preface
When upgrading from MongoDB 2 to MongoDB4, the author found that the driver API has been greatly modified. Although the old API is still available, the driver does not know when these old APIs will be deleted, so the new API is used. One important pit is to calculate the count of document, which was originally the count() method of DBCollection, Now that the API is changed to MongoCollection, it has been abandoned. The author takes it for granted to use the countDocuments of MongoCollection, which leaves a performance risk. The fact is that the MongoDB driver has been upgraded from 3.x to 4.x, and many obsolete APIs have been deleted.
1. MongoDB startup
The author's local environment is the mac environment, and the same is true for other environments Linux. Here, a single MongoDB is built instead of a replica set or fragment cluster. The community version is downloaded from the official website of MongoDB
Then start without permission, run mongod directly, and start the win environment with bat or cmd script
./mongod --dbpath=../data --logpath=../logs/mongod.log
Log in directly on this computer

Use use admin to switch the document set of admin
db.createUser({user: "account", pwd: "password", roles: [{role ":" useradmin "," DB ":" admin "}, {" role ":" root "," DB ":" admin "}, {" role ":" useradminanydatabase "," DB ":" admin "}]})
Then start with -- auth
./mongod --dbpath=../data --logpath=../logs/mongod.log --auth &
At this point, MongoDB single node startup is OK and can be used.
2. demo construction
Build the spring boot application and rely on mongodb's starter
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
<version>2.5.5</version>
</dependency>Build a demo of the use of simulation data and count API. Here, pay attention to the self growth of MongoDB_ id can only identify ObjectId, which is a 12 byte BSON type string, including UNIX timestamp, machine identification code, process number and count value information. Unrecognized data type of Long Integer type.
@Repository
public class MongoDBRepository {
@Autowired
private MongoOperations mongoOperations;
public long insertDemos(){
List<CountDemoEntity> list = new LinkedList<>();
for (int i = 0; i < 100000; i++) {
CountDemoEntity countDemoEntity = new CountDemoEntity();
countDemoEntity.setDemo("demo"+i);
countDemoEntity.setDemoName("demo-name"+i);
list.add(countDemoEntity);
