preface
changestream is a collection based change event stream that appeared after the 3.6 version of monggodb. The application passes through dB collection. Commands such as watch () can obtain the real-time changes of the monitored object
Students who are familiar with the principle of mysql master-slave replication should know that it is the slave node that monitors binlog logs and then parses binlog log data to achieve the purpose of data synchronization. Therefore, based on the principle of mysql master-slave replication, Alibaba has opened a data synchronization middleware tool such as canal
Change Stream introduction
Change stream refers to the change event stream of the collection, and the application passes through dB collection. Commands such as watch () can obtain the real-time changes of the monitored object.
The changestream is described as follows for reference
- Before the appearance of this feature, developers can achieve the same purpose by pulling oplog;
- However, the processing and parsing of oplog is relatively complex, and there is a risk of being rolled back. If it is not used properly, it will also bring performance problems;
- Change Stream can be used in combination with aggregate framework to further filter or convert change sets;
- Because the Change Stream utilizes the information stored in oplog, MongoDB for single process deployment cannot support the Change Stream function. It can only be used for independent clusters or fragmented clusters with replica sets enabled
The type of mongodb target that changestream can listen on
- A single collection, except for the system library (admin/local/config), is supported in version 3.6
- A single database, a collection of databases other than the system library (admin/local/config), which is supported in version 4.0
- The whole cluster, the collection except the system library (admin/local/config) in the whole cluster, which is supported by version 4.0
The basic structure of a Change Stream Event is as follows:
{
_id : { <BSON Object> },
"operationType" : "<operation>",
"fullDocument" : { <document> },
"ns" : {
"db" : "<database>",
"coll" : "<collection"
},
"documentKey" : { "_id" : <ObjectId> },
"updateDescription" : {
"updatedFields" : { <document> },
"removedFields" : [ "<field>", ... ]
}
"clusterTime" : <Timestamp>,
"txnNumber" : <NumberLong>,
"lsid" : {
"id" : <UUID>,
"uid" : <BinData>
}
}
For the above data structure, make a simple explanation,
- _ id, the Token object of the change event
- operationType, change type (see introduction below)
- Document, fullDocument
- ns, target of monitoring
- ns.db, changed database
- ns.coll, set of changes
- documentKey: change the key value of the document, including_ id field
- updateDescription, change description
- updateDescription.updatedFields, update fields in change
- updateDescription.removedFields to delete fields in the change
- clusterTime, corresponding to the timestamp of oplog
- txnNumber, transaction number, appears only in multi document transactions, and is supported in version 4.0
- lsid, the session number associated with the transaction. It only appears in multi document transactions. Version 4.0 supports it
The change types supported by Change Steram mainly include the following for the above operationType parameter:
- Insert, insert document
- Delete to delete the document
