1, Foreword
details of Java performance optimization affecting performance - continued. I intend to write the whole series of articles with this title slowly. This is the first article entrance . This time, the content mainly comes from the book "actual combat of Java program performance optimization". It is a reading note. Interested partners can read this book.
2, List interface
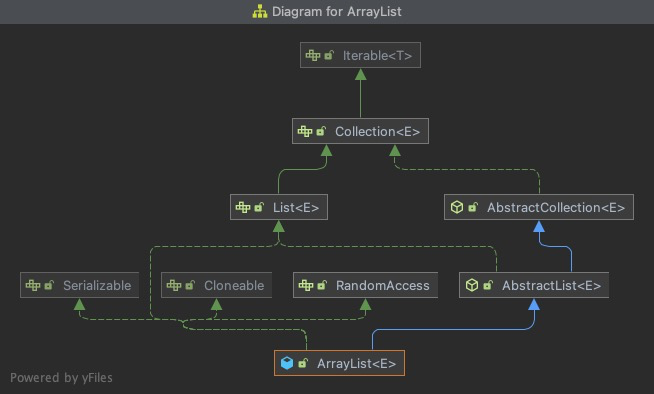
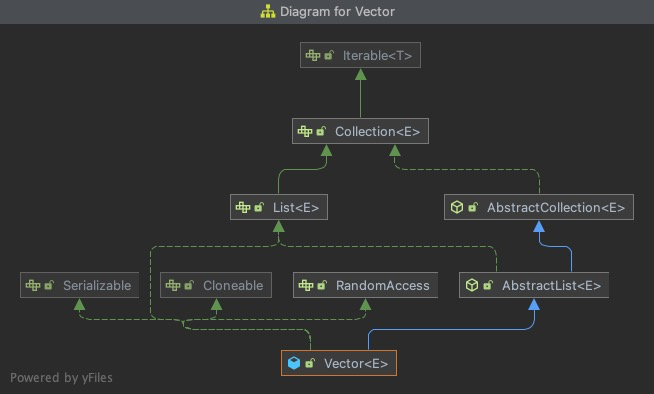
let's first look at the class diagrams of these lists:
- ArrayList
- Vector
- LinkedList
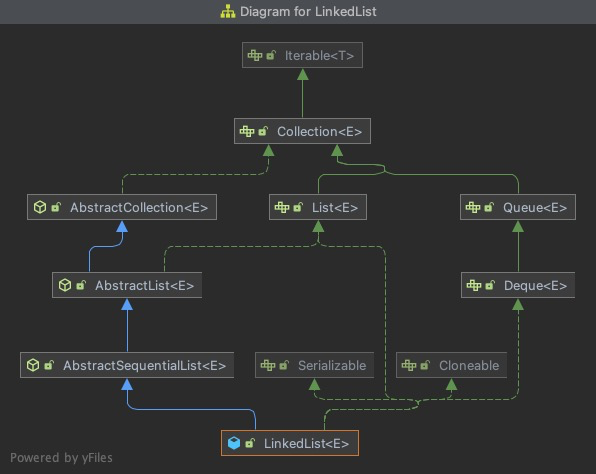
ArrayList, Vector and LinkedList come from the implementation of AbstractList, which directly implements the List interface and extends from AbstractCollection.
1. ArrayList and Vector
ArrayList and Vector are basically the same, so we put these two together. The two implementation classes almost use the same algorithm, and their only difference can be considered as the support for multithreading. ArrayList does not do thread synchronization for any method, so it is not thread safe; Most methods in Vector do thread synchronization, which is a thread safe implementation;
- ArrayList and Vector use arrays. It can be considered that ArrayList or Vector encapsulates the operations on the internal array, such as adding, deleting, inserting new elements into the array or extending and redefining the array. (some optimization methods for ArrayList and Vector are actually based on arrays, so the general situation is also applicable to other cases where the underlying array is used.)
- If the current capacity of ArrayList is large enough [the default initialization length is 10], the efficiency of add() operation is very high. During the expansion of ArrayList [1.5 times the original default expansion], a large number of array copying operations will be carried out, and relatively frequent expansion will have a performance impact; The core source code of capacity expansion is as follows:
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// This is achieved by bit operation. Equivalent to newCapacity = oldCapacity + (oldCapacity / 2)
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}From the source code, we can get another detail: the integer multiplication and division in the code is realized by bit operation, which can greatly improve the computational efficiency.
- Deleting elements from the tail is very efficient, and deleting elements from the head is quite time-consuming, because the array must be reorganized after each deletion;
- The insert operation will copy the array once [except for the tail insertion], and this operation does not exist when adding elements to the tail of the List. A large number of array reorganization operations will lead to low system performance, and the higher the position of the inserted element in the List, the greater the overhead of array reorganization;
- Try to access internal elements directly instead of calling the corresponding interface. Because function calls consume system resources, it is more efficient to directly access elements, such as directly using the List array index instead of the get interface.
