01. Get to know ZooKeeper
-
ZooKeeper is a sub project under the Apache Hadoop project. It is a tree directory service.
-
ZooKeeper is translated as the zoo keeper, who is used to manage Hadoop (elephant) and hive (bee).
-
ZooKeeper is a distributed, open source coordination service for distributed applications.
-
The main functions provided by ZooKeeper include:
- configuration management
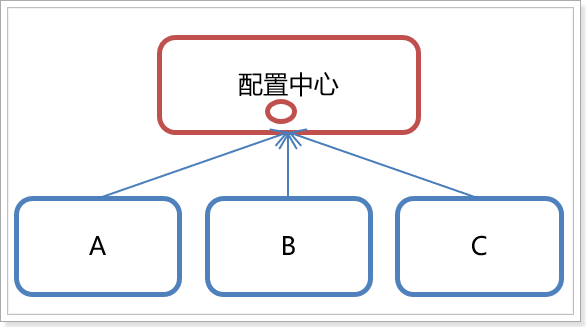
-
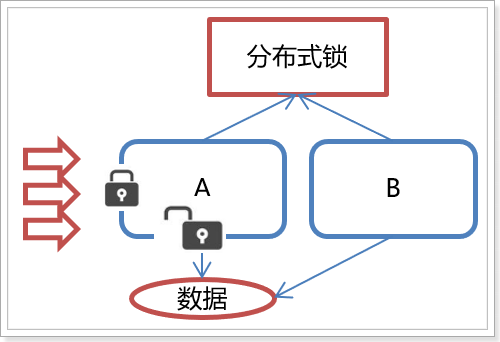
Distributed lock
-
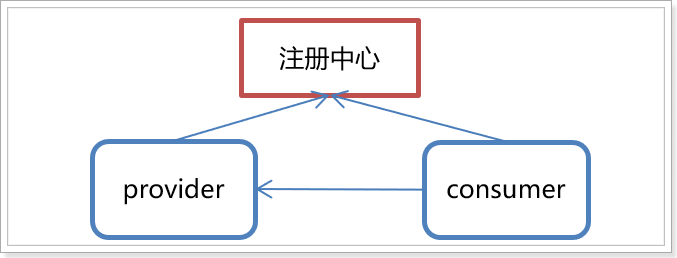
Registration Center
02. ZooKeeper installation
Installation steps
# Make sure the jdk environment is installed first cd /usr/local # Upload the compressed package to the linux system and unzip it tar -zxvf apache-zookeeper-3.6.2-bin.tar.gz # Enter apache-zookeeper-3.6.2-bin directory cd apache-zookeeper-3.6.2-bin

# Enter the conf directory cd conf # Put zoo_sample.cfg is renamed zoo cfg mv zoo_sample.cfg zoo.cfg # Open zoo Cfg file, modify dataDir attribute vi zoo.cfg
# Set zoo CFG directory where data is placed dataDir=/usr/local/apache-zookeeper-3.6.2-bin/data # Save exit
# Enter the bin directory cd /usr/local/apache-zookeeper-3.6.2-bin/bin # Start service command ./zkServer.sh start

./zkServer.sh stop Stop service command ./zkServer.sh status View service status
03. ZooKeeper command operation (understand)
3.1 data model
-
ZooKeeper is a tree directory service. Its data model is very similar to the Unix file system directory tree and has a hierarchical structure.
Unix file system directory:
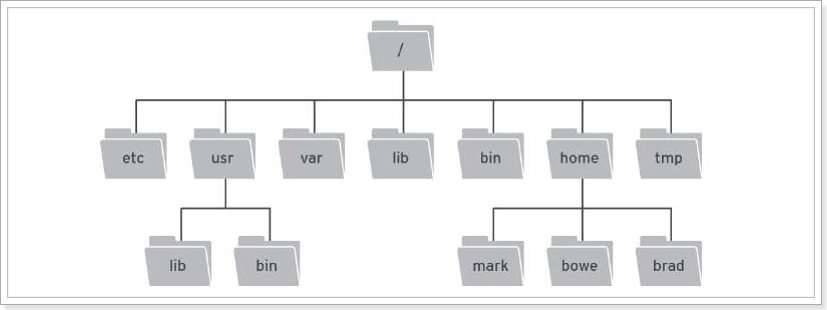
zookeeper directory structure:
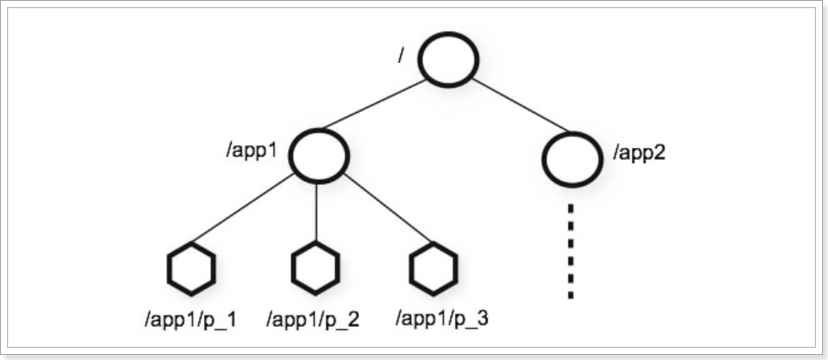
-
Each node is called ZNode, and each node will save its own data and node information.
