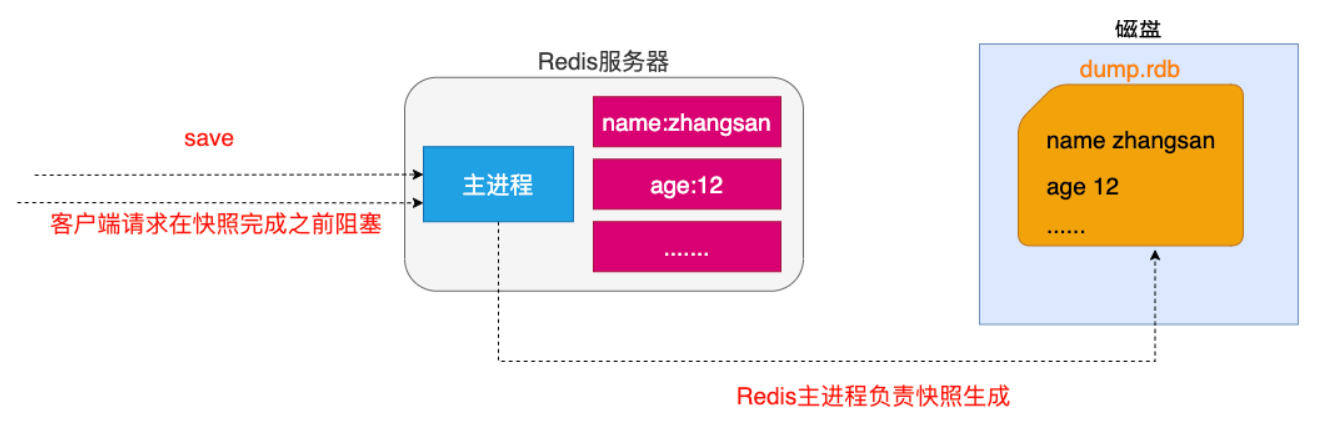
The client can also use the SAVE command to create a snapshot. The Redis server that receives the SAVE command will not respond to any other commands before the snapshot is created;
Note: the SAVE command is not commonly used. Before the snapshot is created, Redis is blocked and cannot provide external services.
3. Configuration snapshot trigger conditions of server configuration mode
If the user is in Redis If the save configuration option is set in conf, Redis will automatically trigger the BGSAVE command once after the Save option conditions are met; If multiple save configuration options are set, Redis will also trigger the BGSAVE command once when the conditions of any save configuration option are met.
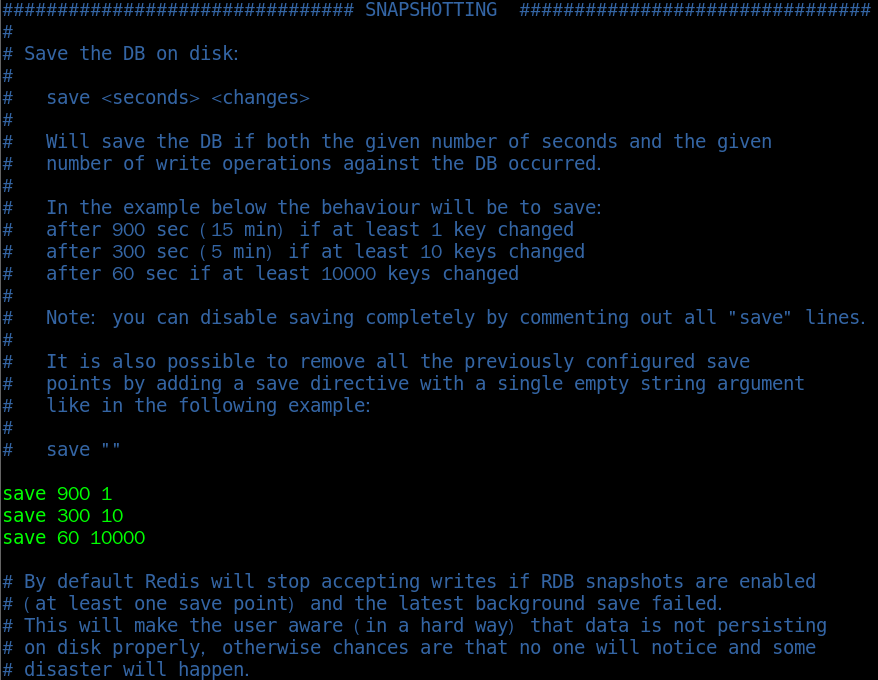
save 900 1 means that once a database operation is performed within 900s, a snapshot is automatically created, and so on.
