Why do I need distributed locks
In the concurrent scenario, it is necessary to use locks to mutually exclusive access to shared resources to ensure thread safety; Similarly, in the distributed scenario, a mechanism is also needed to ensure mutually exclusive access to multi node shared resources. The implementation mechanism is distributed lock. (to put it bluntly, it is to solve the thread safety problem in distributed)
Several points of distributed lock
1. Mutually exclusive; Only one client can acquire a lock at any time
2. Release the dead; Even if the service that locks the resource crashes or partitions, the lock can still be released
3. Fault tolerance; As long as most nodes (more than half) are in use, client s can acquire and release locks
4. Ensure that the client can only unlock the lock it holds.
Implementation and classification of common distributed locks
Implementation of exclusive lock based on Database
Database based implementation is an easy solution to think of. The reason is that for applications, relational database tables are globally unique and suitable for distributed locking.
First edition representation 1
Create a table in the database, which contains fields such as method name, and create a unique index on the method name field. If you want to execute a method, you can use this method name to insert data into the table. If the insertion is successful, you can obtain the lock. After execution, delete the corresponding row data and release the lock.
Table structure
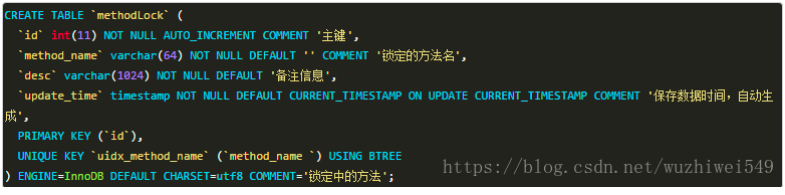
SQL version
#Create Lock Table DROP TABLE IF EXISTS `method_lock`; CREATE TABLE `method_lock` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `method_name` varchar(64) NOT NULL COMMENT 'Locked method name', `desc` varchar(255) NOT NULL COMMENT 'Remark information', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='Methods in locking';
Insert data. This place is locked. For method_name makes a uniqueness constraint. If multiple requests are submitted to the database at the same time, the database will ensure that only one operation can succeed.
NSERT INTO method_lock (method_name, desc) VALUES ('methodName', 'Tested methodName');If the insertion is successful, the lock will be obtained. After the execution is completed, the corresponding row data will be deleted to release the lock:
delete from method_lock where method_name ='methodName';
Existing problems:
1. Because it is implemented based on the database, the availability and performance of the database will directly affect the availability and performance of the distributed lock. Therefore, the database needs dual computer deployment, data synchronization and active / standby switching;
2. It does not have the reentrant feature, because the row data always exists before the same thread releases the lock, and the data cannot be successfully inserted again. Therefore, a new column needs to be added in the table to record the information of the machine and thread currently obtaining the lock. When obtaining the lock again, first query whether the information of the machine and thread in the table is the same as that of the current machine and thread, If it is the same, obtain the lock directly;
3. There is no lock invalidation mechanism, because it is possible that after successfully inserting data, the server goes down, the corresponding data is not deleted, and the lock cannot be obtained after the service is restored. Therefore, a new column needs to be added in the table to record the invalidation time, and there needs to be a regular task to clear these invalid data;
4. It does not have the blocking lock feature, and the failure is directly returned if the lock is not obtained. Therefore, it is necessary to optimize the acquisition logic and cycle for multiple times.
The first version shows form 2
Friendly note: this table is no different from the above table. There is one main field, resource_id corresponds to the above method_name indexes this field
create table `lock_table` (
`id` int(11) unsigned NOT NULL auto_increment comment 'Primary key',
`resource_id` varchar(128) NOT NULL comment 'Identify resources',
`desc` varchar(128) default NULL comment 'describe',
`ctime` bigint(20) NOT NULL COMMENT 'Creation time',
`utime` bigint(20) NOT NULL COMMENT 'Update time',
PRIMARY KEY (`id`),
UNIQUE KEY `unq_resource` (`resource_id`)
) engine=InnoDB default charset=utf8mb4tryLock implementation (locking)
insert into lock_table (resource_id, desc) values ('resource_name1', 'desc1')unlock implementation (release lock)
delete from lock_table where resource_id = 'resource_name1'
The above is a simple implementation of distributed lock, which can meet the requirements of mutual exclusion, but there are obviously some problems:
- Not reentrant.
- There is no lock invalidation mechanism, which may lead to deadlock. If the timeout is set, how much is appropriate.
- No blocking waiting feature;
If there are no three requirements for lock reentry, timeout and blocking acquisition, it can still be used.
Version improvement
Block acquisition lock
You can't stop until you get the lock. Generally, you write an endless loop to perform its operation
The following is the lock interface in implementation JUC. There are two methods: one is dedicated to locking resources, and the other is dedicated to looping to judge whether the locking resources are successful, which forms a blocking to obtain locks
@Override
public void lock() {
while (!lockResource(this.resource)) {
LockSupport.parkNanos(WAIT_TIME);
}
}
private boolean lockResource(String resource) {
// implement lock
// insert int lock_table (resource_id) values ('ressource');
return false;
}Reentrant implementation
The core is Clientid, which is the client identification. It can be composed of ip + thread id , and so on. Add 1.0 for each entry Of course, when unlocking, it is to continuously reduce 1, which is somewhat similar to the most primitive garbage collection algorithm of jvm
@Transcation
private boolean lockResource(String resource) {
if (lockTable.countByResource(resource) == 0) {
return lockTable.insert(resource);
}
if (Objects.equals(lockTable.getClientId(resource), this.clientId)) {
return lockTable.increment(resource);
}
return false;
}Complete code implementation
public class MySqlDistributedLock implements Lock {
private static final long WAIT_TIME = 1000 * 1000 * 3;
private LockTable lockTable;
/**
* Identify resources to be locked
*/
private String resource;
/**
* It is used to identify the client. It can be ip + thread id and other methods to realize the reentrant feature
*/
private String clientId;
public MySqlDistributedLock(LockTable lockTable, String resource) {
this.lockTable = lockTable;
this.resource = resource;
}
@Override
@Transcation
public void lock() {
while (!lockResource(this.resource))
LockSupport.parkNanos(WAIT_TIME);
}
@Override
@Transcation
public boolean tryLock() {
return lockResource(this.resource);
}
@Override
public boolean tryLock(long expires) {
long endTime = System.currentTimeMillis() + expires;
while (!lockResource(this.resource)) {
if (System.currentTimeMillis() > endTime) {
return false;
}
}
return true;
}
@Override
@Transcation
public boolean unLock() {
int count = lockTable.countForUpdate(this.resource);
if (count == 0) return false;
if (Objects.equals(lockTable.getClientId(resource), this.clientId)) {
if (count > 1) return lockTable.decrement(this.resource);
else return lockTable.delete(this.resource);
}
return false;
}
private boolean lockResource(String resource) {
if (lockTable.countForUpdate(resource) == 0) {
return lockTable.insert(resource);
}
if (Objects.equals(lockTable.getClientId(resource), this.clientId)) {
return lockTable.increment(resource);
}
return false;
}
}In addition, a background scheduled task is needed to continuously scan the overtime task. The main purpose is to solve the permanent possession of the lock, so that the permanently occupied lock can be released
Second Edition
It adopts the form of optimistic lock
DROP TABLE IF EXISTS `method_lock`; CREATE TABLE `method_lock` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `method_name` varchar(64) NOT NULL COMMENT 'Locked method name', `state` tinyint NOT NULL COMMENT '1:Not allocated; 2: Assigned', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `version` int NOT NULL COMMENT 'Version number', `PRIMARY KEY (`id`), UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='Methods in locking';
Get lock information first
select id, method_name, state,version from method_lock where state=1 and method_name='methodName';
Possession lock (if no update affects a row of data, it indicates that the resource has been occupied by others.)
