous multiple columns
df7.loc[['a','c'],['name','salary']] Note: the row is a discontinuous selection, only a and c Columns are also discontinuous selections, but name and salary > name salary a jack 30000 c Lucy 999000 Copy code
5.5.4 all rows + discontinuous multiple columns (the same for all columns)
df7.loc[:,['name','salary']] Note: just write an empty slice of the line: > name salary a jack 30000 b HanMeimei 50000 c Lucy 999000 d Mr Green 90000 e Mrs Han 80000 f Lily 75000 Copy code
5.5.5 discontinuous multiple rows + single column (the same for single row)
df7.loc[['a','c'],'name'] Note: single column name is not added[],The result is a Series > a jack c Lucy Name: name, dtype: object <class 'pandas.core.series.Series'> Copy code
df7.loc[['a','c'],['name']] type(df7.loc[['a','c'],['name']]) Note: single column name plus[],The result is a DataFrame > name a jack c Lucy <class 'pandas.core.frame.DataFrame'> Copy code
6. iloc row and column slicing
The principle is the same as that of loc
Just note that the slice does not contain the last number, which is different from loc

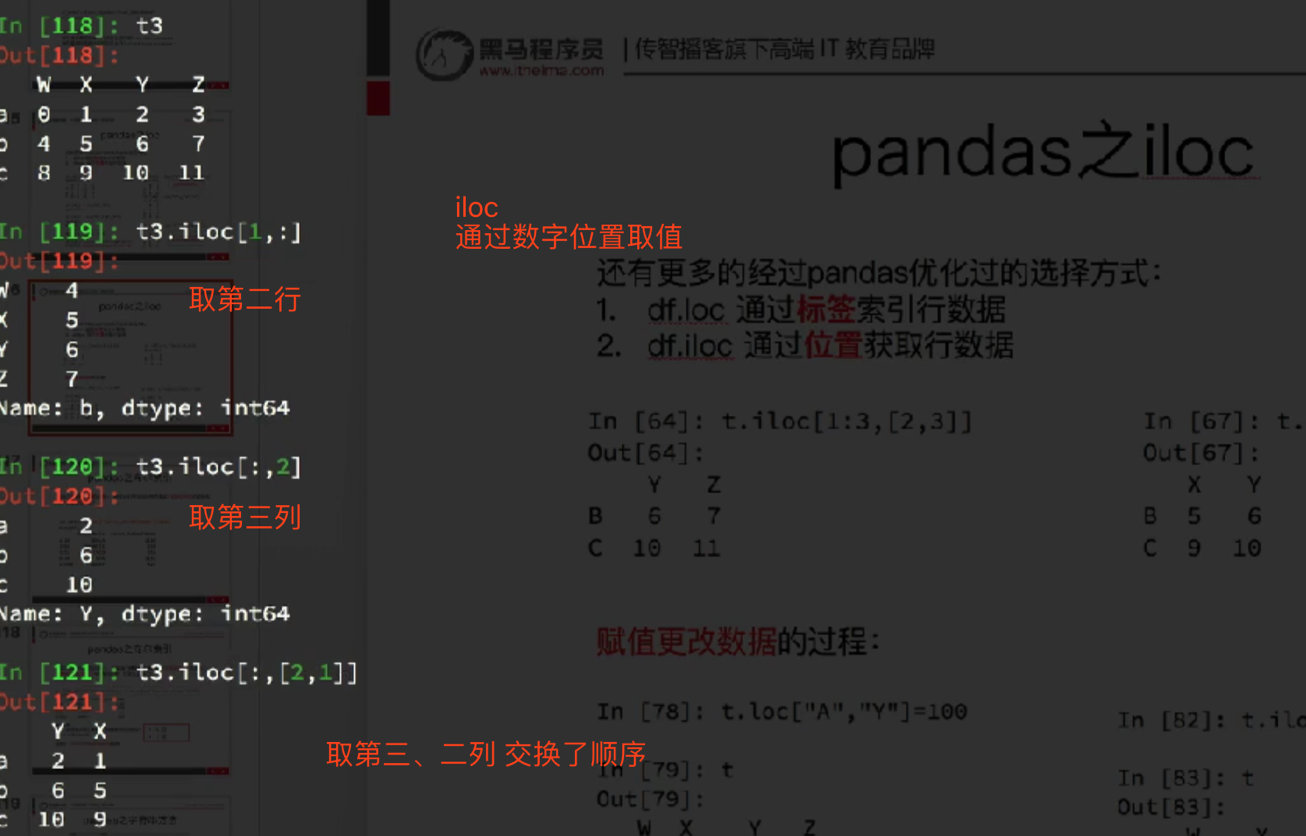
df7.iloc[[1,3],[0]]
> Get discontinuous ranks
name
b HanMeimei
d Mr Green
df7.iloc[1:3,0:1]
> Not including 3 d ,Not including 1 age
name
b HanMeimei
c Lucy
Copy code7. Assignment change data
You can use loc or iloc