2. LinkedList
LinkedList uses a circular bidirectional linked List data structure. Compared with array based List, these are two different implementation technologies, which also determines that they will be suitable for completely different working scenarios. The linked List consists of a series of table items. A table item contains three parts: element content, precursor table item and successor table item.
- Whether the LinkedList is empty or not, there is a header item in the linked list, which represents both the beginning and the end of the linked list. The intent of the circular chain is as follows:
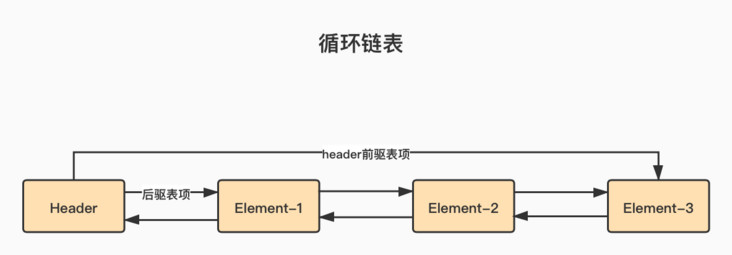
- LinkedList has high requirements for heap memory and GC because new Entry() is required every time an element is added and data must be encapsulated every time, because the front pointer and rear pointer must be set before they can be added to the linked list;
- LinkedList has almost the same efficiency when deleting elements from the beginning to the end, but its performance is very poor when deleting elements from the middle of the List because it has to traverse half of the linked List every time;
(here is Previous article (notes on LinkedList mentioned in) - Use ListIterator (for each, traverse with pointer) to traverse LinkedList [linked list feature];
- Avoid any LinkedList method that accepts or returns the index of the elements in the list [similar to the operation of obtaining the index]. The performance is very poor, and the list is traversed;
3, Map interface
let's take a look at the class diagrams of these maps:
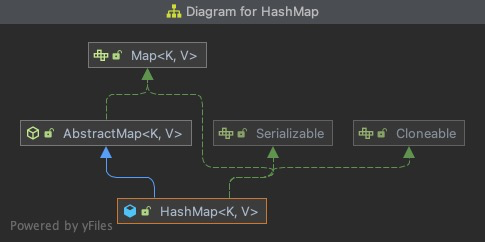
- HashMap
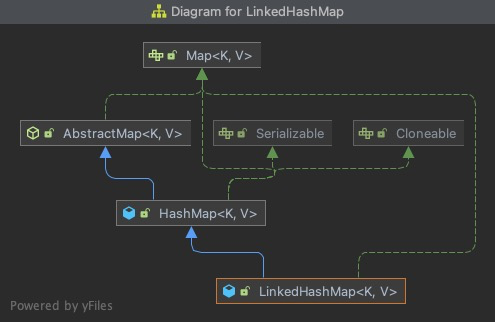
- LinkedHashMap
- TreeMap
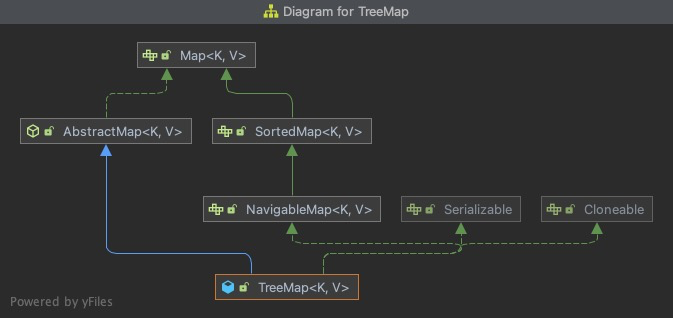
these three maps implement the Map interface and inherit the AbstractMap class. HashMap and LinkedHashMap directly inherit the AbstractMap class, while LinkedHashMap inherits HashMap.
1. HashMap
- The performance of HashMap depends to some extent on the implementation of hashCode(). A good hashCode() algorithm can reduce conflicts as much as possible and improve the access speed of HashMap. In addition, a larger load factor means that less memory space is used, and the smaller the space, the more likely it is to cause Hash conflicts.
- HashMap initializes the default array size of 16 and specifies the size when it is created [75% is used by default for automatic capacity expansion. Each capacity expansion is twice the original, and the maximum length is 2 ^ 30]. The parameter must be an exponential power of 2 (if not, force conversion); The source code of the expansion part is as follows:
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// This is also the bit operation used here, which is equivalent to multiplying 2
newThr = oldThr << 1; // double threshold
}General process of HashMap expansion (jdk8):
i. new a new array
ii. Data migration with the help of binary high and low pointers (if the highest bit is 0, the coordinate remains unchanged, and if the highest bit is 1, the coordinate is the original position + the length of the new array. If it is a tree structure, there is additional logic) [there is not much to explain the capacity expansion mechanism of HashMap];
iii. If the length of the linked list is greater than 8 and the length of the hash table is greater than or equal to 64, the linked list will be transferred to the red black tree (generally, the red black tree is not used, and the capacity expansion is preferred);
2. LinkedHashMap
- LinkedHashMap can maintain the order of element input; The bottom layer uses a circular linked list. In the internal implementation, LinkedHashMap implements LinkedHashMap.Entry by inheriting the HashMap.Entry class, and adds before and after attributes to HashMap.Entry to record the precursor and successor of a table item.