update t_resoure set state=2, version=2, update_time=now() where method_name='methodName' and state=1 and version=2;
Disadvantages:
1. This lock strongly depends on the availability of the database. The database is a single point. Once the database hangs, the business system will be unavailable.
2. This lock has no expiration time. Once the unlocking operation fails, the lock record will always be in the database, and other threads can no longer obtain the lock.
3. This lock can only be non blocking, because once the insert operation of data fails, an error will be reported directly. Threads that do not obtain locks do not enter the queue. To obtain locks again, you need to trigger the obtain locks operation again.
4. The lock is non reentrant. The same thread cannot obtain the lock again before releasing the lock. Because the data already exists in the data.
Solution:
1. Is the database a single point? Two databases, two-way synchronization before data. Once hung up, quickly switch to the standby database.
2. No failure time? Just do a scheduled task and clean up the timeout data in the database at regular intervals.
3. Non blocking? Make a while loop until the insert succeeds and then returns success.
4. Non reentrant? Add a field in the database table to record the host information and thread information of the machine currently obtaining the lock. The next time you obtain the lock, query the database first. If the host information and thread information of the current machine can be found in the database, you can directly assign the lock to him.
Friendly note: the above 3 and 4 versions have been introduced in an improvement
redis based implementation
SET resource_name my_random_value NX PX 30000
Basic theory
redis realizes the distributed lock through the setnx instruction. This command can be set successfully when key does not exist. If it exists, the call fails. After using it, the del instruction is called to release the lock. Use the expire instruction in combination to set the timeout, such as 5s, as shown below.
Friendly tips: locl:a is the key and true is the value
127.0.0.1:6379> setnx lock:a true (integer) 1 127.0.0.1:6379> setnx lock:a true (integer) 0 127.0.0.1:6379> del lock:a (integer) 1 127.0.0.1:6379> setnx lock:a true (integer) 1 127.0.0.1:6379> expire lock:a 5 (integer) 1 127.0.0.1:6379> setnx lock:a true (integer) 0 127.0.0.1:6379> setnx lock:a true (integer) 1
The setnux instruction can be set successfully only when the key does not exist. 5s then, setnx can succeed again
There is a problem here: the setnx and expire instructions are not atomic, so setnx may be executed successfully. When preparing to execute expire, the server process suddenly hangs, resulting in the failure or failure of expire, which may lead to the lock being occupied all the time. In order to solve this problem and ensure the atomicity of setnx and expire, we need to find a way to bind setnx and expire together. This can be done through the following instruction.
127.0.0.1:6379> set lock:a true ex 5 nx OK 127.0.0.1:6379> setnx lock:a true (integer) 0 127.0.0.1:6379> setnx lock:a true (integer) 1
In order to prevent the lock from being released by other threads, it is better to release the lock with a token. However, Redis does not provide an instruction to delete the lock according to the token. In order to delete the lock with conditions, we need to implement it ourselves. The following is to ensure the atomicity of conditional deletion through Lua script.
# delifequals
if redis.call("get", KEY[1]) == ARGV[1] then
return redis.call("del", KEY[1])
else
return 0
endThe reentrant attribute of the lock is optional. Let's try to implement a reentrant lock based on ThreadLocal + Redis.
public class RedisReentrantLock {
private ThreadLocal<Map<String, Integer>> lockers = new ThreadLocal<>();
private Jedis jedis;
public RedisReentrantLock(Jedis jedis) {
this.jedis = jedis;
}
public boolean lock(String key, int expires) {
Map<String, Integer> lockCountMap = getLockCountMap();
Integer count = lockCountMap.get(key);
if (count != null) {
lockCountMap.put(key, count + 1);
return true;
}
String res = jedis.set(key, "", SetParams.setParams().nx().ex(expires));
if (res == null) return false;
lockCountMap.put(key, 1);
return true;
}
public boolean unLock(String key) {
Map<String, Integer> lockCountMap = getLockCountMap();
Integer count = lockCountMap.get(key);
if (count == null) return false;
count--;
if (count > 0) lockCountMap.put(key, count);
else {
lockCountMap.remove(key);
jedis.del(key);
}
return true;
}
private Map<String, Integer> getLockCountMap() {
Map<String, Integer> lockCountMap = lockers.get();
if (lockCountMap != null) return lockCountMap;
lockers.set(new HashMap<>());
return lockers.get();
}
}The test code is as follows
public static void main(String[] args) {
RedisReentrantLock lock = new RedisReentrantLock(new Jedis("127.0.0.1", 6379));
final String LOCK_KEY = "lock_a";
Thread thread1 = new Thread(()->{
try {
while (!lock.lock(LOCK_KEY, 5)) {
System.out.println("thread1:wait lock");
Thread.sleep(500);
}
System.out.println("thread1:get lock");
Thread.sleep(200);
lock.unLock(LOCK_KEY);
System.out.println("thread1:release lock");
} catch (InterruptedException e) {
}
});
Thread thread2 = new Thread(()->{
try {
while (!lock.lock(LOCK_KEY, 5)) {
System.out.println("thread2:wait lock");
Thread.sleep(500);
}
System.out.println("thread2:get lock");
Thread.sleep(200);
lock.unLock(LOCK_KEY);
System.out.println("thread2:release lock");
} catch (InterruptedException e) {
}
});
thread1.start();
thread2.start();
while (Thread.activeCount() > 0)
Thread.yield();
}Output:
thread2:get lock thread1:wait lock thread2:release lock thread1:get lock thread1:release lock
Existing problems
- Releasing the lock in advance after timeout leads to the loss of mutex: the task of obtaining the lock takes too long to execute and exceeds the time specified by expires. At this time, redis will automatically release the lock, and other nodes may obtain the lock. Finally, it violates the mutex attribute.