-
A node can have child nodes and allow a small amount (1MB) of data to be stored under the node.
-
Nodes can be divided into four categories:
- PERSISTENT persistent node
- EPHEMERAL temporary node: - e
- PERSISTENT_SEQUENTIAL persistent order node: - s
- EPHEMERAL_SEQUENTIAL temporary sequence node: - es
3.2 common commands on the server
We can connect to the server through zookeeper's client tool or zookeeper's Api:
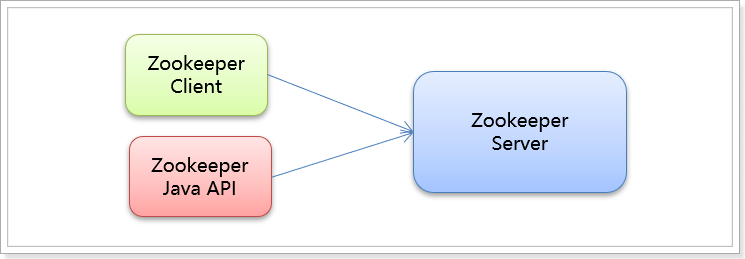
First, let's look at the zookeeper server command. The zookeeper server command is relatively simple, as follows:
# Start ZooKeeper service ./zkServer.sh start # View ZooKeeper service status ./zkServer.sh status # Stop ZooKeeper service ./zkServer.sh stop # Restart ZooKeeper service ./zkServer.sh restart
3.3 common client commands
3.3.1 connection and exit
# You can connect to the zookeeper server without specifying the server address. The default connection is localhost:2181 ./zkCli.sh # Connect to the specified server address ./zkCli.sh –server localhost:2181 # Disconnect quit
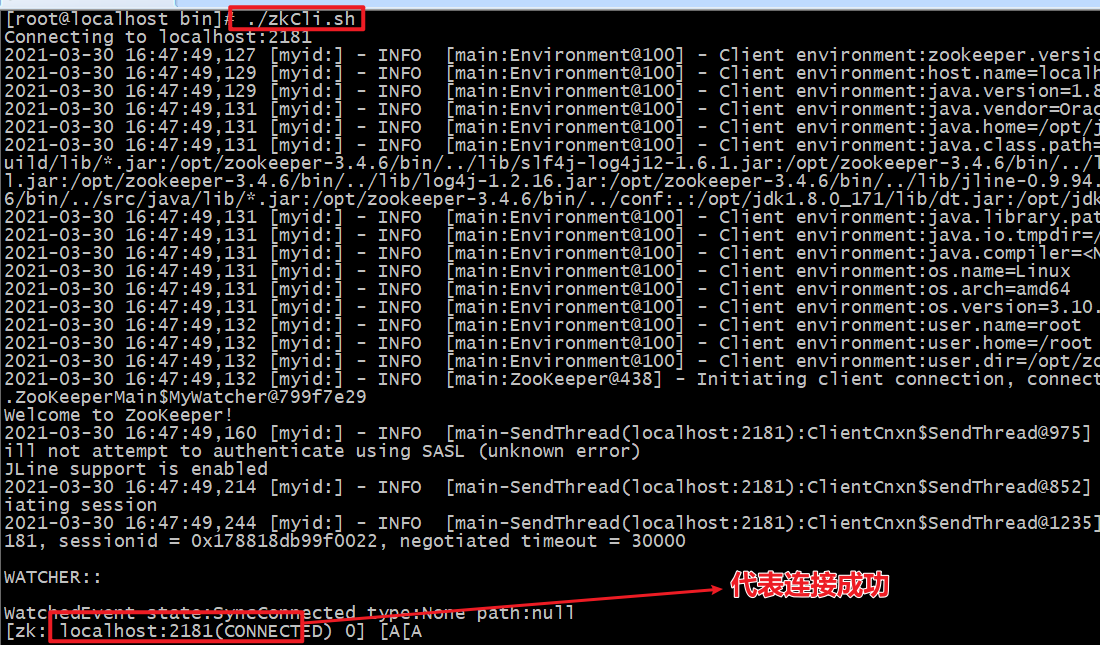
3.3.2 view directory
# Displays the node / representative root directory under the specified directory ls /

Note: if there is a dubbo node, it indicates that it has been used as the information created by the registry
# View the information under the dubbo node ls /zookeeper
3.3.3 create node
# Create the app1 node under the root node and set the value to itheima create /app1 itheima

# Create an app2 node under the root node without setting a value create /app2 ""

Note: This is a bug in version 3.4. You must give a value to create a node. It was fixed after 3.5, that is, you don't need ""
# Create child node create /app2/app2-2 ""
3.3.4 obtaining node values
# Gets the value of the / app1 node get /app1
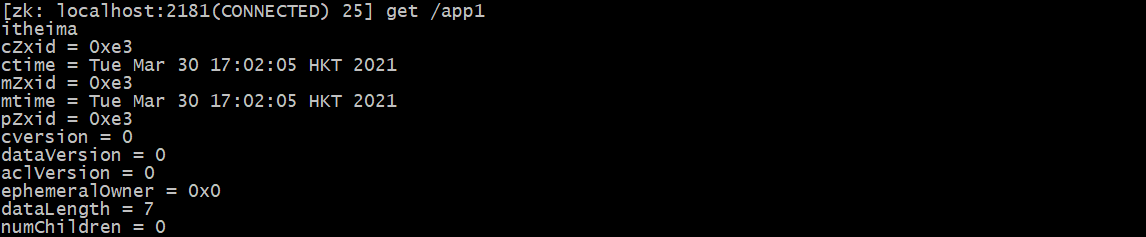
3.3.5 setting node values
# It is equivalent to modifying the value of / app1 node to itheima2 set /app1 itheima2
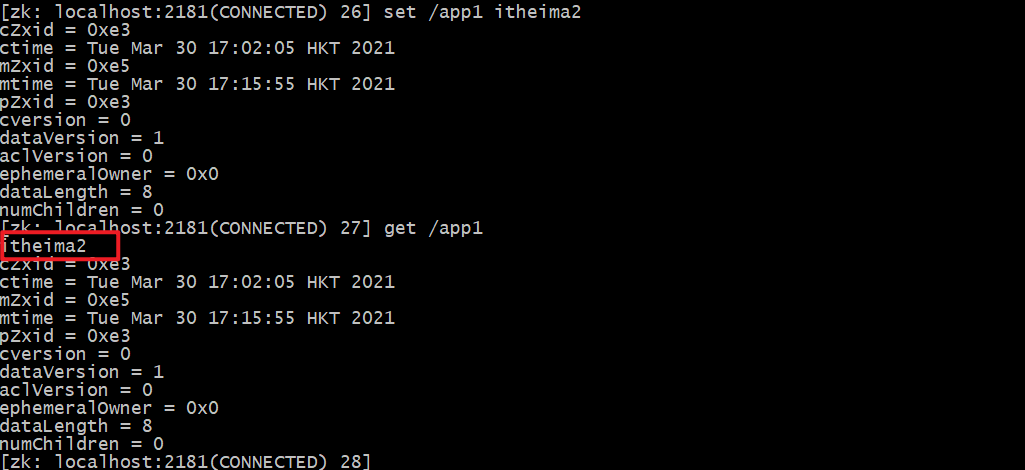
3.3.6 deleting nodes
# Delete a single node. If there are child nodes below, it cannot be deleted delete /app1 # Delete nodes with child nodes. Some versions are deleteall rmr /app2

3.3.7 temporary and sequential nodes
