Introduction:
MapReduce is a cluster based high-performance parallel computing platform. MapReduce is a software framework for parallel computing and operation. MapReduce is a parallel programming model and method
characteristic:
① The distribution is reliable. The operation of the data set is distributed to multiple nodes in the cluster to achieve reliability. Each node periodically returns its completed tasks and the latest status
② Encapsulate the implementation details, program based on the framework API, and carry out distributed coding for business
③ Provide cross language programming capabilities
Main functions of MapReduce:
1.1 data division and computing task scheduling
1.2 data / code positioning
1.3 system optimization
Error detection and recovery
Operation process of MapReduce:
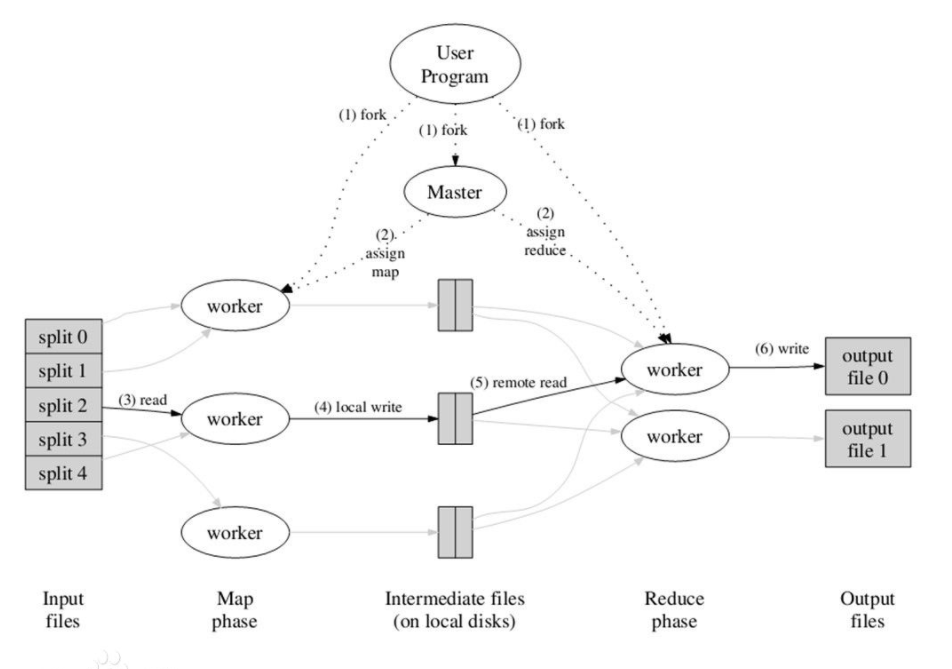
As can be seen from the above figure, MapReduce mainly includes the following steps:
1) First, formally submit the job code and slice the input data source
2) master schedules worker s to execute map tasks
3) The map task in the worker reads the input source slice
4) The worker executes the map task and saves the task output locally
5) The master schedules the worker to execute the reduce task, and the reduce} worker reads the output file of the map task
6) Execute the reduce task and save the task output to HDFS
Detailed explanation of operation process
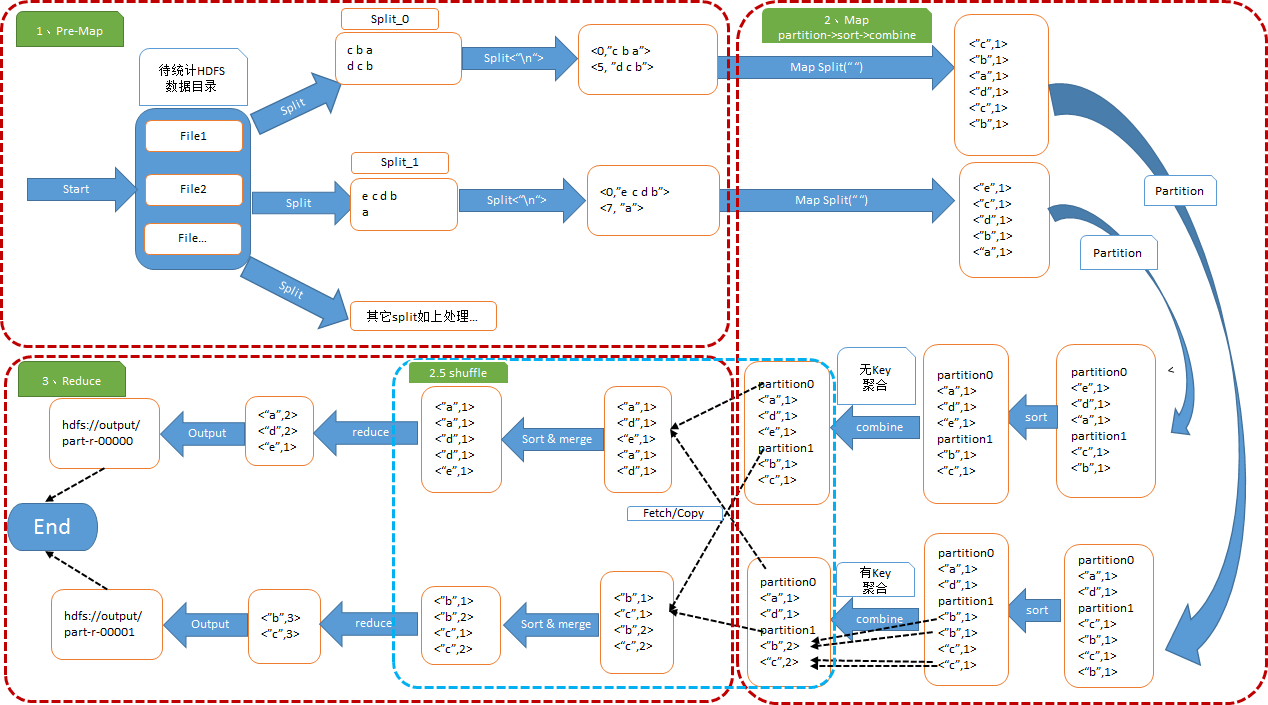
Map: input the data of HDFS directory, then cut the blocks and distribute the cut blocks to different computers. Each computer partitions the blocks according to the local protocol, sorts the different areas according to the key, and then saves the task output locally
Reduce: copy the data from the remote, then merge and process the data according to the key, and finally output
Map The stage consists of a certain number of Map Task The composition and process are as follows: ■ Input data format analysis: InputFormat ■ Input data processing: Mapper ■ Data partition: Partitioner ■ Data according to key sort ■ Local protocol: Combiner(amount to local reducer,(optional) ■ Save task output locally Reduce The stage consists of a certain number of Reduce Task The composition and process are as follows: ■ Remote copy of data ■ Data according to key Sorting and file merging merge ■ Data processing: Reducer ■ Data output format: OutputFormat Usually we start with Mapper Phase output data to Reduce Phasic reduce The process between calculations is called shuffle
MapReduce # Java # API Application
1. MapReduce development process
➢ Build a development environment for reference HDFS The environment is basically the same ➢ be based on MapReduce Framework coding, Map,Reduce,Driver It consists of three parts. ➢ Compile and package the source code into packages and dependencies jar Bag into a bag ➢ Upload to operating environment ➢ function hadoop jar Command, now by yarn jar Instead, it is recommended to use the new command to submit for execution The specific submission orders are: yarn jar testhdfs-jar-with-dependencies.jar com.tianliangedu.driver.WordCount /tmp/tianliangedu/input /tmp/tianliangedu/output3 ➢ adopt yarn web ui View execution process ➢ View execution results
