Chapter 1: three problems in concurrent programming
1. Visibility
target
Learn what visibility issues are
Visibility concept
Visibility: when one thread modifies a shared variable, the other needs to get the latest modified value immediately.
Visibility presentation
Case demonstration: one thread loops according to the flag and while of boolean type. Another thread changes the value of this flag variable, and the other thread will not stop the loop.
/*
Objective: to demonstrate visibility issues
1.Create a shared variable
2.Create a thread that constantly reads shared variables
3.Create a thread to modify shared variables
*/
public class TestVisibility {
// 1. Create a shared variable
private static boolean flag = true;
public static void main(String[] args) throws InterruptedException {
// 2. Create a thread to continuously read shared variables
new Thread(() -> {
while(flag){
}
}).start();
Thread.sleep(2000);
// 3. Create a thread to modify shared variables
new Thread(() -> {
flag = false;
System.out.println("The thread modified the value of the variable to false");
}).start();
}
}
Conclusion: during concurrent programming, there will be visibility problems. When one thread modifies the shared variable, the other thread does not immediately see the latest modified value.
2. Atomicity
target
Learn what atomic problems are
Atomicity concept
Atomicity: in one or more operations, either all operations are performed and will not be disturbed by other factors, or none is performed
Atomicity demonstration
Case demonstration: five threads execute 1000 times i++
public class Test02Atomicity {
// 1. Define a shared variable number
private static int number = 0;
public static void main(String[] args) throws InterruptedException {
// 2. Perform 1000 + + operations on number
// 3. Run 5 threads to
List<Thread> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
Thread t = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
number++;
}
});
t.start();
list.add(t);
}
for (Thread t : list) {
t.join();
}
System.out.println("number = " + number);
}
}
Because number + + is composed of multiple statements
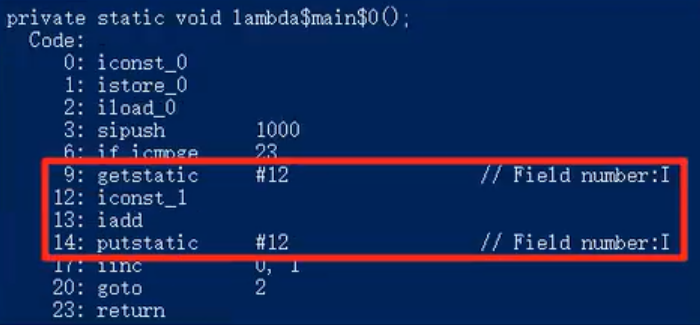
For number + + (number is a static variable), the following JVM bytecode instructions will actually be generated:

It can be seen that number + + is composed of multiple statements. When the above multiple instructions are executed in one thread, there will be no problem. However, when multiple threads are executed, for example, when one thread executes 13: iadd, another thread executes 9: getstatic. Will result in number + + twice, actually only + 1.
Summary
There will be atomicity problems in concurrent programming. During the access process of one thread, another thread also accesses variables. When writing back, it will be returned with the result of the last executed thread.
3. Order
Order concept
Ordering: it refers to the execution order of the code in the program. Java will optimize the code at compile time and run time, which will lead to the final execution order of the program, not necessarily the order when we write the code.
Chapter 2: Java Memory Model (JMM)
Before introducing the Java memory model, look at the computer memory model.
Introduction to computer structure
Von Neumann proposed that the computer consists of five parts.
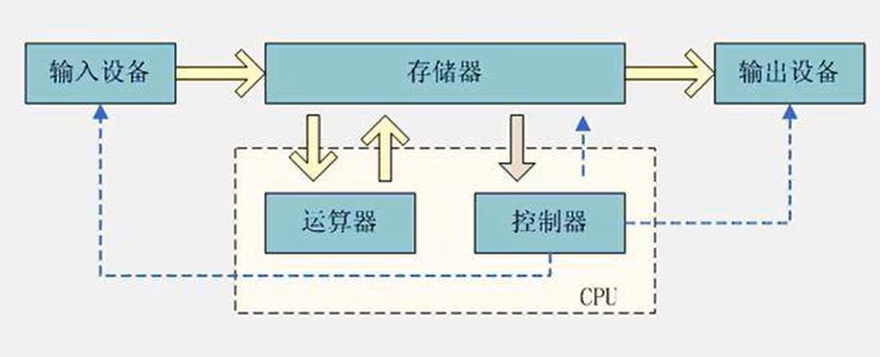
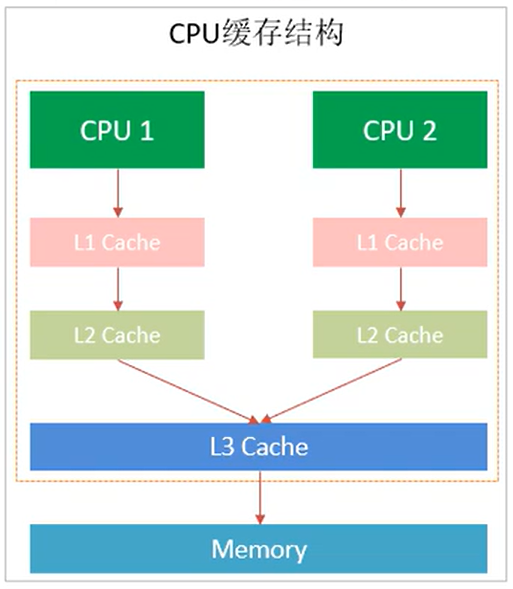
There is a big difference between the operation speed of CPU and the access speed of memory. This causes the CPU to spend a lot of waiting time each time it operates on memory. The reading and writing speed of memory has become the bottleneck of computer operation. So there is a design to add cache between CPU and main memory.
Java Memory Model
1. Concept of Java Memory Model
Java Memory Model (Java Memory Model / JMM) should not be confused with JAVA memory structure.
JAVA memory model is a memory model defined in the Java virtual machine specification. JAVA memory model is standardized and shields the differences between different underlying computers.
The JAVA memory model is a set of specifications that describe the access rules of various variables (thread shared variables) in Java programs, as well as the underlying details of storing variables into memory and reading variables from memory in the JVM.
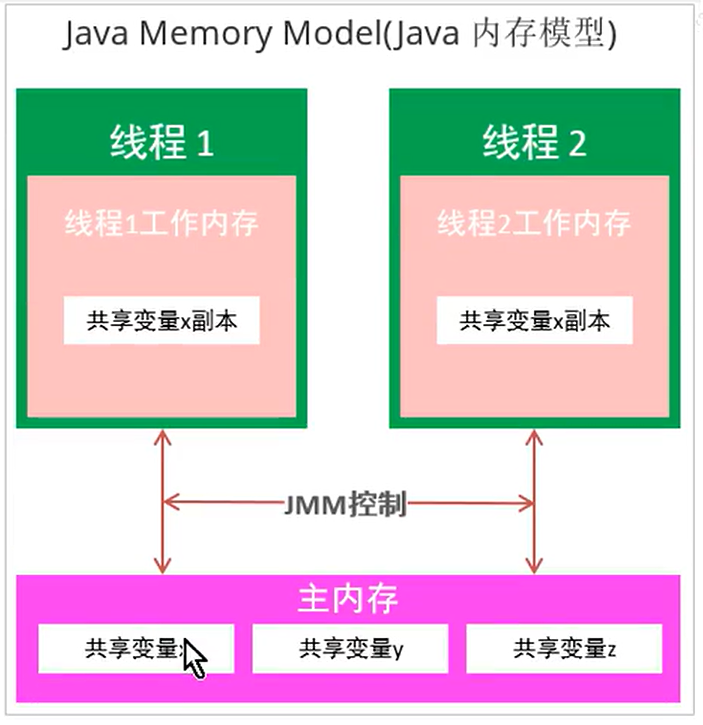
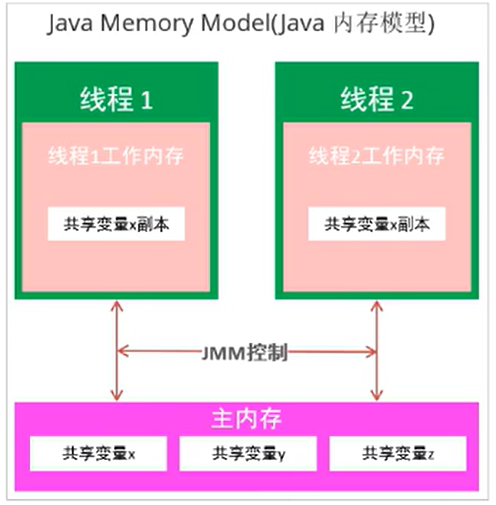
Main memory
Main memory is shared and accessible by all threads. All shared variables are stored in main memory.