# Create a temporary node / app1. If the connection is disconnected, the node will disappear create -e /app1 111
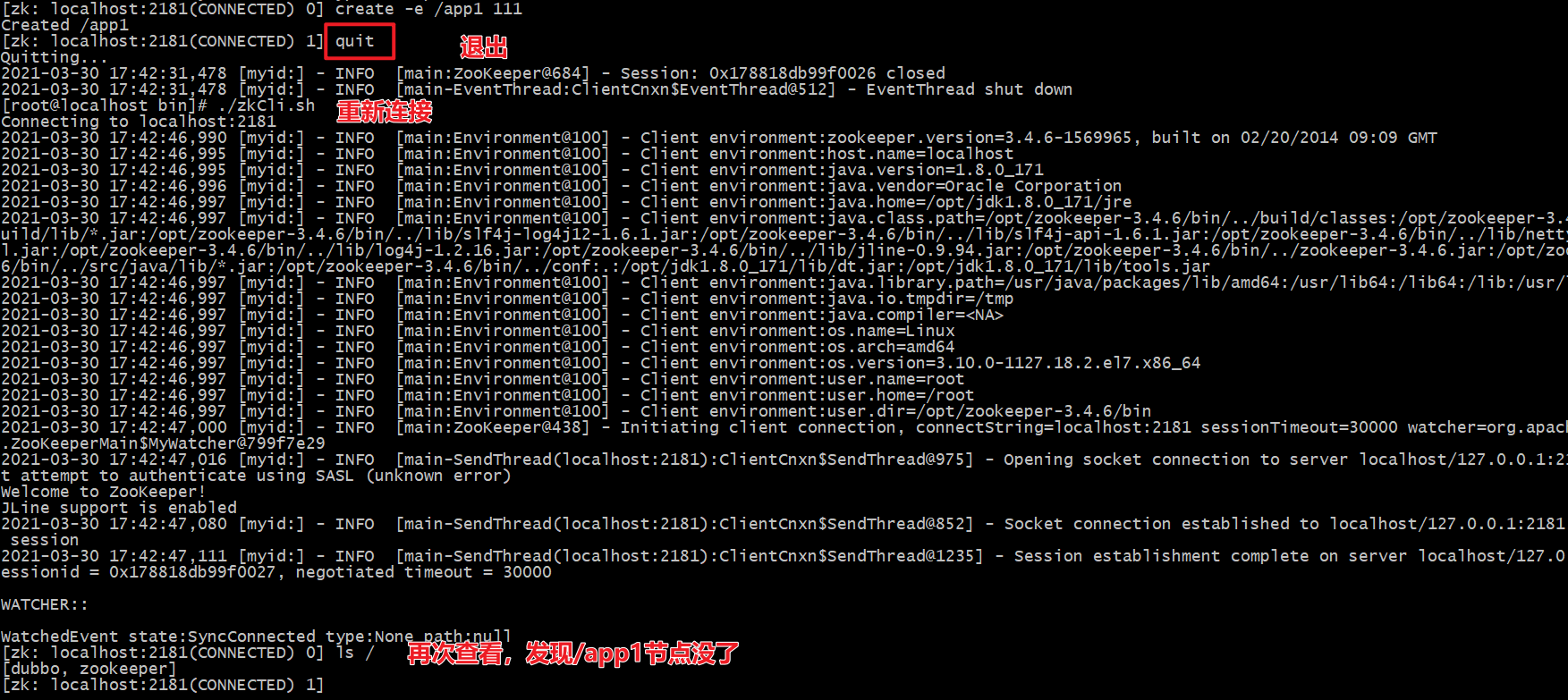
# When creating an order node, a pile of numbers will be added after app1 to facilitate sorting create -s /app1 111 create -s /app1 111 create -s /app1 111

3.3.7 view node details
# Create a node first create /app2 111 # View the node information, and then discard some high version primary keys. Use ls -s /app2 ls2 /app2

explain:
- czxid: transaction ID of the node to be created
- ctime: creation time
- mzxid: last updated transaction ID
- mtime: modification time
- pzxid: transaction ID of the last updated child node list
- cversion: version number of the child node
- Data version: data version number
- aclversion: permission version number
- ephemeralOwner: used for temporary nodes, representing the transaction ID of the temporary node. If it is a persistent node, it is 0
- dataLength: the length of the data stored by the node
- numChildren: the number of child nodes of the current node
04. Zookeeper Java API operation (understand)
4.1 introduction to cursor
Cursor is the Java client library of Apache ZooKeeper, which makes it easier to use ZooKeeper. It contains several packages:
- Cursor client: used to replace the class provided by ZooKeeper. It encapsulates the underlying management and provides some useful tools.
- Cursor framework: it provides advanced API s to simplify the use of ZooKeeper, and adds many ZooKeeper based features to help manage ZooKeeper connections and retry operations.
- Cursor Recipes: encapsulates some advanced features, such as Cache event listening, election, distributed lock, distributed counter, distributed Barrier, etc
- Cursor test: provides a ZooKeeper based unit test tool.
- The goal of the cursor project is to simplify the use of ZooKeeper clients.
- Common zookeeper Java APIs
- zookeeper
- ZkClient
- Curator
- Cursor was originally developed by Netfix and later donated to the Apache foundation. At present, it is a top-level project of Apache.
- Official website: http://curator.apache.org/
4.2 common operations of cursor API
4.2.1 establishing connections
1) Creating maven project: curator demo
2) Add dependency