- Replace: replace the document. When the replace operation is performed to specify upsert, it may be an insert event
- Update, which updates the document. When the update operation specifies upsert, it may be an insert event
- invalidate, an invalidation event, such as the execution of collection Drop or collection rename
The above types can be simply understood as the event types of mongo user operation monitored, such as adding data, deleting data, modifying data, etc
The above is the necessary theoretical knowledge of changestream. If you want to study deeply, you should understand it. Here is a demonstration of the use of changestream through practical operation
Environmental preparation
mongdb replicates the cluster. The corresponding mongodb version of the replication cluster in this example is 4.0 X

Log in to the primary node and create a database
Friendly reminder: the database needs to be created in advance
1. Start two Mongo shell s, one operating database and one watch
Execute the following command in one of the windows to enable listening
cursor = db.comment.watch()
2. In another window, insert a piece of data into the above articledb

After the data is written successfully, execute the following command in the first window:
cursor.next()
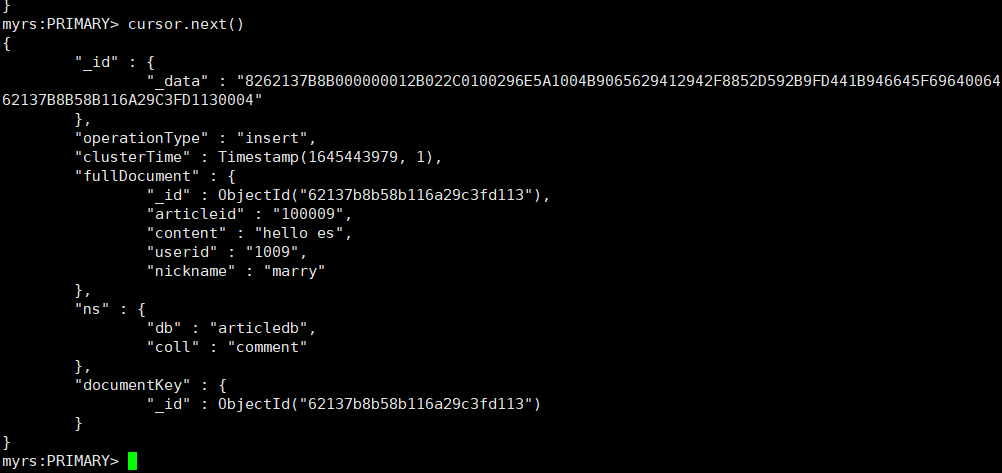
This indicates that the newly added data has been successfully monitored. You can perform similar operations for modifying and deleting events
The above shows the use effect of changestream through the shell window. Next, we will demonstrate how to integrate and use changestream on the client through the program
Java client operation changestream
1. Introducing maven dependency
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.12.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
2. Test class core code
import com.mongodb.*;
import com.mongodb.client.MongoDatabase;
import org.bson.conversions.Bson;
import java.util.List;
import static java.util.Collections.singletonList;
import com.alibaba.fastjson.JSONObject;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientURI;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Aggregates;
import com.mongodb.client.model.Filters;
import com.mongodb.client.model.changestream.ChangeStreamDocument;
import org.bson.Document;
import org.bson.conversions.Bson;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import static java.util.Arrays.asList;
public class MongoTest {
private static Logger logger = LoggerFactory.getLogger(MongoTest.class);
public static void main(String[] args) {
showmogodbdata();
}
private static void showmogodbdata() {
String sURI = "mongodb://IP:27017";
MongoClient mongoClient = new MongoClient(new MongoClientURI(sURI));
MongoDatabase database = mongoClient.getDatabase("articledb");
MongoCollection<Document> collec = database.getCollection("comment");
List<Bson> pipeline = singletonList(Aggregates.match(Filters.or(
Document.parse("{'fullDocument.articleid': '100007'}"),
Filters.in("operationType", asList("insert", "update", "delete")))));
MongoCursor<ChangeStreamDocument<Document>> cursor = collec.watch(pipeline).iterator();
while (cursor.hasNext()) {
ChangeStreamDocument<Document> next = cursor.next();
logger.info("output mogodb of next Corresponding value of" + next.toString());
String Operation = next.getOperationType().getValue();
String tableNames = next.getNamespace().getCollectionName();