Working memory
Each thread has its own working memory, which can only store a copy of the thread's shared variables. All operations (reading and fetching) of a thread on variables must be completed in the working memory, and variables in the main memory cannot be read or written directly. Different threads cannot directly access variables in each other's working memory.
2. Role of Java Memory Model
Java memory model is a set of rules and guarantees for the visibility, order and atomicity of shared data when multithreading reads and writes shared data
Mainly: synchronized, volatile
Relationship between JMM memory model and CPU hardware memory architecture:
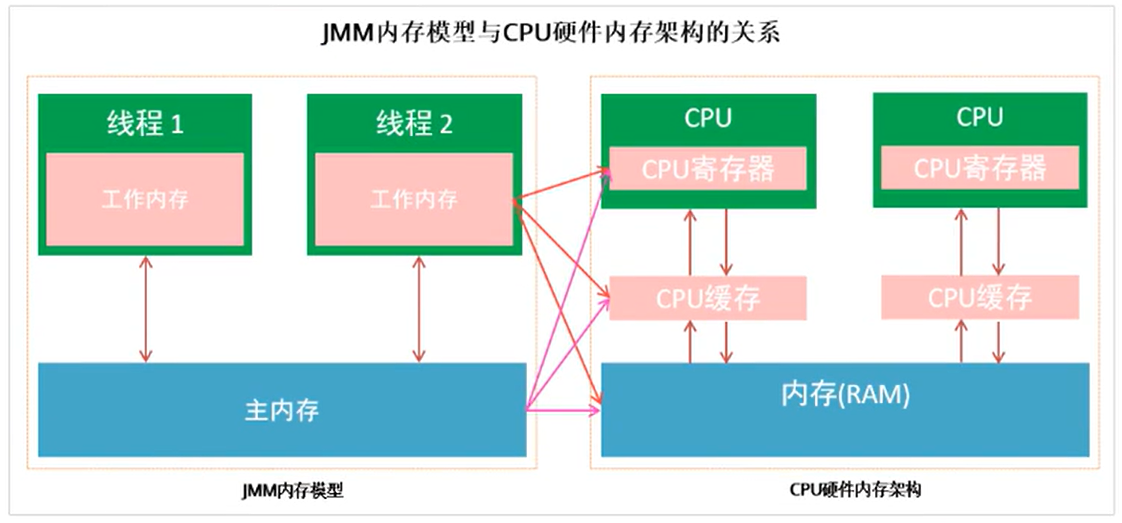
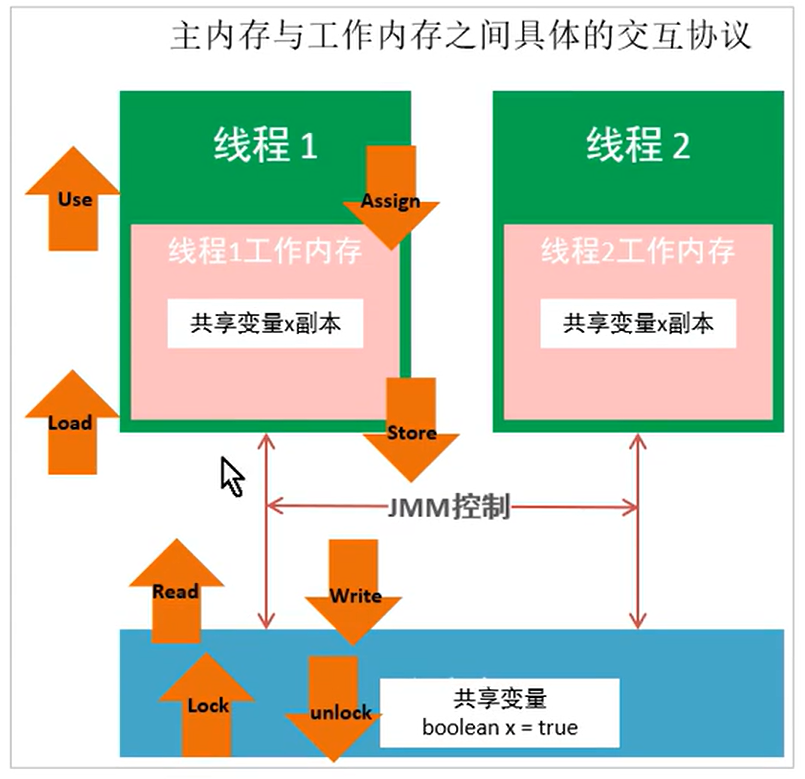
3. Interaction between main memory and working memory
The Java memory model defines the following eight operations to complete. The specific interaction protocol between main memory and working memory, that is, the implementation details of how to copy a variable from main memory to working memory and how to synchronize it back to main memory. During the implementation of virtual machine, it must ensure that each operation mentioned below is atomic and inseparable.
Supplement:
4. Inter thread communication
Inter thread communication can be defined as: when multiple threads operate shared resources together, threads inform each other of their status in some way to avoid invalid resource contention.
What are the communication between threads? There are three main types: wait notification, shared memory, and pipeline flow
Wait - Notification:
To be added
Chapter 3: three features of synchronized assurance
synchronized can ensure that at most one thread executes the code at the same time, so as to ensure concurrency safety.
synchronized (Lock object) {
// Protected resources;
}
synchronized and atomicity
public class Test02Atomicity {
// 1. Define a shared variable number
private static int number = 0;
private static Object obj = new Object();
public static void main(String[] args) throws InterruptedException {
// 2. Perform 1000 + + operations on number
// 3. Run 5 threads to
List<Thread> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
Thread t = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
synchronized (obj){
number++;
}
}
});
t.start();
list.add(t);
}
for (Thread t : list) {
t.join();
}
System.out.println("number = " + number);
}
}
The principle of synchronized ensuring atomicity
Ensure that only one thread operates on the contents of the code block at the same time. The principle of synchronized ensuring atomicity is that synchronized ensures that only one thread gets the lock and can enter the synchronized code block.
synchronized and visibility
public class Test01Visibility {
// 1. Create a shared variable
private static boolean flag = true;
private static Object obj = new Object();
public static void main(String[] args) throws InterruptedException {
// 2. Create a thread to continuously read shared variables
new Thread(() -> {
while (flag){
synchronized (obj){
}
}
}).start();
Thread.sleep(2000);
// 3. Create a thread to modify shared variables
new Thread(() -> {
while (flag){
flag = false;
System.out.println("The thread modified the variable value to false");
}
}).start();
}
}
Synchronized ensures visibility. When synchronized is executed, the corresponding lock atomic operation will refresh the value of the shared variable in the working memory.