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itcast</groupId>
<artifactId>curator-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.2.0</version>
</dependency>
<!-- zookeeper rely on -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
Note: if zookeeper 3.0 is installed 5 above. You must use curator4 Version above 0
3) Writing test classes
package cn.itcast;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.junit.Test;
/**
* TODO
*
* @Author LK
* @Date 2021/3/30
*/
public class CuratorTest {
/**
* Test connection
* namespace The function of / itheima is to specify the root directory as / itheima, mainly to simplify the path writing method. The subsequent operation nodes operate under the root directory of / itheima;
*/
@Test
public void testConnection(){
// 1. Create a retry policy object and specify the retry policy. Parameter 1 - retry interval (unit: ms), parameter 2 - retry times
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 2);
// 2. Create a connection client object
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("192.168.211.130:2181")
.retryPolicy(retryPolicy)
.namespace("itheima")
.build();
// 3. Start and establish connection
client.start();
}
}
4.2.2 adding nodes
- Basic creation
- Create node with data (persistent by default)
- Set node type: temporary node
- Create multi-level node
package cn.itcast;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
* TODO
*
* @Author LK
* @Date 2021/3/30
*/
public class CuratorTest {
private CuratorFramework client;
/**
* Test connection
*/
@Before
public void testConnection(){
// 1. Create a retry policy object and specify the retry policy. Parameter 1 - retry interval (unit: ms), parameter 2 - retry times
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 2);
// 2. Create a connection client object
client = CuratorFrameworkFactory.builder()
.connectString("192.168.211.130:2181")
.retryPolicy(retryPolicy)
.namespace("itheima") // Specify the root directory as itheima
.build();
// 3. Start and establish connection
client.start();
}
/**
* Basic creation
*/
@Test
public void testCreate1() throws Exception{
// No data is set when creating a node. The ip address of the server where the client is located is taken as the data by default.