- The inconsistency between the active and standby locks leads to the loss of mutual exclusivity: in the redis active and standby mode, after client a obtains the lock from the primary, but before copying the primary to the slave node, the primary hangs, and the standby is promoted to the primary. At this time, the lock does not exist, and client b may obtain the lock
Improved scheme - Redlock algorithm (this part is not very clear)
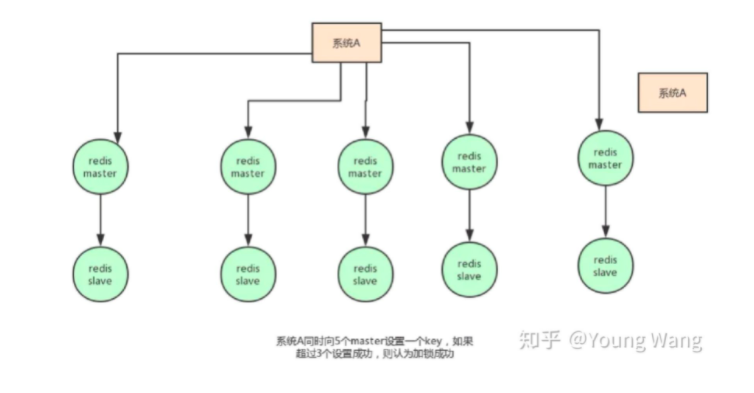
RedLock algorithm description
- Deploy 5 Redis instances.
- The client obtains the current timestamp in milliseconds.
- The client uses the same key and value to try to establish locks on N instances in turn. The timeout time should be short. If one instance cannot be obtained, try the next instance immediately.
- The client calculates the time elapsed to acquire the lock. Only when the lock is acquired on most instances and the time taken to acquire the lock is less than the effective time of the lock, it is considered to have succeeded in acquiring the lock.
- If a lock is acquired, the actual effective time of the lock = initial effective time – time elapsed
- If the client does not acquire the lock on most nodes, or the actual effective time of the lock is negative, the lock release operation is performed on all instances
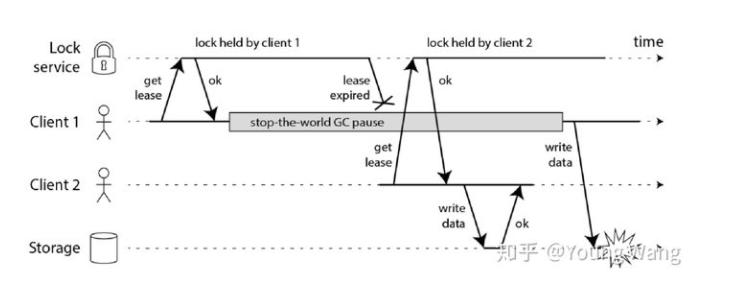
Redlock problem
- If it is only for efficiency, there is no need to set up five Redis instances at all
- The relock itself is not secure enough (lease expired, lock failure leads to data write conflict)
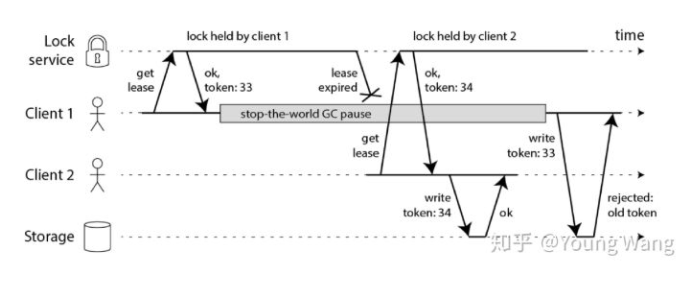
Optimization scheme 1 – introducing fencing token
- The Lock service needs to provide a self incremented token
- The Storage server checks the toke n on every write
Optimization scheme 2 – Redisson
In fact, Redis based distributed locks have a widely used open source project redison. If you are interested, you can pay attention to: https://github.com/redisson/redisson
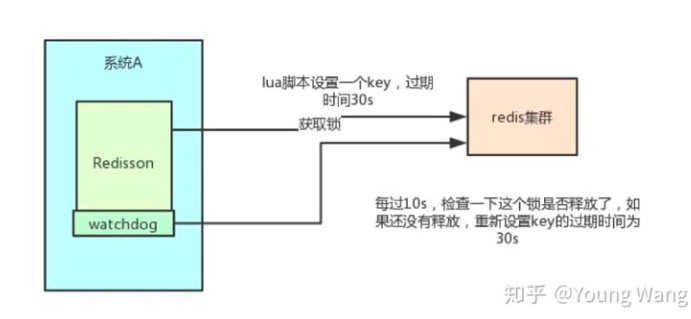
Redisson solves the problem of lock timeout by continuously renewing the lease. Redisson has a concept of Watchdog, which helps you set the timeout of Key to 30s every 10s after you obtain the lock. In this way, even if the lock is held all the time, there will be no problem that the Key expires and other threads acquire the lock (the lease will be renewed continuously, and the lease will not expire if the task is not completed).