Supplement: system out. println(); The synchronized keyword is also included in the
synchronized and ordered
Why reorder
In order to improve the execution efficiency of the program, the compiler and CPU will reorder the code in the program.
As if serial semantics
As if serial semantics means that no matter how the compiler and CPU reorder, the program result must be correct in the case of single thread.
The principle of synchronized ensuring order
Although reordering will still occur after synchronized, our synchronized code block can ensure that only one thread executes the code in the synchronized code block to ensure order.
Chapter 4: characteristics of synchronized
Reentrant property
What is reentrant
A thread can execute synchronized multiple times and acquire the same lock repeatedly
class MyThread extends Thread {
@Override
public void run(){
synchronized (MyThread.class) {
System.out.println(getName() + "Synchronization code block 1 entered");
synchronized (MyThread.class) {
System.out.println(getName() + "Synchronization code block 2 entered");
}
}
}
}
Reentrant principle
There is a counter (recursions variable) in the synchronized lock object that records how many times the thread obtains the lock.
Reentrant locks refer to threads. When a thread acquires an object lock, the thread can acquire the lock on the object again, while other threads cannot.
Reentrant benefits
1. Deadlock can be avoided
2. It can better encapsulate the code
Summary
synchronized is a reentrant lock. In the internal lock object, there will be a counter recording thread that obtains the lock several times. When the synchronization code block is executed, the number of counters will be - 1 until the number of counters is 0, and the lock will be released.
Non interruptible feature
What is non interruptible
After a thread obtains a lock, another thread must be in a blocking or waiting state if it wants to obtain a lock. If the first thread does not release the lock, the second thread will always block or wait and cannot be interrupted.
synchronized is non interruptible
Lock is both interruptible and non interruptible.
synchronized:
private static Object obj = new Object();
public static void main(String[] args) throws InterruptedException {
// 1. Define a Runnable
Runnable run = () -> {
// 2. Define synchronization code block in Runnable
synchronized (obj){
String name = Thread.currentThread().getName();
System.out.println(name + "Enter synchronization code block");
try {
Thread.sleep(888888);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
// 3. Start a thread to execute the synchronous code block first
Thread t1 = new Thread(run);
t1.start();
Thread.sleep(1000);
// 4. After that, start a thread to execute the synchronous code block (blocking state)
Thread t2 = new Thread(run);
t2.start();
// 5. Stop the second thread
System.out.println("Before stopping the thread");
t2.interrupt();
System.out.println("After stopping the thread");
System.out.println(t1.getState());
System.out.println(t2.getState()); // Blocked
}
Non interruptible of Lock:
private static Lock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
test01();
}
// Demonstrate non interruptible Lock
public static void test01() throws InterruptedException {
Runnable run = () -> {
String name = Thread.currentThread().getName();
try{
lock.lock();
System.out.println(name + "Obtain the lock and enter the lock to execute");
Thread.sleep(88888);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
System.out.println(name + "Release lock");
}
};
Thread t1 = new Thread(run);
t1.start();
Thread.sleep(1000);
Thread t2 = new Thread(run);
t2.start();
System.out.println("stop it t2 Before thread");
t2.interrupt();
System.out.println("stop it t2 After thread");
System.out.println(t1.getState());
System.out.println(t2.getState()); // Using the Lock method cannot be interrupted
}
Interruptible of Lock:
// Demonstrate that Lock is interruptible
public static void test02() throws InterruptedException {
Runnable run = () -> {
String name = Thread.currentThread().getName();
boolean b = false;
try{
b = lock.tryLock(3, TimeUnit.SECONDS);
if (b){
System.out.println(name + "Obtain the lock and enter the lock to execute");
Thread.sleep(88888);
} else {
System.out.println(name + "Do not get the lock at the specified time for other operations");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (b){
lock.unlock();
System.out.println(name + "Release lock");
}
}
};
Thread t1 = new Thread(run);
t1.start();
Thread.sleep(1000);
Thread t2 = new Thread(run);
t2.start();
// System.out.println("before stopping t2 thread");
// t2.interrupt();
// System.out.println("after stopping t2 thread");
//
// Thread.sleep(1000);
// System.out.println(t1.getState());
// System.out.println(t2.getState());
}
Chapter V principle of synchronized
javap disassembly
Simply write a synchronized code as follows:
public class Demo01 {
private static Object obj = new Object();
public static void main(String[] args) {
synchronized (obj){
System.out.println("1");
}
}
public synchronized void test(){
System.out.println("a");
}
}
It depends on the principle of synchronized, but because synchronized is a keyword, you can't see the source code, so disassemble the file
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: getstatic #2 // Field obj:Ljava/lang/Object;
3: dup
4: astore_1
5: monitorenter
6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
9: ldc #4 // String 1
11: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
14: aload_1
15: monitorexit
16: goto 24
19: astore_2
20: aload_1
21: monitorexit
22: aload_2
23: athrow
24: return
Exception table:
from to target type
6 16 19 any
19 22 19 any
LineNumberTable:
line 7: 0
line 8: 6
line 9: 14
line 10: 24
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 19
locals = [ class "[Ljava/lang/String;", class java/lang/Object ]
stack = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 4
public synchronized void test();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #6 // String a
5: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 12: 0
line 13: 8
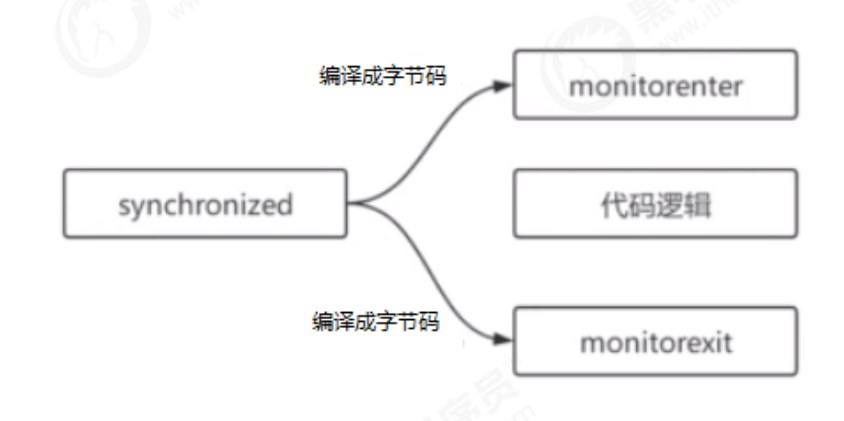
monitorenter
First, let's take a look at the description of monitorenter in the JVM specification:
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-6.html#jvms-6.5.monitorenter
Each object is associated with a monitor. When the monitor is occupied, it will be locked, and other threads cannot get the monitor. When the JVM executes the monitorenter inside a method of a thread, it will try to obtain the ownership of the monitor corresponding to the current object. The process is as follows:
1. The entry number of monitor is 0. The thread can enter monitor and set the entry number of monitor to 1. The current thread becomes the owner of monitor
2. If the thread has the ownership of the monitor and is allowed to rush into the monitor, the number of entries into the monitor will be increased by 1
3. If other threads already own the monitor, the thread currently trying to acquire the monitor's ownership will be blocked. Only when the number of monitor entries becomes 0 can they try to acquire the monitor's ownership again
Summary of monitorenter:
The synchronized lock object will be associated with a monitor. This monitor is not created on our own initiative, but the synchronization code block executed by the JVM thread. If it is found that the lock object does not have a monitor, it will create a monitor. There are two important member variables in the monitor: owner: the thread that owns the lock, and recursions will record the number of times the thread owns the lock, When a thread has a monitor, other threads can only wait.
monitorexit
First, let's take a look at the description of monitorexit in the JVM specification:
1. The thread that can execute the monitorexit instruction must be the thread that owns the ownership of the monitor of the current object.