df7.iloc[1:3,1:3]=99999999 print(df7) > name age salary a jack 100 30000 b HanMeimei 99999999 99999999 c Lucy 99999999 99999999 d Mr Green 90 90000 e Mrs Han 100 80000 f Lily 30 75000 Copy code
8. Boolean index
Let's see an example
Create a dataframe
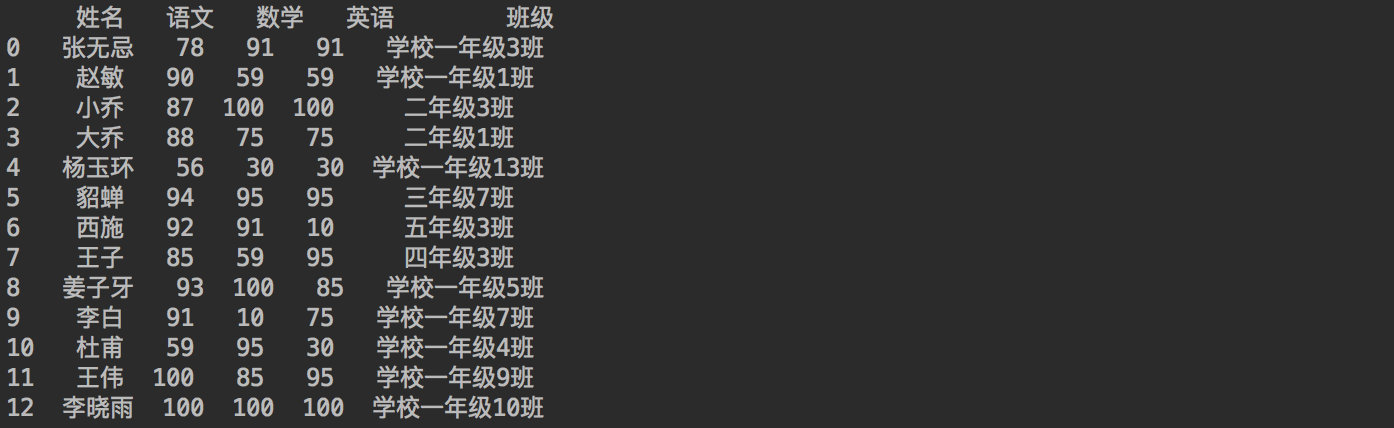
Score = {"full name": ["zhang wuji", "Zhao Min", "Little Joe", "Big Joe", "Yang Yuhuan", "army officer's hat ornaments", "Xi Shi", "prince", "Jiang Ziya", "Li Bai", "Du Fu", "Wang Wei","Li Xiaoyu"],
"language": [78, 90, 87, 88, 56, 94, 92, 85, 93, 91, 59, 100,100],
"mathematics": [91, 59, 100, 75, 30, 95, 91, 59, 100, 10, 95, 85,100],
"English": [91, 59, 100, 75, 30, 95, 10, 95, 85, 75, 30, 95,100]}
df_score = pd.DataFrame(Score)
print(df_score)
Copy code