Redisson's "watchdog" logic ensures that no deadlock occurs. (if the machine goes down, the watchdog will disappear. At this time, the expiration time of the Key will not be extended. It will expire automatically after 30s, and other threads can obtain the lock.)
Supplementary knowledge 1: (this is used by SpringBoot)
try{
lock = redisTemplate.opsForValue().setIfAbsent(lockKey, LOCK);
logger.info("cancelCouponCode Lock acquired:"+lock);
if (lock) {
// TODO
redisTemplate.expire(lockKey,1, TimeUnit.MINUTES); //Expiration time set successfully
return res;
}else {
logger.info("cancelCouponCode The lock is not obtained and the task is not executed!");
}
}finally{
if(lock){
redisTemplate.delete(lockKey);
logger.info("cancelCouponCode When the task is over, release the lock!");
}else{
logger.info("cancelCouponCode No lock was acquired, no need to release the lock!");
}
}Disadvantages:
There is obvious competition in this scenario (master-slave structure):
Client A obtains the lock from the master,
Before the master synchronizes the lock to the slave, the Master goes down.
slave node is promoted to master node,
Client B obtains another lock of the same resource that client A has obtained. Safety failure!
Supplementary knowledge 2 (a bit of redistribution):
Introducing redis dependency:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>redis distributed lock tool class:
public class RedisLock implements AutoCloseable {
private RedisTemplate redisTemplate;
private String key;
private String value;
private int expireTime;
public RedisLock(RedisTemplate redisTemplate,String key,int expireTime){
this.redisTemplate = redisTemplate;
this.key = key;
this.expireTime=expireTime;
this.value = UUID.randomUUID().toString();
}
/**
* Get distributed lock
*/
public boolean getLock(){
RedisCallback<Boolean> redisCallback = connection -> {
//Set NX
RedisStringCommands.SetOption setOption = RedisStringCommands.SetOption.ifAbsent();
//Set expiration time
Expiration expiration = Expiration.seconds(expireTime);
//Serialize key
byte[] redisKey = redisTemplate.getKeySerializer().serialize(key);
//Serialize value
byte[] redisValue = redisTemplate.getValueSerializer().serialize(value);
//Perform setnx operation
Boolean result = connection.set(redisKey, redisValue, expiration, setOption);
return result;
};
//Get distributed lock
Boolean lock = (Boolean)redisTemplate.execute(redisCallback);
return lock;
}
/**
* Unlock
*/
public boolean unLock() {
String script = "if redis.call(\"get\",KEYS[1]) == ARGV[1] then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
RedisScript<Boolean> redisScript = RedisScript.of(script,Boolean.class);
List<String> keys = Arrays.asList(key);
Boolean result = (Boolean)redisTemplate.execute(redisScript, keys, value);
return result;
}
/**
* Auto off
*/
@Override
public void close(){
unLock();
}
}controller:
@RequestMapping("redisLock")
public String redisLock(){
try (RedisLock redisLock = new RedisLock(redisTemplate,"redisKey",30)){
if (redisLock.getLock()) {
//Delay simulation service code execution
Thread.sleep(15000);
}
}catch (Exception e) {
e.printStackTrace();
}
return "Method execution completed";
}Implementation of distributed lock based on Redisson
Redisson is an upgraded version of Redis client. It has realized the function of distributed lock and can be used directly.
Introduce Redisson dependency:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.11.2</version>
</dependency>controller:
@Autowired
private RedissonClient redisson;
@RequestMapping("redissonLock")
public String redissonLock() {
RLock rLock = redisson.getLock("order");
try {
rLock.lock(30, TimeUnit.SECONDS);
//Delay simulation service execution
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
rLock.unlock();
}
return "Method execution completed!!";
}Configure the redis port in the springboot configuration file:
spring.redis.host=127.0.0.1
Implementation based on zookeeper
Reference documents: https://zhuanlan.zhihu.com/p/162105779
Let's review the concept of Zookeeper node:
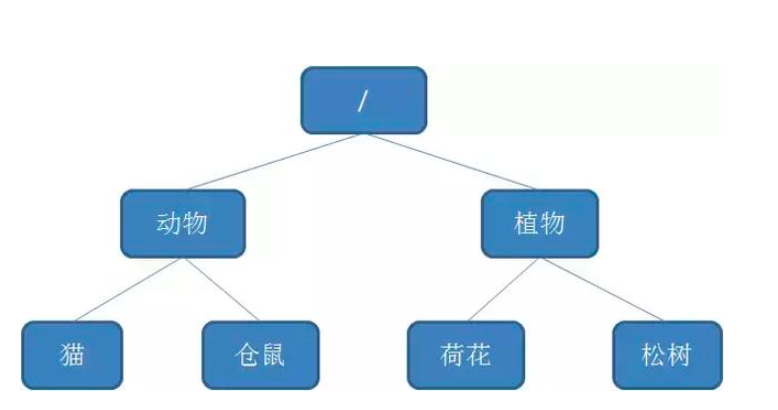
The data storage structure of Zookeeper is like a tree, which is composed of nodes called Znode.
There are four types of Znode:
1. PERSISTENT node
The default node type. After the client that created the node disconnects from zookeeper, the node still exists.