2. WordCount code implementation
Mapper: yes MapReduce Calculation framework Map Process encapsulation Text: Hadoop yes Java String Class, suitable for Hadoop Processing of text strings IntWritable: Hadoop yes Java Integer Class, suitable for Hadoop Integer processing Context: Hadoop Context based operational objects, such as Map in key/value Output of, distributed cache data, distributed parameter transfer, etc StringTokenizer: yes String Object string operation class, which is a tool class for segmentation operation based on white space characters
-
2.1} Map class preparation
-
package com.tianliangedu.mapper; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MyTokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { // Temporarily store the word frequency count of each transmitted word, which is 1, eliminating the space for repeated applications private final static IntWritable one = new IntWritable(1); // Temporarily store the value of each transmitted word to save the space for repeated application private Text word = new Text(); // The specific implementation of the core map method is to process < key, value > pairs one by one public void map(Object key, Text value, Context context) throws IOException, InterruptedException { // Initializes the StringTokenizer with the string value of each line StringTokenizer itr = new StringTokenizer(value.toString()); // Loop to get each element separated by each blank character while (itr.hasMoreTokens()) { // Put each obtained element into the word Text object word.set(itr.nextToken()); // Output the map one by one through the context object context.write(word, one); } } }2.2 Reduce class writing
-
Reducer: it is the encapsulation of the Reduce process in the MapReduce computing framework
-
package com.tianliangedu.reducer; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; //The reduce class implements the reduce function public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); //The specific implementation of the core reduce method is processed one by one < key, list (V1, V2) > public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //Temporarily calculate the sum in each key group int sum = 0; //Enhanced for, obtain the value of each element in the iterator in turn, that is, the word frequency value one by one for (IntWritable val : values) { //sum up each word frequency value in the key group sum += val.get(); } //Put the value completed by the key group sum into the result IntWritable so that the output can be serialized result.set(sum); //Output the calculation results one by one context.write(key, result); } }2.3. Driver class writing
-