2. When you execute monitorexit, the number of monitor entries will be reduced by 1. When the number of monitor entries decreases to 0, the current thread exits the monitor and no longer owns the ownership of the monitor. At this time, other threads blocked by the monitor can try to obtain the ownership of the monitor.
monitorexit releases the lock.
Monitorexit is inserted at the end of the method and at the exception. The JVM ensures that each monitorenter must have a corresponding monitorexit.
Will the lock be released if the interview question synchronized is abnormal?
Will release the lock.
Synchronization method
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.11.10
It can be seen that the ACC will be increased after the synchronization method is de compiled_ Synchronized modification. monitorenter and monitorexit are implicitly called. monitorenter will be called before executing the synchronization method, and monitorexit will be called after executing the synchronization method.
Interview question: the difference between synchronized and Lock
- synchronized is the keyword and Lock is an interface.
- synchronized automatically releases the Lock, and Lock must release the Lock manually. unlock()
- synchronized is non interruptible. Lock can be interrupted or not.
- Through Lock, you can know whether the thread has got the Lock, but synchronized cannot. trylock()
- synchronized can Lock methods and code blocks, while Lock can only Lock code blocks.
- Lock can use read lock to improve multi-threaded read efficiency.
- synchronized is a non fair lock, and ReentrantLock can control whether it is a fair lock. (whether it is a fair lock created during construction)
In depth JVM source code
monitor lock
See youdaoyun notes for details
monitor is a heavyweight lock
You can see that atomic:: cmpxchg is involved in the function call of ObjectMonitor_ ptr,Atomic::inc_ptr and other kernel functions execute synchronous code blocks. Objects that do not compete for locks will park() be suspended, and competing threads will unpark() wake up. At this time, there will be a conversion between user state and kernel state of the operating system, which will consume a lot of system resources. Therefore, synchronized is a heavyweight operation in the Java language.
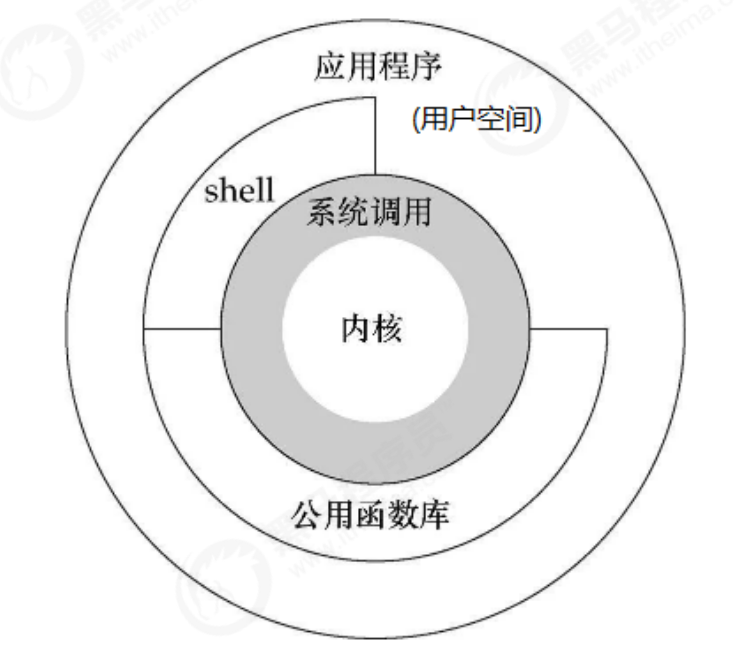
What are user state and kernel state? To understand user mode and kernel mode, you also need to understand the architecture of Linux system:
Chapter 6: JDK6 synchronized optimization
CAS
CAS overview and role
CAS (Compare And Swap) is a special instruction widely supported by modern CPU to operate shared data in memory.
Role of CAS: CAS can convert comparison and exchange into atomic operation, which is directly guaranteed by CPU. CAS can guarantee the atomic operation when assigning shared variables.
CAS operation depends on three values: the value V in memory, the old estimated value X, and the new value B to be modified. If the old estimated value X is equal to the value V in memory, the new value B is saved in memory.
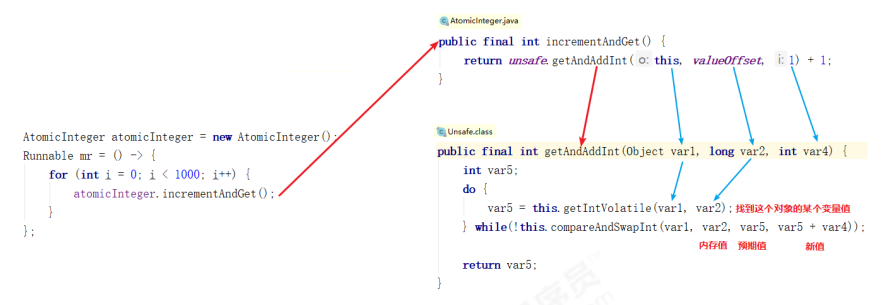
CAS and volatile implement lock free concurrency
public class Demo01 {
// 1. Define a shared variable number
private static AtomicInteger atomicInteger = new AtomicInteger();
public static void main(String[] args) throws InterruptedException {
// 2. Perform 1000 + + operations on number
// 3. Run 5 threads to
List<Thread> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
Thread t = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
atomicInteger.incrementAndGet(); // Ensure the atomicity of variable assignment
}
});
t.start();
list.add(t);
}
for (Thread t : list) {
t.join();
}
System.out.println("number = " + atomicInteger.get());
}
}
CAS principle
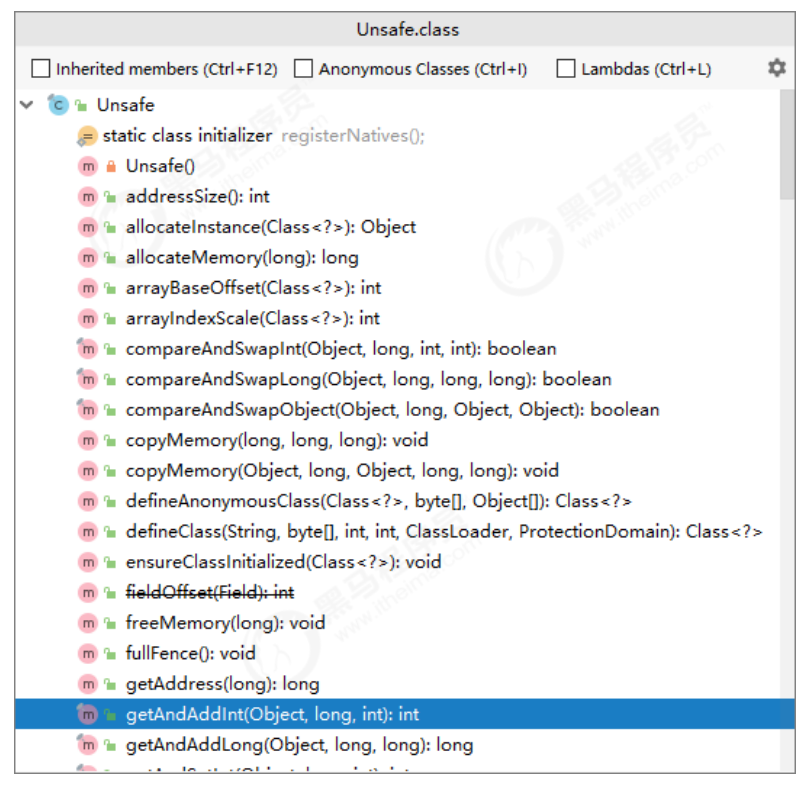
From the source code of AtomicInteger just now, we can see that the Unsafe class provides atomic operations.