- For some notes, refer to the LinkedList (linked list)
3. TreeMap
- TreeMap implements the SortedMap interface, which means that it can sort elements. However, the performance of TreeMap is slightly lower than that of HashMap;
- The internal implementation of TreeMap is based on red black tree. Red black tree is a kind of balanced search tree, and its statistical performance is better than that of balanced binary tree. It has a good worst-case running time, and can do search, insert and delete operations in O (logn) time.
- If you need to sort the data in the Map, you can use TreeMap instead of implementing a lot of code, and the performance is not necessarily very high;
4, Test demo about List
package com.allen.list;
import org.junit.Test;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Vector;
/**
* 1,ArrayList,Vector: Adding elements at the tail has high performance, and inserting elements at the head will involve copying and moving elements every time, so the performance is low
* 2,LinkedList: Every time you add an element, you need a new Entry(), which requires high heap memory and GC [- Xmx512M -Xms512M using this parameter will have a certain impact on the test results]
*/
public class TestList {
private static final int CIRCLE1 = 50000;
protected List list;
protected void testAddTail(String funcname){
Object obj=new Object();
long starttime=System.currentTimeMillis();
for(int i=0;i<CIRCLE1;i++){
list.add(obj);
}
long endtime=System.currentTimeMillis();
System.out.println(funcname+": "+(endtime-starttime));
}
protected void testDelTail(String funcname){
Object obj=new Object();
for(int i=0;i<CIRCLE1;i++){
list.add(obj);
}
long starttime=System.currentTimeMillis();
while(list.size()>0){
list.remove(list.size()-1);
}
long endtime=System.currentTimeMillis();
System.out.println(funcname+": "+(endtime-starttime));
}
protected void testDelFirst(String funcname){
Object obj=new Object();
for(int i=0;i<CIRCLE1;i++){
list.add(obj);
}
long starttime=System.currentTimeMillis();
while(list.size()>0){
list.remove(0);
}
long endtime=System.currentTimeMillis();
System.out.println(funcname+": "+(endtime-starttime));
}
protected void testDelMiddle(String funcname){
Object obj=new Object();
for(int i=0;i<CIRCLE1;i++){
list.add(obj);
}
long starttime=System.currentTimeMillis();
while(list.size()>0){
list.remove(list.size()>>1);
}
long endtime=System.currentTimeMillis();
System.out.println(funcname+": "+(endtime-starttime));
}
protected void testAddFirst(String funcname){
Object obj=new Object();
long starttime=System.currentTimeMillis();
for(int i=0;i<CIRCLE1;i++){
list.add(0, obj);
}
long endtime=System.currentTimeMillis();
System.out.println(funcname+": "+(endtime-starttime));
}
// Test ArrayList tail add
@Test
public void testAddTailArrayList() {
list=new ArrayList();
testAddTail("testAddTailArrayList");
}
//@Test
public void testAddTailVector() {
list=new Vector();
testAddTail("testAddTailVector");
}
// Test LinkedList tail add
@Test
public void testAddTailLinkedList() {
list=new LinkedList();
testAddTail("testAddTailLinkedList");
}
// Test ArrayList header addition
@Test
public void testAddFirstArrayList() {
list=new ArrayList();
testAddFirst("testAddFirstArrayList");
}
// @Test
public void testAddFirstVector() {
list=new Vector();
testAddFirst("testAddFirstVector");
}
// Test LinkedList header addition
@Test
public void testAddFirstLinkedList() {
list=new LinkedList();
testAddFirst("testAddFirstLinkedList");
}
// Test ArrayList tail deletion
@Test
public void testDeleteTailArrayList() {
list=new ArrayList();
testDelTail("testDeleteTailArrayList");
}
// @Test
public void testDeleteTailVector() {
list=new Vector();
testDelTail("testDeleteTailVector");
}
// Test LinkedList tail deletion
@Test
public void testDeleteTailLinkedList() {
list=new LinkedList();
testDelTail("testDeleteTailLinkedList");
}
// Test ArrayList header deletion
@Test
public void testDeleteFirstArrayList() {
list=new ArrayList();
testDelFirst("testDeleteFirstArrayList");
}
// @Test
public void testDeleteFirstVector() {
list=new Vector();
testDelFirst("testDeleteFirstVector");
}
// Test LinkedList header deletion
@Test
public void testDeleteFirstLinkedList() {
list=new LinkedList();
testDelFirst("testDeleteFirstLinkedList");
}
// Test LinkedList middle delete
@Test
public void testDeleteMiddleLinkedList() {
list=new LinkedList();
testDelMiddle("testDeleteMiddleLinkedList");
}
// Test ArrayList middle delete
@Test
public void testDeleteMiddleArrayList() {
list=new ArrayList();
testDelMiddle("testDeleteMiddleArrayList");
}
}