System.out.println(tableNames);
//Gets the value of the primary key id
String pk_id = next.getDocumentKey().toString();
//Synchronous modification of data
if (next.getUpdateDescription() != null) {
JSONObject jsonObject = JSONObject.parseObject(next.getUpdateDescription().getUpdatedFields().toJson());
System.out.println(jsonObject);
}
//Synchronous insertion of data
if (next.getFullDocument() != null) {
JSONObject jsonObject = JSONObject.parseObject(next.getFullDocument().toJson());
System.out.println(jsonObject);
}
//Synchronous deletion of data
if (next.getUpdateDescription() == null && Operation.matches("delete")) {
JSONObject jsonObject = JSONObject.parseObject(pk_id);
System.out.println(jsonObject);
}
}
}
}
This procedure is mainly divided into several core parts, which are explained as follows,
- Connect mogodb server and related configurations
- Enable watch monitoring through pipline
- Monitor the data change of the set under the specific database, and then print the changed data
Start this program and observe the console log data
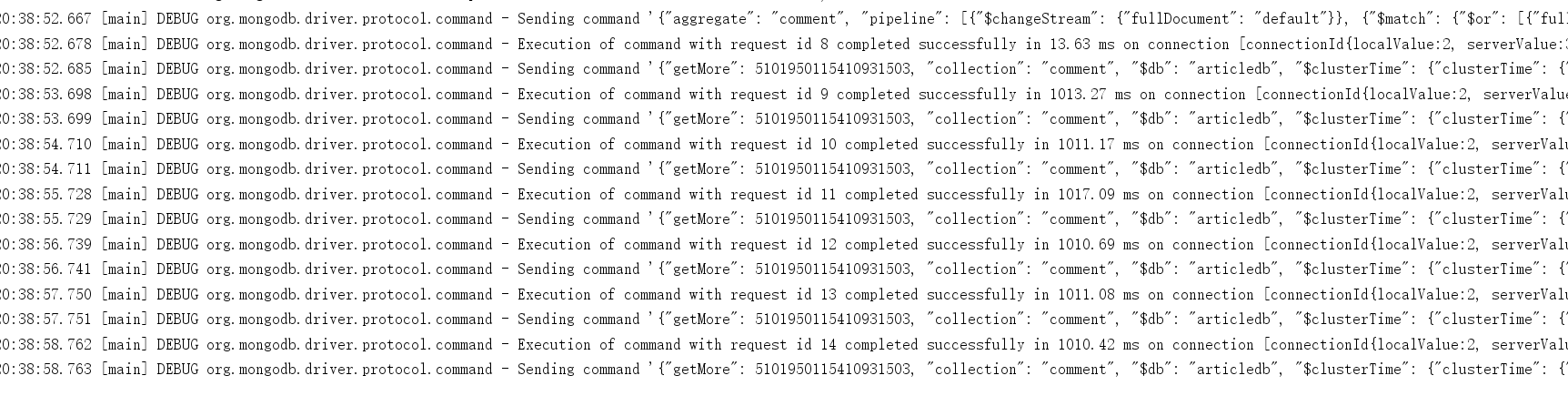
Before doing anything to the comment set under the articledb database, the watch cannot enter the while loop because it detects any data changes. Next, add a piece of data to the comment set from the shell side, and then observe the console data changes again

As you can see, the console quickly detects the changed data

The following is the complete log data
{ operationType=OperationType{value='insert'}, resumeToken={"_data": "8262138891000000022B022C0100296E5A1004B9065629412942F8852D592B9FD441B946645F696400646213889158B116A29C3FD1140004"}, namespace=articledb.comment, destinationNamespace=null, fullDocument=Document{{_id=6213889158b116a29c3fd114, articleid=100010, content=hello kafka, userid=1010, nickname=marry}}, documentKey={"_id": {"$oid": "6213889158b116a29c3fd114"}}, clusterTime=Timestamp{value=7067142396626075650, seconds=1645447313, inc=2}, updateDescription=null, txnNumber=null, lsid=null}
As for the specific use in business, it can be combined with its own situation. For example, if the application only wants to listen to the event of modifying data, it can analyze the changed data for subsequent operations in the monitoring logic of modifying data events
springboot integrates changestream
In actual development, the more common scenario is to integrate it into the springboot project. Students with certain development experience should easily think of what the core logic looks like. Similar to the client operation of canal, it needs to be monitored in a configuration class
Let's take a look at the specific integration steps
1. Introducing core dependencies
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
2. Core profile
This example demonstrates the mongodb replication cluster built above
server.port=8081 #mongodb configuration spring.data.mongodb.uri=mongodb://IP:27017,IP:27018,IP:27019/articledb?maxPoolSize=512
3. Write an entity class to map the fields in the comment collection
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
@Document(collection="comment")
public class Comment {
@Id
private String articleid;
private String content;
private String userid;
private String nickname;
private Date createdatetime;
public String getArticleid() {
return articleid;
}
public void setArticleid(String articleid) {