Introduction to Unsafe class
Unsafe class makes Java have the ability to operate memory space like the pointer of C language. At the same time, it also brings the problem of pointer. Excessive use of unsafe classes will increase the probability of errors. Therefore, Java officials do not recommend it, and there are few official documents. Unsafe objects cannot be called directly and can only be obtained through reflection.
Unsafe implements CAS
Optimistic lock and pessimistic lock
Pessimistic lock from a pessimistic perspective:
Always assume the worst case. Every time I go to get the data, I think others will modify it, so I lock it every time I get the data, so others will block it if they want to get the data. Therefore, synchronized is also called pessimistic lock. ReentrantLock in JDK is also a pessimistic lock. Poor performance!
Optimistic lock from an optimistic perspective:
Always assume the best situation. Every time you go to get the data, you think others will not modify it. Even if you do, it doesn't matter. Just try again. Therefore, it will not be locked, but during the update, it will be judged whether others have modified the data during this period, and how to update if no one has modified it. If someone has modified it, try again.
CAS mechanism can also be called optimistic lock. Good comprehensive performance!
When CAS obtains a shared variable, volatile modification needs to be used to ensure the visibility of the variable. The combination of CAS and volatile can realize lock free concurrency, which is suitable for the scenario of non fierce competition and multi-core CPU.
1. Because synchronized is not used, the thread will not be blocked, which is one of the factors to improve efficiency.
2. However, if the competition is fierce, it can be expected that retry will occur frequently, but the efficiency will be affected.
Summary
The role of CAS? Compare And Swap, CAS can convert comparison and exchange into atomic operations, which are directly guaranteed by the processor.
How does CAS work? CAS needs three values: memory address V, the old expected value A, and the new value B to be modified. If memory address V is equal to the old expected value A, modify the memory address value to B. See the implementation code of AtomicInteger for details.
synchronized lock upgrade process
Efficient concurrency is an important improvement from JDK 5 to JDK 6. The HotSpot virtual machine development team spent a lot of energy on this version to implement various lock optimization technologies, including Biased Locking, Lightweight Locking, adaptive spinning, lock elimination, Lock Coarsening, etc, These technologies are to share data more efficiently between threads and solve the problem of competition, so as to improve the execution efficiency of programs.
No lock – deflection lock – lightweight lock – heavyweight lock
Layout of Java objects
Term reference: http://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html
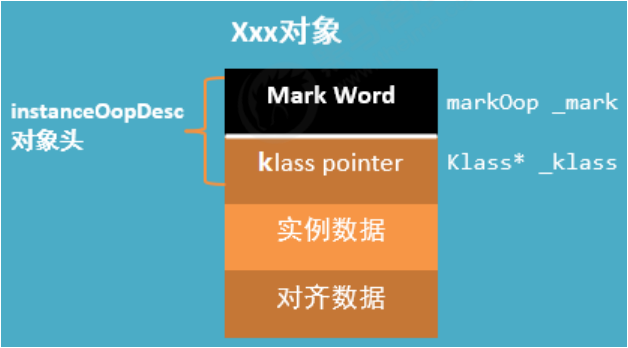
In the JVM, the layout of objects in memory is divided into three areas: object header, instance data, and alignment padding. As shown in the figure below:
Object header
When a thread attempts to access a synchronized modified code block, it first needs to obtain a lock, so where does the lock exist? Is stored in the object header of the lock object.
Hotspot uses instanceOopDesc and arrayopdesc to describe the object header, and arrayopdesc object is used to describe the array type. The instanceOopDesc is defined in the instanceoop. Com of the Hotspot source code In the HPP file, in addition, the definition of arrayOopDesc corresponds to arrayoop hpp .
class instanceOopDesc : public oopDesc {
public:
// aligned header size.
static int header_size() { return sizeof(instanceOopDesc)/HeapWordSize; }
// If compressed, the offset of the fields of the instance may not be aligned.
static int base_offset_in_bytes() {
// offset computation code breaks if UseCompressedClassPointers
// only is true
return (UseCompressedOops && UseCompressedClassPointers) ?
klass_gap_offset_in_bytes() :
sizeof(instanceOopDesc);
}
static bool contains_field_offset(int offset, int nonstatic_field_size) {
int base_in_bytes = base_offset_in_bytes();
return (offset >= base_in_bytes &&
(offset-base_in_bytes) < nonstatic_field_size * heapOopSize);
}
};
From the instanceOopDesc code, you can see that instanceOopDesc inherits from oopDesc. The definition of oopDesc is contained in OOP in the Hotspot source code HPP file.
class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
// Fast access to barrier set. Must be initialized.
static BarrierSet* _bs;
// Omit other codes
};
In a normal instance object, the definition of oopDesc contains two members, namely_ mark and_ metadata
_ Mark refers to the object tag and belongs to markOop type, which is the Mark World to be explained next. It records the information related to the object and lock
_ Metadata represents class meta information. Class meta information stores the first address of class metadata (Klass) that the object points to, where Klass represents ordinary pointer_ compressed_klass represents a compressed class pointer.
The object header consists of two parts. One part is used to store its own runtime data, called Mark Word, and the other part is the type pointer and the pointer of the object to its class metadata.
Mark World
Mark Word is used to store the runtime data of the object itself, such as HashCode, GC generation age, lock status flag, lock held by thread, biased thread ID, biased timestamp, etc. the occupied memory size is consistent with the bit length of the virtual machine. The corresponding type of Mark Word is markOop. The source code is located in markOop.hpp.