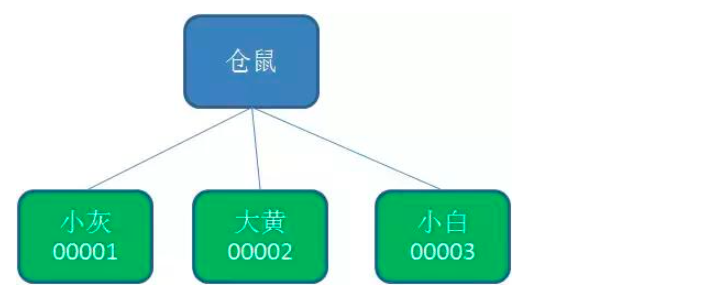
2. PERSISTENT_SEQUENTIAL node
The so-called sequential node means that when creating a node, Zookeeper numbers the name of the node according to the time sequence of creation:
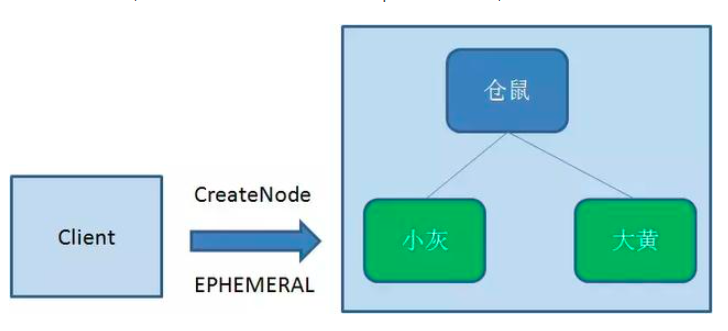
3. Temporary node (EPHEMERAL)
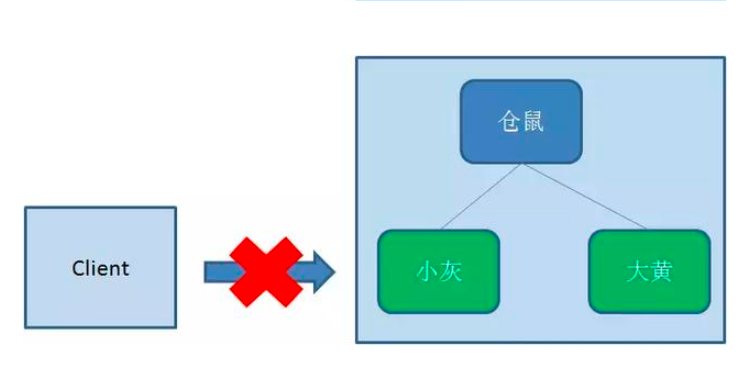
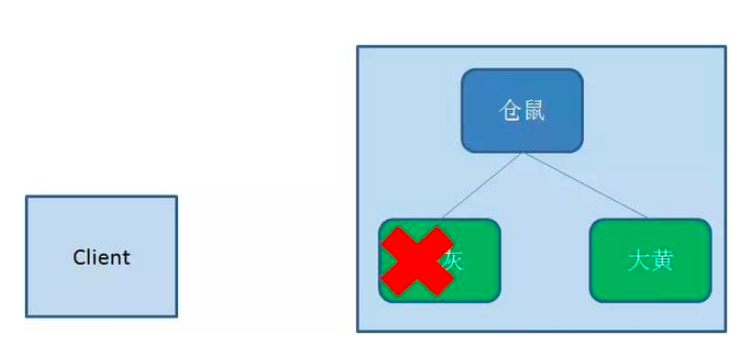
In contrast to persistent nodes, temporary nodes are deleted when the client creating the node disconnects from zookeeper:
4. Temporary sequential node (EPHEMERAL_SEQUENTIAL)
As the name suggests, temporary sequential node combines the characteristics of temporary node and sequential node: when creating a node, zookeeper numbers the name of the node according to the time sequence of creation; When the client that created the node disconnects from zookeeper, the temporary node is deleted.
Principle of Zookeeper distributed lock
Zookeeper distributed lock just applies temporary sequential nodes. How to achieve it? Let's look at the detailed steps:
Acquire lock
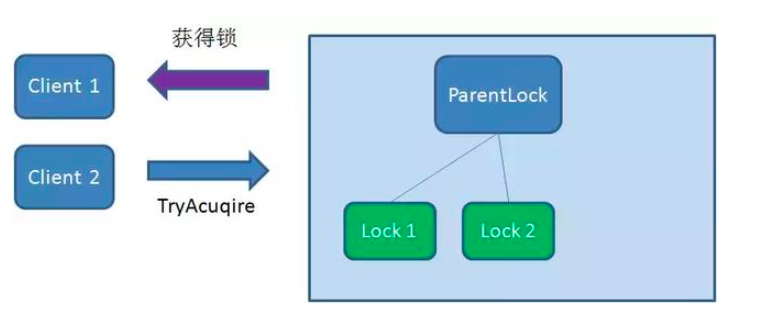
First, create a persistent node ParentLock in Zookeeper. When the first client wants to obtain a lock, it needs to create a temporary sequence node Lock1 under the ParentLock node.
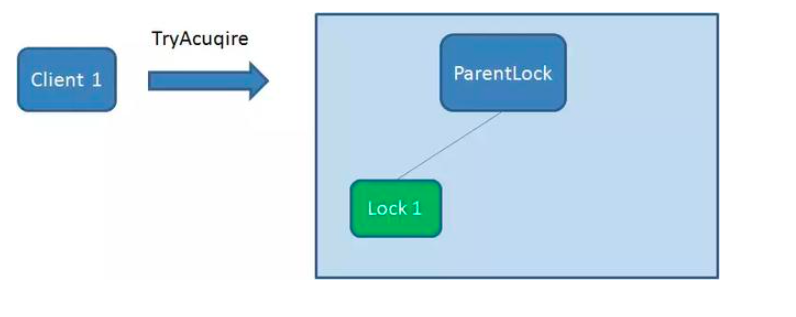
After that, Client1 finds all temporary order nodes under ParentLock and sorts them to determine whether the node Lock1 created by itself is the one with the highest order. If it is the first node, the lock is successfully obtained.
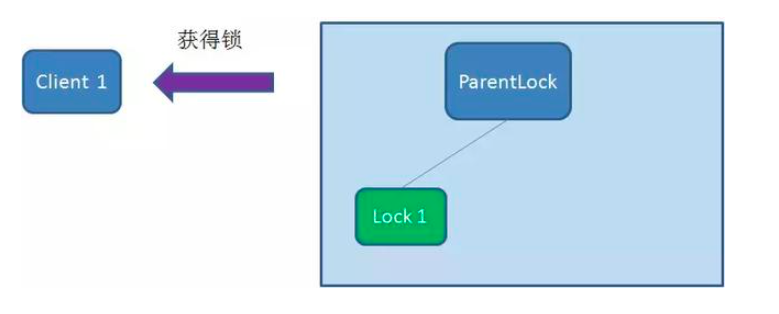
At this time, if another client Client2 comes to obtain the lock, create a temporary sequence node Lock2 in the ParentLock download.
