in the previous article, we learned about the basic functions of the dispatching center other than the scheduler. Today, let's learn how the "Trigger" in XXL job works.
1, Introduction
in the previous study, we can see that XXL job splits the two logic of "time scheduling" and "specific task scheduling". The time scheduling logic is processed in the JobScheduleHelper, and the specific task scheduling logic is placed in the JobTriggerPoolHelper. So in this chapter, we mainly learn how to schedule specific tasks in JobTriggerPoolHelper. let's take a general look at the methods provided by JobTriggerPoolHelper:
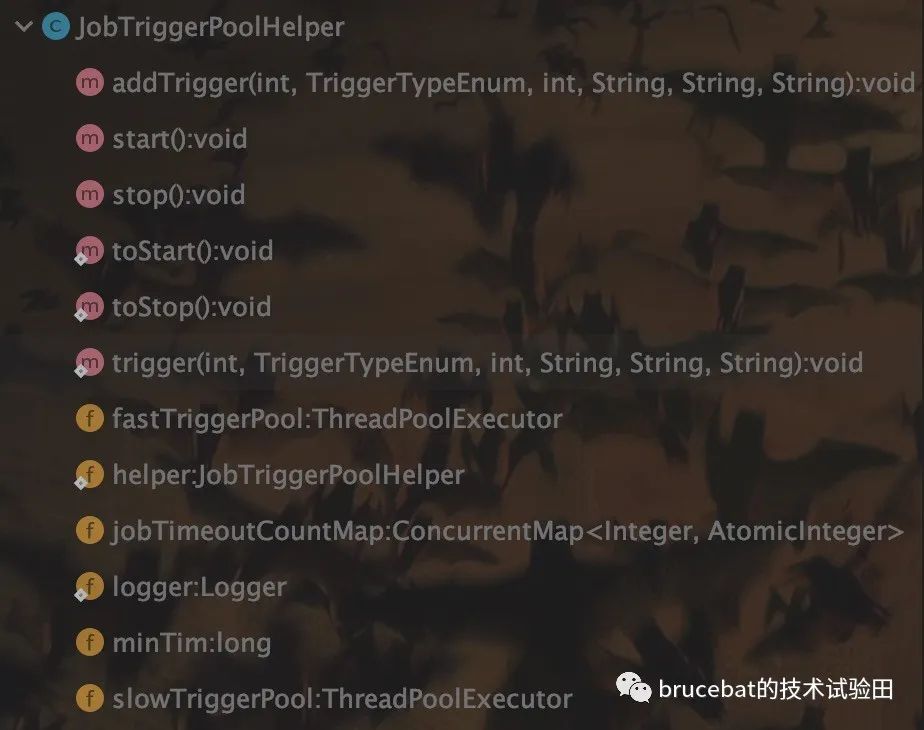
from the above methods, we can conclude that JobTriggerPoolHelper provides the following three functions:
- Start processing thread
- Terminate processing thread
- Perform task trigger
let's take a look at the specific processing logic of JobTriggerPoolHelper.
2, Task trigger JobTriggerPoolHelper
1. Trigger mode
by looking at the user of trigger() method in JobTriggerPoolHelper, we can see the following five scenarios for triggering tasks:
- Trigger a task in the dispatching center page;
- The task is triggered by the dispatching center according to the time schedule;
- If the task fails, trigger the task again;
- Trigger the subtask after the parent task is completed;
- Trigger the task through API call;
of course, we can also view it by triggering the type enumeration class TriggerTypeEnum:
/**
* Manual trigger
*/
MANUAL(I18nUtil.getString("jobconf_trigger_type_manual")),
/**
* Triggered according to cron expression
*/
CRON(I18nUtil.getString("jobconf_trigger_type_cron")),
/**
* Failed retry trigger
*/
RETRY(I18nUtil.getString("jobconf_trigger_type_retry")),
/**
* Parent task trigger
*/
PARENT(I18nUtil.getString("jobconf_trigger_type_parent")),
/**
* API Call trigger
*/
API(I18nUtil.getString("jobconf_trigger_type_api"));
2. Fast task thread pool and slow task thread pool
because the thread pool is used for task scheduling in XXL job, once a task scheduling time is too long and the thread is blocked, the scheduling efficiency of the scheduling center will be reduced. To solve this problem, XXL job creates "fast task thread pool" and "slow task thread pool". generally, tasks are placed in the fast task thread pool by default for task triggering. Here, XXL job sets a task trigger time window with a length of 500ms. The trigger checks the triggered time of the current task every minute during the task triggering process. If the time window is exceeded more than 10 times, the task will be demoted to the slow task thread pool. The specific processing logic is as follows:
// Thread pool selection logic
ThreadPoolExecutor triggerPool_ = fastTriggerPool;
AtomicInteger jobTimeoutCount = jobTimeoutCountMap.get(jobId);
if (jobTimeoutCount!=null && jobTimeoutCount.get() > 10) {
// job-timeout 10 times in 1 min
triggerPool_ = slowTriggerPool;
}
...