String path = client.create().forPath("/app1");
System.out.println(path);
}
/**
* Create node with data
*/
@Test
public void testCreate2() throws Exception{
String path = client.create().forPath("/app2", "hehe".getBytes());
System.out.println(path);
}
/**
* Create a node and specify the node type
*/
@Test
public void testCreate3() throws Exception{
// PERSISTENT persistent node
// PERSISTENT_SEQUENTIAL persistent sequential node
// EPHEMERAL temporary node
// EPHEMERAL_SEQUENTIAL temporary data node
String path = client.create().withMode(CreateMode.EPHEMERAL).forPath("/app3");
System.out.println(path);
}
/**
* Create multi-level node
*/
@Test
public void testCreate4() throws Exception{
// creatingParentsIfNeeded if the parent node does not exist, create the parent node
String path = client.create().creatingParentsIfNeeded().forPath("/app4/app4-1");
System.out.println(path);
}
@After
public void close() {
if (client != null) {
client.close();
}
}
}
4.2.3 query node
-
Query node data: get /itheima/app2
-
Query directory node: ls /itheima/app4
-
Query node status information: ls -s
/**
* Query node data
*/
@Test
public void testGet1() throws Exception{
// Equivalent to get /itheima/app2
byte[] bytes = client.getData().forPath("/app2");
System.out.println("result = " + bytes.toString());
}
/**
* query directory
*/
@Test
public void testGet2() throws Exception{
// Equivalent to ls /itheima/app4, the returned result is the names of all child nodes
List<String> children = client.getChildren().forPath("/app4");
for (String child : children) {
System.out.println(child);
}
}
/**
* Query node details
*/
@Test
public void testGet3() throws Exception{
Stat status = new Stat();
// Put the result data of ls -s /app1 into status
client.getData().storingStatIn(status).forPath("/app1");
// Print node creation time
System.out.println(status.getCtime());
// Number of printing sub nodes
System.out.println(status.getNumChildren());
}
4.2.4 modify node
/**
* Set data: set /app1 goodboy
*/
@Test
public void testSetData() throws Exception{
client.setData().forPath("/app1", "goodBoy".getBytes());
}
/**
* Set data according to version
*/
@Test
public void testSetData2() throws Exception{
Stat status = new Stat();
// Put the result data of ls -s /app1 into status
client.getData().storingStatIn(status).forPath("/app1");
// Get the current version number of the data
int version = status.getVersion();
client.setData().withVersion(version).forPath("/app1", "goodBoy".getBytes());
}
4.2.5 deleting nodes
/**
* Delete node delete all
* 1,Delete a single node
* 2,Delete a node and its children
*/
@Test
public void testDelete() throws Exception {
client.delete().forPath("/app1");
}
@Test
public void testDeleteAll() throws Exception {
client.delete().deletingChildrenIfNeeded().forPath("/app2");
}
05. Cursor event listening
5.1 general
-
ZooKeeper allows the client to register some watchers on the specified node, and when some specific events are triggered, the ZooKeeper server will notify the interested clients of the events. This mechanism is an important feature of ZooKeeper's implementation of distributed coordination services.
-
The Watcher mechanism is introduced into ZooKeeper to realize the publish / subscribe function, which enables multiple subscribers to listen to an object at the same time. When the state of an object changes, it will notify all subscribers.
-
ZooKeeper native supports event monitoring by registering Watcher, but it is not particularly convenient to use. Developers need to register Watcher repeatedly, which is cumbersome.
-
Cursor introduces Cache to monitor ZooKeeper server events.
-
ZooKeeper offers three watchers:
- NodeCache: only listens to a specific node
- PathChildrenCache: monitors the child nodes of a ZNode
- TreeCache: it can monitor all nodes in the whole tree, similar to the combination of PathChildrenCache and NodeCache
5.2 NodeCache
NodeCache: register an event listener for a node (add, delete and modify this node)
/**
* Monitor a node
*/
@Test
public void NodeCache() throws Exception{
// 1. Create listener object
final NodeCache nodeCache = new NodeCache(client, "/app1");
// 2. Bind listener
nodeCache.getListenable().addListener(new NodeCacheListener() {
// When the / app1 node changes, nodeChanged is called back
public void nodeChanged() throws Exception {
System.out.println("The node has changed...");
// Get changed data
ChildData currentData = nodeCache.getCurrentData();
byte[] data = currentData.getData();
// print data
System.out.println(new String(data));
}
});
// 3. Enable listening. If the parameter is true, when listening is enabled, if it is set to true, NodeCache will immediately read on the Zookeeper when it is started for the first time // Get the data content of the corresponding node and save it in the Cache.
