The overall structure of ORC documents is as follows:
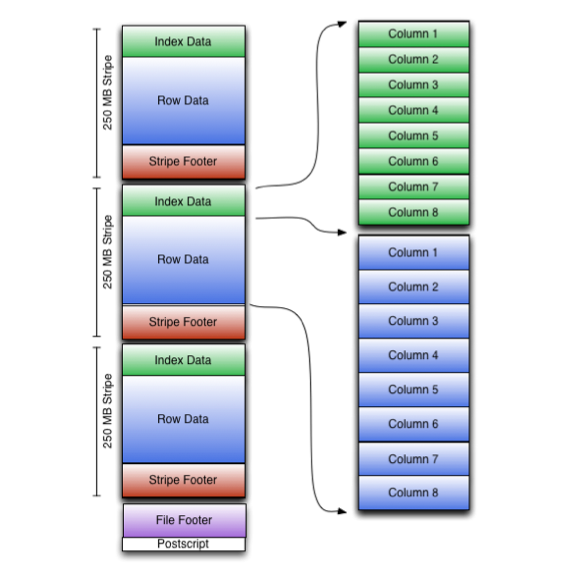
The searching and indexing of data in orc file structure is essentially three-level filtering: file level, Stripe level and Row Group level. In this way, the data actually to be scanned and read can be reduced to part of the RowGroup of part of the Stripe without scanning the whole file. That is, first read the file metadata from the end of the file, then jump to read the Stripe metadata, and finally read some data in the required Stripe.
1, File level
In order to skip unnecessary files in filter conditions such as where faster during SQL query, first record the metadata information at the file level through file tail at the file level. File tail is mainly composed of three parts from bottom to top: postscript, file footer and file metadata. They all use Protocol Buffers for storage (because they can provide the ability to add new fields without rewriting the reader).
1.1,PostScript
The postscript section provides the necessary information to explain the rest of the ORC file, including the length of the File Footer and Metadata sections, the version of the file, and the compression type used (such as none, zlib, or snappy). Postscript is never compressed and ends one byte before the end of the file (so the length of the entire File Tail is: footersize + metatasize + postscript size + 1 byte). The version stored in postscript is the minimum Hive version that can read files. It is stored as a sequence of major and minor versions.
The process of reading the ORC file is from the bottom to the front. ORC reader will directly read the last 16kb of the file and hope it contains both footer and postscript parts. The last byte of the file contains the serialization length of postscript, which must be less than 256 byte s. Once the postscript is parsed, the compressed serialization length of the footer is known and can be decompressed and parsed. The specific information saved in this structure is shown in the following figure:
message PostScript {
// the length of the footer section in bytes
optional uint64 footerLength = 1;
// the kind of generic compression used
optional CompressionKind compression = 2;
// the maximum size of each compression chunk
optional uint64 compressionBlockSize = 3;
// the version of the writer
repeated uint32 version = 4 [packed = true];
// the length of the metadata section in bytes
optional uint64 metadataLength = 5;
// the fixed string "ORC"
optional string magic = 8000;
}
enum CompressionKind {
NONE = 0;
ZLIB = 1;
SNAPPY = 2;
LZO = 3;
LZ4 = 4;
ZSTD = 5;
}The "magic" is called magic number. I understand that it is similar to the "ca fe ba be" at the beginning of java bytecode to make sure that the structure is indeed an ORC file conforming to the specification.