4. The server receives the client SHUTDOWN command
When Redis receives the request to shut down the server through the SHUTDOWN command, it will execute a SAVE command to block all clients, no longer execute any commands sent by the client, and shut down the server after the SAVE command is executed.
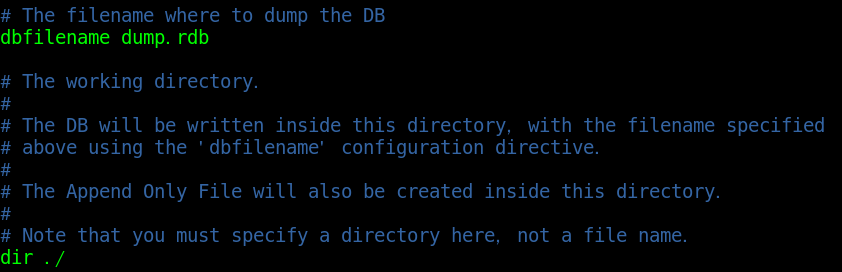
Configure the name and location of the generated snapshot in the configuration file
In the configuration file, you can modify the generated snapshot name and the snapshot save location:
# The name of the generated snapshot. The default is dump rdb dbfilename dump.rdb # The snapshot is saved in the redis cli peer directory by default dir ./
Append only log file AOF (Append Only File)
=================================================================================================
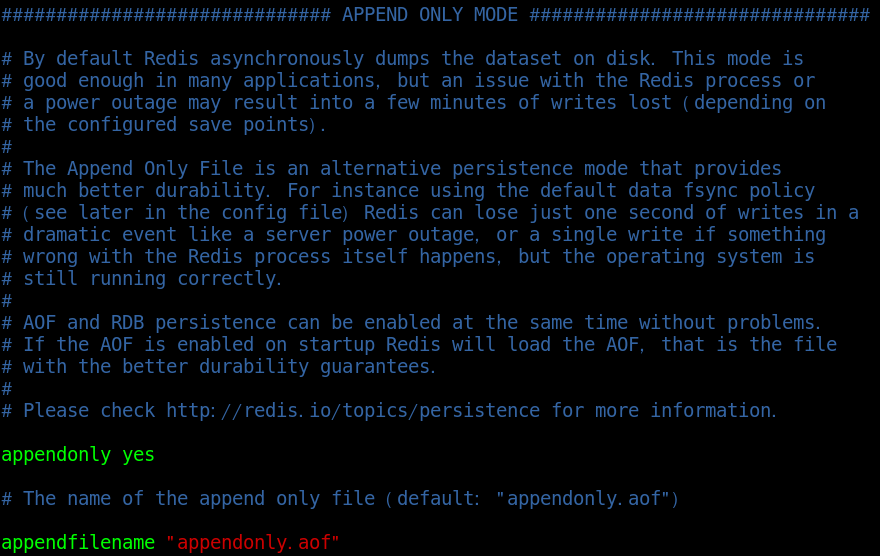
In the default configuration of Redis, the AOF persistence mechanism is not enabled and needs to be enabled in the configuration;
# Enable AOF persistence appendonly yes # Generated log file name appendfilename "appendonly.aof" # The path of the aof log file is the same as the snapshot save location dir ./
AOF has three log append frequencies:
-
always [use with caution]
-
everysec [recommended]
-
no [not recommended]
-
Note: each redis write command must be written to the hard disk synchronously, which seriously reduces the redis speed;
-
Explanation: if the user uses the always option, each redis write command will be written to the hard disk, so as to minimize the data loss in case of system crash; Unfortunately, because this synchronization strategy requires a large number of write operations to the hard disk, the speed of redis processing commands will be limited by the performance of the hard disk;
-
Note: the turntable hard disk (mechanical hard disk) has about 200 commands / s at this frequency; Solid state disk (SSD) millions of commands / S;
-
Warning: users using SSDs should use the always option with caution. The practice of constantly writing a small amount of data in this mode may cause serious write amplification problems and reduce the service life of SSDs from a few years to a few months.
-
Note: execute synchronization once per second to explicitly synchronize multiple write commands to disk;
-
Explanation: to balance data security and write performance, you can use the everysec option to allow redis to synchronize AOF files once per second; When redis synchronizes AOF files every second, its performance is almost the same as when it does not use any persistence features. By synchronizing AOF files every second, redis can ensure that users will lose data generated within one second at most even if the system crashes.