8.1 take out the data of all people whose English scores are greater than 90
# What you get is a Series loc_ = df_score.loc[:,"English"] > 90 print(loc_) print(type(loc_))# <class 'pandas.core.series.Series'> # dataframe Boolean index, which will filter out all rows with the value of true print(df_score[loc_]) # It can also be abbreviated as print(df_score[df_score.loc[:,"English"]>90]) Copy code


8.2 take out the data of all people whose English scores are less than 90 (~)
Note: add ~ reverse
print(df_score[~(df_score.loc[:, "English"] > 90)]) Copy code

8.3 take out the data of all people with English scores greater than 90 and Chinese scores greater than 80
print(df_score[(df_score.loc[:, "English"] > 90)&(df_score.loc[:, "language"] < 80)]) Copy code

8.4 screenshot of knowledge points
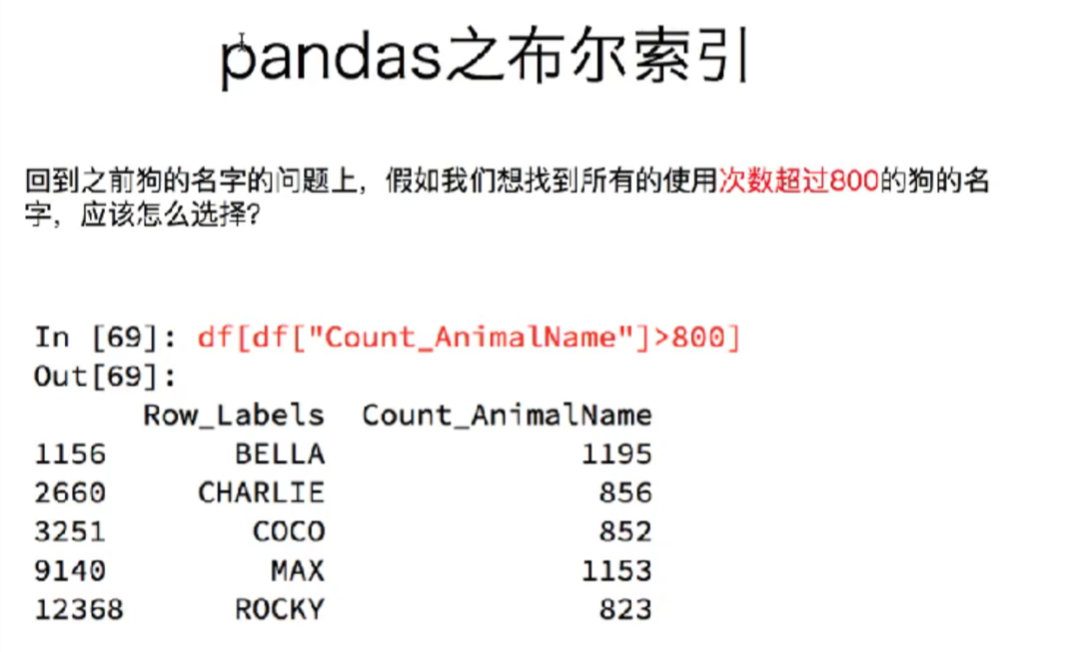
