Flink version 1.13
In some scenarios, the state of Flink users has been growing indefinitely, and some use cases need to be able to automatically clean up the old state. For example, an extremely long time window is defined in the job, or an infinite range of GROUP BY statements are applied to the dynamic table. In addition, at present, developers need to complete the temporary implementation of TTL by themselves, such as using timer service that may not save storage space. Another important point is that some laws and regulations also require that data must be accessed within a limited time.
For these cases, the old version of Flink can not solve them well, so Apache Flink 1.6.0 introduces the state TTL feature. This feature can not be used automatically in the Keyed state within a certain time. If TTL is configured and the status has expired, every effort will be made to clean up the expired status.
1. Usage
Can be in Flink official documents State TTL is used as follows:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
// State descriptor
ValueStateDescriptor<Long> stateDescriptor = new ValueStateDescriptor<>("LastLoginState", Long.class);
// Set TTL
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.minutes(1))
.setTtlTimeCharacteristic(StateTtlConfig.TtlTimeCharacteristic.ProcessingTime)
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupFullSnapshot()
.build();
stateDescriptor.enableTimeToLive(ttlConfig);You can see that to use the State TTL function, you must first define a StateTtlConfig object. StateTtlConfig object can be created through constructor mode. Typically, a Time object is passed in as TTL Time, and then Time processing semantics (TtlTimeCharacteristic), update type (UpdateType) and state visibility (StateVisibility) can be set. When the StateTtlConfig object is created, the State TTL function can be enabled in the state descriptor.
Set the expiration time of 1 minute as follows:
2. Parameter description
2.1 expiration time
The parameter of the newBuilder method is required, which indicates the expiration time of the status. It is an org apache. flink. api. common. time. Time object. You can simply think that once the TTL is set, if the timestamp + TTL of the last access exceeds the current time, it indicates that the status has expired (actually more complex).
2.2 time processing semantics
Ttltimecharacteric indicates the time processing semantics that can be used by the State TTL function:
public enum TtlTimeCharacteristic {
ProcessingTime
}So far, Flink 1.14 only supports processing time semantics. EventTime processing semantics are still under development and can be tracked FLINK-12005.
The settings can be displayed as follows:
setTtlTimeCharacteristic(StateTtlConfig.TtlTimeCharacteristic.ProcessingTime)
2.3 update type
UpdateType indicates the update time of the status timestamp (last access timestamp):
public enum UpdateType {
Disabled,
OnCreateAndWrite,
OnReadAndWrite
}If it is set to Disabled, it means that the TTL function is Disabled and the status will not expire; If it is set to OnCreateAndWrite, it means that the timestamp will be updated during state creation or each write; If set to OnReadAndWrite, the read state will update the timestamp of the state in addition to updating the timestamp when the state is created and written each time. If not configured, the default is OnCreateAndWrite.
The settings can be displayed as follows:
// Equivalent to updatetloncreateandwrite() setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // Equivalent to updatetlonreadandwrite() setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
2.4 state visibility
StateVisibility indicates state visibility. Whether to return the expired value when reading the state:
public enum StateVisibility {
ReturnExpiredIfNotCleanedUp,
NeverReturnExpired
}If it is set to ReturnExpiredIfNotCleanedUp, it will be returned to the caller when the status value has expired but has not been really cleaned up; If it is set to NeverReturnExpired, once the status value expires, it will never be returned to the caller, and only the empty status will be returned.
The settings can be displayed as follows:
// Equivalent to returnExpiredIfNotCleanedUp() setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp) // Equivalent to neverReturnExpired() setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
3. Expiration cleaning strategy
Starting from Flink version 1.6.0, the expired status will be automatically deleted when a Checkpoint or Savepoint full snapshot is generated. However, expiration status deletion is not applicable to incremental checkpoints. Full snapshots must be explicitly enabled to delete expiration status. The size of the full snapshot decreases, but the size of the local state store does not. The user's local state is cleared only when the user reloads its state locally from the snapshot. Due to these limitations, in order to improve the user experience, Flink 1.8.0 introduces two strategies to trigger state cleanup step by step, namely, the incremental cleanup strategy for Heap StateBackend and the compressed cleanup strategy for RocksDB StateBackend. So far, there are three expiration cleanup strategies:
- Full snapshot cleanup policy
- Incremental cleanup strategy
- RocksDB compression cleanup policy
3.1 full snapshot cleaning strategy
Let's take a look at the full snapshot cleaning strategy. This strategy can clean up the expired state when generating a full snapshot (Snapshot/Checkpoint), which can greatly reduce the snapshot storage, but it should be noted that the expired data in the local state will not be cleaned up. The local state will actually decrease only after the job is restarted and restored from the previous snapshot. If you want to use this expiration policy in DataStream, please refer to the following code:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build();This expiration cleanup policy has no effect on the RocksDB status backend with incremental checkpoints on.