-
Note: the operating system decides when to synchronize;
-
Explanation: using the no option, the operating system will completely decide when to synchronize the AOF log files. This option will not affect the performance of redis. However, when the system crashes, an indefinite amount of data will be lost. In addition, if the user's hard disk processing and writing operation is not fast enough, redis will be blocked when the buffer is filled with data waiting to be written to the hard disk, It also causes redis to slow down the processing of command requests.
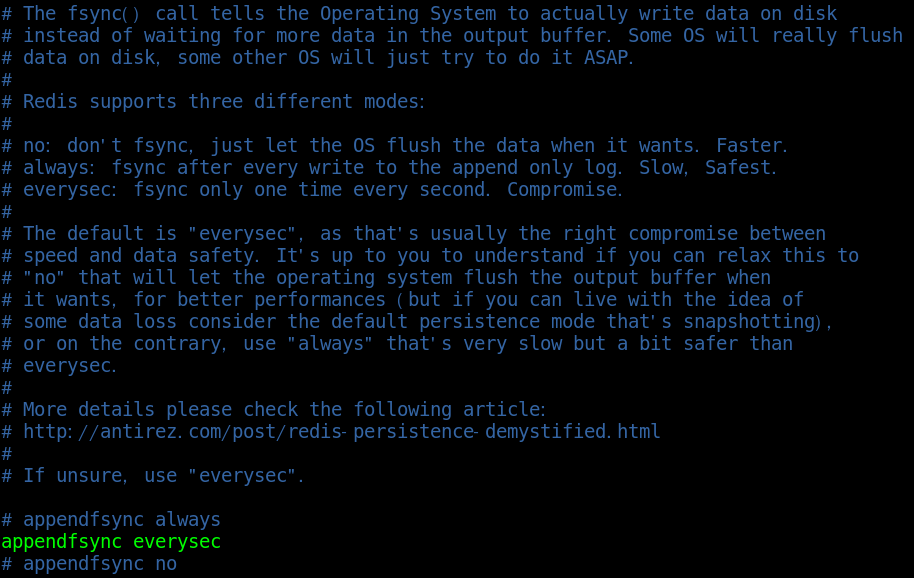
Modify synchronization frequency in configuration file
# appendfsync always appendfsync everysec # appendfsync no
============================================================================
AOF also brings another problem: persistent files will become larger and larger.
For example, if we call incr test command 100 times, all 100 commands must be saved in the file. In fact, 99 commands are redundant, because to restore the state of the database, it is enough to save a set test 100 in the file. In order to compress the persistent files of AOF, Redis provides an AOF rewriter mechanism.
aof rewriting mechanism reduces the volume of aof files to a certain extent.
There are two ways to trigger Rewriting:
1. Trigger rewriting in client mode
Execute BGREWRITEAOF command, which will not block redis service;
2. The server configuration mode is triggered automatically
Configure redis Auto AOF rewrite percentage option in conf:
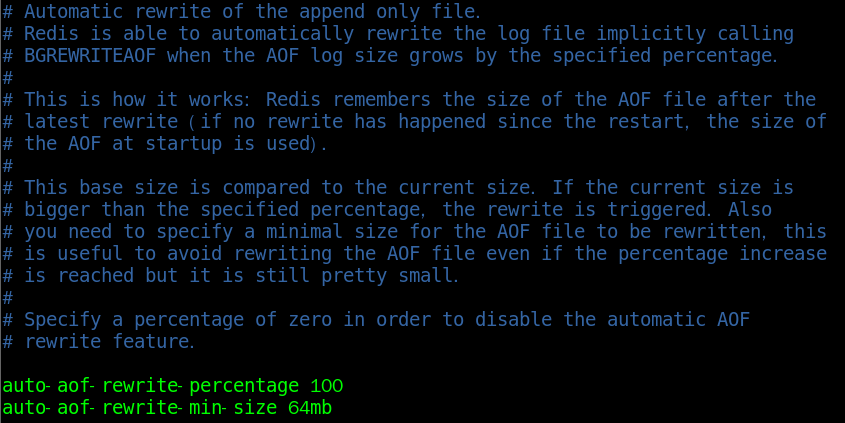