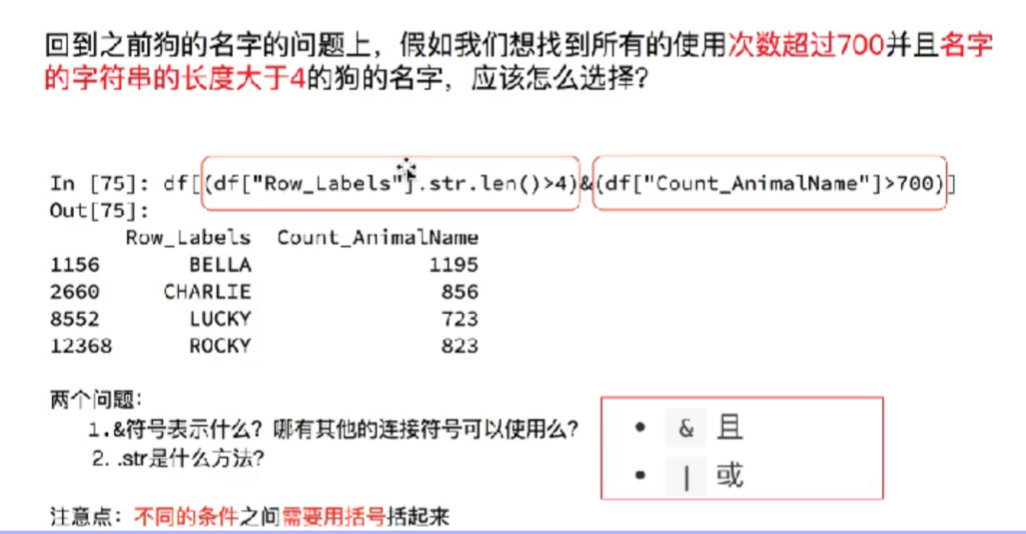
9. String method
# Create a dataframe
student = {"full name": ["zhang wuji", "Zhao Min", "Little Joe", "Big Joe", "Yang Yuhuan", "army officer's hat ornaments", "Xi Shi", "prince", "Jiang Ziya", "Li Bai", "Du Fu", "Wang Wei", "Li Xiaoyu"],
"language": [78, 90, 87, 88, 56, 94, 92, 85, 93, 91, 59, 100, 100],
"mathematics": [91, 59, 100, 75, 30, 95, 91, 59, 100, 10, 95, 85, 100],
"English": [91, 59, 100, 75, 30, 95, 10, 95, 85, 75, 30, 95, 100],
"class": ["Class 3, grade 1", "Class 1, grade 1", "Class 3, grade 2", "Class 1, grade 2", "Class 13, grade 1", "Class 7, grade 3", "Class 3, grade 5", "Class 3, grade 4", "Class 5, grade 1", "Class 7, grade 1", "Class 4, grade 1",
"Class 9, grade 1", "Class 10, grade 1"],
}
df_student = pd.DataFrame(student)
print(df_student)
Copy code