➢ Configuration: And HDFS Medium Configuration Consistent, responsible for parameter loading and transfer ➢ Job: Homework is a round MapReduce The abstraction of a task, that is, a MapReduce Management of the whole process of implementation ➢ FileInputFormat: Specifies the tool class of input data, which is used to specify the input data path of the task ➢ FileOutputFormat: Specifies the tool class of the output data, which is used to specify the output data path of the task
package com.tianliangedu.driver; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.tianliangedu.mapper.MyTokenizerMapper; import com.tianliangedu.reducer.IntSumReducer; public class WordCountDriver { // How to start mr driver public static void main(String[] args) throws Exception { // Get cluster configuration parameters Configuration conf = new Configuration(); // Set to this job instance Job job = Job.getInstance(conf, "dawn WordCount"); // Specifies that the main class of this execution is WordCount job.setJarByClass(WordCountDriver.class); // Specify map class job.setMapperClass(MyTokenizerMapper.class); // Specify the combiner class or not. If specified, it is generally the same as the reducer class job.setCombinerClass(IntSumReducer.class); // Specify reducer class job.setReducerClass(IntSumReducer.class); // Specify the types of key and value of job output. If the output types of map and reduce are different, you need to reset the class types of key and value of map output job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // Specifies the path to the input data FileInputFormat.addInputPath(job, new Path(args[0])); // Specify the output path and require that the output path must not exist FileOutputFormat.setOutputPath(job, new Path(args[1])); // Specify the job execution mode. The client submitting the task will not exit until the task is completed! System.exit(job.waitForCompletion(true) ? 0 : 1); } }2.4 running mapreduce in a local simulation distributed computing environment
In view of the complexity of remote running for code testing, and other new frameworks begin to support local environment to simulate distributed computing, mapreduce starts from 2.0 X has also begun to support local environments
For details, please refer to the auxiliary data set "06 - operation steps of simulating mapreduce parallel computing in local environment".
2.5 packaging of Maven
Use the Maven command to package the code based on the configured Maven plug-in.
2.6 upload to the operating environment
Use the rz command to upload the run package to the cluster environment.
2.7 run WordCount program
The specific submission orders are:
The specific submission orders are: yarn jar testhdfs-jar-with-dependencies.jar com.tianliangedu.driver.WordCount /tmp/tianliangedu/input /tmp/tianliangedu/output3
2.8. Check the execution process
The Web access address is: http://cluster1.hadoop:8088/ui2/#/yarn-apps/apps
-
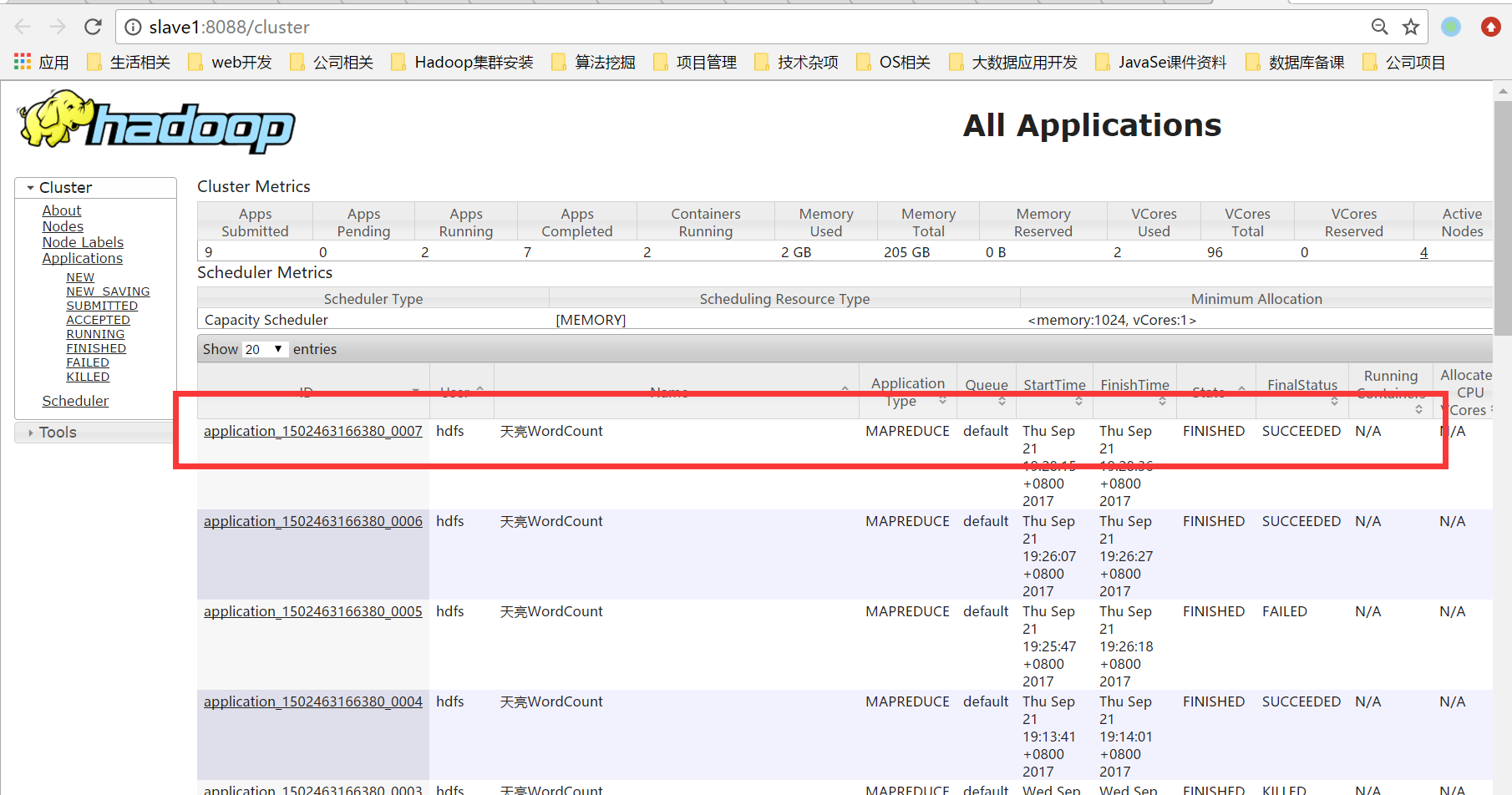
2.9. View the execution results
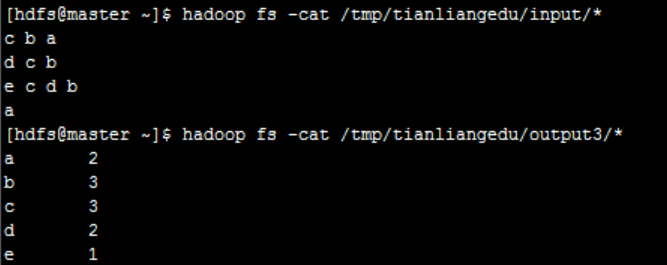 3. Standard code implementation
3. Standard code implementation
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//Start mr's driver class
