Dialogue intention recognition task based on Baidu self-developed model ERNIE
Intention recognition refers to analyzing the core needs of users and outputting the information most relevant to query input, such as finding movies, checking express, municipal office and other needs in search. These needs will be very different in the underlying retrieval strategy. Wrong recognition can almost determine that the content that can meet the needs of users can not be found, resulting in a very poor user experience; It is a challenging task to accurately understand what the other party wants to express during the dialogue.
For example, when the user enters the query "fairy sword and Chivalry", we know that the "fairy sword and Chivalry" has games, TV dramas, news, pictures, etc. if we find that the user wants to watch the "fairy sword and Chivalry" TV drama through user intention identification, we will directly return the TV drama to the user as the result, which will save the user's search clicks, Shorten the search time and greatly improve the use experience. In the dialogue, if the other party says "my apple never gets stuck", then we can judge that the apple at the moment is an electronic device rather than a fruit through intention recognition, so that the dialogue can go on smoothly.
This example uses ERNIE pre training model to CrossWOZ The data set completes the slot filling and intention recognition tasks in the task-based dialogue, which are the cornerstone of a pipeline task dialogue system.
learning resource
- For more in-depth learning materials, such as in-depth learning knowledge, paper interpretation, practical cases, etc., please refer to: awesome-DeepLearning
- For more information about the propeller frame, please refer to: Propeller deep learning platform
⭐ ⭐ ⭐ Welcome to order a small one Star , open source is not easy. I hope you can support it~ ⭐ ⭐ ⭐

1. Scheme design
This practical design scheme will complete the tasks of intention identification and slot filling on the CrossWOZ dataset based on ERNIE. In this practice, intention recognition and slot filling are essentially a sentence classification task and a sequence annotation task. As shown in Figure 1, the output of CLS token position will be used for sentence classification, and the actual token of text string will be used for sequence annotation task. In the training process, the loss of the two will be combined to realize the multi task learning of intention recognition and slot filling.
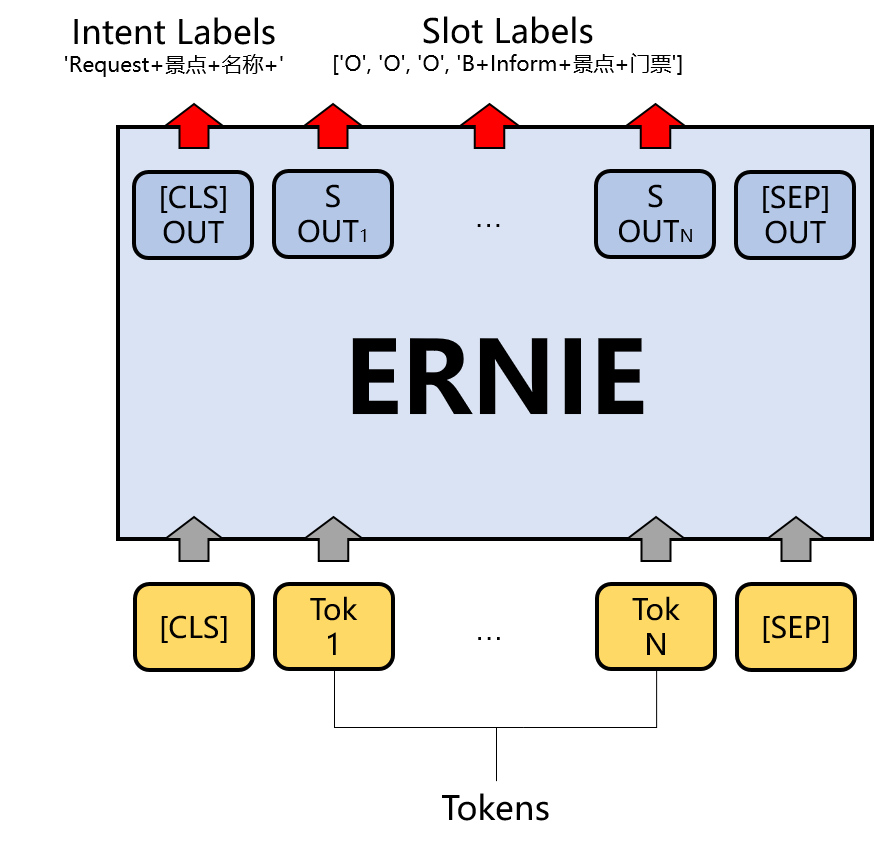 Figure 1 ERNIE dialogue intention identification architecture
Figure 1 ERNIE dialogue intention identification architecture
2. Data preparation
2.1 data set introduction
CrossWOZ is the first large-scale cross domain task oriented data set in China. It contains five areas, a total of 6K conversations and 102K sentences, including hotels, restaurants, scenic spots, subways and taxis. In addition, the corpus contains rich annotations of user and system dialogue status and dialogue behavior.