9.1 len - select the data whose element string length in [class] column is greater than 5
print(df_student[df_student["class"].str.len() > 5]) Copy code

9.2 replace - change [grade] in the element of [class] column to [first grade of school]
# Note that the right side of the equal sign returns a Series, which should be assigned to the column corresponding to the original DataFrame
df_student["class"] = df_student["class"].str.replace("first grade", "First grade of school")
print(df_student)
# The following is the loc usage of column fetching
df_student.loc[:,"class"] = df_student.loc[:,"class"].str.replace("first grade", "First grade of school")
Copy code
9.3 contains - filter the data of "school" and "1" in the [class] column
print(df_student[
(df_student["class"].str.contains("school"))
&
(df_student["class"].str.contains("1"))])
Copy code

9.4 split -- cut string
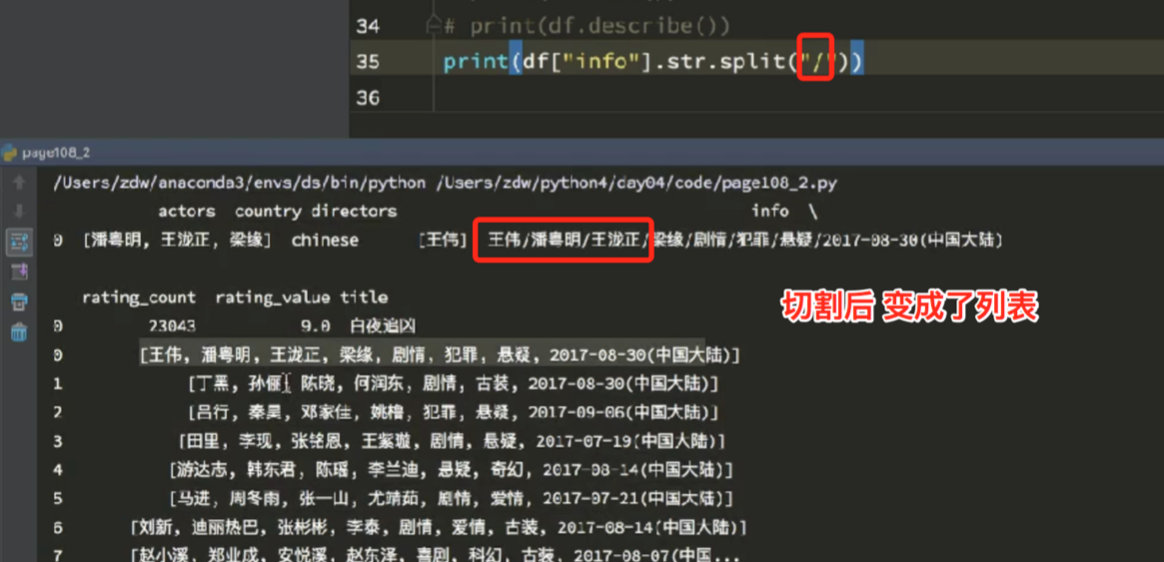
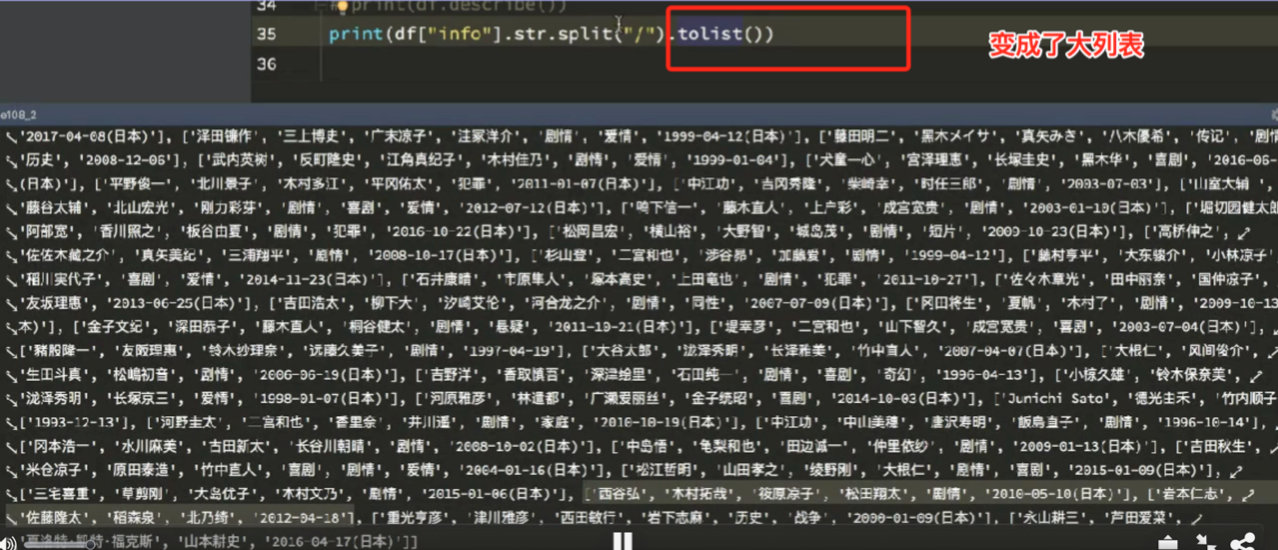
9.5 get - print the first character of the student's name (last name)
print((df_student["full name"].str.get(0))) Copy code