public class WordCountDriver {
//Map class, which implements the map function
public static class MyTokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
//Temporarily store the word frequency count of each transmitted word, which is 1, eliminating the space for repeated applications
private final static IntWritable one = new IntWritable(1);
//Temporarily store the value of each transmitted word to save the space for repeated application
private Text word = new Text();
//The specific implementation of the core map method is to process < key, value > pairs one by one
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//Initializes the StringTokenizer with the string value of each line
StringTokenizer itr = new StringTokenizer(value.toString());
//Loop to get each element separated by each blank character
while (itr.hasMoreTokens()) {
//Put each obtained element into the word Text object
word.set(itr.nextToken());
//Output the map one by one through the context object
context.write(word, one);
}
}
}
//The reduce class implements the reduce function
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
//The specific implementation of the core reduce method is processed one by one < key, list (V1, V2) >
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
//Temporarily calculate the sum in each key group
int sum = 0;
//Enhanced for, obtain the value of each element in the iterator in turn, that is, the word frequency value one by one
for (IntWritable val : values) {
//sum up each word frequency value in the key group
sum += val.get();
}
//Put the value completed by the key group sum into the result IntWritable so that the output can be serialized
result.set(sum);
//Output the calculation results one by one
context.write(key, result);
}
}
//Start the driver method of mr
public static void main(String[] args) throws Exception {
//Get cluster configuration parameters
Configuration conf = new Configuration();
//Set to this job instance
Job job = Job.getInstance(conf, "dawn WordCount");
//By specifying the relevant bytecode object, find the main jar package to which it belongs
job.setJarByClass(WordCountDriver.class);
//Specify map class
job.setMapperClass(MyTokenizerMapper.class);
//Specify the combiner class or not. If specified, it is generally the same as the reducer class
job.setCombinerClass(IntSumReducer.class);
//Specify reducer class
job.setReducerClass(IntSumReducer.class);
//Specify the types of key and value of job output. If the output types of map and reduce are different, you need to reset the class types of key and value of map output
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//Specifies the path to the input data
FileInputFormat.addInputPath(job, new Path(args[0]));
//Specify the output path and require that the output path must not exist
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Specify the job execution mode. The client submitting the task will not exit until the task is completed!
