All the code in this article is written in C + +
4 double linked list, circular linked list and static linked list
4.1 double linked list
4.1.1 definition of double linked list
In the previous knowledge, we once said that because each data element in the single linked list is divided into two parts - data field and pointer field, the single linked list can only find the next element, but not the previous element, that is, it can not be retrieved reversely. In order to solve this problem, we introduced the double linked list.
The nodes of the Double linked list are named with DNode (D refers to Double), which adds a pre pointer field (prior) on the basis of the original data field and pointer field. The definitions are as follows:
typedef struct DNode{
ElemType data;
struct DNode *prior,*next;
}DNode,*DLinklist;
4.1.2 initialization of double linked list
The initialization of a double linked list is different from that of a single linked list.
bool InitDLinkList(DLINKLIST &L){
L = new DNode;
if(L == NULL)
return false;
L->prior = NULL;
L->next = NULL;
return true;
}
4.1.2 post insertion operation of double linked list
Similarly, for students who are familiar with the insertion operation of single linked list, double linked list insertion will also be familiar, but one thing to pay attention to is also the problem of modifying the pointer order.
bool InsertNextDNode(DNode *p,DNode *s){
if(p == NULL || s== NULL)
retur false;
s->next = p->next;
if(p->next != NULL)
p->next->prior = s;
s->prior = p;
p->next = s;
return true;
}
4.1.3 post deletion of double linked list
bool DeleteNextDNode(DNode *p){
if(p == NULL)
return false;
DNode *q = p->next;
if(q == NULL)
return false;
p->next = q->next;
if(q->next != NULL)
q->next->prior = p;
delete(q);
return true;
}
4.1.4 destruction of double linked list
void DestoryList(DLinklist &L)
{
while(L->next != NULL)
DeleteNextDNode(L);
delete(L);
L=NULL;
}
4.2 circular linked list
4.2.1 concept of circular linked list
At the beginning, let's understand the concept of circular list.
Circular linked list: it is a linked list with head and tail connected (that is, the pointer field of the last node in the list points to the head node, and the whole linked list forms a ring).

It should be noted that since there is no NULL pointer in the circular linked list, when the traversal operation is involved, the termination condition will no longer judge whether p or p - > next is NULL as in the non circular linked list, but whether they are equal to the header pointer.
//Cycle condition Single linked list: p! = NULL p->next != NULL //Circular single linked list: p! = L p->next! = L
4.2.2 circular single chain list
In the previous study of single linked list, we know that if for a node p, its precursor node does not know where it is. However, for a circular single linked list, starting from any node in the table, you can find other nodes in the table, because the table is circular.
For ordinary single linked list, the time complexity of finding the tail from the head node is O(n); The same is true for circular linked lists, but if you find the head from the tail, the time complexity is actually O(1). Therefore, for many operations, if you need to frequently work on the header and footer, you can make the L pointer point to the footer element during initialization.
4.2.2.1 initialization of circular single linked list
bool InitList(LinkList &L){
L = new LNode; //Assign a header node
if(L == NULL) //Insufficient memory allocation failed
return false;
L->next = L; //The header node next points to the header node
return true;
}
4.2.2.2 empty judgment of circular single linked list
bool Empty(LinkList L){
if(L->next == L)
return true;
else
return false;
}
4.2.2.3 judge the end node of the table
bool isTail(LinkList L,LNode *p){
if(p->next == L)
return true;
else
return false;
}
4.2.3 circular bidirectional linked list
Although the circular single linked list can find any node from any node, if the node to be found is just the previous node, isn't it a waste of time? Circular lists are similar to circular lists. If the above situation occurs, it can be accessed directly through the front pointer.
4.2.3.1 initialization of circular double linked list
We discussed its definition in the last section, as follows:
//Definition of circular double linked list
typedef struct DNode
{
int data;
struct DNode* prior,*next;
}DNode,*DLinklist;
Its initialization is as follows:
//Initialize circular double linked list
bool InitDList(DLinklist& L)
{
L = new DNode;
if (L == NULL)
return false;
L->prior = L;
L->next = L;
return true;
}
For initializing the two-way linked list, we should first pay attention to the problem of insufficient memory space, which should also be paid attention to in the previous single linked list initialization; The second difference is: because it is a circular linked list, the subsequent pointer field does not point to null, but needs to refer to itself; Similarly, the same is true for the precursor pointer field.