For more information about data sets, please refer to the paper CrossWOZ: A Large-Scale Chinese Cross-Domain Task-Oriented Dialogue Dataset .
2.2. Data loading
Next, we load the dictionary, training and evaluation data set into memory. Then count the number of intent tags in the current data set, which will be used in the subsequent intent loss calculation.
import paddle
import os
import ast
import argparse
import warnings
import numpy as np
from functools import partial
from seqeval.metrics.sequence_labeling import get_entities
from utils.utils import set_seed
from utils.data import read, load_dict, convert_example_to_feature
from utils.metric import SeqEntityScore, MultiLabelClassificationScore
import paddle
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset
from paddlenlp.transformers import ErnieTokenizer, ErnieModel, LinearDecayWithWarmup
from paddlenlp.data import Stack, Pad, Tuple
intent_dict_path = "./dataset/intent_labels.json"
slot_dict_path = "./dataset/slot_labels.json"
train_path = "./dataset/train.json"
dev_path = "./dataset/test.json"
# load and process data
intent2id, id2intent = load_dict(intent_dict_path)
slot2id, id2slot = load_dict(slot_dict_path)
train_ds = load_dataset(read, data_path=train_path, lazy=False)
dev_ds = load_dataset(read, data_path=dev_path, lazy=False)
# compute intent weight
intent_weight = [1] * len(intent2id)
for example in train_ds:
for intent in example["intent_labels"]:
intent_weight[intent2id[intent]] += 1
for intent, intent_id in intent2id.items():
neg_pos = (len(train_ds) - intent_weight[intent_id]) / intent_weight[intent_id]
intent_weight[intent_id] = np.log10(neg_pos)
intent_weight = paddle.to_tensor(intent_weight)
2.3 converting data into feature form
Next, we convert the data into a feature form suitable for the input model, that is, the text string data into the form of dictionary id. Here we will load Ernie tokenizer in paddleNLP, which will help us complete the conversion from this string to dictionary id.
model_name = "ernie-1.0" max_seq_len = 512 batch_size = 32 tokenizer = ErnieTokenizer.from_pretrained(model_name) trans_func = partial(convert_example_to_feature, tokenizer=tokenizer, slot2id=slot2id, intent2id=intent2id, pad_default_tag="O", max_seq_len=max_seq_len) train_ds = train_ds.map(trans_func, lazy=False) dev_ds = dev_ds.map(trans_func, lazy=False)
[2021-11-03 14:31:14,540] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/vocab.txt 100%|██████████| 90/90 [00:00<00:00, 19868.80it/s]
2.4 construct DataLoader
Next, we need to construct a DataLoader, which will support the division of data in the form of batch, so as to train the corresponding model in the form of batch.
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
Stack(dtype="float32"),
Pad(axis=0, pad_val=slot2id["O"], dtype="int64"),
):fn(samples)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=batch_size, shuffle=True)
dev_batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=batch_size, shuffle=False)
train_loader = paddle.io.DataLoader(dataset=train_ds, batch_sampler=train_batch_sampler, collate_fn=batchify_fn, return_list=True)
dev_loader = paddle.io.DataLoader(dataset=dev_ds, batch_sampler=dev_batch_sampler, collate_fn=batchify_fn, return_list=True)
3. Model construction
In this case, we will implement the intention recognition and slot filling functions shown in Figure 1 based on ERNIE. Specifically, we input the processed text data into ERNIE model. ERNIE will encode each token of the text and generate the corresponding vector sequence, then carry out the intention recognition task according to the token vector of CLS position, and carry out the slot filling task according to the subsequent position text token vector. The corresponding codes are as follows.