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}MapReduce Shell application
1. Secondary command of MapReduce
Mapred is called the first level command. Enter mapred and press enter to view the second level command:
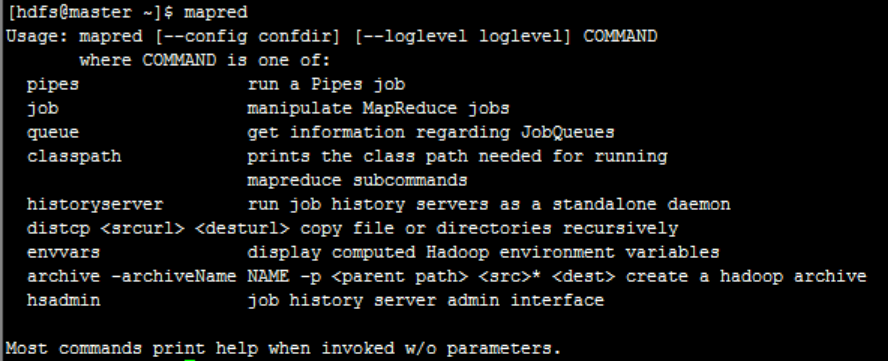
2. Three level commands of MapReduce
Enter the first level command mapred, and then enter any second level command to view the third level command:
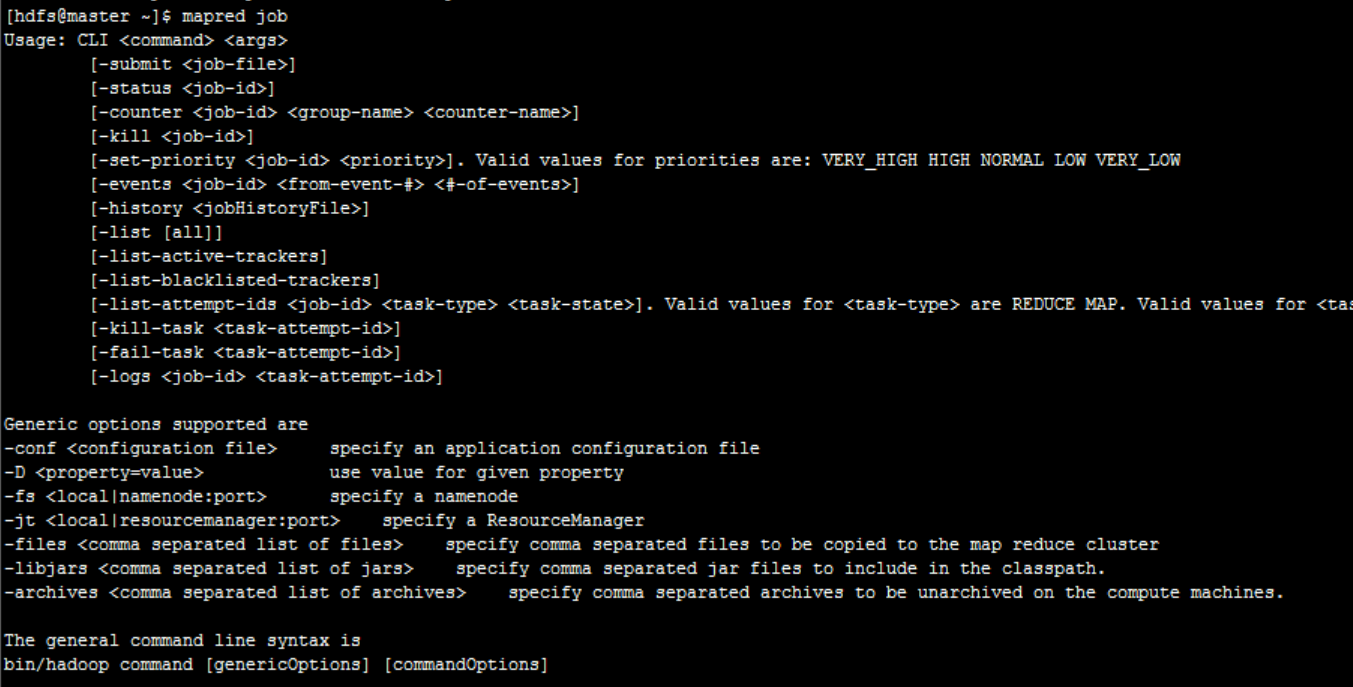
3. MapReduce shell application
-
View currently executing job tasks
-
First submit a WordCount task, and then use mapred job - list to view the task list
-
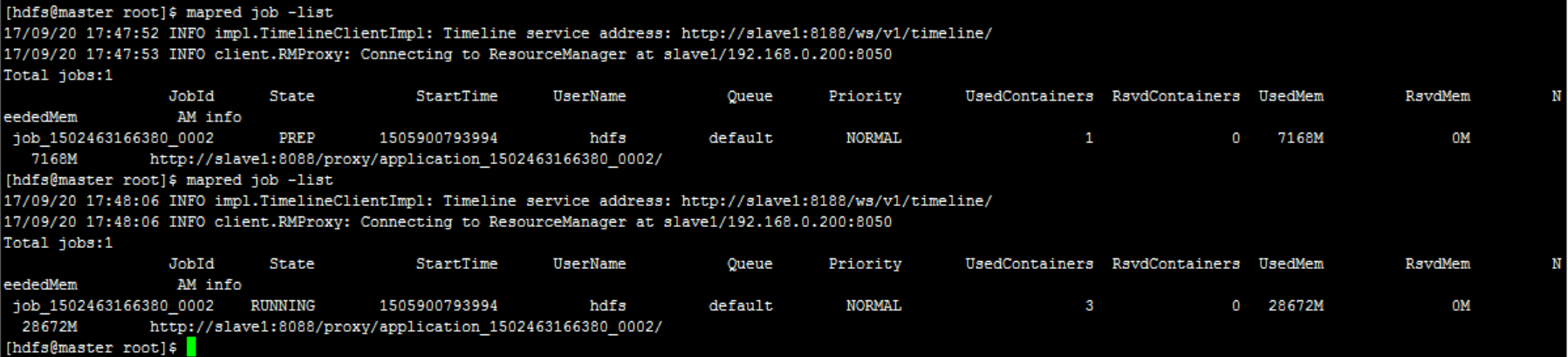
-
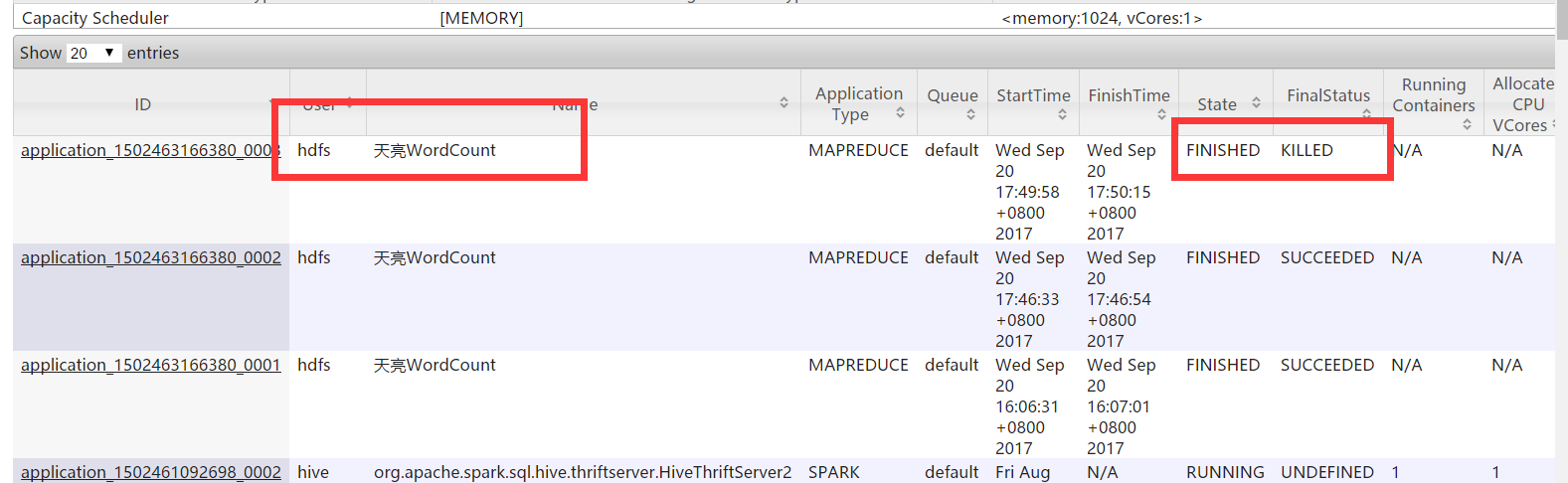
Kill the execution of a task
For some reason, to immediately terminate the execution of a task, use mapred job - kill job ID.