1.2,File footer
The Footer section contains the layout of the file body, type schema information, number of rows, and statistics about each column. The structure diagram at the beginning of the article shows that the ORC file is mainly divided into three parts: Header, body and tail. The Header consists of the byte "ORC" to support other tools that want to scan the beginning of the file to determine the file type. The body contains rows and indexes, and the tail provides file level information. Therefore, the File Footer in the tail mainly contains some meta information of these three parts, as shown below:
message Footer {
// the length of the file header in bytes (always 3)
optional uint64 headerLength = 1;
// the length of the file header and body in bytes
optional uint64 contentLength = 2;
// the information about the stripes
repeated StripeInformation stripes = 3;
// the schema information
repeated Type types = 4;
// the user metadata that was added
repeated UserMetadataItem metadata = 5;
// the total number of rows in the file
optional uint64 numberOfRows = 6;
// the statistics of each column across the file
repeated ColumnStatistics statistics = 7;
// the maximum number of rows in each index entry
optional uint32 rowIndexStride = 8;
// Each implementation that writes ORC files should register for a code
// 0 = ORC Java
// 1 = ORC C++
// 2 = Presto
// 3 = Scritchley Go from https://github.com/scritchley/orc
// 4 = Trino
optional uint32 writer = 9;
// information about the encryption in this file
optional Encryption encryption = 10;
// the number of bytes in the encrypted stripe statistics
optional uint64 stripeStatisticsLength = 11;
}1.2.1,Stripe Information
The ORC file is divided into multiple strips. This design allows you to determine which strips you actually need to read only by reading the PostScript at the end of the file and the value range Information in the File Footer (such as the maximum and minimum value of each strip content) when SQL has filtering conditions, and skip the reading of other strips in the file. Each stripe contains three parts: a set of indexes for each row in the stripe (each stripe contains a branch of the file), the data itself and the Stripe Footer. The index and data parts are divided by column, so only the data of the required column needs to be read. The Information of each stripe will be saved in the File Footer. The details are as follows:
message StripeInformation {
// the start of the stripe within the file
optional uint64 offset = 1;
// the length of the indexes in bytes
optional uint64 indexLength = 2;
// the length of the data in bytes
optional uint64 dataLength = 3;
// the length of the footer in bytes
optional uint64 footerLength = 4;
// the number of rows in the stripe
optional uint64 numberOfRows = 5;
// If this is present, the reader should use this value for the encryption
// stripe id for setting the encryption IV. Otherwise, the reader should
// use one larger than the previous stripe's encryptStripeId.
// For unmerged ORC files, the first stripe will use 1 and the rest of the
// stripes won't have it set. For merged files, the stripe information
// will be copied from their original files and thus the first stripe of
// each of the input files will reset it to 1.
// Note that 1 was choosen, because protobuf v3 doesn't serialize
// primitive types that are the default (eg. 0).
optional uint64 encryptStripeId = 6;
// For each encryption variant, the new encrypted local key to use until we
// find a replacement.
repeated bytes encryptedLocalKeys = 7;
}1.2.2,Type
All rows in the ORC file must have the same schema. The column type information is stored in the tree structure shown in the following figure. If it is a composite type such as Map, the leaf nodes will continue to spread downward:

The tree structure of such records actually represents the column types in the following table creation statements:
create table Foobar ( myInt int, myMap map<string, struct<myString : string, myDouble: double>>, myTime timestamp );
The type tree is flattened in a list through preorder traversal (similar to the storage structure of binary tree in the course of algorithm data structure), in which each type is assigned a self increasing id. Obviously, the root of the type tree is always type id 0. The composite type will have a field named subtypes, which contains the list of its subtype id. the stored proto structure is as follows:
message Type {
enum Kind {
BOOLEAN = 0;
BYTE = 1;
SHORT = 2;
INT = 3;
LONG = 4;
FLOAT = 5;
DOUBLE = 6;
STRING = 7;
BINARY = 8;
TIMESTAMP = 9;
LIST = 10;
MAP = 11;
STRUCT = 12;
UNION = 13;
DECIMAL = 14;
DATE = 15;
VARCHAR = 16;
CHAR = 17;
TIMESTAMP_INSTANT = 18;
}
// the kind of this type
required Kind kind = 1;
// the type ids of any subcolumns for list, map, struct, or union
repeated uint32 subtypes = 2 [packed=true];
