Technical background
coupon https://m.fenfaw.net/Distributed and parallel computing are very important concepts in the computer field. For some laymen, I always think this is a very simple job, but if we look at the hardware development history of computers, from CPU to GPU, TPU and Huawei's shengteng (NPU), and even the current hot quantum computer (QPU), it is actually the development history of distributed and parallel computing. From simple data parallelism, to algorithm parallelism, to graph parallelism, and finally the physical parallelism brought by quantum superposition. Therefore, whether we can do well in distributed and parallel technology largely determines the upper limit of the performance of a tool. In this paper, let's study the mindspire distributed training method.
Environment deployment
In the previous blog, we discussed using Docker and Singularity container to install the CPU version and GPU version of mindcore. Interested readers can turn to these historical blogs. In this article, we will have installed a mindspire GPU environment locally by default. On this premise, we will discuss how to use the distributed function of mindspire in the environment of single machine and multiple GPU cards. For a more complete introduction, please refer to this official address, which contains a complete introduction to installation, deployment and use. Here we only introduce the basic installation and use methods for the local Ubuntu environment.
Install openmpi
A total of 2 softwares need to be installed here. We all adopt the method of source code installation. First, download the source code of the corresponding version from the download link given by mindspire:
According to the version, we can download the tar. 4.0.3 GZ compressed package:
After downloading, you can roughly install the source code according to the operation instructions: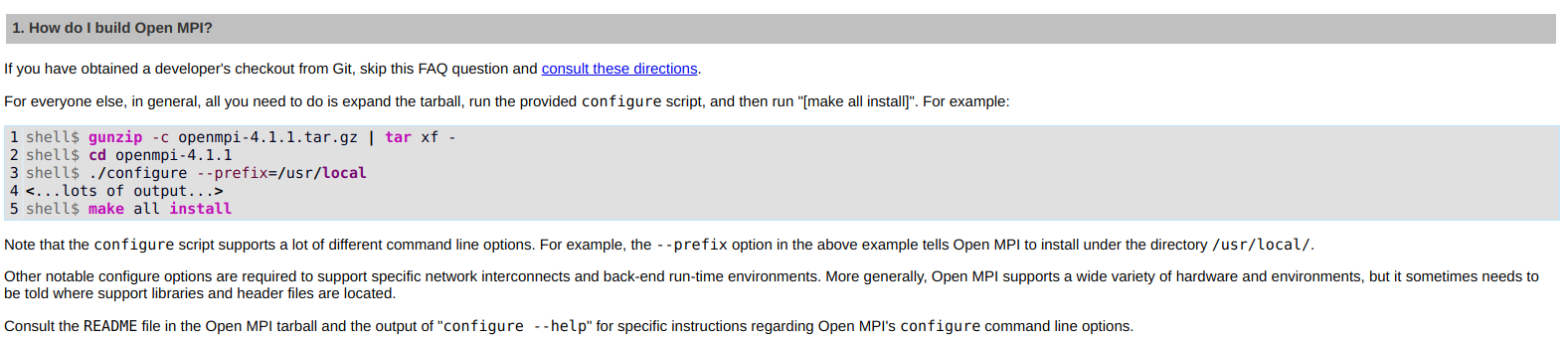
If the installation is successful, run mpirun --version to see the version number. Yes, there are two points to remind: 1 Decompression does not necessarily use the instructions given here. You can use your own; 2. If the prefix of this guideline is followed, it needs to be in LD later_ LIBRARY_ Add / usr/local/lib / to the environment variable path, otherwise some so libraries will not be recognized.