The corresponding implementation of full_state_scan_snapshot is EmptyCleanupStrategy:
static final CleanupStrategy EMPTY_STRATEGY = new EmptyCleanupStrategy();
public Builder cleanupFullSnapshot() {
strategies.put(CleanupStrategies.Strategies.FULL_STATE_SCAN_SNAPSHOT, EMPTY_STRATEGY);
return this;
}
static class EmptyCleanupStrategy implements CleanupStrategy {
private static final long serialVersionUID = 1373998465131443873L;
}3.2 incremental cleanup strategy
Let's take another look at the incremental cleanup strategy for Heap StateBackend. Under this strategy, the storage backend will maintain an inert global iterator for all state entries. Each time incremental cleanup is triggered, the iterator iterates forward to delete the traversed expired data. If you want to use this expiration policy in DataStream, please refer to the following code:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(5, false)
.build();The policy has two parameters: the first parameter indicates the number of state entries to be checked each time the cleanup is triggered, which is always triggered when the state is accessed. The second parameter defines whether additional cleanup is triggered each time a record is processed. The default background cleanup at the back end of the heap state triggers the check of 5 entries each time, and there will be no additional overdue data cleanup when processing records.
The corresponding implementation of incremental_cleanup strategy is incremental cleanup strategy:
public Builder cleanupIncrementally(@Nonnegative int cleanupSize, boolean runCleanupForEveryRecord) {
strategies.put(
CleanupStrategies.Strategies.INCREMENTAL_CLEANUP,
new IncrementalCleanupStrategy(cleanupSize, runCleanupForEveryRecord)
);
return this;
}
public static class IncrementalCleanupStrategy implements CleanupStrategies.CleanupStrategy {
static final IncrementalCleanupStrategy DEFAULT_INCREMENTAL_CLEANUP_STRATEGY =
new IncrementalCleanupStrategy(5, false);
private final int cleanupSize;
private final boolean runCleanupForEveryRecord;
private IncrementalCleanupStrategy(int cleanupSize, boolean runCleanupForEveryRecord) {
this.cleanupSize = cleanupSize;
this.runCleanupForEveryRecord = runCleanupForEveryRecord;
}
...
}It should be noted that:
- If the status is not accessed or no records need to be processed, the expiration status will always exist.
- The time taken for incremental cleanup increases record processing latency.
- At present, only the heap state backend implements incremental cleanup. Setting up incremental cleanup for the RocksDB state backend has no effect.
- If the heap state backend is used with synchronous snapshots, the global iterator retains copies of all keys during iteration because its specific implementation does not support concurrent modifications. Enabling this feature will increase memory consumption. Asynchronous snapshots do not have this problem.
- For existing jobs, you can enable or disable this cleanup policy in StateTtlConfig at any time.
3.3 RocksDB compression cleaning strategy
Finally, let's take a look at the RocksDB compression cleanup strategy. If RocksDB StateBackend is used, the compression filter specified by Flink will be called for background cleanup. RocksDB periodically runs asynchronous compression to merge state updates and reduce storage. Flink compression filter uses TTL to check the expiration timestamp of status entries and delete the expiration status value. If you want to use this expiration policy in DataStream, please refer to the following code:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build();The RocksDB compression filter queries the current timestamp and checks whether it is expired after each processing of a certain status entry. Updating timestamps frequently can improve cleanup speed, but also reduce compression performance. The default of RocksDB status backend is to query the current timestamp every 1000 entries processed.
The corresponding implementation of RocksDB_compaction_filter is RocksdbCompactFilterCleanupStrategy:
public Builder cleanupInRocksdbCompactFilter(long queryTimeAfterNumEntries) {
strategies.put(
CleanupStrategies.Strategies.ROCKSDB_COMPACTION_FILTER,
new RocksdbCompactFilterCleanupStrategy(queryTimeAfterNumEntries)
);
return this;
}
public static class RocksdbCompactFilterCleanupStrategy implements CleanupStrategies.CleanupStrategy {
private static final long serialVersionUID = 3109278796506988980L;
static final RocksdbCompactFilterCleanupStrategy DEFAULT_ROCKSDB_COMPACT_FILTER_CLEANUP_STRATEGY =
new RocksdbCompactFilterCleanupStrategy(1000L);
private final long queryTimeAfterNumEntries;
private RocksdbCompactFilterCleanupStrategy(long queryTimeAfterNumEntries) {
this.queryTimeAfterNumEntries = queryTimeAfterNumEntries;
}
...
}Calling the TTL filter during compression reduces the compression speed. The TTL filter must parse the timestamp of the last access and check the expiration time of each storage status entry that is compressing the Key. In the case of a collection state type (List or Map), a check is also called for each stored element.