nodeCache.start(true);
// Don't let the thread end
while(true){
}
}
5.3 PathChildrenCache
PathChildrenCache: monitors the changes of child nodes of a node (child nodes are added, deleted and modified)
/**
* PathChildrenCache: Monitor the changes of child nodes of a node
*/
@Test
public void pathChildrenCache() throws Exception {
// 1. Create listener object, parameter 3 - load cached data
PathChildrenCache pathChildrenCache = new PathChildrenCache(client, "/app2", true);
// 2. Bind listener
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event)
throws Exception {
// event={type=CHILD_ADDED, data=ChildData{path='/app2/p2', stat=..,data=null}}
// event={type=CHILD_UPDATED, data=ChildData{path='/app2/p2', stat=..,data=null}}
// event={type=CHILD_REMOVED, data=ChildData{path='/app2/p2', stat=..,data=null}}
System.out.println("The child nodes have changed," + event);
// Get type
PathChildrenCacheEvent.Type type = event.getType();
if (type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)){
byte[] data = event.getData().getData();
System.out.println("Get changed data:" + new String(data));
}
}
});
// 3. Enable monitoring
pathChildrenCache.start();
while (true){
}
}
5.4 TreeCache
TreeCache: it can monitor all nodes in the whole tree, which is equivalent to the combination of NodeCache+PathChildrenCache
/**
* TreeCache : It can monitor all nodes in the whole tree, which is equivalent to the combination of NodeCache+PathChildrenCache
*/
@Test
public void treeCache() throws Exception {
// 1. Create listener object
TreeCache treeCache = new TreeCache(client, "/app3");
// 2. Bind listener
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
System.out.println("The child nodes have changed," + event);
// Get type
TreeCacheEvent.Type type = event.getType();
// Listen to the event of modifying the node and get the modified value (no matter whether you or your son changes)
if (type.equals(TreeCacheEvent.Type.NODE_UPDATED)){
byte[] data = event.getData().getData();
System.out.println("Get changed data:" + new String(data));
}
}
});
// 3. Enable monitoring
treeCache.start();
while (true){
}
}
06. Zookeeper distributed lock
6.1 concept
-
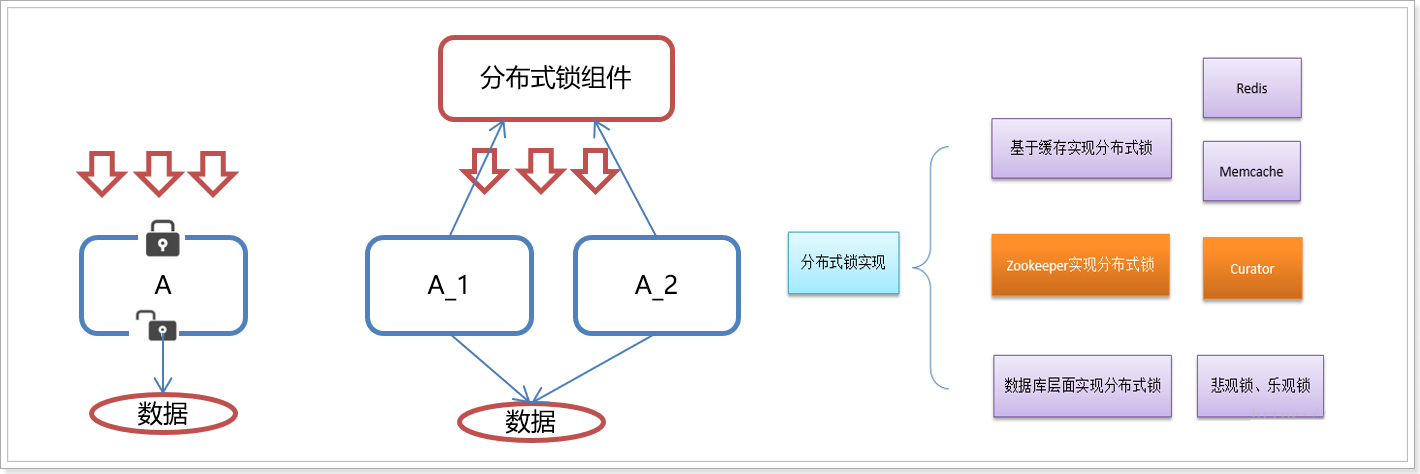
When we develop stand-alone applications and involve concurrent synchronization, we often use synchronized or Lock to solve the problem of code synchronization between multiple threads. At this time, multiple threads run under the same JVM without any problem.
-
However, when our application works in a distributed cluster, it belongs to the working environment of multiple JVMs, and the synchronization problem can not be solved through multi-threaded locks between different JVMs.
-
Then a more advanced locking mechanism is needed to deal with the problem of data synchronization between processes across machines - this is distributed locking.
-
As shown in the figure:
6.2 principle
Core idea: when the client wants to obtain a lock, it creates a node. After using the lock, it deletes the node.
- When the client is ready to acquire the lock, a temporary sequence node is created under the lock node.
- Then obtain all child nodes under the lock. If you find that the number of the child node you created is the smallest, it is considered that the client has obtained the lock. After using the lock, delete the node.
- If you find that the node you created is not the smallest of all the child nodes of lock, it means that you have not obtained the lock. At this time, the client needs to find the node smaller than itself, register an event listener for it, and listen for deletion events.
- If it is found that the node smaller than itself is deleted, the Watcher of the client will receive the corresponding notification. At this time, judge again whether the node you created is the one with the lowest sequence number among the lock child nodes. If so, you will obtain the lock. If not, repeat the above steps to continue to obtain a node smaller than yourself and register to listen.