Install NCCL
The NCCL tool is used for mindspire's distributed communication on GPU. Similarly, let's go to the link given here to find the source package to download and install:
The Local installation scheme is recommended here:
After finding the software package suitable for your own system version, you can install it step by step according to the following guidelines: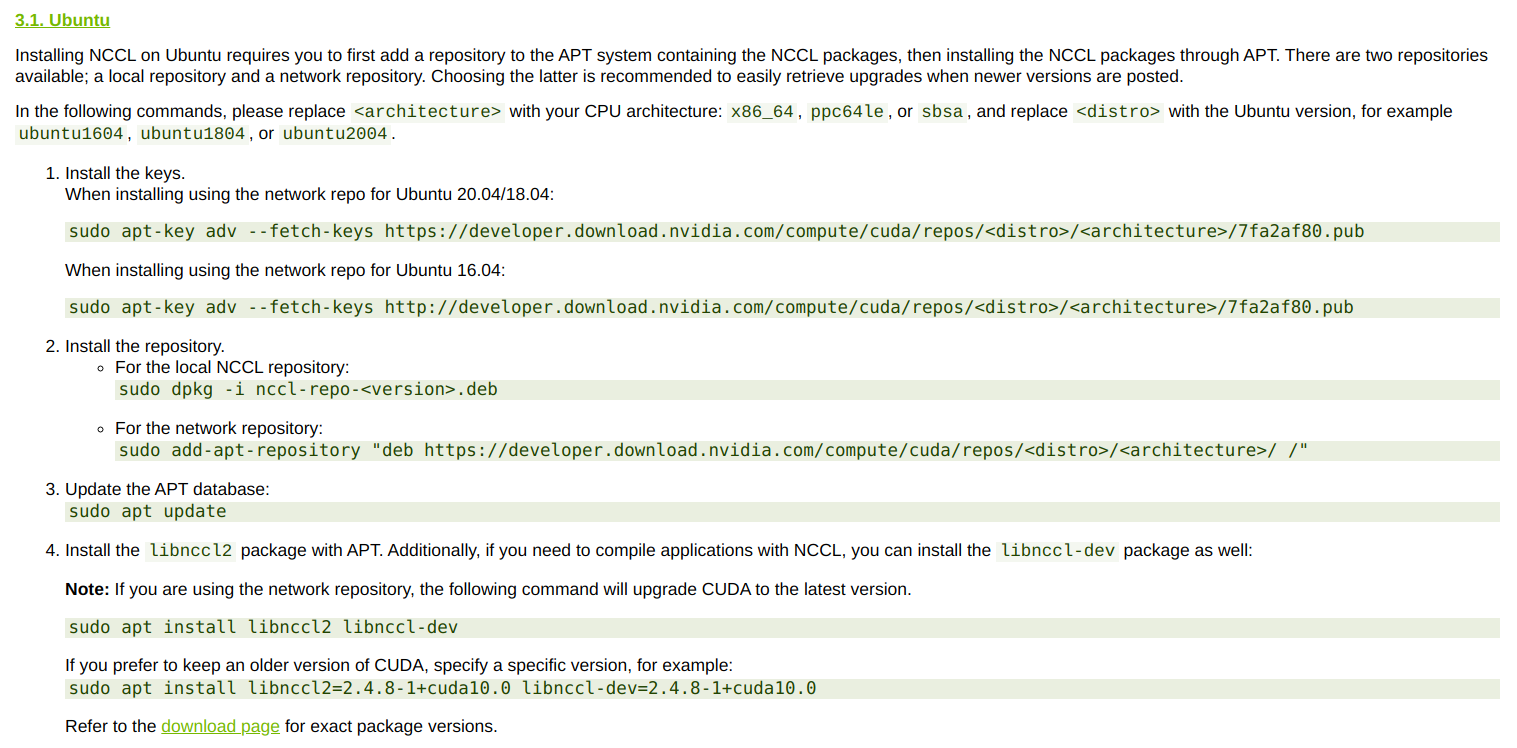
If you fail to execute apt key once, you can execute it twice more.
Environmental testing
After successful installation, after both openmpi and NCCL are installed successfully, you can use the following initialization example to test the deployment of the environment:
# test-init.py
from mindspore import context
from mindspore.communication.management import init
if __name__ == "__main__":
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
init("nccl")
If the execution result is as follows and there is no error message, the environment deployment is successful:
dechin@ubuntu2004:~/projects/mindspore/test$ mindspore test-init.py dechin@ubuntu2004:~/projects/mindspore/test$
Mindspire distributed training
First of all, some people may wonder, what is the last instruction mindscore used in the previous chapter? This is actually a shortcut command of mindscore GPU version configured locally by myself:
dechin@ubuntu2004:~/projects/$ cat ~/.bashrc | grep mindspore alias mindspore='singularity exec --nv /home/dechin/tools/singularity/mindspore-gpu_1.2.0.sif python'
If you think it's convenient, readers can also go to alias for a quick command according to their preferences.