4. Precautions
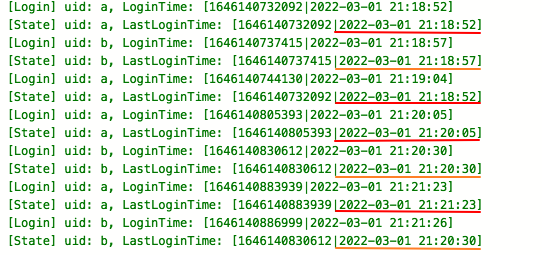
When recovering from the state, the previously set TTL expiration time will not be lost and will continue to take effect. Set a 5-minute expiration time for the logged in user as follows:
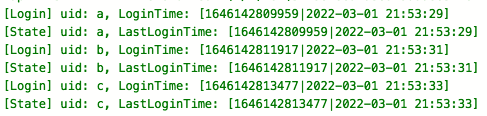
Cancel the job and trigger Savepoint before the status expires, as shown below:
flink cancel -s hdfs://localhost:9000/flink/savepoints/ 3b37dece248dafc7330b854c38bf526d
Then resume the job from Savepoint:
flink run -s hdfs://localhost:9000/flink/savepoints/savepoint-c82ee3-e7ca58626e3b -c com.flink.example.stream.state.state.StateTTLExample flink-example-1.0.jar
If the user logs in again within 5 minutes after the first login, the last login time of the user will remain unchanged. If it exceeds 5 minutes, the first login time will be recorded again:
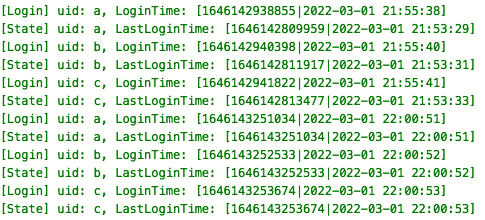
When recovering from Checkpoint/Savepoint, the status of TTL (whether it is enabled or not) must be the same as before, otherwise the following compatibility problems will be encountered:
2022-03-01 22:34:33 java.lang.RuntimeException: Error while getting state at org.apache.flink.runtime.state.DefaultKeyedStateStore.getState(DefaultKeyedStateStore.java:62) at org.apache.flink.streaming.api.operators.StreamingRuntimeContext.getState(StreamingRuntimeContext.java:203) at com.flink.example.stream.state.state.StateTTLExample$1.open(StateTTLExample.java:82) at org.apache.flink.api.common.functions.util.FunctionUtils.openFunction(FunctionUtils.java:34) at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.open(AbstractUdfStreamOperator.java:102) at org.apache.flink.streaming.runtime.tasks.OperatorChain.initializeStateAndOpenOperators(OperatorChain.java:437) at org.apache.flink.streaming.runtime.tasks.StreamTask.restoreGates(StreamTask.java:574) at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.call(StreamTaskActionExecutor.java:55) at org.apache.flink.streaming.runtime.tasks.StreamTask.restore(StreamTask.java:554) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:756) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.flink.util.StateMigrationException: For heap backends, the .new state serializer (org.apache.flink.runtime.state.ttl.TtlStateFactory$TtlSerializer@724383d2) must not be incompatible with the old state serializer (org.apache.flink.api.common.typeutils.base.LongSerializer@13921758). at org.apache.flink.runtime.state.heap.HeapKeyedStateBackend.tryRegisterStateTable(HeapKeyedStateBackend.java:214) at org.apache.flink.runtime.state.heap.HeapKeyedStateBackend.createInternalState(HeapKeyedStateBackend.java:279) at org.apache.flink.runtime.state.ttl.TtlStateFactory.createTtlStateContext(TtlStateFactory.java:211) at org.apache.flink.runtime.state.ttl.TtlStateFactory.createValueState(TtlStateFactory.java:146) at org.apache.flink.runtime.state.ttl.TtlStateFactory.createState(TtlStateFactory.java:133) at org.apache.flink.runtime.state.ttl.TtlStateFactory.createStateAndWrapWithTtlIfEnabled(TtlStateFactory.java:70) at org.apache.flink.runtime.state.AbstractKeyedStateBackend.getOrCreateKeyedState(AbstractKeyedStateBackend.java:301) at org.apache.flink.runtime.state.AbstractKeyedStateBackend.getPartitionedState(AbstractKeyedStateBackend.java:352) at org.apache.flink.runtime.state.DefaultKeyedStateStore.getPartitionedState(DefaultKeyedStateStore.java:115) at org.apache.flink.runtime.state.DefaultKeyedStateStore.getState(DefaultKeyedStateStore.java:60) ... 11 more
It is recommended to add StateTtlConfig first when using state. If expiration cleaning is not required, it can be set to StateTtlConfig first Disablecleanupinbackground(), and then configure the expiration time and cleaning policy if expiration cleaning is required later.