// the list of field names for struct
repeated string fieldNames = 3;
// the maximum length of the type for varchar or char in UTF-8 characters
optional uint32 maximumLength = 4;
// the precision and scale for decimal
optional uint32 precision = 5;
optional uint32 scale = 6;
}1.2.3,Column Statistics
This statistic is that for each column, orc writer records the number of count s at the file level and records other useful fields according to the column type. For most basic types, min and max values are recorded; For digital types, sum will also be stored. In this way, in addition to skipping files that do not need to be read, you can also directly read the returned value of footer when selecting min, Max and sum in SQL without actually scanning each value of the whole file for aggregation. Starting from Hive 1.1.0, the hasNull flag can also be set to record whether there are any NULL values in the row group. Orc's predicate push down uses the hasNull flag to better filter "IS NULL" queries and skip rows with NULL corresponding columns. Therefore, it is recommended to use NULL instead of "-" and "" to represent NULL logic in SQL business, because NULL can trigger Orc's own predicate push down performance optimization. This structure stores the following information:
message ColumnStatistics {
// the number of values
optional uint64 numberOfValues = 1;
// At most one of these has a value for any column
optional IntegerStatistics intStatistics = 2;
optional DoubleStatistics doubleStatistics = 3;
optional StringStatistics stringStatistics = 4;
optional BucketStatistics bucketStatistics = 5;
optional DecimalStatistics decimalStatistics = 6;
optional DateStatistics dateStatistics = 7;
optional BinaryStatistics binaryStatistics = 8;
optional TimestampStatistics timestampStatistics = 9;
optional bool hasNull = 10;
}1.3,File Metadata
This section contains the column statistics of each Stripe level granularity (the column statistics in the File Footer above is the statistics of the whole file level). These statistics can skip the reading of some strips by using predicate push down according to the filter conditions in SQL. The contents stored in this part are as follows:
message StripeStatistics {
repeated ColumnStatistics colStats = 1;
}
message Metadata {
repeated StripeStatistics stripeStats = 1;
}2, Stripe class
The body of the ORC file consists of a series of strips. Each Stripe is usually about 200MB and independent of each other, and is usually handled by different tasks. The definition feature of column storage format is that the data of each column is stored separately, and the data read from the file should be proportional to the number of columns read.
In the ORC file, each column is stored in multiple streams, which are stored adjacent to each other in the file. For example, an integer column would be represented as two streams:
(1) PRESENT, if the value is not empty, a Stream is used, and one bit is recorded for each value.
(2) And record the DATA of non null value.
If the values of all columns in the Stripe are not empty, omit PRESENT stream from the Stripe. For binary DATA, ORC uses three streams: PRESENT, DATA, and LENGTH, which store the LENGTH of each value. Consistent with the structure diagram at the beginning of the article, the storage structure of each Stripe is shown in the following three parts:
index streams unencrypted encryption variant 1..N data streams unencrypted encryption variant 1..N stripe footer
2.1,Stripe Footer
It contains the code of each column and the of the Stream, as follows:
message StripeFooter {
// the location of each stream
repeated Stream streams = 1;
// the encoding of each column
repeated ColumnEncoding columns = 2;
optional string writerTimezone = 3;
// one for each column encryption variant
repeated StripeEncryptionVariant encryption = 4;
}2.1.1,Stream
To describe each Stream, the ORC stores the type, column ID, and size of the Stream in bytes. The details of what is stored in each Stream depend on the type and encoding of the column. In other words, each column in a Stripe may have multiple streams representing different information, and the storage contents are as follows:
message Stream {
enum Kind {
// boolean stream of whether the next value is non-null
PRESENT = 0;
// the primary data stream
DATA = 1;
// the length of each value for variable length data
LENGTH = 2;
// the dictionary blob
DICTIONARY_DATA = 3;
// deprecated prior to Hive 0.11
// It was used to store the number of instances of each value in the
// dictionary
DICTIONARY_COUNT = 4;
// a secondary data stream
SECONDARY = 5;
// the index for seeking to particular row groups
ROW_INDEX = 6;
// original bloom filters used before ORC-101
BLOOM_FILTER = 7;
// bloom filters that consistently use utf8
BLOOM_FILTER_UTF8 = 8;
// Virtual stream kinds to allocate space for encrypted index and data.