9.6 match - regular expression matching to find the data whose name contains' Wang | Li '
reg = 'king|Lee' print(df_student[df_student["full name"].str.match(reg)]) Copy code

9.7 pad - fill character*
# Note that width=10 means that the current character + the * to be filled, and the width is 10 # Both sides are added with *, and the length of the final string is 10, which is not enough to be added with * (you can also directly use the center function without writing side) df_student["full name"] = df_student["full name"].str.pad(width=10, side='both', fillchar='*') # Add - on the right, and the length of the final string is 20, which is insufficient - add df_student["full name"] = df_student["full name"].str.pad(width=20, side='right', fillchar='-') print(df_student) Copy code
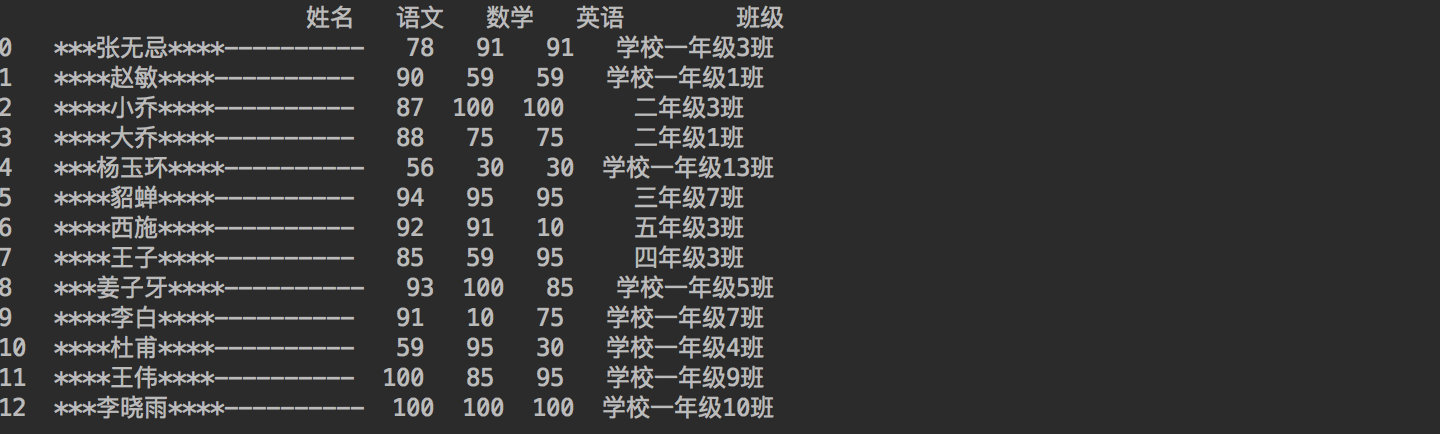
9.5 screenshot of knowledge points