As shown in the figure:
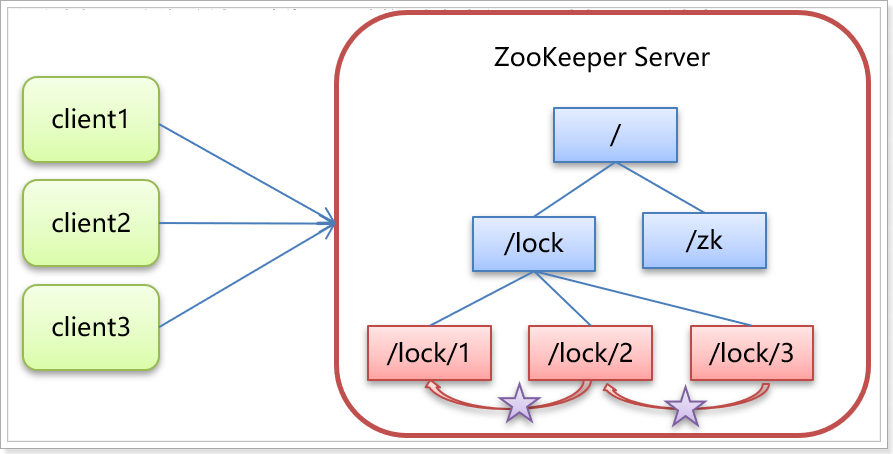
6.3 simulated 12306 ticket selling case
There are five locking schemes in cursor:
- InterProcessSemaphoreMutex: distributed exclusive lock (non reentrant lock)
- InterProcessMutex: distributed reentrant exclusive lock
- InterProcessReadWriteLock: distributed read / write lock (read sharing, read / write mutual exclusion, write / write mutual exclusion)
- InterProcessMultiLock: locks multiple objects
- InterProcessSemaphoreV2: shared semaphore
6.3.1 demonstration oversold
Step 1: simulate ticket sales
package cn.itcast;
// In a real project, it is a controller
public class Ticket12306 {
private int ticket = 10; // The number of votes in the database. The actual project exists in the database
/**
* Ticket selling interface
*/
public void sellTicket() {
if (ticket > 0) {
// Print the name of the current thread and the number of votes
System.out.println(Thread.currentThread().getName() + ":" + ticket);
ticket--;
}
}
}
Step 2: simulate ticket grabbing
package cn.itcast;
public class LockMain {
public static void main(String[] args) {
final Ticket12306 ticket = new Ticket12306();
// Simulate 20 threads to grab tickets at the same time
for (int i = 0; i < 20; i++) {
Thread t = new Thread(new Runnable() {
public void run() {
// Buy a ticket
ticket.sellTicket();
}
}, "thread " + i);
t.start();
}
// An endless loop does not stop the main thread, otherwise all child threads will stop
while (true) {
}
}
}
Step 3: run LockMain to grab tickets and check the log. Oversold occurs
Thread 0:10 Thread 1:10 Thread 2:8 Thread 4:7 Thread 5:6 Thread 7:6 Thread 3:6 Thread 8:4 Thread 6:5 Thread 9:2 Thread 10:1
6.3.2 distributed lock
package cn.itcast;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
import java.util.concurrent.TimeUnit;
public class Ticket12306 {
private int ticket = 10; // Number of votes in the database
private CuratorFramework client;
private InterProcessMutex lock;
// Initializes the client object and creates a connection in the constructor
public Ticket12306() {
// 1. Create a retry policy object and specify the retry policy. Parameter 1 - retry interval (unit: ms), parameter 2 - retry times
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 2);
// 2. Create a connection client object
client = CuratorFrameworkFactory.builder()
.connectString("192.168.211.130:2181")
.retryPolicy(retryPolicy)
.build();
// 3. Start and establish connection
client.start();
// 4. Create lock object
lock = new InterProcessMutex(client, "/lock");
}
public void sellTicket(){
try {
// Try to obtain the lock. If you can't get it for 10s, give up. If you get the lock, execute the following code. If you don't get it, block it in this place, register to listen and listen for deletion events
lock.acquire(10, TimeUnit.SECONDS);
if (ticket > 0) {
System.out.println(Thread.currentThread().getName() + ":" + ticket);
ticket--;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if(lock!=null) {
// Release lock
lock.release();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
