1. Regular expression symbols
| ? | Match zero or one previous grouping |
|---|---|
| * | Matches zero or more previous groups |
| + | Match one or more previous groups |
| {n} | Match n previous groups |
| {n,} | Match n or more previous groups |
| {,m} | Match zero to m previous groups |
| {n,m} | Match the previous group at least n times and at most m times |
| {n,m}? Or *? Or +? | Non greedy matching of the previous groups |
| ^spam | This means that the string must start with spam |
| spam$ | This means that the string must end with spam |
| . | Matches all characters except line breaks |
| \d \w \s | Match numbers, words, and spaces, respectively |
| \D \W \S | Match all characters except numbers, words and spaces |
| [abc] | Matches any character in parentheses (such as a, b, or c) |
| [^abc] | Matches any character that is not within square brackets |
2. Create regular expression object
All regular expression functions in python are in the re module.
import re
2.1 regular expression matching steps:
- import re import regular expression module
- Create a Regex object (using the original string) with the re.compile() function
- Pass the string you want to find into the search() method of the Regex object. It returns a Match object
- Call the group() method of the Match object to return the string of the actual matching text
#!/usr/bin/python3
import re
hero=re.compile(r'Batman')
mo=hero.search('Batman and Tina')
mo.group()
| Pipe symbol | You can match one of many expressions |
|---|
The first occurrence of matching text is returned as a Match object
The Match object returned by search() contains only the matching text that appears for the first time
Use the findall() method to include all matches in the found string
#!/usr/bin/python3
import re
hero = re.compile(r'Batman | Tina')
mo = hero.search('Batman and Tina Fey')
print(mo.group())
print(hero.findall('Batman and Tina Fey'))

| ? | Indicates that the grouping before it is optional |
|---|
#!/usr/bin/python3
import re
bat = re.compile(r'Bat(wo)?man')
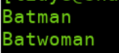
mo = bat.search('The Adventures of Batman')
print(mo.group())
mo1 = bat.search('The Adventures of Batwoman')
print(mo1.group())
Use curly braces to match a specific number of times, or you can not write the first or second number in curly braces, and do not limit the minimum or maximum value
#!/usr/bin/python3
import re
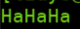
ha = re.compile(r'(Ha){3}')
mo = ha.search('HaHaHa')
print(mo.group())
2.2 greedy and non greedy matching
python's regular expressions are "greedy" by default, which means that in case of ambiguity, they will match the longest string as much as possible. The "non greedy" version of the curly braces matches the shortest possible string, that is, the closing curly braces are followed by a question mark
#!/usr/bin/python3
import re
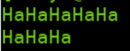
ha = re.compile(r'(Ha){3,5}')
mo = ha.search('HaHaHaHaHa')
print(mo.group())
ha1 = re.compile(r'(Ha){3,5}?')
mo1 = ha1.search('HaHaHaHaHa')
print(mo1.group())
2.3 create your own character classification
You can use a short horizontal bar to represent the range of letters or numbers, and add an insertion character (^) after the left square bracket to get the "non character class"
| [a-zA-Z0-9] | Matches all lowercase letters, uppercase letters, and numbers |
|---|---|
| [^aeio] | Matches all characters that are not in this character class |
2.4 insert characters and dollar characters
You can use the caret (^) at the beginning of the regular expression and the dollar sign ($) at the end of the regular expression
| ^ | The match must occur at the beginning of the text being found |
|---|---|
| $ | The string must end in the pattern of this regular expression |
2.5 wildcards
The. (period) character is called a wildcard. It matches all characters except line feed. It matches only one character
| .* | Match any text, greedy mode |
|---|---|
| .*? | Match any text, non greedy mode |
By passing in re.DOTALL as the second parameter of re.compile(), you can make the period character match all characters, including newline characters
newlineRegex = re.compile('.*', re.DOTALL)
newlineRegex.search('Serve the public trust.\nProtect the innocent.
\nUphold the law.').group()
2.6 case insensitive matching
Pass re.I to re.compile() as the second parameter
ro = re.compile(r'robocop',re.I)
2.7 replace string with sub() method
The sub() method needs to pass in two parameters. The first parameter is a string that replaces the found match. The second parameter is a string, a regular expression. The sub() method returns the string after the replacement is completed.
#!/usr/bin/python3
import re
namesRegex = re.compile(r'Agent \w+')
print(namesRegex.sub('CENSORED', 'Agent Alice gave the secret documents to Agent Bob.'))

2.8 managing complex regular expressions
Matching complex text patterns can alleviate this by telling re.compile() to ignore whitespace and comments in regular expression strings. To implement this verbose mode, you can pass the variable re.VERBOSE to re.compile() as the second parameter.
This allows regular expressions to be placed on multiple lines and annotated.
phoneRegex = re.compile(r'''(
(\d{3}|\(\d{3}\))? # area code
(\s|-|\.)? # separator
\d{3} # first 3 digits
(\s|-|\.) # separator
\d{4} # last 4 digits
(\s*(ext|x|ext.)\s*\d{2,5})? # extension
)''', re.VERBOSE)