// Time window check logic
// check timeout-count-map
long minTim_now = System.currentTimeMillis()/60000;
if (minTim != minTim_now) {
minTim = minTim_now;
jobTimeoutCountMap.clear();
}
// incr timeout-count-map
long cost = System.currentTimeMillis()-start;
if (cost > 500) {
// ob-timeout threshold 500ms
AtomicInteger timeoutCount = jobTimeoutCountMap.putIfAbsent(jobId, new AtomicInteger(1));
if (timeoutCount != null) {
timeoutCount.incrementAndGet();
}
}
3. Task trigger
task triggering is realized by calling the trigger() method of XxlJobTrigger by fast task thread pool / slow task thread pool. The specific codes are as follows:
public static void trigger(int jobId,
TriggerTypeEnum triggerType,
int failRetryCount,
String executorShardingParam,
String executorParam,
String addressList) {
// load data
XxlJobInfo jobInfo = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().loadById(jobId);
if (jobInfo == null) {
logger.warn(">>>>>>>>>>>> trigger fail, jobId invalid,jobId={}", jobId);
return;
}
if (executorParam != null) {
jobInfo.setExecutorParam(executorParam);
}
int finalFailRetryCount = failRetryCount>=0?failRetryCount:jobInfo.getExecutorFailRetryCount();
XxlJobGroup group = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().load(jobInfo.getJobGroup());
// cover addressList
if (addressList!=null && addressList.trim().length()>0) {
group.setAddressType(1);
group.setAddressList(addressList.trim());
}
// sharding param
int[] shardingParam = null;
if (executorShardingParam!=null){
String[] shardingArr = executorShardingParam.split("/");
if (shardingArr.length==2 && isNumeric(shardingArr[0]) && isNumeric(shardingArr[1])) {
shardingParam = new int[2];
shardingParam[0] = Integer.valueOf(shardingArr[0]);
shardingParam[1] = Integer.valueOf(shardingArr[1]);
}
}
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST==ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null)
&& group.getRegistryList()!=null && !group.getRegistryList().isEmpty()
&& shardingParam==null) {
for (int i = 0; i < group.getRegistryList().size(); i++) {
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, i, group.getRegistryList().size());
}
} else {
if (shardingParam == null) {
shardingParam = new int[]{0, 1};
}
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, shardingParam[0], shardingParam[1]);
}
}
the following processing is performed in the trigger() method:
- Load the task information according to jobId and load the execution parameters in the task information;
- Get the number of task retries;
- Recheck the actuator list and update it;
- Obtain the fragment execution information executorShardingParam and convert it into a fragment parameter array. The data size is 2. The first element stores the "currently executed task fragment index" and the second element stores the "total number of task fragments";
- According to the task execution routing strategy, judge whether to execute in pieces. If it is executed in pieces, execute in pieces according to the current actuator group. "The total number of pieces is equal to the number of online machines in the actuator group". If fragmentation execution is not performed, set "fragmentation index to 0" and "total number of fragmentation to 1", and then perform task execution.
3, Summary
so far, the main processing logic of XXL job has been learned (finally, the water is over and the flowers are scattered ~ ~). At this time, looking back at the original article, there are still many places where the analysis is not detailed enough, but as an introduction to basic cognition, it should still be OK, right? Ha ha ha~~ although the epidemic is stable, the situation is still severe. I hope you should always be vigilant. Finally, I wish you good health and smooth work. Come on~~