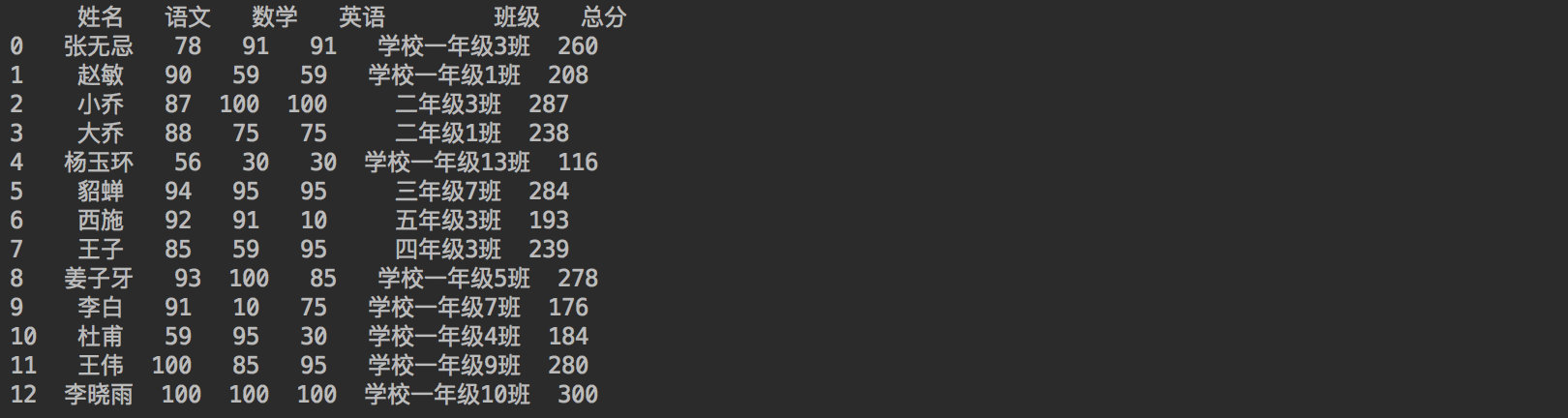
10. Add a column of statistical total score apply method
10.1 direct addition
df_student["Total score"] = df_student["language"] + df_student["mathematics"] + df_student["English"] Copy code
10.2 traversal using the apply method of Series (apply passes in a function, which is more powerful)
df_student['Total score'] = pd.Series(df_student.index.tolist()).apply(
lambda i: df_student.loc[i, "language"] + df_student.loc[i, "mathematics"] + df_student.loc[i, "English"])
# 1. In order to use the apply method of Series, a Series is generated according to the Index of DataFrame,
pd.Series(df_student.index.tolist())
# 2. The following is a lambda expression, which can also be passed in by defining a function (you can do a lot of processing by writing a function), as shown in the following example
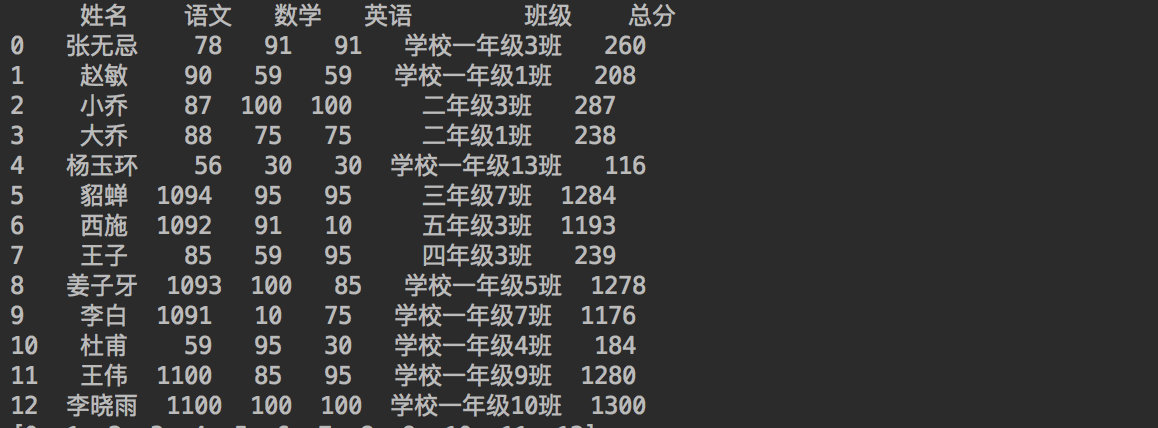
Copy code# Let the person whose Chinese is greater than 90 add 1000 points to his Chinese score, and then calculate the total score
def sum1(i):
if df_student.loc[i, "language"] > 90:
df_student.loc[i, "language"] = df_student.loc[i, "language"] + 1000
return df_student.loc[i, "language"] + df_student.loc[i, "mathematics"] + df_student.loc[i, "English"]