// Bit-format of an object header (most significant first, big endian layout below): // // 32 bits: // -------- // hash:25 ------------>| age:4 biased_ Lock: 1 lock: 2 (normal object) in a 64 bit virtual machine, Mark Word is 64 bit in size, and its storage structure is as follows: // JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object) // size:32 ------------------------------------------>| (CMS free block) // PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object) // // 64 bits: // -------- // unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object) // PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object) // size:64 ----------------------------------------------------->| (CMS free block) // [JavaThread* | epoch | age | 1 | 01] lock is biased toward given thread // [0 | epoch | age | 1 | 01] lock is anonymously biased // // - the two lock bits are used to describe three states: locked/unlocked and monitor. // // [ptr | 00] locked ptr points to real header on stack // [header | 0 | 01] unlocked regular object header // [ptr | 10] monitor inflated lock (header is wapped out) // [ptr | 11] marked used by markSweep to mark an object // not valid at any other time
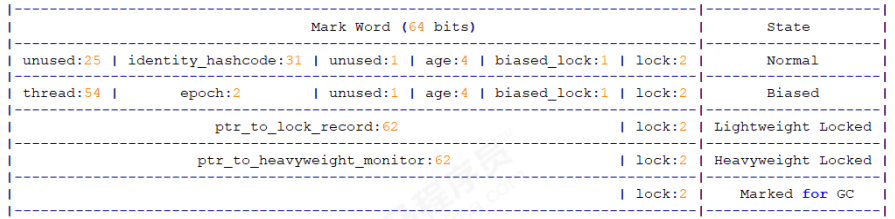
Under the 64 bit virtual machine, Mark Word is 64bit in size, and its storage structure is as follows:

Under the 32-bit virtual machine, Mark Word is 32bit in size, and its storage structure is as follows:
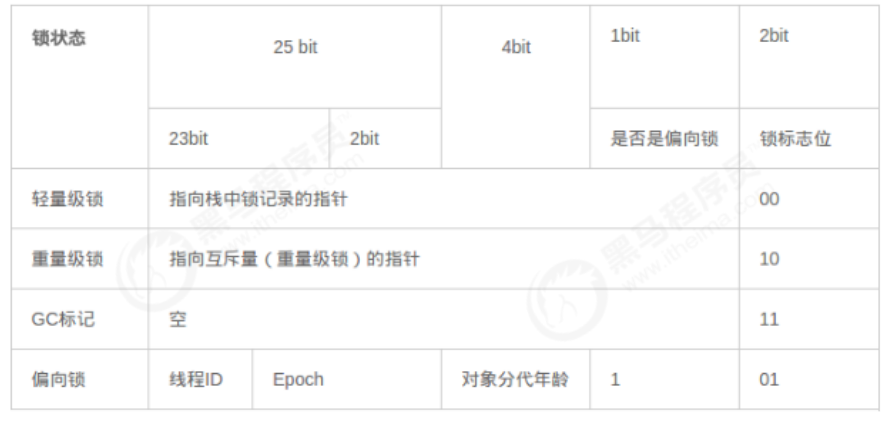
klass pointer
This part is used to store the type pointer of the object, which points to its class metadata, JVM This pointer determines which class the object is an instance of. The bit length of this pointer is JVM A word size of 32 bits JVM 32-bit, 64 bit JVM Is 64 bit. If too many objects are applied, using 64 bit pointers will waste a lot of memory. Statistically speaking, 64 bit pointers JVM Will be better than 32-bit JVM Cost 50 more%Memory. To save memory, you can use this option -XX:+UseCompressedOops Turn on pointer compression, where, oop Namely ordinary object pointer Normal object pointer. When on, the following pointers are compressed to 32 bits:
1. Attribute pointer of each Class (i.e. static variable)
2. Attribute pointer of each object (i.e. object variable)
3. Pointer to each element of ordinary object array
Of course, not all pointers will be compressed, and the JVM will not optimize some special types of pointers, such as Class object pointer to PermGen (Class object pointer to meta space in JDK8), local variables, stack elements, input parameters, return values and NULL pointers.
Object header = Mark Word + pointer type (when pointer compression is not turned on):
In 32-bit system, Mark Word = 4 bytes, type pointer = 4 bytes, object header = 8 bytes = 64 bits;
In 64 bit system, Mark Word = 8 bytes, type pointer = 8 bytes, object header = 16 bytes = 128bits;
Instance data
Is the member variable defined in the class.
Align fill
Alignment filling does not necessarily exist and has no special significance. It only acts as a placeholder. Because the automatic memory management system of HotSpot VM requires that the starting address of the object must be an integer multiple of 8 bytes, in other words, the size of the object must be an integer multiple of 8 bytes. The object header is exactly a multiple of 8 bytes. Therefore, when the object instance data part is not aligned, it needs to be filled in by alignment.
You can view the Java object layout by importing dependencies
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
Summary
java object consists of three parts: object header, instance data and alignment data
The object header is divided into two parts: Mark World + Klass pointer
Bias lock
What is a bias lock
Biased lock is an important introduction in JDK 6, because the author of HotSpot has found through research and practice that in most cases, the lock not only does not exist multi-threaded competition, but is always obtained by the same thread many times. In order to make the thread obtain the lock at a lower cost, biased lock is introduced.
The "bias" of the bias lock is the "bias" of the bias lock and the "bias" of the bias lock. It means that the lock will be biased to the first thread to obtain it, and the thread ID of the lock bias will be stored in the object head. In the future, when the thread enters and exits the synchronization block, it only needs to check whether it is a bias lock, lock flag bit and ThreadID.

However, once multiple threads compete, the biased lock must be revoked, so the performance consumption of revoking the biased lock must be less than the performance consumption of CAS atomic operations saved before, otherwise the gain is not worth the loss.
Deflection lock principle
When the thread accesses the synchronization block for the first time and obtains the lock, the processing flow of partial lock is as follows:
1, The virtual machine will set the flag bit in the object header to "01", that is, bias mode. 2, Simultaneous use CAS The operation returns the name of the thread that obtained the lock ID Record in object Mark Word In, if CAS The operation is successful. Every time the thread holding the bias lock enters the synchronization block related to the lock, the virtual machine can no longer perform any synchronization operation. The efficiency of the bias lock is high.
Every time the thread holding the bias lock enters the synchronization block related to the lock, the virtual machine can no longer perform any synchronization operation. The efficiency of the bias lock is high.
Cancellation of bias lock
1. The revocation of the bias lock must wait for the global security point
2. Pause the thread with biased lock and judge whether the lock object is locked
3. Cancel the bias lock and return to the state of no lock (flag bit 01) or lightweight lock (flag bit 00)
Bias locking is enabled by default after Java 6, but it is activated only a few seconds after the application starts. It can be used
- 20: The biasedlockingstartupdelay = 0 parameter turns off the delay. If it is determined that all locks in the application are normally in a competitive state, you can turn off the biased lock through the XX:-UseBiasedLocking=false parameter.
Bias lock benefits
Biased locking is to further improve performance when only one thread executes synchronization blocks. It is applicable to the case where a thread repeatedly obtains the same lock. Biased locking can improve the performance of programs with synchronization but no competition.
It is also an optimization with benefit tradeoff, that is, it is not always beneficial to the program operation. If most locks in the program are always accessed by multiple different threads, such as thread pool, the bias mode is redundant.
In JDK5, the bias lock is turned off by default, while in JDK6, the bias lock has been turned on by default. However, it is activated only a few seconds after the application starts. You can use the - XX:BiasedLockingStartupDelay=0 parameter to turn off the delay. If it is determined that all locks in the application are normally in a competitive state, you can turn off the bias lock through the XX:-UseBiasedLocking=false parameter.
Summary
Principle of deflection lock:
When the lock object is acquired by the thread for the first time, the virtual machine will set the flag bit in the object header to "01", that is, bias mode. Simultaneous use CAS The operation returns the name of the thread that obtained the lock ID Record in object Mark Word In, if CAS The operation is successful. Every time the thread holding the bias lock enters the synchronization block related to the lock, the virtual machine can no longer perform any synchronization operation. The efficiency of the bias lock is high.
Benefits of bias lock:
Biased locking is to further improve performance when only one thread executes synchronization blocks. It is applicable to the case where a thread repeatedly obtains the same lock. Biased locking can improve the performance of programs with synchronization but no competition.
Lightweight Locking
What is a lightweight lock
Lightweight lock is a new lock mechanism added to JDK 6. The "lightweight" in its name is relative to the traditional lock using monitor. Therefore, the traditional lock mechanism is called "heavyweight" lock. First of all, it should be emphasized that lightweight locks are not used to replace heavyweight locks.
The purpose of introducing lightweight lock: when multiple threads execute synchronization blocks alternately, try to avoid the performance consumption caused by heavyweight lock. However, if multiple threads enter the critical zone at the same time, it will lead to the expansion of lightweight lock and upgrade heavyweight lock. Therefore, the emergence of lightweight lock is not to replace heavyweight lock.