if (i % 1000 == 0) {
mongoOperations.insert(list, "countDemo");
list.clear();
}
}
return 100000;
}
public long countDocuments(){
return mongoOperations.getCollection("countDemo").countDocuments();
}
public long estimatedDocumentCount(){
return mongoOperations.getCollection("countDemo").estimatedDocumentCount();
}
}
@Document(collation = "countDemo")
public class CountDemoEntity {
@Id
private ObjectId id;
private String demoName;
private String demo;
public ObjectId getId() {
return id;
}
public void setId(ObjectId id) {
this.id = id;
}
public String getDemoName() {
return demoName;
}
public void setDemoName(String demoName) {
this.demoName = demoName;
}
public String getDemo() {
return demo;
}
public void setDemo(String demo) {
this.demo = demo;
}
}
@RestController
public class MongoDBController {
@Autowired
private MongoDBRepository repository;
@RequestMapping("/insertDemos")
public String insertDemos() {
repository.insertDemos();
return "ok";
}
@RequestMapping("/countDocuments")
public long countDocuments() {
long start = System.currentTimeMillis();
long count = repository.countDocuments();
System.out.println("countDocuments = " + (System.currentTimeMillis()-start));
return count;
}
@RequestMapping("/estimatedDocumentCount")
public long estimatedDocumentCount() {
long start = System.currentTimeMillis();
long count = repository.estimatedDocumentCount();
System.out.println("estimatedDocumentCount = " + (System.currentTimeMillis()-start));
return count;
}
}Simulate data using insert method
http://localhost:8080/insertDemos
The author made 6138062 data

The execution time of count is
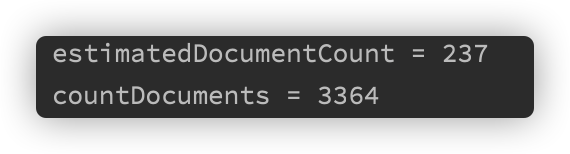
The gap between 237 MS and 3364 MS is too large, and it increases with the increase of MongoDB stored documents. Therefore, it is recommended from the perspective of performance
estimatedDocumentCount
3. Why is countDocuments not recommended
Why is this? You need to check the source code analysis
3.1 estimatedDocumentCount function
public long estimatedDocumentCount(final EstimatedDocumentCountOptions options) {
return executeCount(null, new BsonDocument(), fromEstimatedDocumentCountOptions(options), CountStrategy.COMMAND);
}When it comes to policies, estimatedDocumentCount uses the count command method, that is, the count function reflected in the nosql statement
public enum CountStrategy {
/**
* Use the count command