auto-aof-rewrite-percentage 100 ## Summary: draw a brain map of Kakfa framework Thinking Outline (xmind) 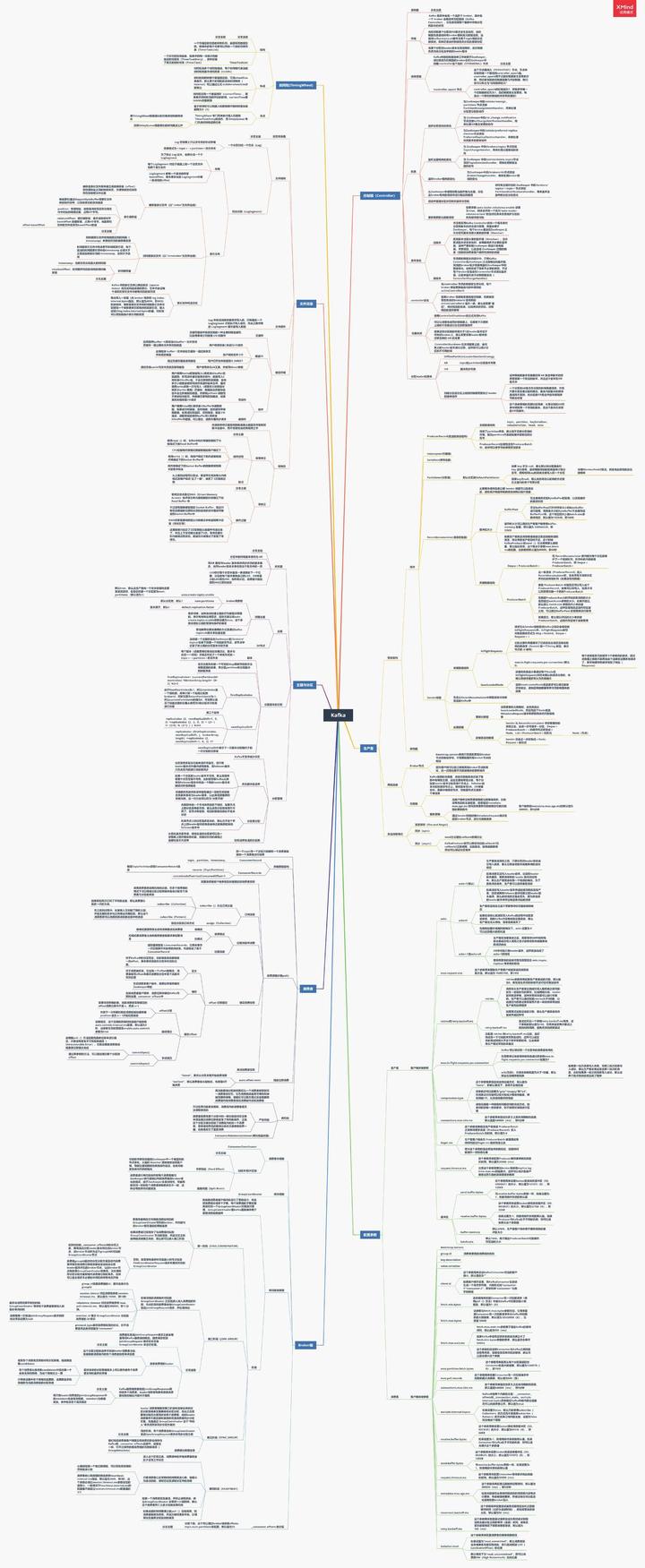 Actually about Kafka,There are too many questions to ask. After a few days, we finally screened out 44 questions: 17 questions in the basic chapter, 15 questions in the advanced chapter and 12 questions in the advanced chapter. All of them poke pain points. I don't know how many questions can you answer if you don't look at the answers in a hurry? If yes Kafka If you can't recall your knowledge, you might as well look at my hand-painted knowledge summary brain map first( xmind It can't be uploaded. The article uses a picture version) to sort out the overall architecture **[Data collection method: click here to download for free](https://gitee.com/vip204888/java-p7)** After combing the knowledge and finishing the interview, if you want to further study and interpret kafka And the source code, then the next handwritten“ kafka">Would be a good choice. * Kafka introduction * Why Kafka * Kafka Installation, management and configuration of * Kafka Cluster of * first Kafka program * Kafka Producer of * Kafka Consumers of * In depth understanding Kafka * Reliable data transfer * Spring and Kafka Integration of * SpringBoot and Kafka Integration of * Kafka Practice of cutting peaks and filling valleys * Data pipeline and streaming(Just understand)  choice Kafka * Kafka Installation, management and configuration of * Kafka Cluster of * first Kafka program * Kafka Producer of * Kafka Consumers of * In depth understanding Kafka * Reliable data transfer * Spring and Kafka Integration of * SpringBoot and Kafka Integration of * Kafka Practice of cutting peaks and filling valleys * Data pipeline and streaming(Just understand) [External chain picture transfer...(img-HHJhyx1O-1628417364146)] 