this.articleid = articleid;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUserid() {
return userid;
}
public void setUserid(String userid) {
this.userid = userid;
}
public String getNickname() {
return nickname;
}
public void setNickname(String nickname) {
this.nickname = nickname;
}
public Date getCreatedatetime() {
return createdatetime;
}
public void setCreatedatetime(Date createdatetime) {
this.createdatetime = createdatetime;
}
}
3. Write a service class
Simply add 2 methods to test with interface
import com.congge.entity.Comment;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class MongoDbService {
private static final Logger logger = LoggerFactory.getLogger(MongoDbService.class);
@Autowired
private MongoTemplate mongoTemplate;
/**
* Query all
* @return
*/
public List<Comment> findAll() {
return mongoTemplate.findAll(Comment.class);
}
/***
* Query by id
* @param id
* @return
*/
public Comment getBookById(String id) {
Query query = new Query(Criteria.where("articleid").is(id));
return mongoTemplate.findOne(query, Comment.class);
}
}
4. Write an interface
@RestController
public class CommentController {
@Autowired
private MongoDbService mongoDbService;
@GetMapping("/listAll")
public Object listAll(){
return mongoDbService.findAll();
}
@GetMapping("/findById")
public Object findById(String id){
return mongoDbService.getBookById(id);
}
}
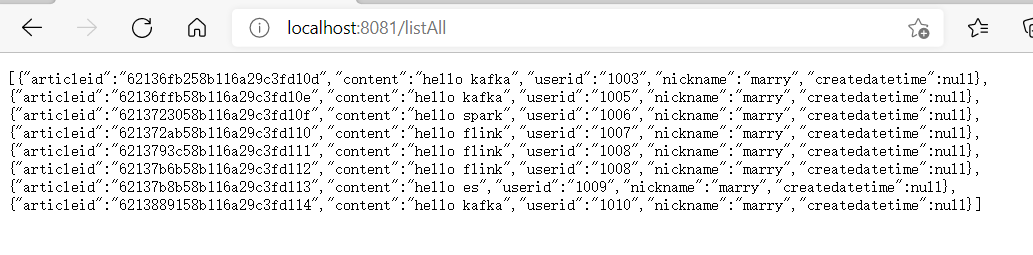
Start the project, then call the interface to query all data under the browser, and the data can return normally, indicating that the infrastructure of the project is completed
5. Next, you only need to add the following three configuration classes in turn
MongoMessageListener class, as its name suggests, is used to monitor the changes of aggregate data in a specific database. In actual development, this class also plays a very important role. It is similar to the client listener of many middleware. After monitoring the data changes, it makes subsequent business responses, such as data warehousing, pushing messages to kafka Send related events, etc
import com.congge.entity.Comment;
import com.mongodb.client.model.changestream.ChangeStreamDocument;
import com.mongodb.client.model.changestream.OperationType;
import org.bson.Document;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.data.mongodb.core.messaging.Message;
import org.springframework.data.mongodb.core.messaging.MessageListener;
import org.springframework.stereotype.Component;
@Component
public class MongoMessageListener implements MessageListener<ChangeStreamDocument<Document>,Comment> {
private static Logger logger = LoggerFactory.getLogger(MongoMessageListener.class);
@Override
public void onMessage(Message<ChangeStreamDocument<Document>, Comment> message) {
OperationType operationType = message.getRaw().getOperationType();
System.out.println("Operation type is :" + operationType);
System.out.println("Change data subject :" + message.getBody().getArticleid());
System.out.println("Change data subject :" + message.getBody().getContent());
System.out.println("Change data subject :" + message.getBody().getNickname());
System.out.println("Change data subject :" + message.getBody().getUserid());
System.out.println();
/*logger.info("Received Message in collection: {},message raw: {}, message body:{}",
message.getProperties().getCollectionName(), message.getRaw(), message.getBody());*/