Lightweight lock principle
When the bias lock function is turned off or multiple threads compete for the bias lock, resulting in the bias lock being upgraded to a lightweight lock, an attempt will be made to obtain the lightweight lock. The steps are as follows: obtain the lock
1)Before thread 1 executes the synchronous code block, JVM A space will be created in the stack frame of the current thread to store lock records, and then the Mark Word Copy to the lock record, officially known as Displaced Mark Word. Then the thread tries to use CAS Place the object in the header Mark Word Replace with a pointer to the lock record. If successful, obtain the lock and proceed to step 3). If it fails, go to step 2) 2)The thread spins. If the spin succeeds, the lock is obtained. Go to step 3). If the spin fails, it will expand into a heavyweight lock, change the lock flag bit to 10, and the thread will block (go to step 3) 3)The thread holding the lock executes the synchronization code, and the execution is completed CAS replace Mark Word If the lock is released successfully CAS If successful, the process ends, CAS Failed (step 4) 4)CAS During the execution failure description, a thread attempts to obtain a lock and fails to spin. The lightweight lock is upgraded to a heavyweight lock. At this time, after releasing the lock, the waiting thread needs to be awakened
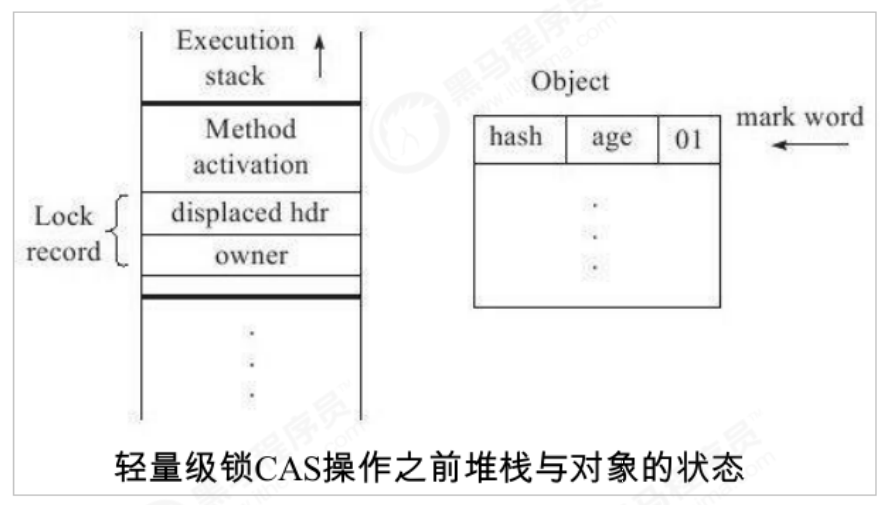
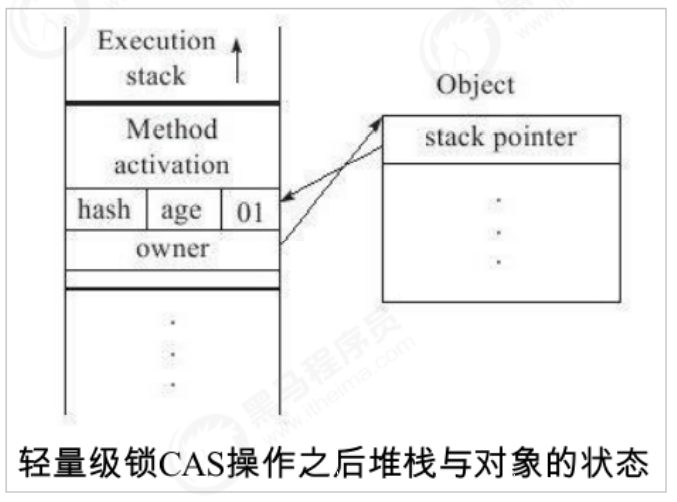
Lightweight lock release
The lightweight lock is also released through CAS operation. The main steps are as follows:
1. Take out the data saved in the Displaced Mark Word after obtaining the lightweight lock.
2. Use CAS operation to replace the retrieved data in the Mark Word of the current object. If it is successful, the lock is released successfully.
3. If CAS operation replacement fails, it indicates that other threads are trying to obtain the lock, and the lightweight lock needs to be upgraded to a heavyweight lock.
For lightweight locks, the performance improvement is based on "for most locks, there will be no competition in the whole life cycle". If this basis is broken, there will be additional CAS operations in addition to the cost of mutual exclusion. Therefore, in the case of multi-threaded competition, lightweight locks are slower than heavyweight locks.
Benefits of lightweight locks
When multiple threads execute synchronous blocks alternately, the performance consumption caused by heavyweight locks can be avoided.
Summary
What is the principle of lightweight lock? Copy the object's Mark Word to Lock Recod in the stack frame. Mark Word is updated to a pointer to Lock Record.
What are the benefits of lightweight locks? When multiple threads execute synchronous blocks alternately, the performance consumption caused by heavyweight locks can be avoided.
Spin lock
synchronized (Demo01.class) {
...
System.out.println("aaa");
}
When we discussed the lock implementation of monitor, we know that monitor will block and wake up threads. Thread blocking and wake-up require the CPU to change from user state to core state. Frequent blocking and wake-up is a heavy burden for the CPU. These operations bring great pressure to the concurrency of the system. At the same time, the virtual machine development team also noticed that in many applications, the locking state of shared data will only last for a short period of time. It is not worth blocking and waking up threads for this period of time. If the physical machine has more than one processor and can allow two or more threads to execute in parallel at the same time, we can ask the thread requesting the lock to "wait a minute", but do not give up the execution time of the processor to see if the thread holding the lock will release the lock soon. In order to make the thread wait, we only need to make the thread execute a busy loop (spin). This technology is called spin lock.
Spin lock in JDK 1.4 It has been introduced in 2, but it is turned off by default. You can use the - XX: + usepinning parameter to turn it on. It has been turned on by default in JDK 6. Spin waiting cannot replace blocking, and let alone the requirements for the number of processors. Although spin waiting itself avoids the overhead of thread switching, it takes up processor time. Therefore, if the lock is occupied for a short time, the effect of spin waiting will be very good. On the contrary, if the lock is occupied for a long time. Then spinning threads will only consume processor resources in vain, and will not do any useful work. On the contrary, it will bring a waste of performance. Therefore, the spin waiting time must have a certain limit. If the spin exceeds the limited number of times and still does not successfully obtain the lock, the traditional method should be used to suspend the thread. The default value of spin times is 10 times, which can be changed by the user using the parameter - XX: preblockspin.
Adaptive spin lock
An adaptive spin lock is introduced in JDK 6. Adaptive means that the spin time is no longer fixed, but determined by the previous spin time on the same lock and the state of the lock owner. If on the same lock object, the spin wait has just successfully obtained the lock, and the thread holding the lock is running, the virtual machine will think that the spin is likely to succeed again, and then it will allow the spin wait to last for a relatively longer time, such as 100 cycles. In addition, if the spin is rarely successfully obtained for a lock, the spin process may be omitted when acquiring the lock in the future to avoid wasting processor resources. With adaptive spin, with the continuous improvement of program operation and performance monitoring information, the virtual machine will predict the status of program lock more and more accurately, and the virtual machine will become more and more "smart".