Next, let's look at an implementation case. This code comes from the previous blog, but on the basis of this code, we added the initialization code init() in the previous chapter. The complete code is as follows:
# test_nonlinear.py
from mindspore import context
from mindspore.communication.management import init
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
init()
import numpy as np
from mindspore import dataset as ds
from mindspore import nn, Tensor, Model
import time
from mindspore.train.callback import Callback, LossMonitor
def get_data(num, a=2.0, b=3.0, c=5.0):
for _ in range(num):
x = np.random.uniform(-1.0, 1.0)
y = np.random.uniform(-1.0, 1.0)
noise = np.random.normal(0, 0.03)
z = a * x ** 2 + b * y ** 3 + c + noise
yield np.array([[x**2], [y**3]],dtype=np.float32).reshape(1,2), np.array([z]).astype(np.float32)
def create_dataset(num_data, batch_size=16, repeat_size=1):
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['xy','z'])
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data
data_number = 160
batch_number = 16
repeat_number = 200
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
dict_datasets = next(ds_train.create_dict_iterator())
class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
self.fc = nn.Dense(2, 1, 0.02, 0.02)
def construct(self, x):
x = self.fc(x)
return x
net = LinearNet()
model_params = net.trainable_params()
print ('Param Shape is: {}'.format(len(model_params)))
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
net_loss = nn.loss.MSELoss()
optim = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.6)
model = Model(net, net_loss, optim)
epoch = 1
model.train(epoch, ds_train, callbacks=[LossMonitor(10)], dataset_sink_mode=False)
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
At this point, we need to run this code with mpirun instead:
dechin@ubuntu2004:~/projects/gitlab/dechin/src/mindspore$ mpirun -n 2 singularity exec --nv /home/dechin/tools/singularity/mindspore-gpu_1.2.0.sif python test_nonlinear.py
During operation, we can see that there are two python tasks running on two different GPU cards: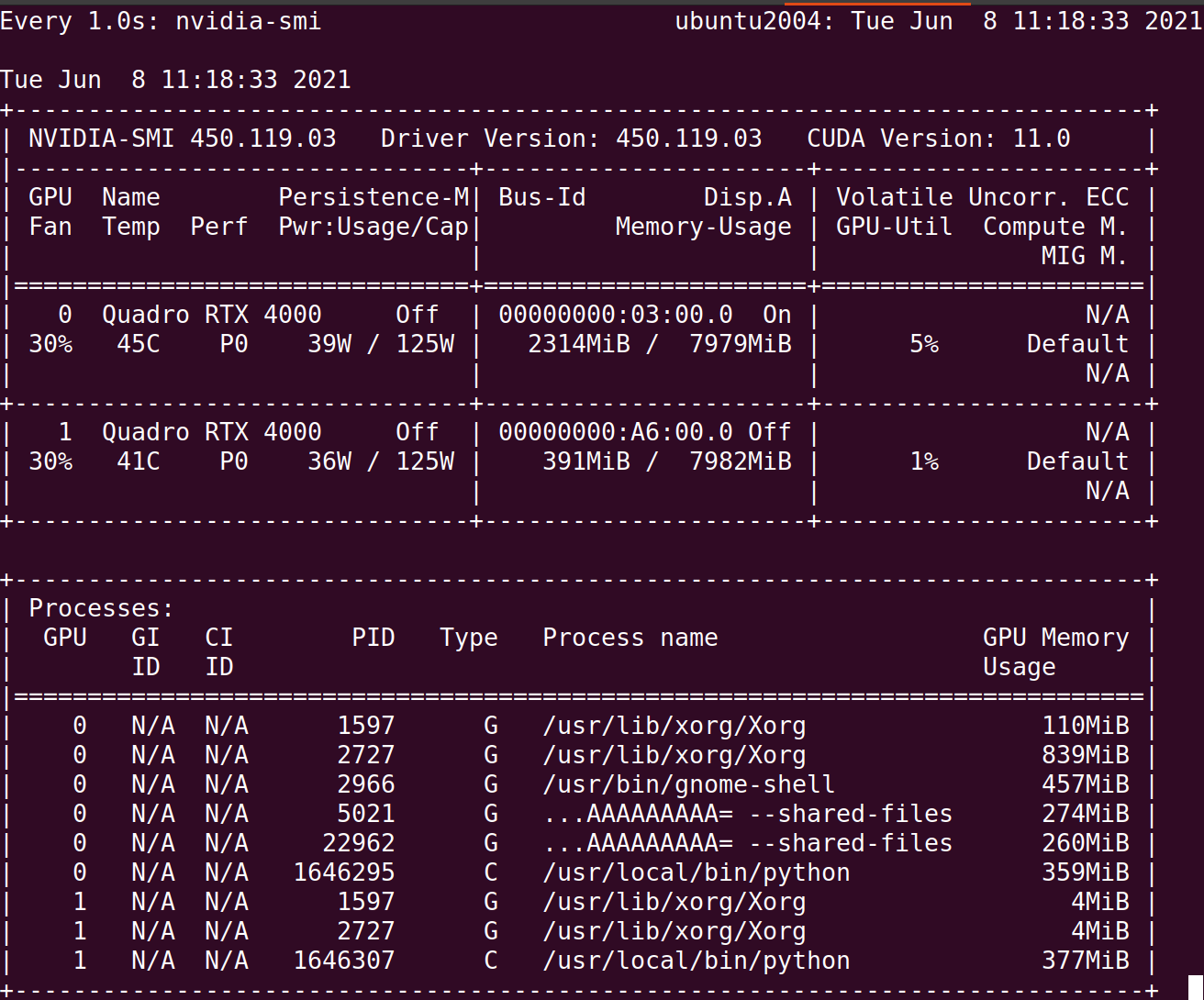
This monitoring method is actually NVIDIA SMI instruction, but in order to monitor the GPU status for a long time, I use the watch - N 1 NVIDIA SMI instruction to refresh the NVIDIA SMI status every 1s. But there are also two points to note here: 1 This code can also run on a single GPU card directly with the mindshare instruction, but if you want to run it with mpirun, you can't use the mindshare instruction of alias just now, but you need to write the complete instruction manually, unless you add a new instruction to alias; 2. Because the above code is only initialized, although it runs on two cards, in fact, the training process does not communicate with each other. It is two independent tasks. Then, if you want to construct a complete automatic distributed training, you need to add context like the following code set_ auto_ parallel_ Context (parallel_mode = parallelmode. Data_parallel) and some configurations in checkpoint. The new complete code is as follows:
# test_nonlinear.py
from mindspore import context
from mindspore.communication.management import init
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
init()
import numpy as np
from mindspore import dataset as ds
from mindspore import nn, Tensor, Model
import time
from mindspore.train.callback import Callback, LossMonitor, ModelCheckpoint, CheckpointConfig
from mindspore.context import ParallelMode
import mindspore as ms
ms.common.set_seed(0)
start_time = time.time()
def get_data(num, a=2.0, b=3.0, c=5.0):
for _ in range(num):
x = np.random.uniform(-1.0, 1.0)
y = np.random.uniform(-1.0, 1.0)
noise = np.random.normal(0, 0.03)
z = a * x ** 2 + b * y ** 3 + c + noise
yield np.array([[x**2], [y**3]],dtype=np.float32).reshape(1,2), np.array([z]).astype(np.float32)
def create_dataset(num_data, batch_size=16, repeat_size=1):
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['xy','z'])
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data
data_number = 160
batch_number = 16
repeat_number = 20
context.set_auto_parallel_context(parallel_mode=ParallelMode.DATA_PARALLEL)
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
dict_datasets = next(ds_train.create_dict_iterator())
class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
self.fc = nn.Dense(2, 1, 0.02, 0.02)
def construct(self, x):
x = self.fc(x)
return x
net = LinearNet()
model_params = net.trainable_params()
print ('Param Shape is: {}'.format(len(model_params)))
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
net_loss = nn.loss.MSELoss()
optim = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.6)
ckpt_config = CheckpointConfig()
ckpt_callback = ModelCheckpoint(prefix='data_parallel', config=ckpt_config)
model = Model(net, net_loss, optim)
epoch = 10
model.train(epoch, ds_train, callbacks=[ckpt_callback], dataset_sink_mode=True)
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
print ('The total time cost is: {}s'.format(time.time() - start_time))
The running result of this code is as follows:
dechin@ubuntu2004:~/projects/gitlab/dechin/src/mindspore$ mpirun -n 2 singularity exec --nv /home/dechin/tools/singularity/mindspore-gpu_1.2.0.sif python test_nonlinear.py Param Shape is: 2 Parameter (name=fc.weight, shape=(1, 2), dtype=Float32, requires_grad=True) [[0.02 0.02]] Parameter (name=fc.bias, shape=(1,), dtype=Float32, requires_grad=True) [0.02] Param Shape is: 2 Parameter (name=fc.weight, shape=(1, 2), dtype=Float32, requires_grad=True) [[0.02 0.02]] Parameter (name=fc.bias, shape=(1,), dtype=Float32, requires_grad=True) [0.02] [WARNING] ME(2528801:139843698521024,MainProcess):2021-06-10-09:45:37.603.010 [mindspore/train/callback/_checkpoint.py:428] OSError, failed to remove the older ckpt file /home/dechin/projects/gitlab/dechin/src/mindspore/data_parallel-1_200.ckpt. [WARNING] ME(2528799:139709496722368,MainProcess):2021-06-10-09:45:37.713.232 [mindspore/train/callback/_checkpoint.py:428] OSError, failed to remove the older ckpt file /home/dechin/projects/gitlab/dechin/src/mindspore/data_parallel-2_200.ckpt. [WARNING] ME(2528799:139709496722368,MainProcess):2021-06-10-09:45:37.824.271 [mindspore/train/callback/_checkpoint.py:428] OSError, failed to remove the older ckpt file /home/dechin/projects/gitlab/dechin/src/mindspore/data_parallel-3_200.ckpt. [WARNING] ME(2528799:139709496722368,MainProcess):2021-06-10-09:45:37.943.749 [mindspore/train/callback/_checkpoint.py:428] OSError, failed to remove the older ckpt file /home/dechin/projects/gitlab/dechin/src/mindspore/data_parallel-4_200.ckpt. [WARNING] ME(2528801:139843698521024,MainProcess):2021-06-10-09:45:38.433.85 [mindspore/train/callback/_checkpoint.py:428] OSError, failed to remove the older ckpt file /home/dechin/projects/gitlab/dechin/src/mindspore/data_parallel-5_200.ckpt. Parameter (name=fc.weight, shape=(1, 2), dtype=Float32, requires_grad=True) [[0.12186428 0.21167319]] Parameter (name=fc.bias, shape=(1,), dtype=Float32, requires_grad=True) [5.561276] The total time cost is: 8.412446737289429s Parameter (name=fc.weight, shape=(1, 2), dtype=Float32, requires_grad=True) [[0.12186428 0.21167319]] Parameter (name=fc.bias, shape=(1,), dtype=Float32, requires_grad=True) [5.561276] The total time cost is: 8.439369916915894s
Although the operation is successful, it should be noted that the distributed case takes 8.44s, while the training of single card takes 8.15s. The distributed training speed is even slower than that of single card. We will explain this phenomenon in the summary.
Summary
In this article, we mainly discuss how to deploy a distributed training environment based on mindspire framework. When the mindspire environment has been configured, we only need to install openmpi and nccl to realize distributed training. In this paper, we have given the corresponding examples. Although the purpose of distributed and parallel technology is to improve performance, it does not mean that it can accelerate all scenarios. For example, the cases in this article have no acceleration effect. In fact, this is because our use case scenario is too simple. Throughout the whole training process, the utilization rate of GPU is less than 10%. In this case, we also need to consider the overhead of communication. Naturally, it is not faster to train on the same card. This also gives us an inspiration. When considering the use of distributed and parallel computing technology, we must first evaluate whether the problem itself is suitable for parallel processing, otherwise the expected acceleration will not be achieved.
Copyright notice
The first link of this article is: https://www.cnblogs.com/dechinphy/p/dms.html
Author ID: DechinPhy
For more original articles, please refer to: https://www.cnblogs.com/dechinphy/
Special links for rewards: https://www.cnblogs.com/dechinphy/gallery/image/379634.html
Tencent cloud column synchronization: https://cloud.tencent.com/developer/column/91958