}
}
ChangeStream class, event registration class, that is, the operations of several event types mentioned in the opening chapter
import com.congge.entity.Comment;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.mongodb.core.aggregation.Aggregation;
import org.springframework.data.mongodb.core.messaging.ChangeStreamRequest;
import org.springframework.data.mongodb.core.messaging.MessageListenerContainer;
import org.springframework.data.mongodb.core.query.Criteria;
@Configuration
public class ChangeStream implements CommandLineRunner {
@Autowired
private MongoMessageListener mongoMessageListener;
@Autowired
private MessageListenerContainer messageListenerContainer;
@Override
public void run(String... args) throws Exception{
ChangeStreamRequest<Comment> request = ChangeStreamRequest.builder(mongoMessageListener)
.collection("comment")
.filter(Aggregation.newAggregation(Aggregation.match(Criteria.where("operationType").in("insert","update","replace"))))
.build();
messageListenerContainer.register(request,Comment.class);
}
}
MongoConfig configures the relevant parameters of the MessageListenerContainer container
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.messaging.DefaultMessageListenerContainer;
import org.springframework.data.mongodb.core.messaging.MessageListenerContainer;
import java.util.concurrent.Executor;
import java.util.concurrent.Executors;
@Configuration
public class MongoConfig {
@Bean
MessageListenerContainer messageListenerContainer(MongoTemplate mongoTemplate){
Executor executor = Executors.newFixedThreadPool(5);
return new DefaultMessageListenerContainer(mongoTemplate,executor){
@Override
public boolean isAutoStartup(){
return true;
}
};
}
}
After adding the three classes, start the program again and observe the console data log
Test 1: log in to the primary node through the shell window and add a piece of data to the comment set
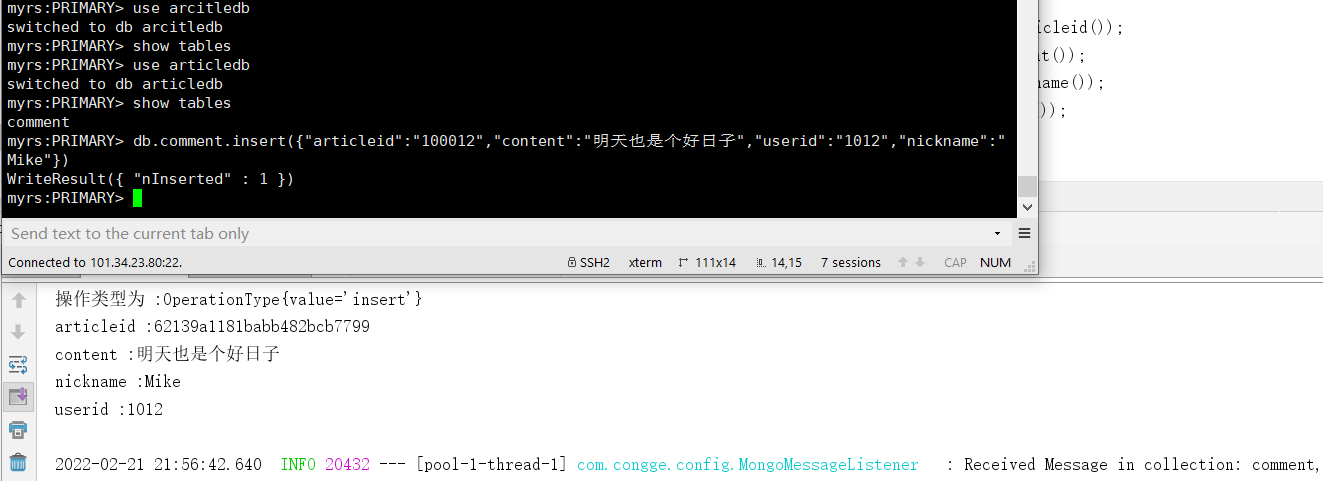
The data change of event operation is monitored almost in real time. The following is the complete output log
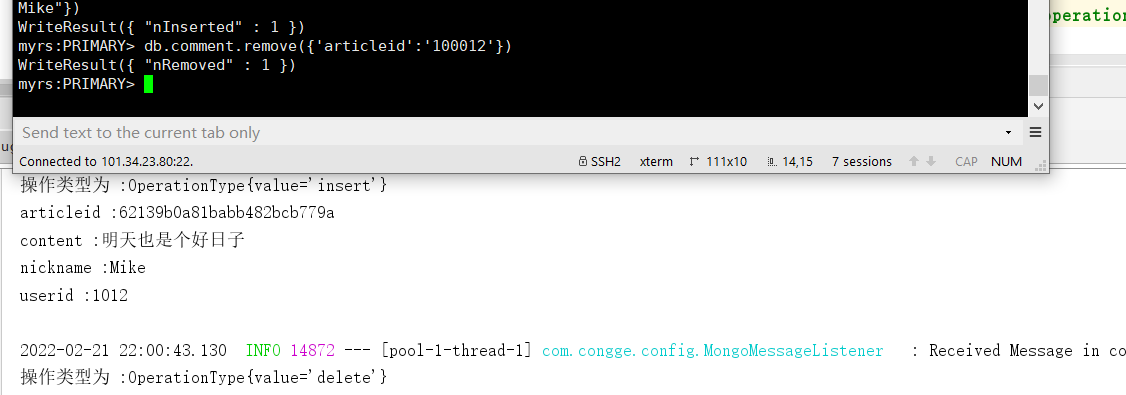
Test 2: delete the data added above through the shell window
Typical application scenarios
data migration
If the data of one system needs to be migrated to another system, you can consider using mongodb changestream. Imagine that if the data of the old system is very messy and there are some dirty data in the document, in order to ensure that the migrated data can be put into production quickly, the original data can be processed similar to ETL through the way of application, which is more convenient
Application monitoring
If your system has strict data supervision, you can consider using changestream to subscribe to data operations of specific events, such as modifying and deleting data, and then send alarm notifications in time
Docking big data applications
We know that mongodb, as a distributed document database with excellent performance, can actually store massive data. In some big data scenarios, such as other downstream applications using big data technology, it is necessary to analyze the trajectory behavior of the data in mongo. changestream is a good choice. When you hear the data changes of specific events, Push the corresponding messages to the message queue, such as kafka, and the downstream related big data applications can do subsequent business processing