*/
COMMAND,
/**
* Use the Aggregate command
*/
AGGREGATE
}Further tracking, the command can see that the count instruction is used
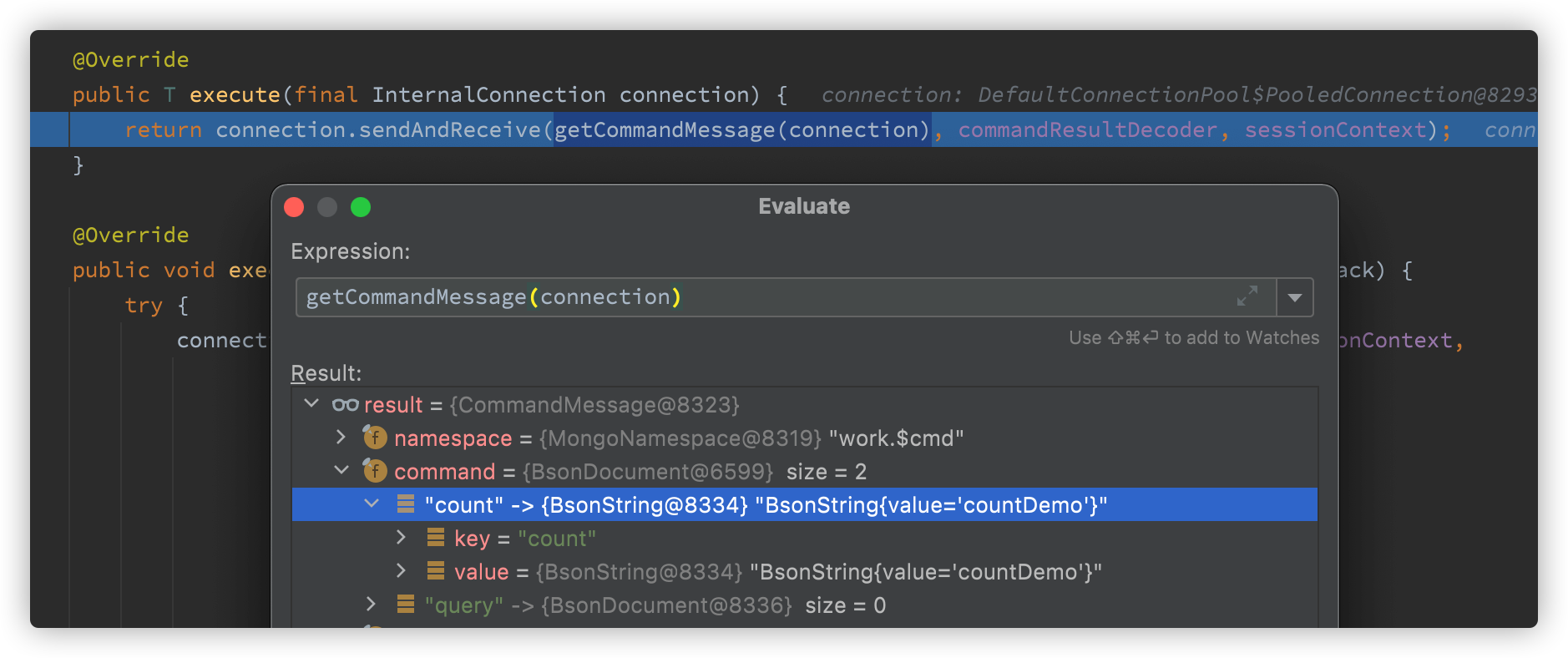
Sending and receiving messages is a bit like rxjava. The observer mode is similar to the event mechanism of spring
public <T> T sendAndReceive(final CommandMessage message, final Decoder<T> decoder, final SessionContext sessionContext) {
ByteBufferBsonOutput bsonOutput = new ByteBufferBsonOutput(this);
CommandEventSender commandEventSender;
try {
//Assemble message
message.encode(bsonOutput, sessionContext);
commandEventSender = createCommandEventSender(message, bsonOutput);
//If you don't open the log here, you won't do anything
commandEventSender.sendStartedEvent();
} catch (RuntimeException e) {
bsonOutput.close();
throw e;
}
try {
//Send command message
sendCommandMessage(message, bsonOutput, sessionContext);
if (message.isResponseExpected()) {
//Get the message, get the result
return receiveCommandMessageResponse(decoder, commandEventSender, sessionContext, 0);
} else {
commandEventSender.sendSucceededEventForOneWayCommand();
return null;
}
} catch (RuntimeException e) {
commandEventSender.sendFailedEvent(e);
throw e;
}
}You can print logs here. It is said on the Internet that configuring print logs is not feasible
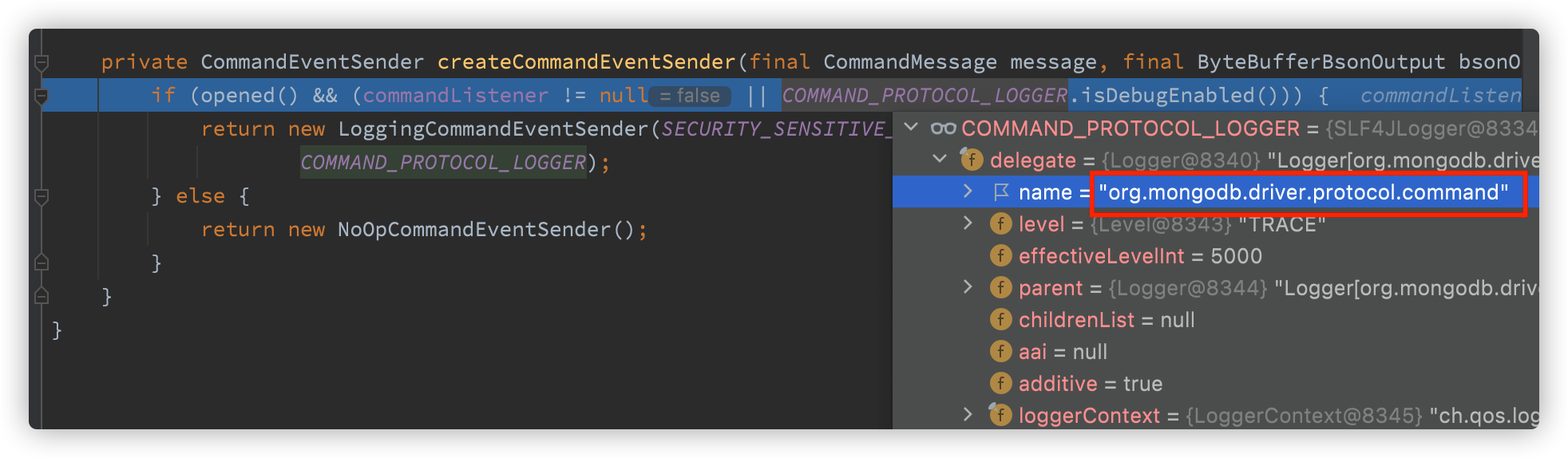
Spring boot requires configuration
logging:
level:
org.mongodb.driver.protocol.command: DEBUG
To print nosql information, which has been proved to be true
2021-10-07 21:22:55.728 DEBUG 5615 --- [nio-8080-exec-1] org.mongodb.driver.protocol.command : Sending command '{"count": "countDemo", "query": {}, "$db": "work", "lsid": {"id": {"$binary": {"base64": "mUhZ0SIkSYWkCSQNo6GdrA==", "subType": "04"}}}}' with request id 6 to database work on connection [connectionId{localValue:3, serverValue:81}] to server localhost:27017
Send instructions
public void sendMessage(final List<ByteBuf> byteBuffers, final int lastRequestId) {
notNull("stream is open", stream);
if (isClosed()) {
throw new MongoSocketClosedException("Cannot write to a closed stream", getServerAddress());
}
try {
stream.write(byteBuffers);
} catch (Exception e) {
close();
throw translateWriteException(e);
}
}The received results include header and buffer, and can also be compressed to reduce network IO
private ResponseBuffers receiveResponseBuffers(final int additionalTimeout) throws IOException {