Lock elimination
Lock elimination refers to virtual machine real-time compiler (JIT) at run time, locks that require synchronization in some code but are detected to be impossible to compete with shared data are eliminated. The main determination of lock elimination is based on the data support from escape analysis. If it is determined that all data on the heap will not escape and be accessed by other threads in a piece of code, they can be regarded as data on the stack It is considered that they are thread private, and synchronous locking is not necessary. Whether variables escape or not needs to be determined by data flow analysis for virtual machines, but programmers themselves should be very clear. How can they require synchronization when they know that there is no data contention? In fact, many synchronization measures are not added by programmers themselves. The popularity of synchronized code in Java programs may exceed the imagination of most readers. The following very simple code just outputs the result of the addition of three strings. There is no synchronization in both source code literal and program semantics.
public class Demo01 {
public static void main(String[] args) {
contactString("aa", "bb", "cc");
}
public static String contactString(String s1, String s2, String s3) {
return new StringBuffer().append(s1).append(s2).append(s3).toString();
}
}
The append() of StringBuffer is a synchronization method, and the lock is this, that is (new StringBuilder()). The virtual machine found that its dynamic scope was restricted to the concatString() method. In other words, the reference of the new StringBuilder () object will never "escape" outside the concatString() method, and other threads cannot access it. Therefore, although there is a lock here, it can be safely eliminated. After immediate compilation, this code will ignore all synchronization and execute directly.
Object escape
There are two types of object escape:
Method escape (object escapes from current method):
When an object is defined in a method, it may be referenced by an external method, for example, as a call parameter to other methods.
Thread escape (object escapes from current thread):
This object may even be accessed by other threads, such as assigned to class variables or instance variables that can be accessed in other threads.
Lock coarsening
In principle, when writing code, we always recommend to limit the scope of synchronization blocks as small as possible and synchronize only in the actual scope of shared data. This is to minimize the number of operations to be synchronized. If there is lock competition, the thread waiting for the lock can get the lock as soon as possible. In most cases, the above principles are correct, but if a series of continuous operations repeatedly lock and unlock the same object, or even the lock operation occurs in the loop body, frequent mutually exclusive synchronization operations will lead to unnecessary performance loss even if there is no thread competition.
public class Demo01 {
public static void main(String[] args) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 100; i++) {
sb.append("aa");
}
System.out.println(sb.toString());
}
}
Summary
What is lock coarsening? The JVM will detect that a series of small operations use the same object to lock, and enlarge the scope of the synchronization code block and put it outside the series of operations. In this way, it only needs to lock once.
Optimization of Synchronized by writing code at ordinary times
Reduce Synchronized range
The synchronization code block shall be as short as possible to reduce the execution time of the code in the synchronization code block and reduce lock competition.
synchronized (Demo01.class) {
System.out.println("aaa");
}
Reduce the granularity of synchronized locks
Talk about splitting a lock into multiple locks to improve concurrency.
Hashtable hs = new Hashtable();
hs.put("aa", "bb");
hs.put("xx", "yy");
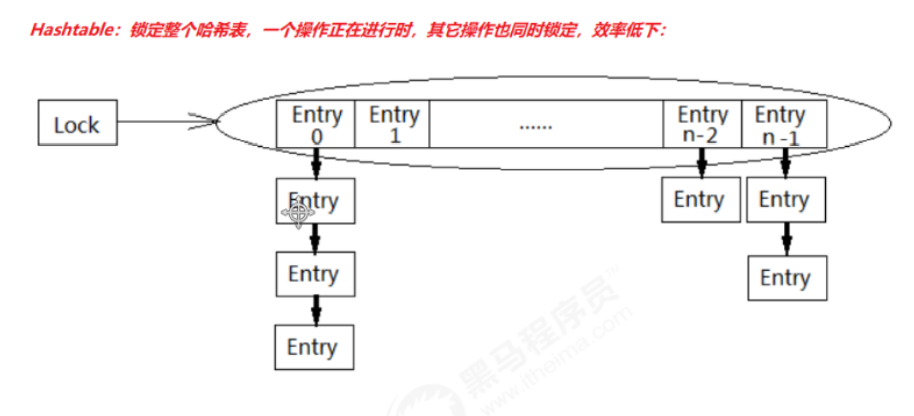
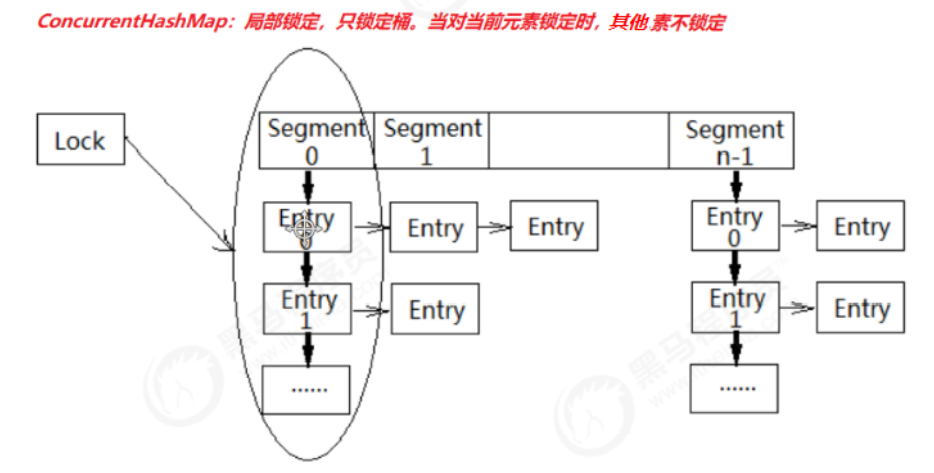
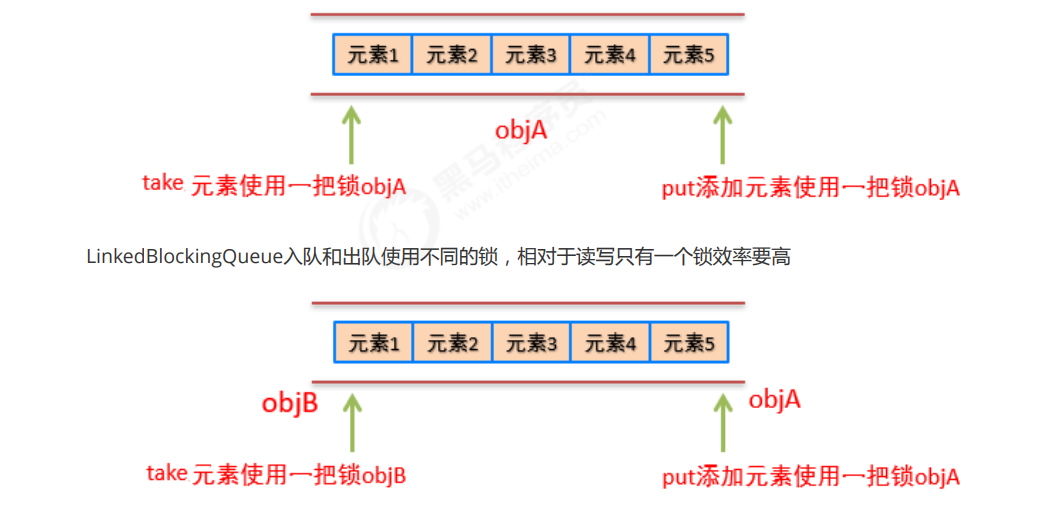
Read write separation
Do not lock when reading, and lock when writing and deleting
ConcurrentHashMap, CopyOnWriteArrayList and concuronwriteset
How the volatile keyword works (including comparison with Synchronized)
When the program is running, it will copy a copy of the data required for the operation from the main memory to the CPU cache. When the CPU performs the calculation, it can directly read and write data from its cache. When the operation is completed, it will refresh the data in the cache to the main memory. Take a simple example, such as the following code:
i = i + 1;
When the thread executes this statement, it will first read the value of i from the main memory, and then copy a copy to the cache. Then the CPU executes an instruction to add 1 to i, then writes the data to the cache, and finally flushes the latest value of i in the cache to the main memory.
(6 messages) deep understanding of the volatile keyword_ ChaseRaod's blog - CSDN blog