ENCRYPTED_INDEX = 9;
ENCRYPTED_DATA = 10;
// stripe statistics streams
STRIPE_STATISTICS = 100;
// A virtual stream kind that is used for setting the encryption IV.
FILE_STATISTICS = 101;
}
required Kind kind = 1;
// the column id
optional uint32 column = 2;
// the number of bytes in the file
optional uint64 length = 3;
}2.1.2,ColumnEncoding
Depending on the type of column, there may be several encoding options. Codes are divided into different types directly or based on dictionaries, and further refine whether they use RLE v1 or v2 (RLE, run length coding, a technology to reduce the space occupied by files. Multiple duplicate contents in files are stored only once, and the positions of duplicate values are indicated).
2.2,Index
2.2.1,Row Group Index
It consists of the row of each original column_ Index Stream, each original column has RowIndexEntry. Row groups are controlled by orc writer. By default, there is one row group for 10000 rows. A Stripe may have multiple row groups, so there may also be multiple row group index es. Each RowIndexEntry gives the position of each Stream in the column and the statistical information of the row group, so a RowIndexEntry corresponds to a row group.
Index streams are placed at the beginning of each Stripe (just like the green part of the structure diagram at the beginning of the article), because they do not need to be read under the default streaming condition, except when using predicate push down or orc reader to find a specific row. The contents stored in Row Group Index are as follows:
message RowIndexEntry {
repeated uint64 positions = 1 [packed=true];
optional ColumnStatistics statistics = 2;
}
message RowIndex {
repeated RowIndexEntry entry = 1;
}In order to record position, each Stream needs a numeric list. RLE is the number of bytes required to read from the uncompressed position in the Stream. In a compressed Stream, the first number is the beginning of the compressed block in the Stream, followed by the number of decompressed bytes to be read, and finally the number of values read in RLE.
For columns with multiple streams, the sequence of positions in each Stream is connected. Code that uses indexes is error prone here.
Because the dictionary is accessed randomly, there is no place to record the dictionary. Even if only part of the Stripe is read, the whole dictionary must be read.
2.2.2,Bloom Filter Index
Since Hive 1.2.0, Bloom Filters have been added to the orc index. Predicate pushdown can use bloom filter to better prune row groups that do not meet the filtering conditions. Bloom Filter Index is the bloom of each column specified through the "orc.bloom.filter.columns" table property_ Filter stream. BLOOM_FILTER Stream records a bloom filter entry for each row group (10000 rows by default) in the column. Only row groups that meet the min/max row index range will be evaluated according to the Bloom Filter Index.
Each bloom filter entry stores the number of hash functions ('k ') used and the BitSet that supports Bloom filters. The original coding of Bloom filter (before ORC-101) uses BitSet field to encode the long repeat sequence in BitSet field, and uses small end sequence coding (0x1 is bit 0, 0x2 is bit 1) After ORC-101, encoding is a byte sequence with small end encoding in utf8bitset field.
The storage content of Bloom Filter Index is shown in the following figure:
message BloomFilter {
optional uint32 numHashFunctions = 1;
repeated fixed64 bitset = 2;
optional bytes utf8bitset = 3;
}
message RowIndex {
repeated RowIndexEntry entry = 1;
}Bloom Filter Stream interleaves with Row Group Index. This layout facilitates the simultaneous reading of bloom stream and row index stream in a single read operation.
3, Compress
If the orc file writer selects the compression method (zlib or snappy), other parts except Postscript will be compressed. However, one of the requirements of ORC is that the reader can skip the compressed bytes without decompressing the whole Stream. To manage this, ORC writes the compressed Stream into the block with header, as shown in the following figure:

In order to process uncompressed data, if the compressed data is larger than the original data, the original data is stored and the isOriginal flag is set. Each header is 3 bytes long, that is, (compressedLength * 2 + isOriginal) is stored as a small end value. For example, the header of a block compressed to 100000 bytes would be [0x40, 0x0d, 0x03]. The uncompressed 5-byte header is [0x0b, 0x00, 0x00]. Each compressed block is compressed independently, so as long as the decompressor starts from the top of the header, it can start decompressing without other previous bytes.