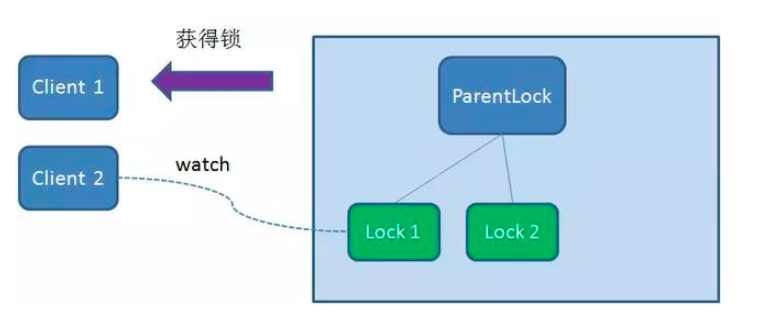
Client2 finds and sorts all temporary order nodes under ParentLock, and judges whether the node Lock2 created by itself is the one in the top order. It is found that node Lock2 is not the smallest.
Therefore, Client2 registers a Watcher with the node Lock1 whose ranking is only higher than it to monitor whether the Lock1 node exists. This means that Client2 failed to grab the lock and entered the waiting state.
At this time, if another client Client3 comes to obtain the lock, create a temporary sequence node Lock3 in the ParentLock download.
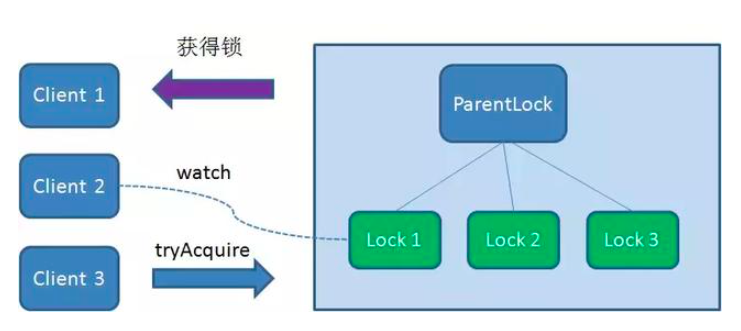
Client3 finds and sorts all temporary order nodes under ParentLock, and judges whether the node Lock3 created by itself is the one in the top order. As a result, it is also found that node Lock3 is not the smallest.
Therefore, Client3 registers a Watcher with the node Lock2 that is only ahead of it to listen for the existence of the Lock2 node. This means that Client3 also failed to grab the lock and entered the waiting state.
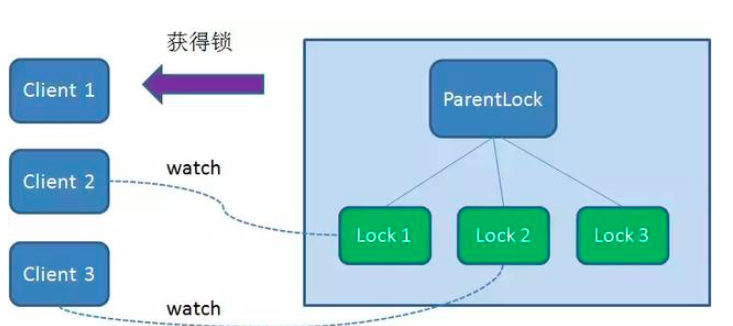
In this way, Client1 gets the lock, Client2 listens to Lock1, and Client3 listens to Lock2. This just forms a waiting queue, much like the one that ReentrantLock in Java relies on
Release lock
There are two situations to release the lock:
1. When the task is completed, the client displays release
When the task is completed, Client1 will display the instruction calling to delete node Lock1.
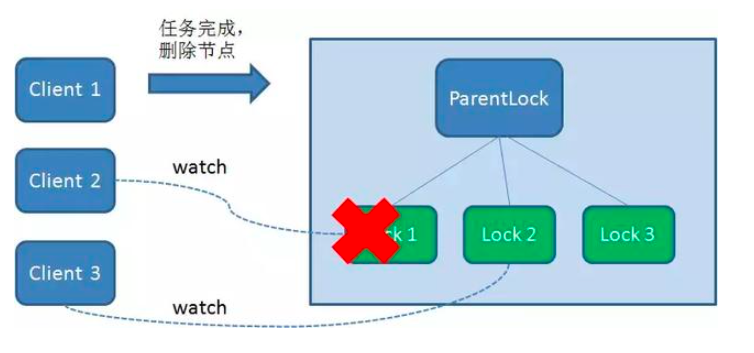
2. The client crashes during task execution
If Duang crashes during the execution of the task, Client1 that has obtained the lock will disconnect the link with the Zookeeper server. Depending on the characteristics of the temporary node, the associated node Lock1 is automatically deleted.
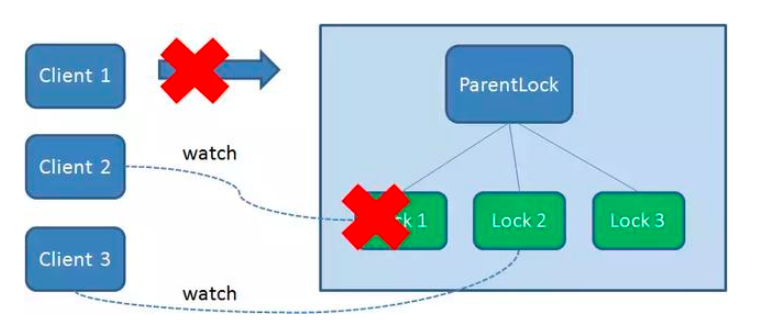
Because Client2 has been monitoring the existence status of Lock1, when the Lock1 node is deleted, Client2 will immediately receive a notification. At this time, Client2 will query all nodes under ParentLock again to confirm whether the node Lock2 created by itself is the smallest node at present. If it is the smallest, Client2 naturally obtains the lock.
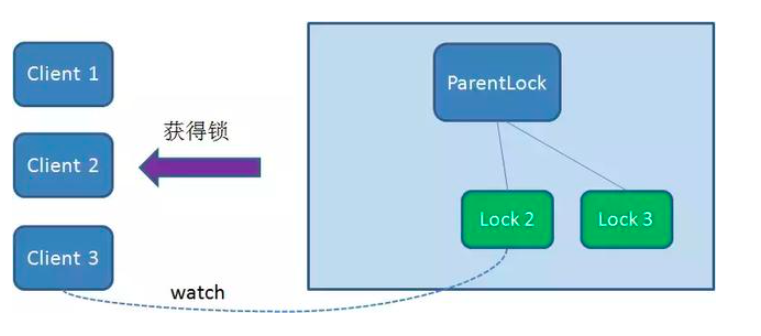
Similarly, if Client2 also deletes node Lock2 because the task is completed or the node crashes, Client3 will be notified.