Construction scenario: first submit a WordCount job, and then terminate the task through kill job ID:


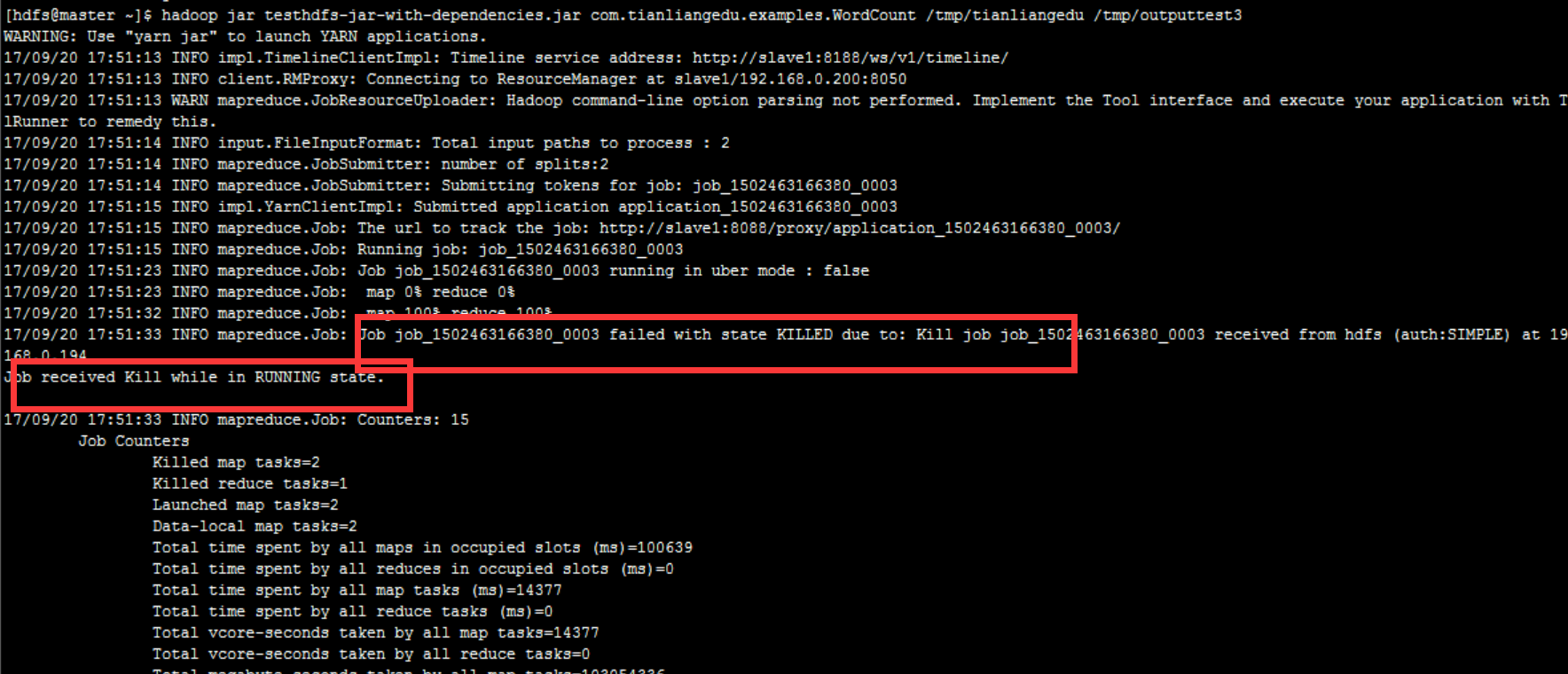
-
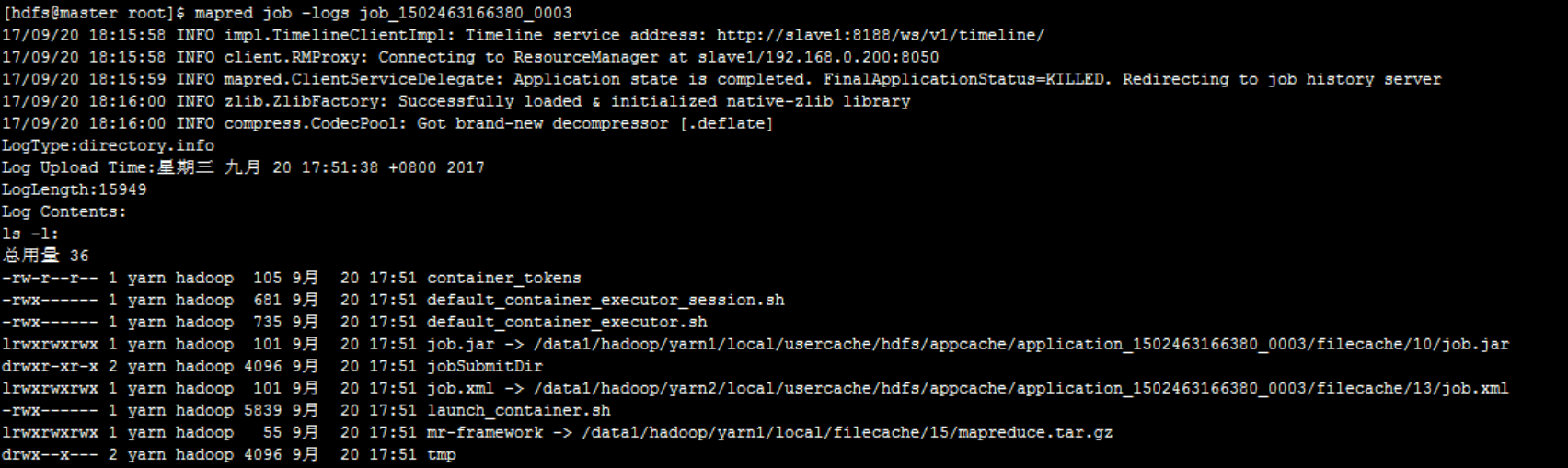
View the log of a job
Using the mapred shell command, you can view the job log through job ID.
The command format is: mapred job - logs job ID:
MapReduce technical characteristics 1,Expand "out" horizontally, not "up" vertically ➢ The construction of the cluster completely selects low-end commercial servers that are cheap and easy to expand, rather than expensive and difficult to expand commercial services ➢ For the needs of large-scale data processing and large-scale data storage, the comprehensive capacity of the cluster is emphasized, rather than the processing capacity of a single machine, and the data volume of machine nodes is increased horizontally 2,Failure is considered normal ➢ Using a large number of ordinary servers, node hardware and software errors are normal ➢ It has a variety of effective error detection and recovery mechanisms, which will automatically transfer to other computing nodes after a computing node fails. After a task node fails, other nodes can seamlessly take over the computing tasks of the failed node ➢ After the failed node recovers, it will automatically and seamlessly join the cluster without requiring the administrator to manually configure the system 3,Mobile computing, migrating processing to data(Data locality) ➢ Adopt code/The function of data mutual positioning. The calculation and data are in the same machine node or the same rack, giving play to the characteristics of data localization ➢ It can avoid data transmission across machine nodes or racks and improve operation efficiency 4,Process data sequentially and avoid random access to data ➢ Sequential access to disks is much faster than random access, so MapReduce It is designed for disk access processing of sequential large-scale data ➢ Using a large number of data storage nodes in the cluster to access data at the same time, high-throughput parallel processing for large data set batch processing is realized 5,Speculative execution ➢ A job consists of several Map Tasks and Reduce Task composition: the completion time of the whole job depends on the completion time of the slowest task. Some tasks may run very slowly due to the hardware and software problems of the node ➢ Using the speculative execution mechanism, it is found that the running speed of a task is much lower than the average speed of the task, and a backup task will be started for the slow task and run at the same time. Which runs first and which results are adopted. 6,Smooth and seamless scalability ➢ Cluster computing nodes can be flexibly increased or reduced to adjust computing power ➢ The performance of the calculation keeps near linear growth with the increase of the number of nodes 7,Hide the underlying details of the system for application development ➢ There are many difficulties in parallel programming. We need to consider the complex and cumbersome details in multithreading, such as distributed storage management, data distribution, data communication and synchronization, calculation result collection and so on. ➢ MapReduce It provides an abstract mechanism to separate the programmer from the details of the system layer. The programmer only needs to pay attention to the business, and other specific execution can be handled by the framework.