ByteBuf messageHeaderBuffer = stream.read(MESSAGE_HEADER_LENGTH, additionalTimeout);
MessageHeader messageHeader;
try {
messageHeader = new MessageHeader(messageHeaderBuffer, description.getMaxMessageSize());
} finally {
messageHeaderBuffer.release();
}
ByteBuf messageBuffer = stream.read(messageHeader.getMessageLength() - MESSAGE_HEADER_LENGTH, additionalTimeout);
if (messageHeader.getOpCode() == OP_COMPRESSED.getValue()) {
CompressedHeader compressedHeader = new CompressedHeader(messageBuffer, messageHeader);
Compressor compressor = getCompressor(compressedHeader);
ByteBuf buffer = getBuffer(compressedHeader.getUncompressedSize());
compressor.uncompress(messageBuffer, buffer);
buffer.flip();
return new ResponseBuffers(new ReplyHeader(buffer, compressedHeader), buffer);
} else {
return new ResponseBuffers(new ReplyHeader(messageBuffer, messageHeader), messageBuffer);
}
}three point two countDocuments method
public long countDocuments(final Bson filter, final CountOptions options) {
return executeCount(null, filter, options, CountStrategy.AGGREGATE);
}Use the method of aggregate and cursor
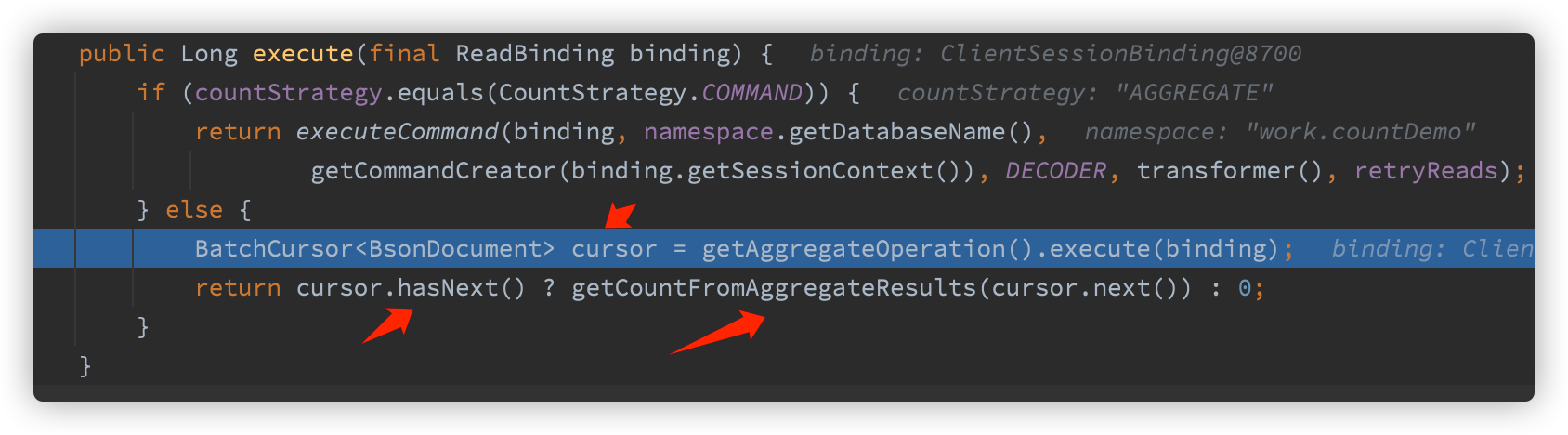
So let's see what the nosql command creates
BsonDocument getCommand(final SessionContext sessionContext) {
BsonDocument commandDocument = new BsonDocument("aggregate", aggregateTarget.create());
appendReadConcernToCommand(sessionContext, commandDocument);
commandDocument.put("pipeline", pipelineCreator.create());
if (maxTimeMS > 0) {
commandDocument.put("maxTimeMS", maxTimeMS > Integer.MAX_VALUE
? new BsonInt64(maxTimeMS) : new BsonInt32((int) maxTimeMS));
}
BsonDocument cursor = new BsonDocument();
if (batchSize != null) {
cursor.put("batchSize", new BsonInt32(batchSize));
}
commandDocument.put(CURSOR, cursor);
if (allowDiskUse != null) {
commandDocument.put("allowDiskUse", BsonBoolean.valueOf(allowDiskUse));
}
if (collation != null) {
commandDocument.put("collation", collation.asDocument());
}
if (comment != null) {
commandDocument.put("comment", new BsonString(comment));
}
if (hint != null) {
commandDocument.put("hint", hint);
}
return commandDocument;
}View directly, 😖, Through the $sum method, it is no wonder that the efficiency of full table scanning and accumulation is low. If this method has accurate conditions, it is good, but the execution of all sets is not good.