import paddle
from paddle import nn
import paddle.nn.functional as F
from paddlenlp.transformers import ErniePretrainedModel
class JointModel(paddle.nn.Layer):
def __init__(self, ernie, num_slots, num_intents, dropout=None):
super(JointModel, self).__init__()
self.num_slots = num_slots
self.num_intents = num_intents
self.ernie = ernie
self.dropout = nn.Dropout(dropout if dropout is not None else self.ernie.config["hidden_dropout_prob"])
self.intent_hidden = nn.Linear(self.ernie.config["hidden_size"], self.ernie.config["hidden_size"])
self.slot_hidden = nn.Linear(self.ernie.config["hidden_size"], self.ernie.config["hidden_size"])
self.intent_classifier = nn.Linear(self.ernie.config["hidden_size"], self.num_intents)
self.slot_classifier = nn.Linear(self.ernie.config["hidden_size"], self.num_slots)
def forward(self, token_ids, token_type_ids=None, position_ids=None, attention_mask=None):
sequence_output, pooled_output = self.ernie(token_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
sequence_output = F.relu(self.slot_hidden(self.dropout(sequence_output)))
pooled_output = F.relu(self.intent_hidden(self.dropout(pooled_output)))
intent_logits = self.intent_classifier(pooled_output)
slot_logits = self.slot_classifier(sequence_output)
return intent_logits, slot_logits
4. Training configuration
The loss function used in model training is defined. Since this practice is a multi task learning method, there will be two losses: intention recognition and slot filling. In this practice, we add the two as the final loss. In addition, we will define the environment for model training, including configuring training parameters, configuring model parameters, defining the instantiation object of the model, specifying the optimization algorithm of model training iteration, etc. the relevant codes are as follows.
class JointLoss(paddle.nn.Layer):
def __init__(self, intent_weight=None):
super(JointLoss, self).__init__()
self.intent_criterion = paddle.nn.BCEWithLogitsLoss(weight=intent_weight)
self.slot_criterion = paddle.nn.CrossEntropyLoss()
def forward(self, intent_logits, slot_logits, intent_labels, slot_labels):
intent_loss = self.intent_criterion(intent_logits, intent_labels)
slot_loss = self.slot_criterion(slot_logits, slot_labels)
loss = intent_loss + slot_loss
return loss
# model hyperparameter setting
num_epoch = 10
learning_rate = 2e-5
weight_decay = 0.01
warmup_proportion = 0.1
max_grad_norm = 1.0
log_step = 50
eval_step = 1000
seed = 1000
save_path = "./checkpoint"
# envir setting
set_seed(seed)
use_gpu = True if paddle.get_device().startswith("gpu") else False
if use_gpu:
paddle.set_device("gpu:0")
ernie = ErnieModel.from_pretrained(model_name)
joint_model = JointModel(ernie, len(slot2id), len(intent2id), dropout=0.1)
num_training_steps = len(train_loader) * num_epoch
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
decay_params = [p.name for n, p in joint_model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler, parameters=joint_model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
joint_loss = JointLoss(intent_weight)
intent_metric = MultiLabelClassificationScore(id2intent)
slot_metric = SeqEntityScore(id2slot)
[2021-10-29 14:36:51,852] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams [2021-10-29 14:36:56,330] [ INFO] - Weights from pretrained model not used in ErnieModel: ['cls.predictions.layer_norm.weight', 'cls.predictions.decoder_bias', 'cls.predictions.transform.bias', 'cls.predictions.transform.weight', 'cls.predictions.layer_norm.bias']
4. Model training
In this section, we will define a general train function and evaluate function. During training, every log_steps print the log once every eval_ The steps step is to evaluate the model once, and when either of the indicators of intention recognition or slot extraction task is better, we will save the model. Relevant codes are as follows:
def evaluate(joint_model, data_loader, intent_metric, slot_metric):
joint_model.eval()
intent_metric.reset()
slot_metric.reset()
for idx, batch_data in enumerate(data_loader):
input_ids, token_type_ids, intent_labels, tag_ids = batch_data
intent_logits, slot_logits = joint_model(input_ids, token_type_ids=token_type_ids)
# count intent metric
intent_metric.update(pred_labels=intent_logits, real_labels=intent_labels)
# count slot metric
slot_pred_labels = slot_logits.argmax(axis=-1)
slot_metric.update(pred_paths=slot_pred_labels, real_paths=tag_ids)
intent_results = intent_metric.get_result()
slot_results = slot_metric.get_result()
return intent_results, slot_results
def train():
# start to train joint_model
global_step, intent_best_f1, slot_best_f1 = 0, 0., 0.