4.2.3.2 empty judgment of circular double linked list
If you want to judge whether the double linked list is empty, it is nothing more than to judge whether the precursor pointer and successor pointer point to the head node as in initialization, as follows:
//Judge whether the circular double linked list is empty
bool Empty(DLinklist L)
{
if (L->next == L)
return true;
else
return false;
}
4.2.3.3 insertion of circular double linked list
If you want to insert the circular double linked list, you need to pay attention to changing more than one pointer. If you want to insert node s after node p in the circular double linked list, it is as follows:
bool InsertNextDNode(DNode* p, DNode* s)
{
s->next = p->next;
p->next->prior = s;
s->prior = p;
p->next = s;
}
4.2.3.4 deletion of circular double linked list
For deletion, it is the same as for insertion:
//delete p->next = q->next; q->next->prior = p; free(q);
2.5.2 merging two linked lists
How to merge two linked lists with tail pointers
Train of thought analysis:
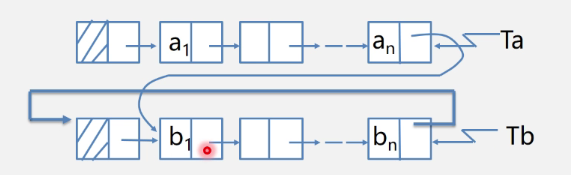
Operation analysis:
//Save header node with p p = Ta->next; //Tb header connected to Ta footer Ta -> next = Tb ->next ->next; //Release Tb header node delete Tb->next; //Modify pointer Tb -> next = p;
Specific code:
LinkList Counnect(LinkList Ta,LinkList Tb){
//Suppose that Ta and Tb are non empty single cycle linked lists
p = Ta->nextl//p save header node
Ta->next = Tb->next->next;//Tb with Ta tail
delete Tb->next;//Release Tb header node
Tb->next = p;/
return Tb;
}
4.3 static linked list
In the postgraduate entrance examination, the code implementation of static linked list is rarely investigated. So people who take the postgraduate entrance examination can watch this section step by step.
In the early programming environment, there was no such advanced pointer mechanism as C language. If we lose the tool of pointer, the linked list structure we talked about earlier will fail. To this end, people came up with an array instead of a pointer to describe a single linked list.
We let the elements of the array consist of two data fields, data and cur. In other words, the index subscript of the array corresponds to a data and a cur. The data field data is used to store data elements, and the cursor cur is equivalent to the next pointer in the single linked list, which stores the subsequent subscripts of the element in the array. If a picture is used to describe it, it is as follows:
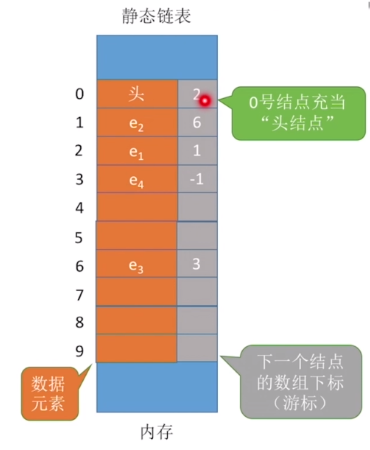
We call this kind of linked list described by array as static linked list, and it is also called cursor implementation method in some books.
4.3.1 definition of static linked list
For static linked list, because it is actually stored by array, it needs a whole piece of continuous space with high storage density; And because the array has static characteristics, in order to facilitate the insertion of data, we usually build the array larger, so that the free space can be inserted conveniently without overflow.
#define MAXSIZE 100
typedef struct
{
ElemType data;
int cur
}Component,StaticLinkList [MAXSIZE];
4.3.2 initialization of static linked list
In the initialization of single linked list, we set the pointer field of the head node to null. Corresponding to the static linked list, we can set its cursor to - 1, indicating that there is no index in the array to point to.
Status InitList(StaticLinkList space)
{
int i;
for(i = 0;i<MAXSIZE-1;i++)
space[i].cur = -2;
space[MAXSIZE-1].cur = 0;
return OK;
}
In fact, I made some improvements to the above code. The function of the for loop is to attach a - 2 to the cursor of each element in the array. This is because there is dirty data in the memory. If we don't initialize the cursor, there is still data in it. When adding elements, we can't judge which array element is empty. Of course, if you like, - 2 can also be other negative numbers or some specific numbers.
4.3.3 insertion of static linked list
For static linked list, because it can not generate nodes like single linked list, and there is no function to release nodes, we must implement these two functions ourselves.
For inserting nodes with bit order i, we can do it in the following steps:
- Find an empty node and store it in the data element
- Find the node with bit order i-1 by division from the ab initio node
- Modify the next of the new node
- Modify the next of node i-1
4.3.4 deletion of static linked list
If you want to delete a node, you can do it in the following steps:
- Starting from the original node, find the precursor node
- Modify the cursor of the precursor node
- The next of the deleted node is set to - 2 (it can be set as the initialization value)
4.3.5 after static linked list
The advantages and disadvantages of static linked list are obvious. The advantage is that during the insertion and deletion operations, only the cursor needs to be modified without moving elements, which improves the disadvantage that the insertion and deletion operations need to move a large number of elements in the sequential storage structure.
The disadvantage is that although it is stored sequentially, it insists on implementing the linked list, which leads to the loss of the characteristics of random access, and the table length cannot be extended due to the fixed length of the array. (although dynamic arrays can be used, it's too troublesome)
Generally speaking, the static linked list is applicable in some places, such as in some low-level languages that do not support pointers and some scenes where the number of array elements is fixed (such as the file allocation table FAT of the operating system).