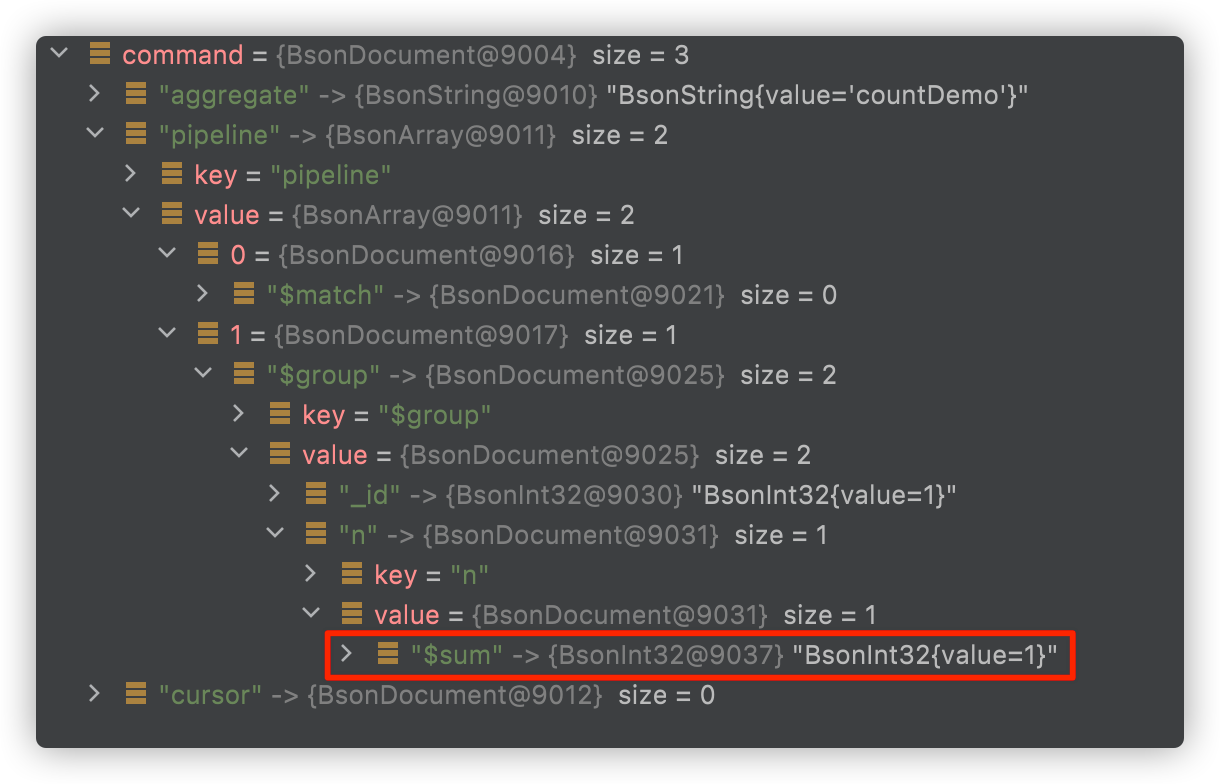
The following logic refers to the above method in 3.1, which is only to receive the cursor, and the received result is blocked until the result is obtained
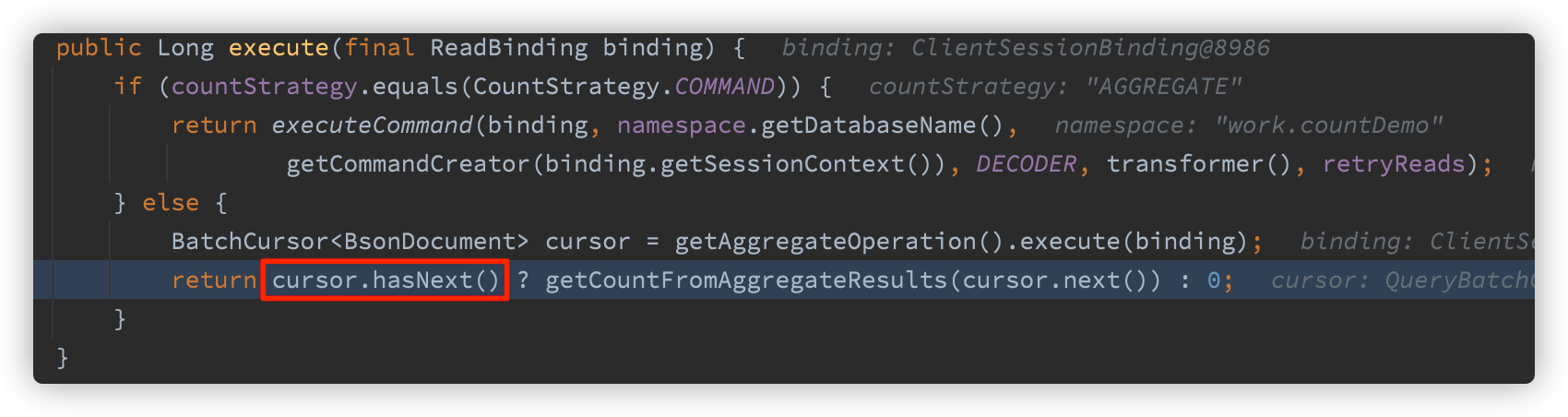
Follow up
public boolean hasNext() {
if (closed) {
throw new IllegalStateException("Cursor has been closed");
}
if (nextBatch != null) {
return true;
}
if (limitReached()) {
return false;
}
while (serverCursor != null) {
getMore();
if (closed) {
throw new IllegalStateException("Cursor has been closed");
}
if (nextBatch != null) {
return true;
}
}
return false;
}The key is getMore
private void getMore() {
Connection connection = connectionSource.getConnection();
try {
//For version 3.2 and above, it seems that version 3.2 has changed a lot
if (serverIsAtLeastVersionThreeDotTwo(connection.getDescription())) {
try {
initFromCommandResult(connection.command(namespace.getDatabaseName(),
asGetMoreCommandDocument(),
NO_OP_FIELD_NAME_VALIDATOR,
ReadPreference.primary(),
CommandResultDocumentCodec.create(decoder, "nextBatch"),
connectionSource.getSessionContext()));
} catch (MongoCommandException e) {
throw translateCommandException(e, serverCursor);
}
} else {
QueryResult<T> getMore = connection.getMore(namespace, serverCursor.getId(),
getNumberToReturn(limit, batchSize, count), decoder);
initFromQueryResult(getMore);
}
if (limitReached()) {
killCursor(connection);
}
} finally {
connection.release();
releaseConnectionSourceIfNoServerCursor();
}
}results of enforcement

Similarly, the log also shows the problem
2021-10-07 21:47:20.363 DEBUG 5615 --- [nio-8080-exec-8] org.mongodb.driver.protocol.command : Sending command '{"aggregate": "countDemo", "pipeline": [{"$match": {}}, {"$group": {"_id": 1, "n": {"$sum": 1}}}], "cursor": {}, "$db": "work", "lsid": {"id": {"$binary": {"base64": "mUhZ0SIkSYWkCSQNo6GdrA==", "subType": "04"}}}}' with request id 29 to database work on connection [connectionId{localValue:3, serverValue:81}] to server localhost:27017
summary
After analyzing the source code, it is found that countDocuments are counted by sum, which is suitable for accurate conditions, and the count instruction is suitable for collecting the overall count.