Operation results:
Thread 5:10 Thread 6:9 Thread 12:8 Thread 0:7 Thread 9:6 Thread 14:5 Thread 19:4 Thread 8:3 Thread 7:2 Thread 10:1
07. ZooKeeper cluster
7.1 cluster introduction
1) Election
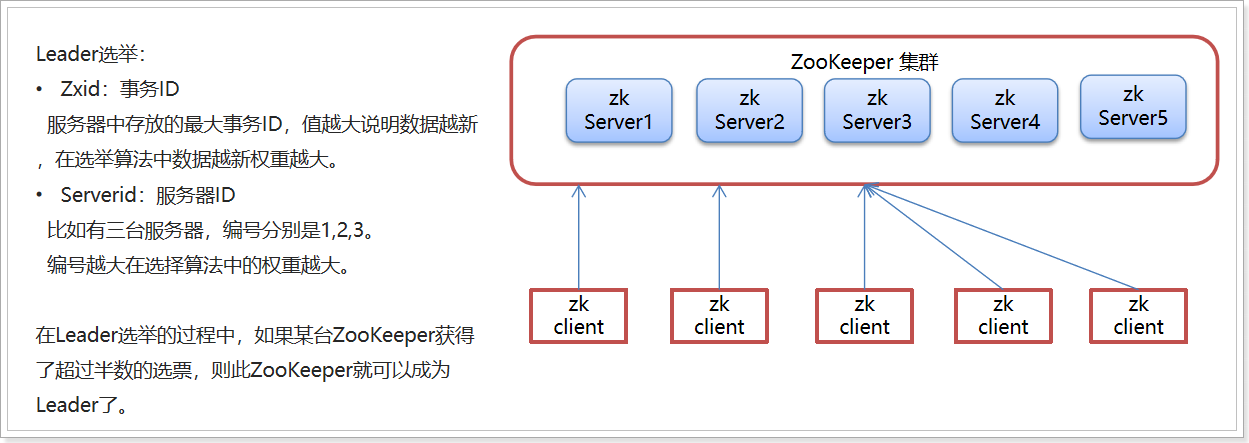
2) Role introduction
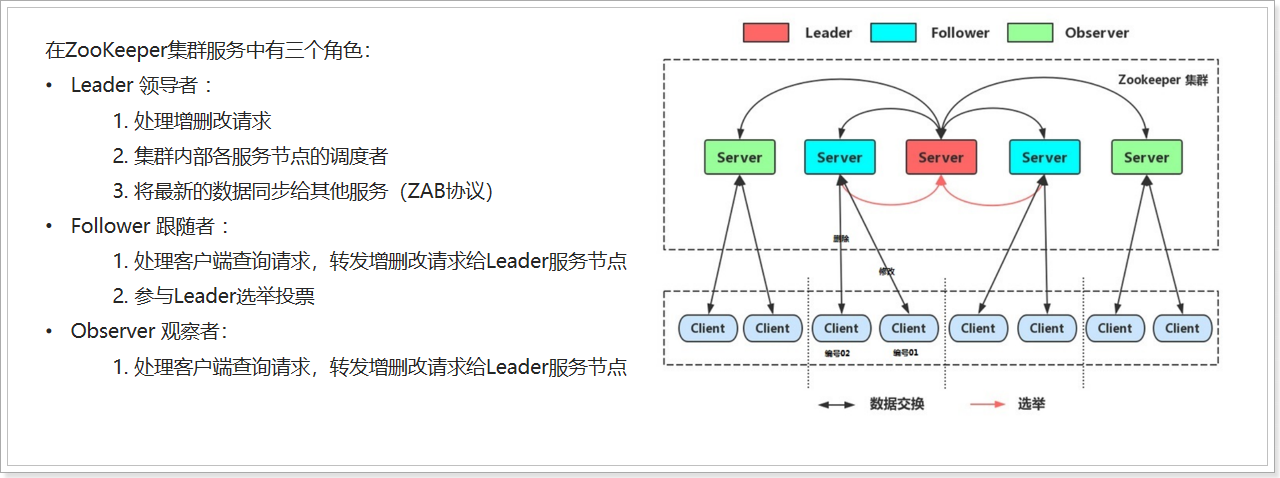
7.2 cluster construction (understand)
1) Copy three folders: zookeeper-1, zookeeper-2 and zookeeper-3
# Enter folder cd /usr/local # Create folder ZK cluster mkdir zk-cluster # Delete old data to avoid affecting cd apache-zookeeper-3.6.2-bin rm -rf data # Go back to the usr/local directory cd /usr/local # Copy three folders: zookeeper-1, zookeeper-2 and zookeeper-3 cp -r apache-zookeeper-3.6.2-bin zk-cluster/zookeeper-1 cp -r apache-zookeeper-3.6.2-bin zk-cluster/zookeeper-2 cp -r apache-zookeeper-3.6.2-bin zk-cluster/zookeeper-3
2) Modify the zoo in each folder CFG configuration file
zookeeper-1 configuration:
vi /usr/local/zk-cluster/zookeeper-1/conf/zoo.cfg
# Set data directory dataDir=/usr/local/zk-cluster/zookeeper-1/data # Set the port (for the same server, the port cannot conflict. In the actual project, it is best to deploy on multiple servers) clientPort=2181
zookeeper-2 configuration:
vi /usr/local/zk-cluster/zookeeper-2/conf/zoo.cfg
# Set data directory dataDir=/usr/local/zk-cluster/zookeeper-2/data # Set the port (for the same server, the port cannot conflict. In the actual project, it is best to deploy on multiple servers) clientPort=2182
zookeeper-3 configuration:
vi /usr/local/zk-cluster/zookeeper-3/conf/zoo.cfg
# Set data directory dataDir=/usr/local/zk-cluster/zookeeper-3/data # Set the port (for the same server, the port cannot conflict. In the actual project, it is best to deploy on multiple servers) clientPort=2183
3) In each service node, create a data directory and a myid file, which records its serverId
# Write a content to the corresponding file. If the file does not exist, it will be created automatically echo 1 > /usr/local/zk-cluster/zookeeper-1/data/myid echo 2 > /usr/local/zk-cluster/zookeeper-2/data/myid echo 3 > /usr/local/zk-cluster/zookeeper-3/data/myid
4) In the zoo of each service node In the cfg file, configure the address information list of all service nodes
vi /usr/local/zk-cluster/zookeeper-1/conf/zoo.cfg vi /usr/local/zk-cluster/zookeeper-2/conf/zoo.cfg vi /usr/local/zk-cluster/zookeeper-3/conf/zoo.cfg
The following contents are added to each configuration file:
server.1=192.168.211.130:2881:3881 server.2=192.168.211.130:2882:3882 server.3=192.168.211.130:2883:3883
5) Start each node separately
# Stop the 2181 service of the previous stand-alone before starting to avoid port conflict /usr/local/apache-zookeeper-3.6.2-bin/bin/zkServer.sh stop
/usr/local/zk-cluster/zookeeper-1/bin/zkServer.sh start /usr/local/zk-cluster/zookeeper-2/bin/zkServer.sh start /usr/local/zk-cluster/zookeeper-3/bin/zkServer.sh start
6) View status
/usr/local/zk-cluster/zookeeper-1/bin/zkServer.sh status

/usr/local/zk-cluster/zookeeper-2/bin/zkServer.sh status

/usr/local/zk-cluster/zookeeper-3/bin/zkServer.sh status