joint_model.train()
for epoch in range(1, num_epoch+1):
for batch_data in train_loader:
input_ids, token_type_ids, intent_labels, tag_ids = batch_data
intent_logits, slot_logits = joint_model(input_ids, token_type_ids=token_type_ids)
loss = joint_loss(intent_logits, slot_logits, intent_labels, tag_ids)
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step > 0 and global_step % log_step == 0:
print(f"epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}")
if global_step > 0 and global_step % eval_step == 0:
intent_results, slot_results = evaluate(joint_model, dev_loader, intent_metric, slot_metric)
intent_result, slot_result = intent_results["Total"], slot_results["Total"]
joint_model.train()
intent_f1, slot_f1 = intent_result["F1"], slot_result["F1"]
if intent_f1 > intent_best_f1 or slot_f1 > slot_best_f1:
paddle.save(joint_model.state_dict(), f"{save_path}/best.pdparams")
if intent_f1 > intent_best_f1:
print(f"intent best F1 performence has been updated: {intent_best_f1:.5f} --> {intent_f1:.5f}")
intent_best_f1 = intent_f1
if slot_f1 > slot_best_f1:
print(f"slot best F1 performence has been updated: {slot_best_f1:.5f} --> {slot_f1:.5f}")
slot_best_f1 = slot_f1
print(f'intent evalution result: precision: {intent_result["Precision"]:.5f}, recall: {intent_result["Recall"]:.5f}, F1: {intent_result["F1"]:.5f}, current best {intent_best_f1:.5f}')
print(f'slot evalution result: precision: {slot_result["Precision"]:.5f}, recall: {slot_result["Recall"]:.5f}, F1: {slot_result["F1"]:.5f}, current best {slot_best_f1:.5f}\n')
global_step += 1
train()
6. Model reasoning
Realize a function of model prediction and input a string of text description arbitrarily, such as: "Huawei's mobile phone has been reduced in price, 32 million pixels only need 1000 yuan, and the cost performance of Xiaomi is incomparable!". It is expected to output the events contained in this description. First, we load the trained model parameters, and then reasoning. The relevant codes are as follows.
# load model model_path = "./checkpoint/best.pdparams" loaded_state_dict = paddle.load(model_path) ernie = ErnieModel.from_pretrained(model_name) joint_model = JointModel(ernie, len(slot2id), len(intent2id), dropout=0.1) joint_model.load_dict(loaded_state_dict)
[2021-11-03 14:31:31,350] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-1.0 [2021-11-03 14:31:31,353] [ INFO] - Downloading ernie_v1_chn_base.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams 100%|██████████| 392507/392507 [00:06<00:00, 56321.65it/s] [2021-11-03 14:31:44,458] [ INFO] - Weights from pretrained model not used in ErnieModel: ['cls.predictions.layer_norm.weight', 'cls.predictions.decoder_bias', 'cls.predictions.transform.bias', 'cls.predictions.transform.weight', 'cls.predictions.layer_norm.bias']
def predict(input_text, joint_model, tokenizer, id2intent, id2slot):
joint_model.eval()
splited_input_text = list(input_text)
features = tokenizer(splited_input_text, is_split_into_words=True, max_seq_len=max_seq_len, return_length=True)
input_ids = paddle.to_tensor(features["input_ids"]).unsqueeze(0)
token_type_ids = paddle.to_tensor(features["token_type_ids"]).unsqueeze(0)
seq_len = features["seq_len"]
intent_logits, slot_logits = joint_model(input_ids, token_type_ids=token_type_ids)
# parse intent labels
intent_labels = [id2intent[idx] for idx, v in enumerate(intent_logits.numpy()[0]) if v > 0]
# parse slot labels
slot_pred_labels = slot_logits.argmax(axis=-1).numpy()[0][1:(seq_len)-1]
slot_labels = []
for idx in slot_pred_labels:
slot_label = id2slot[idx]
if slot_label != "O":
slot_label = list(id2slot[idx])
slot_label[1] = "-"
slot_label = "".join(slot_label)
slot_labels.append(slot_label)
slot_entities = get_entities(slot_labels)
# print result
if intent_labels:
print("intents: ", ",".join(intent_labels))
else:
print("intents: ", "nothing")
for slot_entity in slot_entities:
entity_name, start, end = slot_entity
print(f"{entity_name}: ", "".join(splited_input_text[start:end+1]))
input_text = "Hello, you can choose the Forbidden City, Badaling Great Wall, summer palace or red brick art museum."
predict(input_text, joint_model, tokenizer, id2intent, id2slot)
Text to be recognized: Hello, you can choose the Forbidden City, Badaling Great Wall, summer palace or red brick art museum. intents: General+greet+none+none Recommend+scenic spot+name: the Imperial Palace Recommend+scenic spot+name: Badaling Great Wall Recommend+scenic spot+name: the Summer Palace Recommend+scenic spot+name: Red brick art museum
7. More in-depth learning resources
7.1 one stop deep learning platform awesome-DeepLearning
- Introduction to deep learning
- Deep learning questions

- Characteristic course

- Industrial practice
If you have any questions during the use of paddledu, you are welcome to awesome-DeepLearning For more in-depth learning materials, please refer to Propeller deep learning platform.
Remember to order one Star ⭐ Collection oh~~

7.2 propeller technical communication group (QQ)
At present, 2000 + students in QQ group have studied together. Welcome to join us by scanning the code