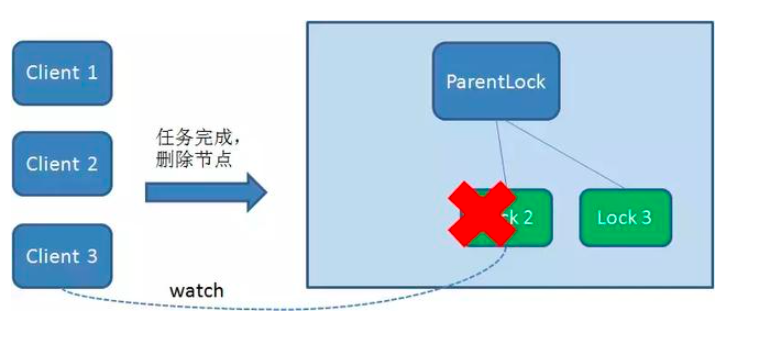
Finally, Client3 successfully got the lock.
Basic principles
The client attempts to create a temporary znode, and obtains the lock when the creation is successful; Other clients will fail to create locks. Only listeners can be registered to listen for locks. Releasing a lock is to delete the znode. Once released, the client will be notified, and then a waiting client can re lock it again
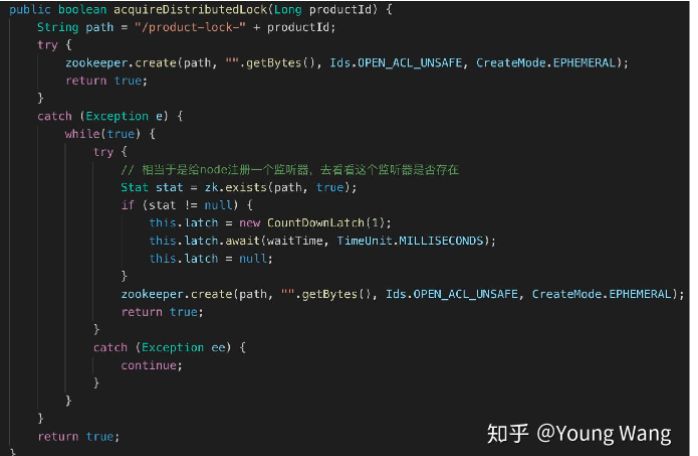
Existing problems - startling group effect
When a large number of clients compete for locks, a "shock group" effect will occur. Here, the startling effect refers to that in the process of distributed lock competition, a large number of "Watcher notification" and "create / exclusive/lock" operations are repeated, and most of the operation results fail to create nodes, so they continue to wait for the next notification. If the cluster is large, it will have a huge performance impact and network impact on ZooKeeper server and client server
Improvement scheme and implementation scheme:
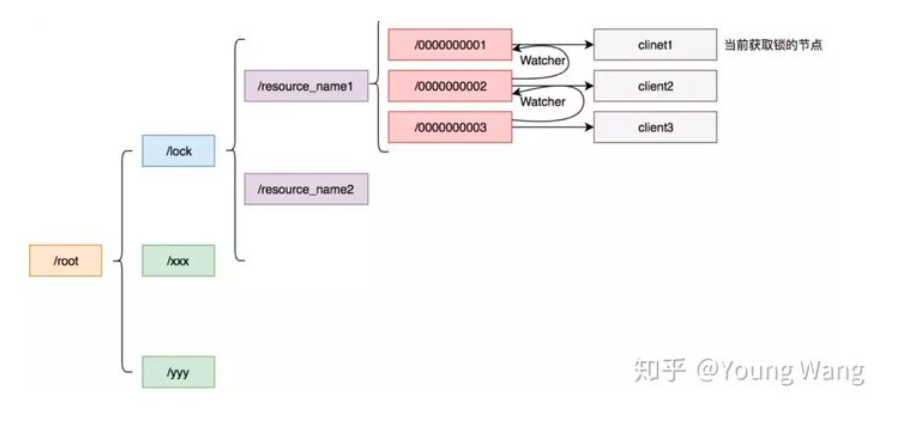
Cursor is the implementation of the improved scheme, and its scheme is as follows:
- Using ZK's temporary nodes and ordered nodes, each thread acquires a lock by creating a temporary ordered node in ZK, such as in the / lock / directory
- After the node is successfully created, obtain all temporary nodes in the / lock directory, and then judge whether the node created by the current thread is the node with the lowest sequence number of all nodes
- If the node created by the current thread is the node with the smallest sequence number of all nodes, it is considered to have succeeded in obtaining the lock
- If the node created by the current thread is not the node with the smallest node sequence number, add an event listener to the previous node of the node sequence number.
For example, if the node sequence number obtained by the current thread is / lock/003, and then the list of all nodes is [/ lock/001, / lock/002, / lock/003], add an event listener to the node / lock/002
The InterProcessMutex of Curator is the implementation of the improved scheme
InterProcessMutex also introduces the concept of reentrant.
Note: for the problem of ZooKeeper 3.4 cluster, the parent node will not be deleted, resulting in a large number of parent nodes. After ZooKeeper 3.5 cluster, a new Container node is introduced. If there is no child node, it will be deleted automatically.
Summary:
The implementation is relatively simple. Listeners can be used instead of polling, with less performance consumption
It is easy to generate self increasing IDs
The performance is similar to that of the database. If more clients frequently apply for locking and releasing locks, the pressure on the ZK cluster will be greater.
You can directly use zookeeper third-party libraries Curator Client, which encapsulates a reentrant lock service.