df_student['Total score'] = pd.Series(df_student.index.tolist()).apply(
lambda i: sum1(i))
Copy code
11. Missing data processing
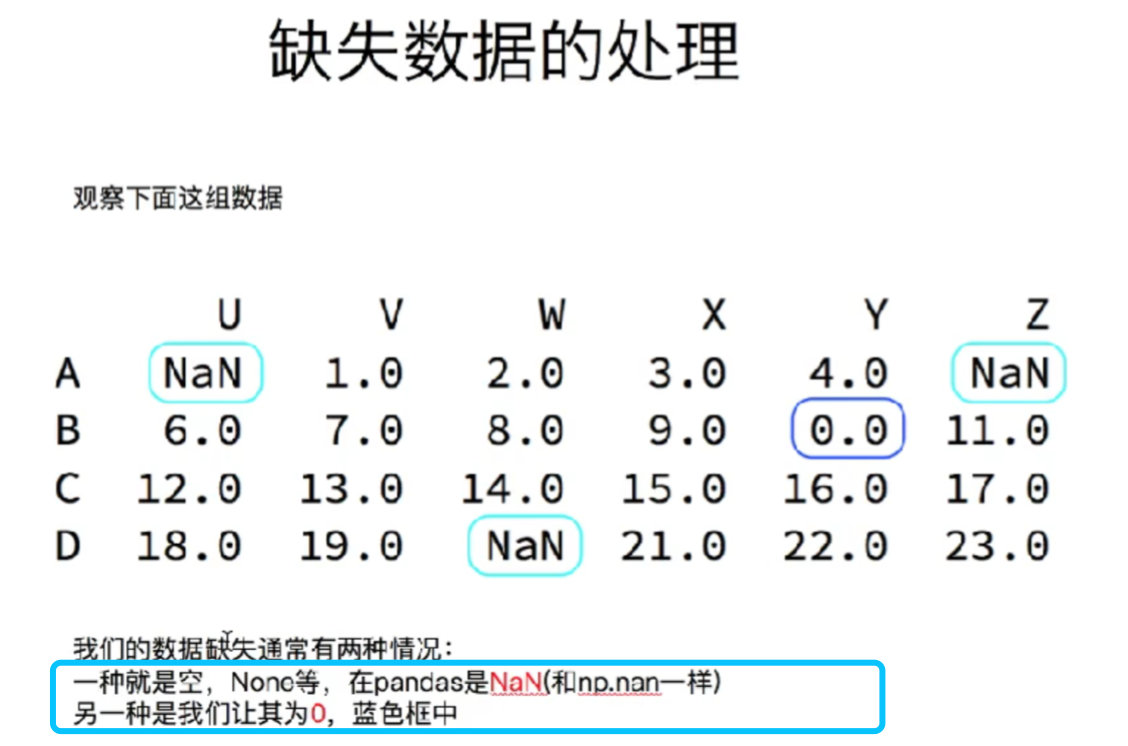
# Use numpy to generate a set of random integers (between 0 and 100, with the shape of 5 rows and 7 columns)
rand = np.random.randint(0, 100, (5, 7))
# Upload data generated using DataFrame
df = pd.DataFrame(rand, columns=list("ABCDEFG"))
# Define some NaN
df.loc[0:3, "A":"B"] = np.nan
print(df)
Copy code

11.1 judge whether it is NaN
11.1.1 judge whether the whole df is Nan
# Is it null print(pd.isnull(df)) The result is: DataFrame Copy code

# Isn't it null print(pd.notnull(df)) Copy code

11.1.2 judge whether df specified column is Nan
# Print the data with NUll in column A print(df[pd.isnull(df["A"])]) Copy code

# Print data whose data in column A is not NUll print(df[pd.notnull(df["A"])]) Copy code

11.2 delete data with nan in df
# Do not enter the how parameter. The default value is any # As long as one is NaN, the row will be deleted print(df.dropna(axis=0)) Copy code

# This row will be deleted only if all of them are NaN print(df.dropna(axis=0,how="all")) Copy code