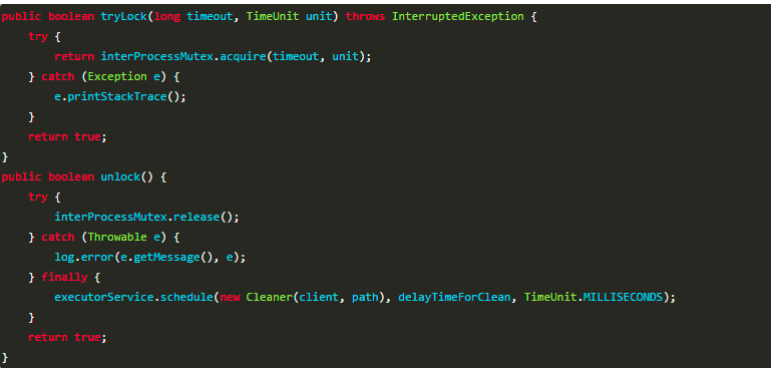
InterProcessMutex provided by cursor is the implementation of distributed lock. The acquire method is used to obtain the lock from the user, and the release method is used to release the lock.
Address: https://github.com/apache/curator/
Implementation of distributed lock based on cursor
Cursor is an upgraded version of Zookeeper client. It has realized the function of distributed lock and can be used directly.
Introduce cursor dependency:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.2.0</version>
</dependency>controller:
@Autowired
private CuratorFramework client;
@RequestMapping("curatorLock")
public String curatorLock(){
InterProcessMutex lock = new InterProcessMutex(client, "/order");
try{
if (lock.acquire(30, TimeUnit.SECONDS)){
//Delay simulation service code execution
Thread.sleep(10000);
}
}catch (Exception e) {
e.printStackTrace();
}finally {
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
return "Method execution completed!";
}Disadvantages:
The performance may not be as high as the cache service. Because every time in the process of creating and releasing locks, instantaneous nodes must be dynamically created and destroyed to realize the lock function. Creating and deleting nodes in ZK can only be performed through the Leader server, and then synchronize the data to all Follower machines.
In fact, using Zookeeper may also cause concurrency problems, but it is not common. Considering such a situation, due to network jitter, the session connection of the client ZK cluster is disconnected. Then ZK thinks that the client is hung, and the temporary node will be deleted. At this time, other clients can obtain the distributed lock. Concurrency problems may arise. This problem is not common because ZK has a retry mechanism. Once the ZK cluster cannot detect the heartbeat of the client, it will retry. The cursor client supports a variety of retry strategies. The temporary node will not be deleted until it fails after multiple retries. (therefore, it is also important to choose an appropriate retry strategy. We should find a balance between lock granularity and concurrency.)
Reference documents: https://blog.csdn.net/qq_36756682/article/details/109411847
Introducing Zookeeper dependency:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.14</version>
</dependency>Zookeeper distributed lock tool class:
public class ZkLock implements AutoCloseable, Watcher {
private ZooKeeper zooKeeper;
private String znode;
public ZkLock() throws IOException {
this.zooKeeper = new ZooKeeper("localhost:2181", 10000,this);
}
public boolean getLock(String businessCode) {
try {
//Create business root node
Stat stat = zooKeeper.exists("/" + businessCode, false);
if (stat==null){
zooKeeper.create("/" + businessCode,businessCode.getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
//Create instantaneous ordered node / order/order_00000001
znode = zooKeeper.create("/" + businessCode + "/" + businessCode + "_", businessCode.getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
//Get all child nodes under the business node
List<String> childrenNodes = zooKeeper.getChildren("/" + businessCode, false);
//Child node sorting
Collections.sort(childrenNodes);
//Gets the (first) child node with the smallest sequence number
String firstNode = childrenNodes.get(0);
//If the created node is the first child node, the lock is obtained
if (znode.endsWith(firstNode)){
return true;
}
//If it is not the first child node, listen to the previous node
String lastNode = firstNode;
for (String node:childrenNodes){
if (znode.endsWith(node)){
zooKeeper.exists("/"+businessCode+"/"+lastNode,true);
break;
}else {
lastNode = node;
}
}
//Realize blocking function
synchronized (this){
wait();
}
return true;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
@Override
public void close() throws Exception {
zooKeeper.delete(znode,-1);
zooKeeper.close();
}
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted){
synchronized (this){
notify();
}
}
}
}controller:
@RequestMapping("zkLock")
public String zookeeperLock(){
try (ZkLock zkLock = new ZkLock()) {
if (zkLock.getLock("order")){
//Delay simulation service code execution
Thread.sleep(10000);
}
}catch (Exception e) {
e.printStackTrace();
}
return "Method execution completed!";
}4. Summary
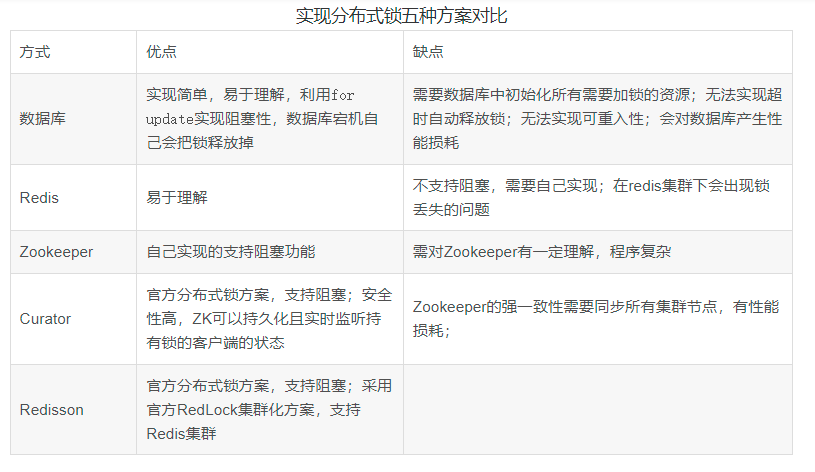
The following table summarizes the advantages and disadvantages of Zookeeper and Redis distributed locks:

Comparison of three schemes
None of the above methods can be perfect. Just like CAP, it cannot meet the requirements of complexity, reliability and performance at the same time. Therefore, it is the king to choose the most suitable one according to different application scenarios.
From the perspective of difficulty of understanding (from low to high)
Database > cache > zookeeper
From the perspective of implementation complexity (from low to high)
Zookeeper > = cache > Database
From a performance perspective (high to low)
Cache > zookeeper > = database
From the perspective of reliability (from high to low)
Zookeeper > cache > Database